Command Palette
Search for a command to run...
DSpark: فك شفريته المفترضة المجدولة حسب الثقة مع التوليد شبه الذاتوي
الشرح:
"Confidence-Scheduled" تترجم إلى "المجدولة حسب الثقة" حيث أن "scheduled" تعني مجدولة و "confidence" تعني الثقة.
"Speculative Decoding" تترجم إلى "فك شفريته المفترضة" حيث أن "speculative" تعني مفترضة و "decoding" تعني فك شفريته.
"Semi-Autoregressive Generation" تترجم إلى "التوليد شبه الذاتوي" حيث أن "semi" تعني شبه و "autoregressive" تعني الذاتوي.
هذا الترجمة تعكس المصطلحات الأكاديمية المتداولة في مجال الذكاء الاصطناعي واللغويات الحاسوبية.
DSpark: فك شفريته المفترضة المجدولة حسب الثقة مع التوليد شبه الذاتوي الشرح:
"Confidence-Scheduled" تترجم إلى "المجدولة حسب الثقة" حيث أن "scheduled" تعني مجدولة و "confidence" تعني الثقة. "Speculative Decoding" تترجم إلى "فك شفريته المفترضة" حيث أن "speculative" تعني مفترضة و "decoding" تعني فك شفريته. "Semi-Autoregressive Generation" تترجم إلى "التوليد شبه الذاتوي" حيث أن "semi" تعني شبه و "autoregressive" تعني الذاتوي.
هذا الترجمة تعكس المصطلحات الأكاديمية المتداولة في مجال الذكاء الاصطناعي واللغويات الحاسوبية.
الملخص
يعجّل التحليل التخميني (Speculative Decoding) من استنتاج نماذج اللغات الكبيرة (LLMs) من خلال فصل عملية إنشاء المسودات عن مرحلتها الموثقة. وعلى الرغم من أن مسودات الموازية الحديثة تقترح تسلسلات رموز طويلة بكفاءة في عملية مرور أمامي واحدة، إلا أنها تعاني من تراجع سريع في معدلات القبول بسبب افتقارها إلى تبعيات بين الرموز. وعلاوة على ذلك، فإن التحقق العشوائي من هذه الكتل الممتدة يهدر سعة الحزم الحرجة على الرموز ذات المخاطر العالية للرفض، ما يقلل بشدة من الإنتاجية في أنظمة الخدمة ذات التشغيل المتزامن العالي. نقدم إطار عمل "ديسبارك" (DSpark) للتحليل التخميني، الذي يدمج بين الإنتاج العالي للتعامل المتوازى والتحقق التكيفي الذي يدرك الحمل. للحفاظ على جودة المسودات، تستخدم "ديسبارك" بنية شبه ذاتية الارتباط، من خلال دمج العمود الفقري المتوازي مع وحدة تسلسلية خفيفة الوزن، لطرح نمذجة التبعيات داخل الكتلة والتخفيف من تدهور السلسلة. ولتحسين كفاءة النظام، تستخدم "ديسبارك" التحقق المجدول بناءً على الثقة، حيث تُكيّف طول التحقق ديناميكياً لكل طلب استناداً إلى احتمالات البقاء المتبقية المقدرة وملفات تعريف إنتاجية المحرك. أظهرت الاختبارات غير المتصلة عبر نطاقات متنوعة أن "ديسبارك" يحسّن بشكل ملحوظ طول الرموز المقبولة مقارنة بأحدث مسودات الاعتماد الذاتي والمتوازى. عند نشره داخل نظام خدمة "ديبسيك-في4" تحت حركة مرور المستخدمين المباشرة، نجح "ديسبارك" في التخفيف من هدر التحقق.
One-sentence Summary
DeepSeek researchers propose DSpark, a speculative decoding framework that couples a semi-autoregressive draft architecture, combining a parallel backbone with a lightweight sequential module to introduce intra-block dependencies and mitigate suffix decay, with confidence-scheduled verification that dynamically adjusts verification length per request based on estimated prefix survival probabilities and engine-specific throughput profiles, to reduce verification waste and improve throughput in live deployments on DeepSeek-V4.
