HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

스타일 하나가 코드 하나보다 더 가치 있다: 이산 스타일 공간을 통한 코드에서 스타일 이미지 생성 해제

AraLingBench: 대규모 언어 모델의 아랍어 언어 능력을 평가하기 위한 인간 주석 기반 벤치마크


























스타일 하나가 코드 하나보다 더 가치 있다: 이산 스타일 공간을 통한 코드에서 스타일 이미지 생성 해제
AraLingBench: 대규모 언어 모델의 아랍어 언어 능력을 평가하기 위한 인간 주석 기반 벤치마크
Think-at-Hard: 추론 기능 향상을 위한 선택적 잠재 반복 기법
HumanSense: 다중모달 인지에서 출발하여 추론을 통한 공감적이고 맥락 인지형 응답으로
CamCloneMaster: 영상 생성을 위한 기준 기반 카메라 제어 가능하게 하기
EditScore: 이미지 편집을 위한 온라인 강화학습을 고정밀 보상 모델링을 통해 열기
InteractMove: 3차원 장면에서 이동 가능한 물체를 활용한 텍스트 제어형 인간-물체 상호작용 생성
웹코치: 세션 간 기억 안내를 통한 자가진화형 웹 에이전트
신뢰하기를 배우기: 순차적 의사결정에서 제안자 신뢰성의 변화에 대한 베이지안 적응
GroupRank: 강화학습에 의해 구동되는 그룹 기반 재정렬 프레임워크
MMaDA-Parallel: 사고 인식 편집 및 생성을 위한 다중모달 대규모 확산 언어 모델
TiViBench: 영상 생성 모델을 위한 Think-in-Video 추론 평가
Part-X-MLLM: 부분 인지형 3D 다중모달 대규모 언어 모델
Uni-MoE-2.0-Omni: 고급 MoE, 훈련 및 데이터를 활용한 언어 중심 옴니모달 대규모 모델의 확장
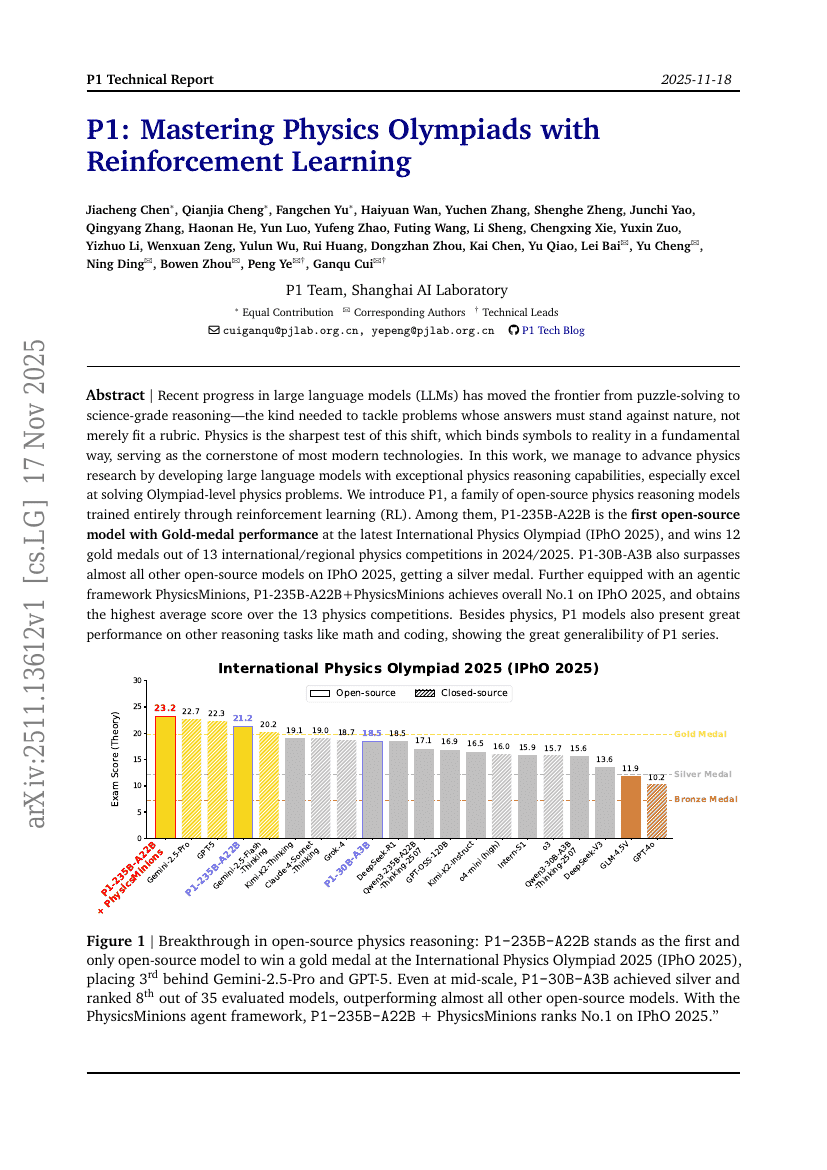
P1: 강화학습을 통한 물리올림피아드 정복
랜슬로트: 완전 동형 암호화 내에서 효율적이고 프라이버시를 보장하는 바지안-저항성 분산 학습을 위한 방향
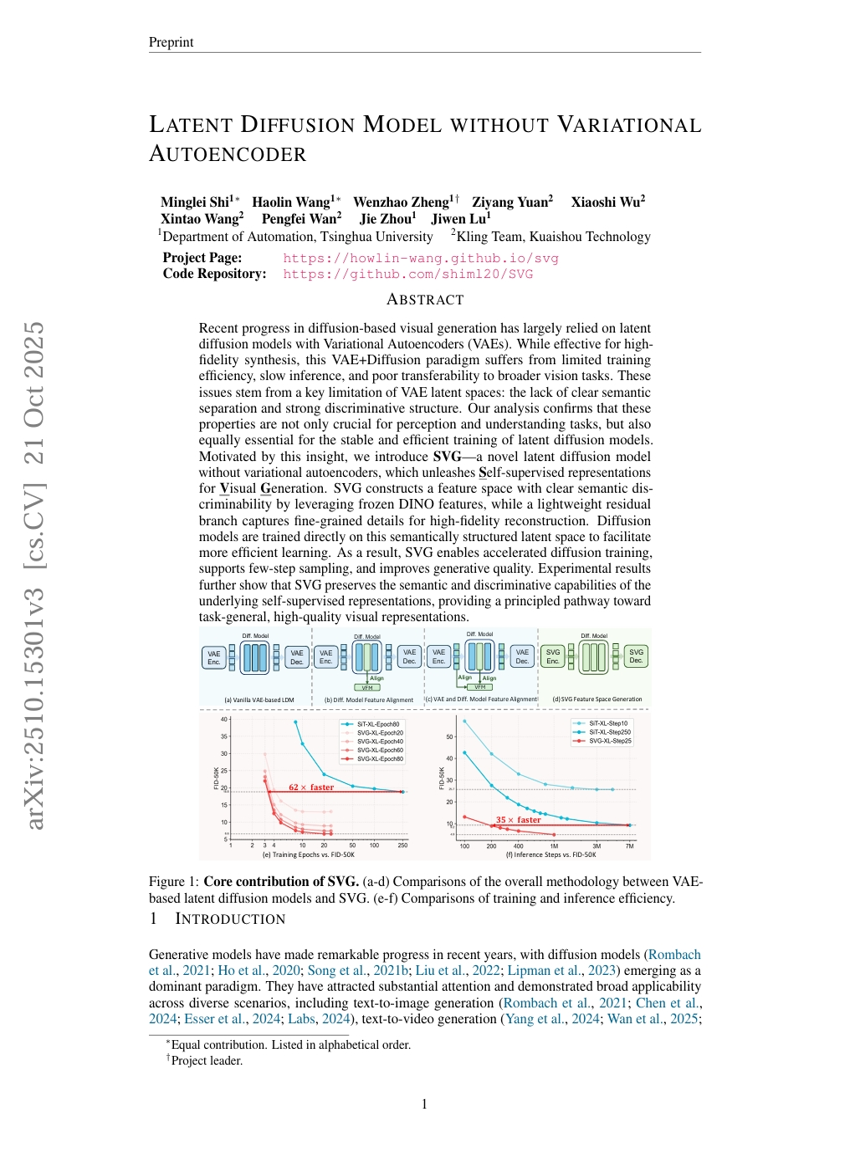
변분 오토인코더 없이 사용하는 잠재 확산 모델
RewardMap: 미세한 시각적 추론에서 희소 보상 문제에 다가가기 위한 다단계 강화 학습을 통한 접근
ReinFlow: 온라인 강화 학습을 통한 플로우 매칭 정책의 피니어 투닝
이성 능력에 대한 음성 평가: 모달리티 유도 성과 격차 진단
