HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

3EED: 3차원에서 모든 것을 기반으로 하기

DetectiumFire: 시각과 언어를 연결하는 화재 이해를 위한 종합적인 다중 모달 데이터셋




























3EED: 3차원에서 모든 것을 기반으로 하기
DetectiumFire: 시각과 언어를 연결하는 화재 이해를 위한 종합적인 다중 모달 데이터셋
CHIP: 산업 환경에서 의자 6D 자세 추정을 위한 다중 센서 데이터셋
기하학적 제약을 갖춘 에이전트를 통한 공간적 추론
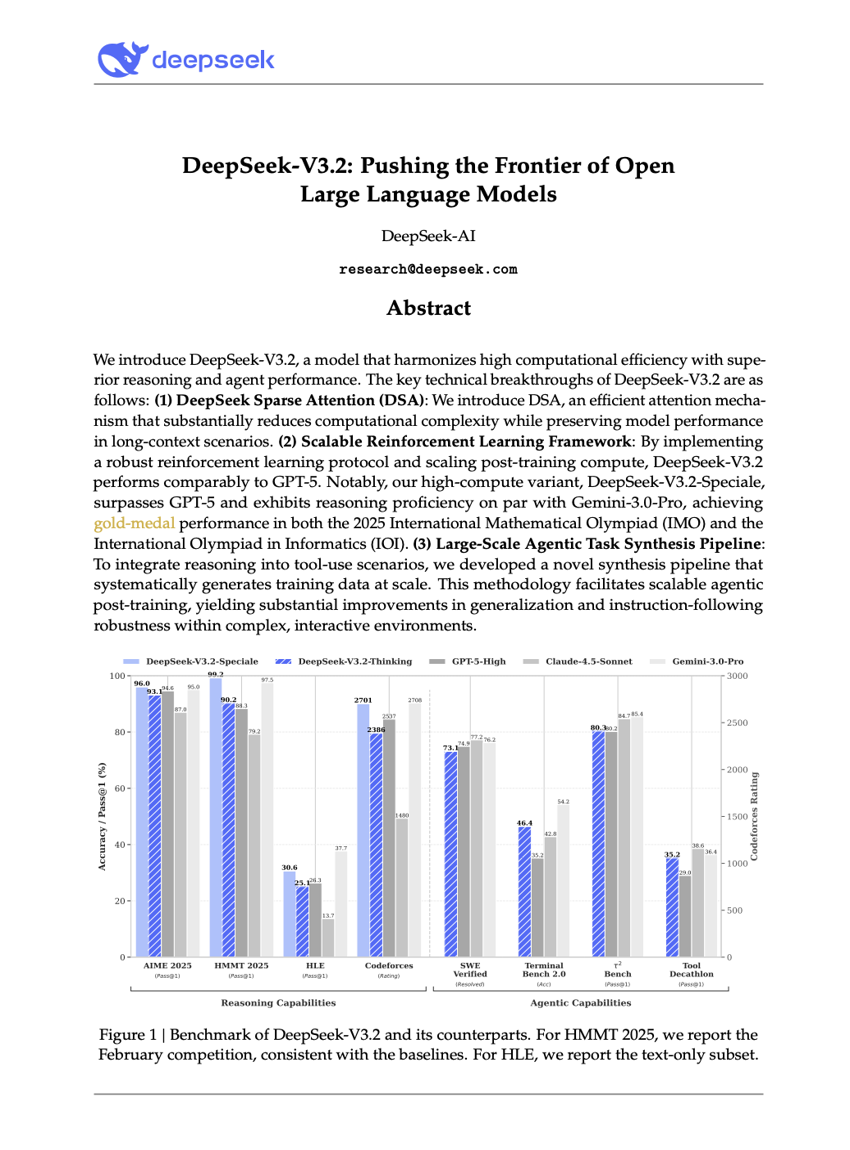
딥시크-V3.2: 오픈형 대규모 언어 모델의 경계를 넘어서
DiP: 픽셀 공간에서의 확산 모델 제어하기
통합 다중모달 모델을 위한 아키텍처 분리만으로는 충분하지 않다
스케일링된 뷰전 브리지 트랜스포머
AnyTalker: 상호작용 개선을 통한 다중 인물 대화 영상 생성의 확장
REASONEDIT: 추론 강화 이미지 편집 모델을 향해
OpenApps: 환경 변이를 시뮬레이션하여 UI 에이전트의 신뢰성 측정하기
Qwen3-VL 기술 보고서