Key Contributions
- DSpark uses a semi-autoregressive drafter that couples a parallel backbone with a lightweight sequential RNN head, injecting intra-block dependencies to mitigate suffix decay while preserving exact per-token softmax probabilities for rejection sampling.
- The framework introduces confidence-scheduled verification, which dynamically selects verification lengths per request using estimated prefix survival probabilities and engine-level throughput profiles to eliminate wasted batch capacity on high-risk tokens.
- Across diverse offline benchmarks, DSpark substantially improves accepted length over state-of-the-art autoregressive and parallel drafters, and in a live DeepSeek-V4 serving deployment it mitigates verification waste under real user traffic.
Introduction
Autoregressive decoding forces large language models to generate one token per forward pass, causing inference latency to grow linearly with output length. Speculative decoding bypasses this bottleneck by having a fast draft model propose multiple tokens at once, which the target model then verifies in parallel to maintain exact output distributions. However, practical speedups are limited because draft models struggle to combine both high acceptance rates and low drafting cost: lightweight autoregressive drafters reintroduce sequential overhead, while parallel generation schemes (non-autoregressive transformers, CTC-based models) cannot easily provide per-token probabilities for the standard rejection-sampling acceptance rule, restricting them to greedy verification. The authors present DSpark, which introduces a semi-autoregressive drafter that first predicts a block of tokens in parallel from a shared representation, then applies a local sequential correction head to yield exact per-token distributions for full compatibility with speculative decoding’s verification step. Coupled with a confidence-based scheduler that dynamically adapts the number of draft tokens per cycle, DSpark improves the drafting speed-quality balance and overall decoding throughput.
Method
The authors introduce DSpark, a speculative decoding framework designed to unify high-throughput parallel generation with adaptive, load-aware verification. To address the limitations of existing drafters, DSpark integrates two complementary components: a semi-autoregressive generation module and a confidence-scheduled verification mechanism.
As shown in the figure below:
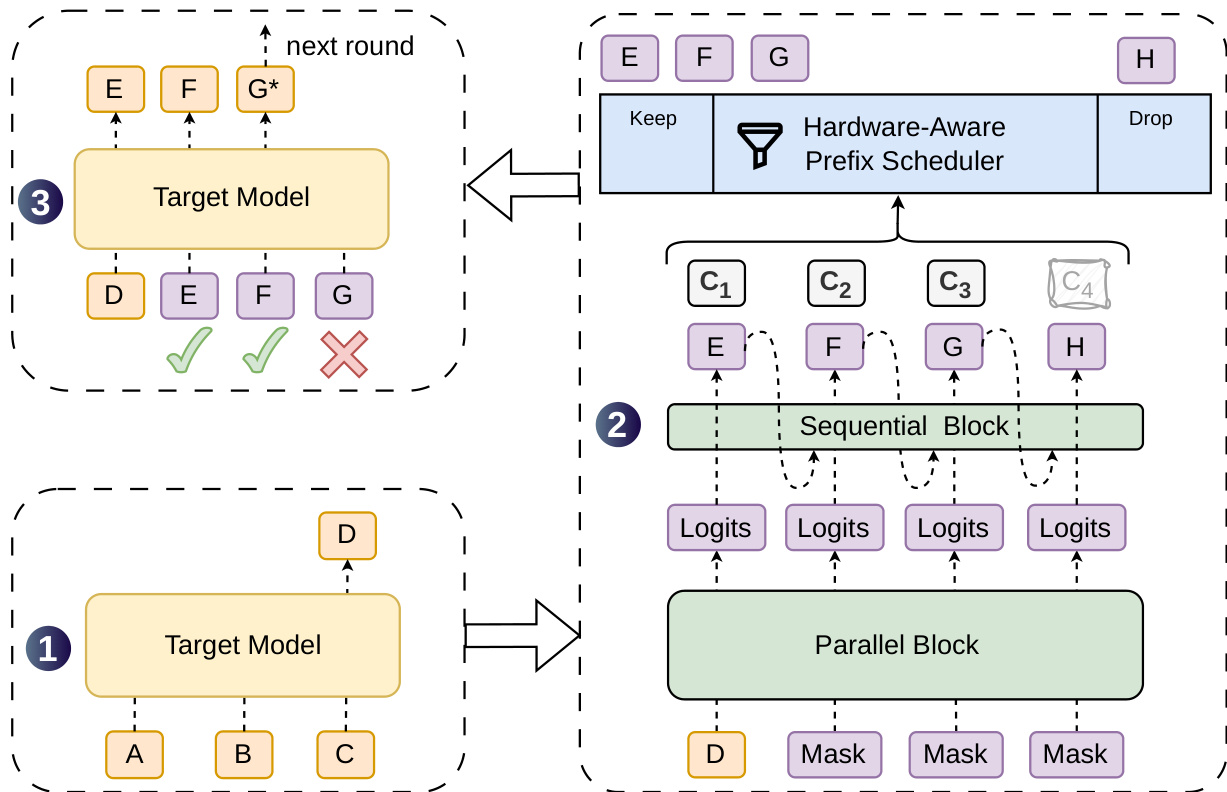
The semi-autoregressive generation module splits draft generation into two stages to maintain draft quality while keeping latency low. First, a parallel backbone processes the entire block in a single forward pass, producing hidden states and base logits. This keeps the drafting time nearly independent of the block size. Second, a lightweight sequential block injects dependency among draft tokens. Rather than defining a globally normalized energy model, the sequential stage induces a causal block distribution through an autoregressive factorization:
P(X∣x0)=k=1∏γpk(xk∣x0,x<k),pk(v∣x0,x<k)=∑u∈Vexp(Uk(u)+Bk(x0,x<k,u))exp(Uk(v)+Bk(x0,x<k,v)).Here, x0 is the anchor token, Uk represents the base logits from the parallel backbone, and Bk is a prefix-dependent transition bias. The authors implement this sequential stage using either a Markov head, which restricts the bias to depend only on the immediately preceding token via low-rank factorization, or an RNN head, which maintains a recurrent state to accumulate the full prefix history.
To optimize system efficiency, DSpark employs confidence-scheduled verification. A confidence head outputs a scalar estimate ck∈(0,1) for each draft position, modeling the conditional probability that the draft token will survive target verification given that all preceding tokens have been accepted. The architecture uses a lightweight linear projection followed by a sigmoid function:
ck=σ(w⊤[hk;W1[xk−1]]),where hk is the backbone hidden state and W1[xk−1] is the embedding of the previous draft token. To ensure the absolute magnitudes of these probabilities are accurate for scheduling, the authors apply Sequential Temperature Scaling to calibrate the joint probability of a draft prefix being accepted.
The hardware-aware prefix scheduler then uses these calibrated survival probabilities to dynamically determine the optimal verification length for each request. The scheduler formulates verification length selection as a global throughput maximization problem. For a batch of R active requests, the total batch size sent to the target model is B=∑r=1R(1+ℓr), and the expected number of accepted tokens is τ=∑r=1R(1+∑j=1ℓrar,j), where ar,j=∏i≤jcr,i is the cumulative survival probability. The scheduler aims to maximize the expected system-wide token throughput Θ=τ⋅SPS(B), where SPS(B) is the profiled engine throughput. By greedily admitting tokens with the highest survival probabilities and employing an early-stopping mechanism to enforce causality, the scheduler prevents verification waste without compromising the lossless guarantee of speculative decoding.
During training, the target model is frozen, and the draft model updates only the backbone, sequential block, and confidence head. The training objective combines three position-weighted terms: a cross-entropy loss Lce for next-token prediction, a distribution-matching loss Ltv that penalizes the total variation distance between draft and target distributions, and a binary cross-entropy confidence loss Lconf. The overall objective is a weighted combination:
L=αceLce+αtvLtv+αconfLconf.This multi-task training ensures the draft model generates high-quality tokens while providing reliable confidence estimates for the scheduler.
