HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

DAComp: 데이터 지능 생애 주기 전반에 걸친 데이터 에이전트 평가

라이브 아바타: 무한 길이의 실시간 오디오 기반 아바타 생성

























DAComp: 데이터 지능 생애 주기 전반에 걸친 데이터 에이전트 평가
라이브 아바타: 무한 길이의 실시간 오디오 기반 아바타 생성
F5-TTS: 흐름 매칭을 활용한 자연스럽고 충실한 발화를 위장하는 화자
VOccl3D: 실제 가림 상황 하에서 3D 인체 자세 및 형상 추정을 위한 비디오 벤치마크 데이터셋
알파마요-R1: 긴 꼬리 상황에서 일반화 가능한 자율주행을 위한 추론과 행동 예측의 통합
모든 것은 연결되어 있다: 테스트 시간 기억화, 주의 집중 편향, 유지, 온라인 최적화를 아우르는 여정
텍스트-시각 생성에서 추론 시스템 확장에 대한 프롬프트 설계 재고
테스트 시각적-언어-행동 모델의 안티-탐색을 위한 안내: 테스트 시스케일링 접근법
OneThinker: 이미지 및 비디오를 위한 통합 추론 모델
ViDiC: 비디오 차이 설명 생성
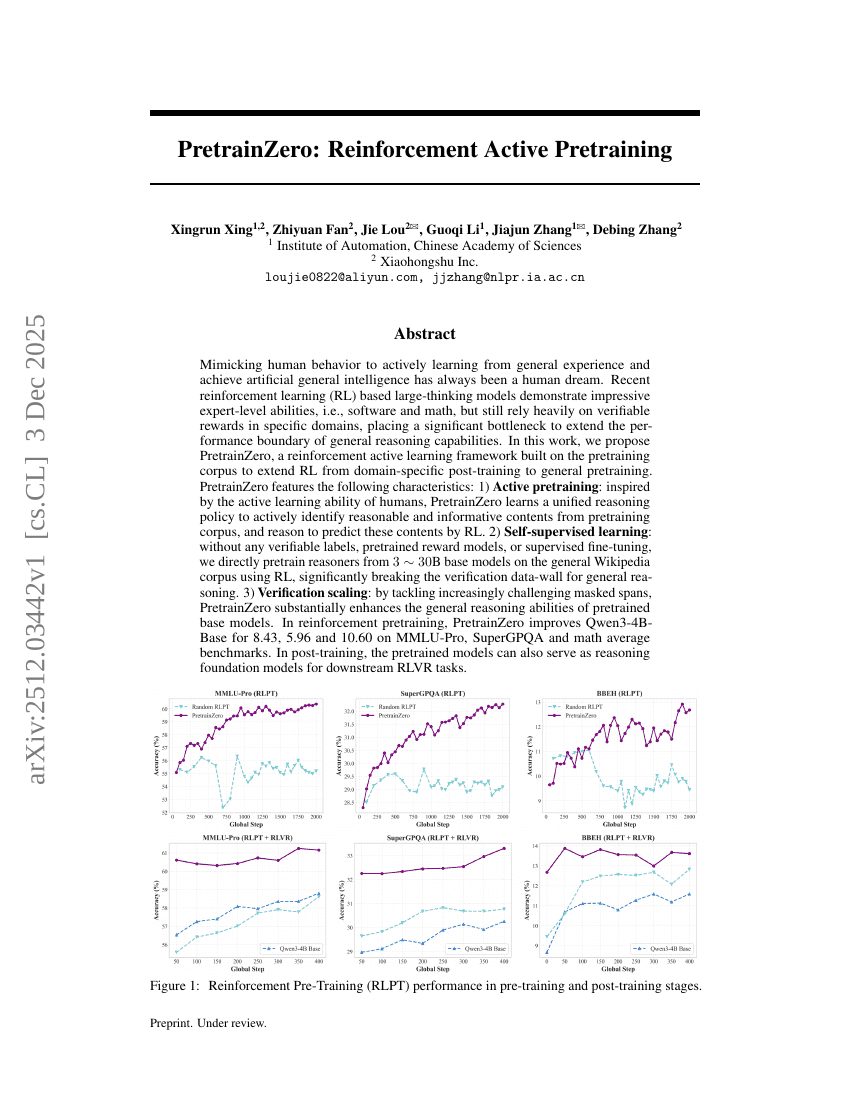
PretrainZero: 강화 학습 기반 주동 사전학습
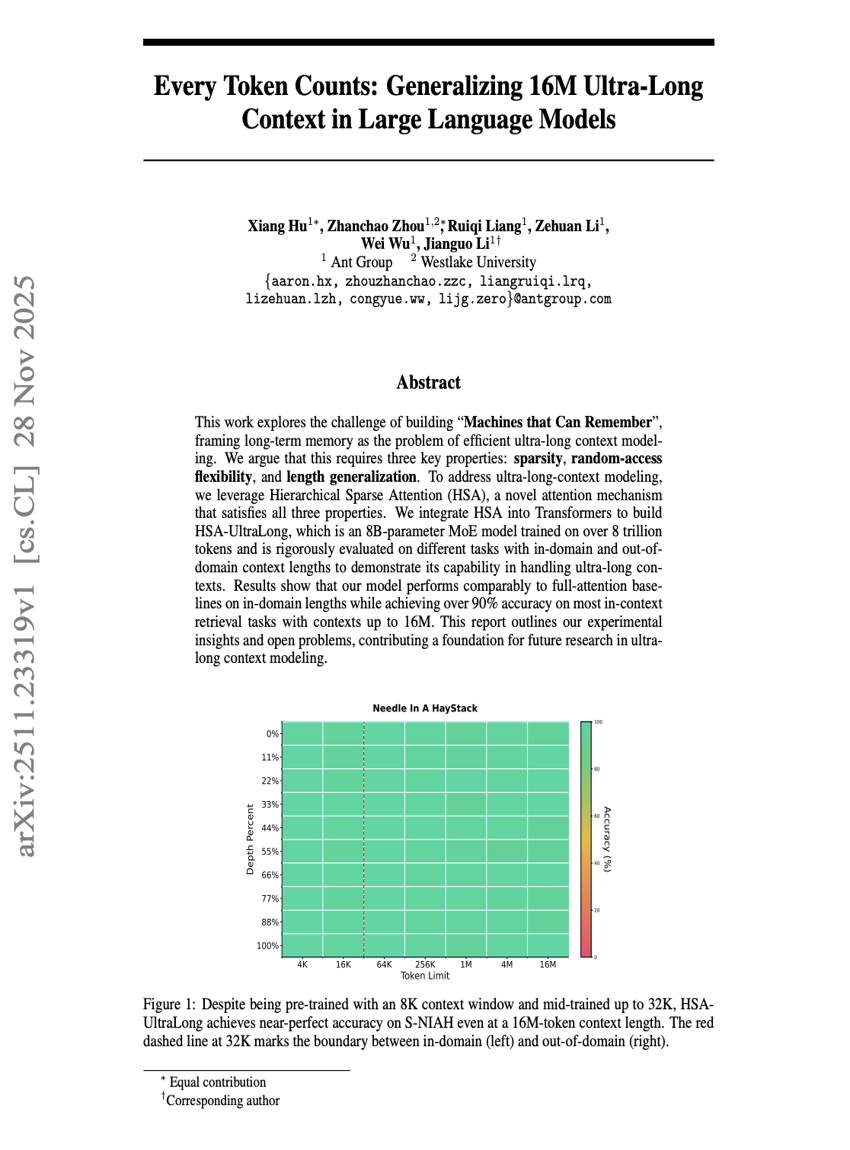
모든 토큰이 중요하다: 대규모 언어 모델에서 16M 초장거리 컨텍스트의 일반화
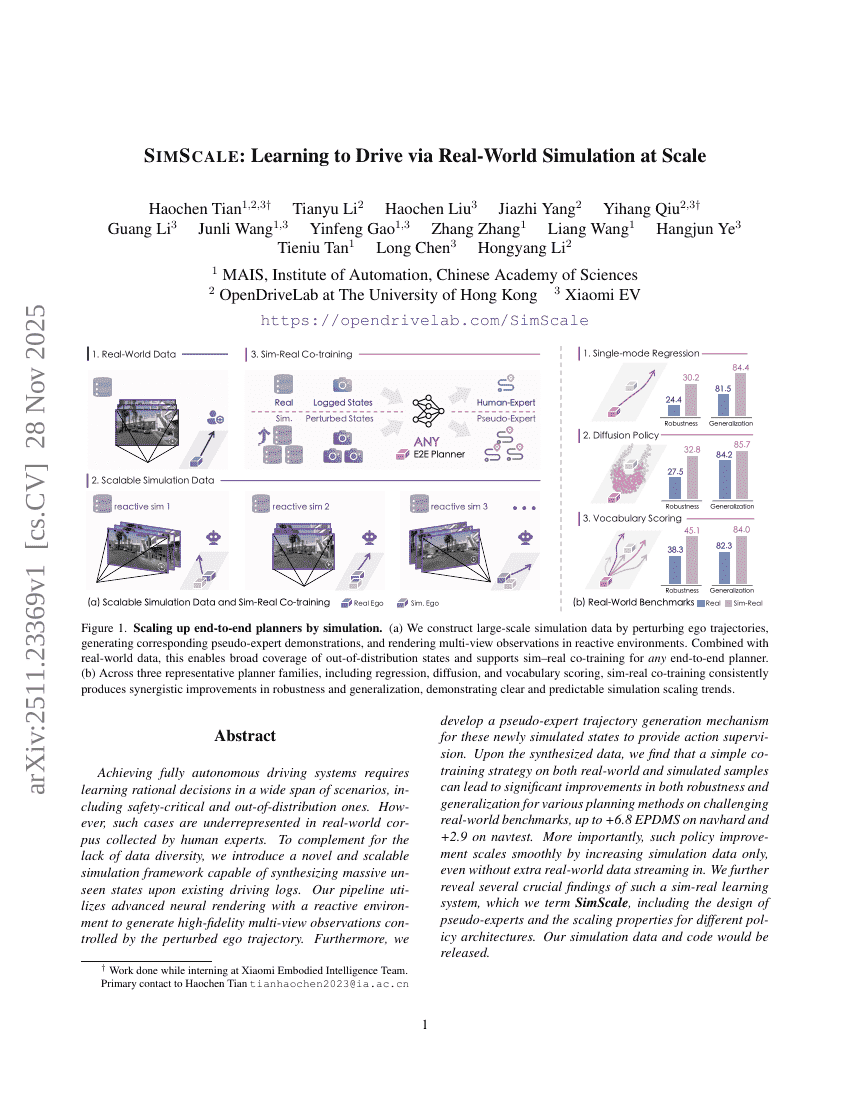
SimScale: 대규모 실세계 시뮬레이션을 통한 주행 학습
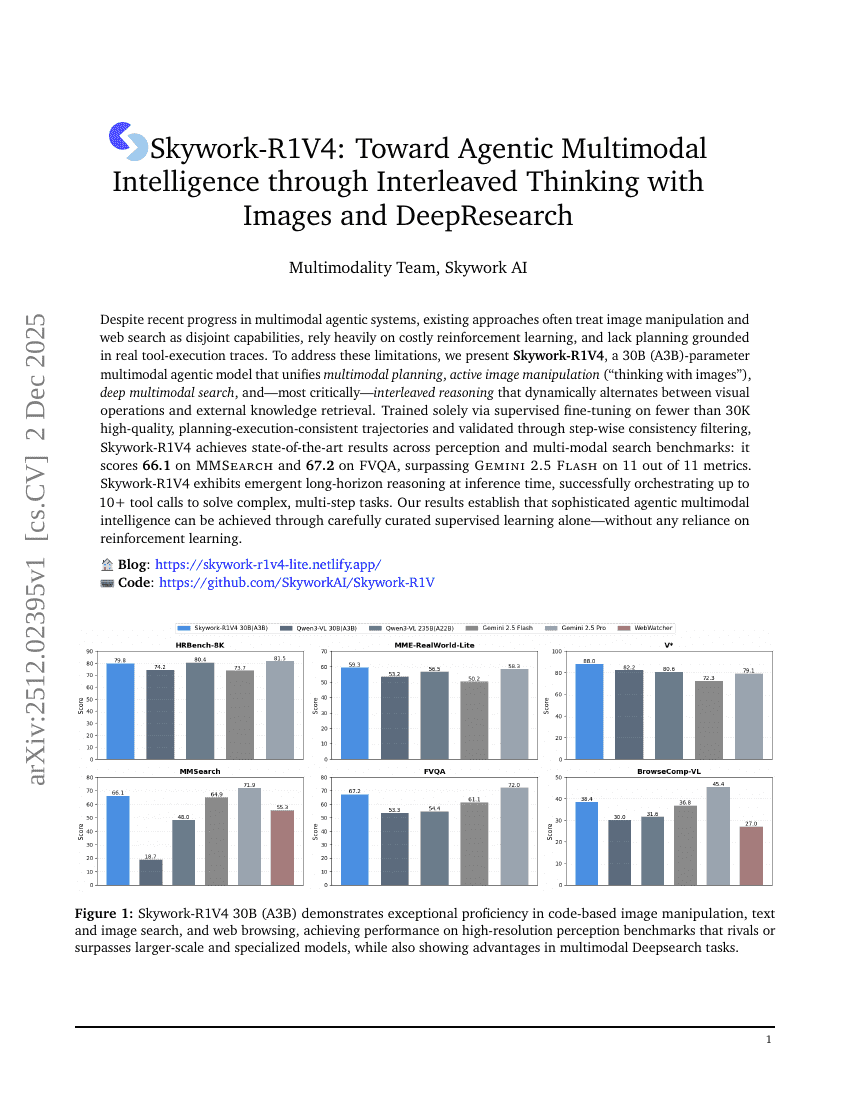