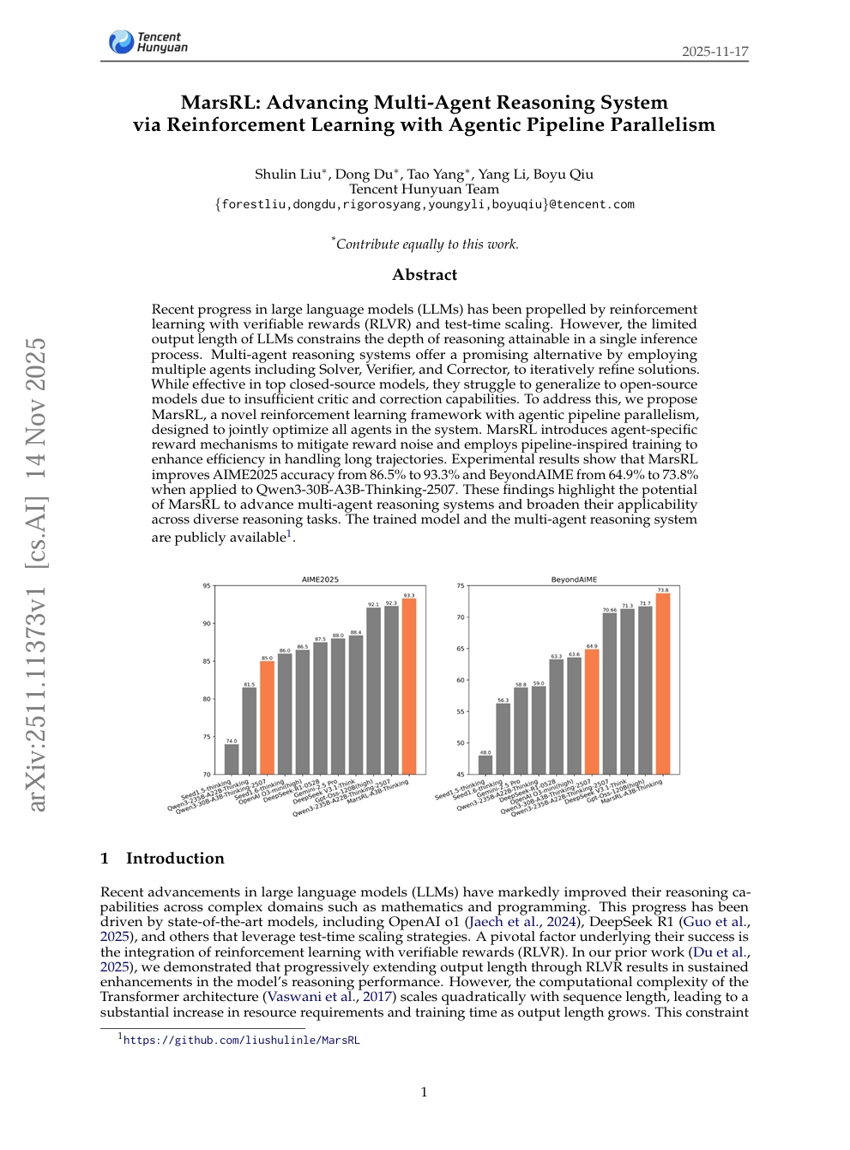
MarsRL: 에이전트형 파이프라인 병렬화를 통한 강화 학습을 통한 다중 에이전트 추론 시스템의 발전
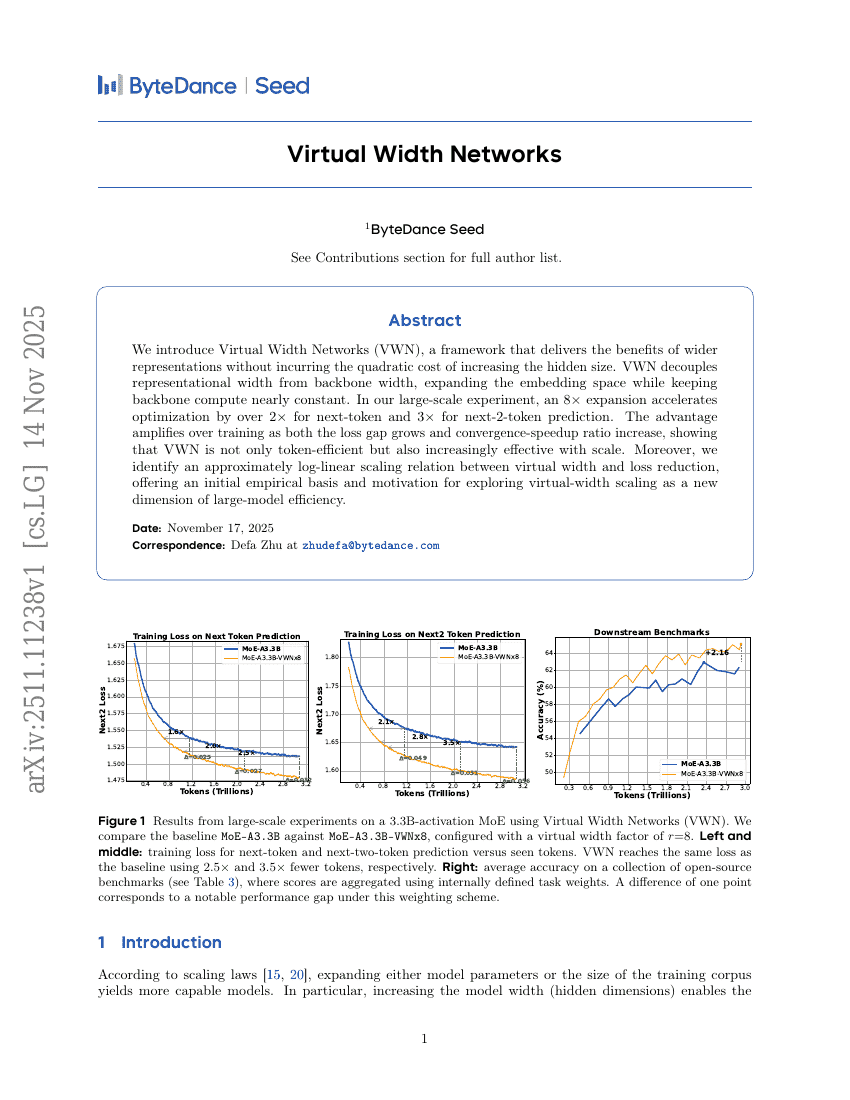
가상 폭 네트워크
AIonopedia: 이온 액체 탐사에 대한 다중 모달 학습을 조율하는 LLM 에이전트
UI2CodeextN: 테스트 시각적 확장 가능한 인터랙티브 UI-to-Code 생성을 위한 시각 언어 모델
GGBench: 통합 다중모달 모델을 위한 기하학적 생성 추론 벤치마크
WEAVE: 맥락 내 혼합 이해 및 생성의 잠재력 해방과 벤치마킹
DoPE: 복원 회전 위치 임베딩
BRFL: 블록체인 기반의 바이잔트 강건 편제 학습 모델
지수-가우시안 혼합망을 통한 영상 시청 시간 예측을 위한 다중 과립도 분포 모델링
SAC 플로우: 속도 재파라미터화된 순차 모델링을 통한 샘플 효율적인 기반 플로우 정책 강화 학습
특징 최적 일치를 통한 폐쇄형 MLLM에 대한 적대적 공격
Hail to the Thief: 분산형 GRPO에서의 공격 및 방어 탐구
Think-at-Hard: 추론 기능 향상을 위한 선택적 잠재 반복 기법