Experiment
The evaluation uses offline benchmarks spanning mathematical reasoning, code generation, and chat to compare the semi-autoregressive DSpark drafter against fully autoregressive and parallel drafters, revealing that DSpark combines the high initial-token capacity of parallel models with reduced suffix decay via a lightweight sequential head. Controlled experiments further show that even a small amount of autoregression yields substantial coherence gains and that a confidence head adaptively prunes low-probability suffixes, reducing wasted verification. In a live production deployment under user traffic, DSpark’s hardware-aware scheduler dynamically adjusts verification length to load, shifting the throughput-interactivity Pareto frontier outward and maintaining robust capacity under strict latency constraints.
The authors evaluate the DSpark speculative decoding framework against autoregressive and parallel baselines across multiple target models and domains. Results show that DSpark consistently achieves the highest accepted length per decoding round, outperforming both baseline drafters across all tested configurations. Additionally, the experiments reveal that structured tasks like math and code naturally sustain higher acceptance rates compared to open-ended chat domains. DSpark consistently outperforms both the autoregressive Eagle3 and parallel DFlash drafters across all target model scales and benchmark domains. Structured tasks such as mathematical reasoning and code generation yield higher accepted lengths than open-ended chat tasks. The performance advantage of DSpark generalizes across different model families, including both Qwen3 and Gemma4 targets.
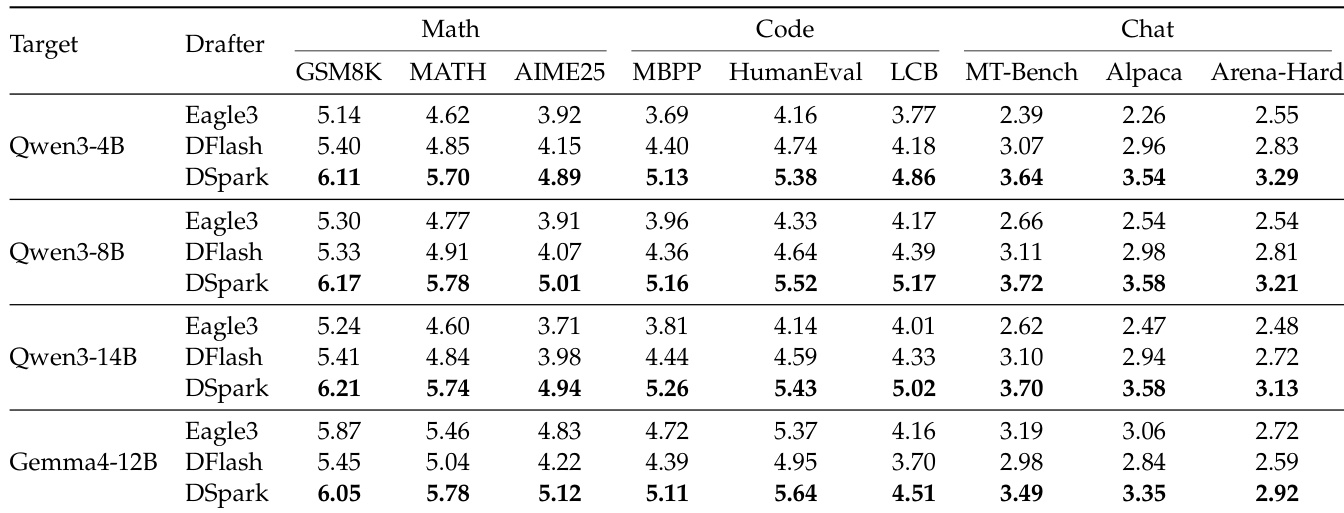
The evaluation benchmarks DSpark against autoregressive (Eagle3) and parallel (DFlash) drafters across multiple target model scales and domains, including Qwen3 and Gemma4, measuring accepted token length per decoding round. DSpark consistently yields the highest accepted lengths, outperforming both baselines on all configurations, and its advantage generalizes across model families. Structured tasks like math reasoning and code generation sustain higher acceptance rates than open-ended chat, indicating that the framework thrives in more predictable generation settings.