스카이워크-R1V4: 이미지와 딥리서치를 통한 혼합 사고를 통한 에이전트형 멀티모달 지능으로의 도전
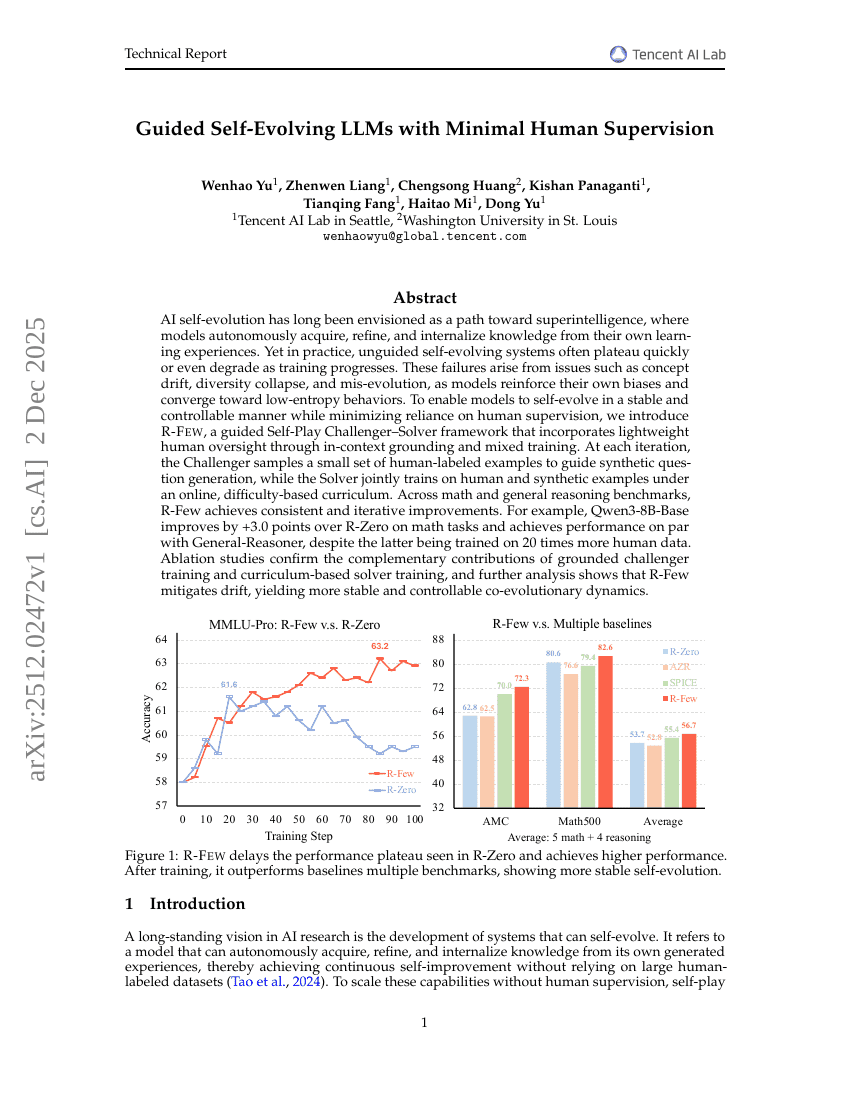
최소한의 인간 감독 하에 안내되는 자기진화형 LLMs
MultiShotMaster: 조작 가능한 다중 샷 영상 생성 프레임워크
MG-Nav: 희소 공간 기억을 통한 이중 규모 시각 탐색
일관성 비평가: 참조 기반 주의적 정렬을 통한 생성 이미지 내부 일관성 오류 보정
진정으로 유용한 딥 레이서치 에이전트에 얼마나 가까워졌는가?