HumanSense: 다중모달 인지에서 출발하여 추론을 통한 공감적이고 맥락 인지형 응답으로
CamCloneMaster: 영상 생성을 위한 기준 기반 카메라 제어 가능하게 하기
EditScore: 이미지 편집을 위한 온라인 강화학습을 고정밀 보상 모델링을 통해 열기
InteractMove: 3차원 장면에서 이동 가능한 물체를 활용한 텍스트 제어형 인간-물체 상호작용 생성
웹코치: 세션 간 기억 안내를 통한 자가진화형 웹 에이전트
신뢰하기를 배우기: 순차적 의사결정에서 제안자 신뢰성의 변화에 대한 베이지안 적응
GroupRank: 강화학습에 의해 구동되는 그룹 기반 재정렬 프레임워크
MMaDA-Parallel: 사고 인식 편집 및 생성을 위한 다중모달 대규모 확산 언어 모델
TiViBench: 영상 생성 모델을 위한 Think-in-Video 추론 평가
Part-X-MLLM: 부분 인지형 3D 다중모달 대규모 언어 모델
Uni-MoE-2.0-Omni: 고급 MoE, 훈련 및 데이터를 활용한 언어 중심 옴니모달 대규모 모델의 확장
P1: 강화학습을 통한 물리올림피아드 정복
랜슬로트: 완전 동형 암호화 내에서 효율적이고 프라이버시를 보장하는 바지안-저항성 분산 학습을 위한 방향
변분 오토인코더 없이 사용하는 잠재 확산 모델