G2VLM: 통합 3D 재구성 및 공간 추론을 갖춘 기하학적 기반 비전 언어 모델
다중기준: 다중기준 준수를 위한 다중모달 심사자 벤치마킹
MIRA: 이미지 편집을 위한 다중모달 반복 추론 에이전트
ENACT: 자기중심 상호작용의 월드 모델링을 통한 몸을 가진 인지 평가
Canvas-to-Image: 다중모달 제어를 통한 구성적 이미지 생성
비디오 생성 모델은 우수한 잠재 보상 모델이다
DeepSeekMath-V2: 자가 검증 가능한 수학적 추론을 향하여
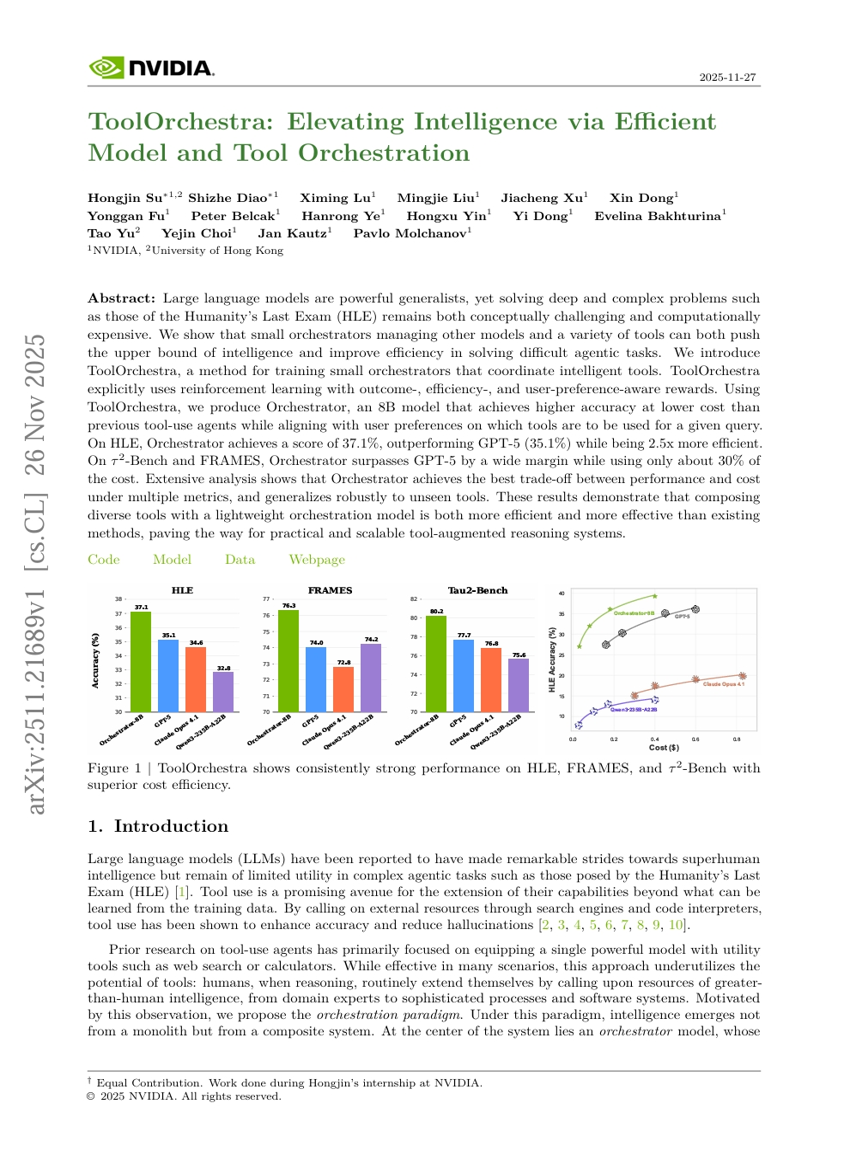
ToolOrchestra: 효율적인 모델 및 도구 오케스트레이션을 통한 지능의 고도화
시각적으로 생각하고 텍스트적으로 추론하라: ARC에서의 시각-언어 융합
하모니: 교차 작업 상호작용을 통한 오디오 및 비디오 생성의 조화
Inferix: 월드 시뮬레이션을 위한 차세대 추론 엔진으로서 블록-디퓨전 기반의 아키텍처
다중 에이전트 시스템에서의 잠재적 협업
다중모달 평가: 러시아어 기반 아키텍처
ROOT: 신경망 학습을 위한 강건한 직교화 최적화기
중첩은 강력한 신경망 스케일링을 초래한다
전도형 온라인 학습을 위한 최적의 오류 한계
강화학습이 기초 모델을 넘어서 대규모 언어 모델의 추론 능력을 진정으로 유인하는가?