LLM을 활용한 강화학습의 안정화: 공식화 및 실천 방법
Envision: 인과 세계 프로세스 통찰을 위한 통합적 이해 및 생성 평가 기준
LongVT: 내재적 도구 호출을 통한 "긴 영상으로 사고하기" 유도
코드 기반 모델에서 에이전트 및 응용 프로그램으로: 코드 인텔리전스를 위한 실용적인 가이드
물리 기반의 시공간 모델링을 통한 AI 생성 영상 탐지
Mem-α: 강화학습을 통한 메모리 구축 학습
검색 자가대전: 감독 없이 에이전트 능력의 경계를 한층 더 밀어붙이기
CudaForge: 하드웨어 피드백을 갖춘 CUDA 커널 최적화를 위한 에이전트 프레임워크
ScaleNet: 증분 파라미터를 활용한 사전 학습된 신경망의 확장
블록 어텐션의 혼합 최적화
프랙탈포렌식스: 프랙탈 워터마크를 통한 능동적 딥페이크 탐지 및 위치화
체인 오브 써스 하이재킹
인스턴스어셈블리: 인스턴스 어셈블링 어텐션을 통한 레이아웃 인지 이미지 생성
F5-TTS: 흐름 매칭을 활용한 자연스럽고 충실한 발화를 위장하는 화자
VOccl3D: 실제 가림 상황 하에서 3D 인체 자세 및 형상 추정을 위한 비디오 벤치마크 데이터셋
알파마요-R1: 긴 꼬리 상황에서 일반화 가능한 자율주행을 위한 추론과 행동 예측의 통합
모든 것은 연결되어 있다: 테스트 시간 기억화, 주의 집중 편향, 유지, 온라인 최적화를 아우르는 여정
텍스트-시각 생성에서 추론 시스템 확장에 대한 프롬프트 설계 재고
테스트 시각적-언어-행동 모델의 안티-탐색을 위한 안내: 테스트 시스케일링 접근법
OneThinker: 이미지 및 비디오를 위한 통합 추론 모델
ViDiC: 비디오 차이 설명 생성
PretrainZero: 강화 학습 기반 주동 사전학습
모든 토큰이 중요하다: 대규모 언어 모델에서 16M 초장거리 컨텍스트의 일반화
SimScale: 대규모 실세계 시뮬레이션을 통한 주행 학습
스카이워크-R1V4: 이미지와 딥리서치를 통한 혼합 사고를 통한 에이전트형 멀티모달 지능으로의 도전
최소한의 인간 감독 하에 안내되는 자기진화형 LLMs
MultiShotMaster: 조작 가능한 다중 샷 영상 생성 프레임워크
MG-Nav: 희소 공간 기억을 통한 이중 규모 시각 탐색
일관성 비평가: 참조 기반 주의적 정렬을 통한 생성 이미지 내부 일관성 오류 보정
진정으로 유용한 딥 레이서치 에이전트에 얼마나 가까워졌는가?
LLM을 활용한 강화학습의 안정화: 공식화 및 실천 방법
Envision: 인과 세계 프로세스 통찰을 위한 통합적 이해 및 생성 평가 기준
LongVT: 내재적 도구 호출을 통한 "긴 영상으로 사고하기" 유도
코드 기반 모델에서 에이전트 및 응용 프로그램으로: 코드 인텔리전스를 위한 실용적인 가이드
물리 기반의 시공간 모델링을 통한 AI 생성 영상 탐지
Mem-α: 강화학습을 통한 메모리 구축 학습
검색 자가대전: 감독 없이 에이전트 능력의 경계를 한층 더 밀어붙이기
CudaForge: 하드웨어 피드백을 갖춘 CUDA 커널 최적화를 위한 에이전트 프레임워크
ScaleNet: 증분 파라미터를 활용한 사전 학습된 신경망의 확장
블록 어텐션의 혼합 최적화
프랙탈포렌식스: 프랙탈 워터마크를 통한 능동적 딥페이크 탐지 및 위치화
체인 오브 써스 하이재킹
인스턴스어셈블리: 인스턴스 어셈블링 어텐션을 통한 레이아웃 인지 이미지 생성