RewardMap: 미세한 시각적 추론에서 희소 보상 문제에 다가가기 위한 다단계 강화 학습을 통한 접근
ReinFlow: 온라인 강화 학습을 통한 플로우 매칭 정책의 피니어 투닝
이성 능력에 대한 음성 평가: 모달리티 유도 성과 격차 진단
MarsRL: 에이전트형 파이프라인 병렬화를 통한 강화 학습을 통한 다중 에이전트 추론 시스템의 발전
가상 폭 네트워크
AIonopedia: 이온 액체 탐사에 대한 다중 모달 학습을 조율하는 LLM 에이전트
UI2CodeextN: 테스트 시각적 확장 가능한 인터랙티브 UI-to-Code 생성을 위한 시각 언어 모델
GGBench: 통합 다중모달 모델을 위한 기하학적 생성 추론 벤치마크
WEAVE: 맥락 내 혼합 이해 및 생성의 잠재력 해방과 벤치마킹
DoPE: 복원 회전 위치 임베딩
BRFL: 블록체인 기반의 바이잔트 강건 편제 학습 모델
지수-가우시안 혼합망을 통한 영상 시청 시간 예측을 위한 다중 과립도 분포 모델링
SAC 플로우: 속도 재파라미터화된 순차 모델링을 통한 샘플 효율적인 기반 플로우 정책 강화 학습
특징 최적 일치를 통한 폐쇄형 MLLM에 대한 적대적 공격
Hail to the Thief: 분산형 GRPO에서의 공격 및 방어 탐구