확산 모델이 왜 기억하지 않는가: 훈련에서 은닉된 역동적 정규화의 역할
자기지도 학습 강화학습을 위한 1000층 네트워크: 깊이를 확장함으로써 새로운 목표 도달 능력이 가능해질 수 있다
게이트형 어텐션을 통한 대규모 언어 모델: 비선형성, 희소성 및 어텐션 싱크 없음
CHIP: 산업 환경에서 의자 6D 자세 추정을 위한 다중 센서 데이터셋
기하학적 제약을 갖춘 에이전트를 통한 공간적 추론
딥시크-V3.2: 오픈형 대규모 언어 모델의 경계를 넘어서
DiP: 픽셀 공간에서의 확산 모델 제어하기
통합 다중모달 모델을 위한 아키텍처 분리만으로는 충분하지 않다
스케일링된 뷰전 브리지 트랜스포머
AnyTalker: 상호작용 개선을 통한 다중 인물 대화 영상 생성의 확장
REASONEDIT: 추론 강화 이미지 편집 모델을 향해
OpenApps: 환경 변이를 시뮬레이션하여 UI 에이전트의 신뢰성 측정하기
Qwen3-VL 기술 보고서
G2VLM: 통합 3D 재구성 및 공간 추론을 갖춘 기하학적 기반 비전 언어 모델
다중기준: 다중기준 준수를 위한 다중모달 심사자 벤치마킹
MIRA: 이미지 편집을 위한 다중모달 반복 추론 에이전트
ENACT: 자기중심 상호작용의 월드 모델링을 통한 몸을 가진 인지 평가
Canvas-to-Image: 다중모달 제어를 통한 구성적 이미지 생성
비디오 생성 모델은 우수한 잠재 보상 모델이다
DeepSeekMath-V2: 자가 검증 가능한 수학적 추론을 향하여
ToolOrchestra: 효율적인 모델 및 도구 오케스트레이션을 통한 지능의 고도화
시각적으로 생각하고 텍스트적으로 추론하라: ARC에서의 시각-언어 융합
하모니: 교차 작업 상호작용을 통한 오디오 및 비디오 생성의 조화
Inferix: 월드 시뮬레이션을 위한 차세대 추론 엔진으로서 블록-디퓨전 기반의 아키텍처
다중 에이전트 시스템에서의 잠재적 협업
다중모달 평가: 러시아어 기반 아키텍처
ROOT: 신경망 학습을 위한 강건한 직교화 최적화기
중첩은 강력한 신경망 스케일링을 초래한다
전도형 온라인 학습을 위한 최적의 오류 한계
강화학습이 기초 모델을 넘어서 대규모 언어 모델의 추론 능력을 진정으로 유인하는가?
확산 모델이 왜 기억하지 않는가: 훈련에서 은닉된 역동적 정규화의 역할
자기지도 학습 강화학습을 위한 1000층 네트워크: 깊이를 확장함으로써 새로운 목표 도달 능력이 가능해질 수 있다
게이트형 어텐션을 통한 대규모 언어 모델: 비선형성, 희소성 및 어텐션 싱크 없음