Command Palette
Search for a command to run...
Nemotron-Math: Multi-Mode Supervision을 통한 수학적 추론의 효율적인 Long-Context Distillation
Nemotron-Math: Multi-Mode Supervision을 통한 수학적 추론의 효율적인 Long-Context Distillation
Wei Du Shubham Toshniwal Branislav Kisacanin Sadegh Mahdavi Ivan Moshkov George Armstrong Stephen Ge Edgar Minasyan Feng Chen Igor Gitman
초록
고품질의 수학적 추론(mathematical reasoning) 감독(supervision)을 위해서는 다양한 추론 스타일, 긴 형태의 추론 과정(long-form traces), 그리고 효과적인 도구 통합 능력이 필요하지만, 기존 데이터셋들은 이러한 역량을 제한적인 형태로만 제공하고 있습니다. 본 연구에서는 gpt-oss-120b의 멀티모드 생성 능력을 활용하여, 고·중·저 단계의 다양한 추론 모드를 포함하고 각 모드별로 Python 도구 통합 추론(TIR, Tool-Integrated Reasoning) 적용 여부를 선택할 수 있는 750만 개의 솔루션 trace를 담은 대규모 수학적 추론 데이터셋인 Nemotron-Math를 소개합니다.이 데이터셋은 정교하게 선별된 85,000개의 AoPS 문제와 커뮤니티 기반의 262,000개 StackExchange-Math 문제를 통합하여, 구조화된 경시대회 과제와 다양한 실전 수학 질의를 결합하였습니다. 데이터셋의 품질을 평가하기 위해 대조 실험(controlled evaluations)을 수행한 결과, Nemotron-Math는 동일한 AoPS 문제군에서 기존의 OpenMathReasoning보다 일관되게 우수한 성능을 보였습니다. 또한, StackExchange-Math를 통합함으로써 수학 경시대회 benchmark에서의 정확도를 유지하면서도, 특히 HLE-Math에서 견고성(robustness)과 일반화(generalization) 능력을 대폭 향상시켰습니다.효율적인 long-context 학습을 지원하기 위해, 본 연구에서는 순차적 버킷 전략(sequential bucketed strategy)을 개발하였습니다. 이 전략은 전체 길이(full-length) 학습과 비교했을 때 정확도의 유의미한 손실 없이 128K context-length fine-tuning 속도를 2~3배 가속화합니다. 감독 데이터의 확장성(scalability)을 검증하기 위해 Qwen3-8B 및 Qwen3-30B-A3B 모델을 대상으로 추가 실험을 진행하였으며, 두 모델 모두 본 연구의 full context 학습 레시피 하에서 유사한 최종 정확도에 수렴함을 확인하였습니다.종합적으로 Nemotron-Math는 다양하고 고품질이며 확장 가능한 추론 감독을 제공합니다. 이를 통해 Python TIR을 적용한 Qwen3-8B 및 Qwen3-30B-A3B 모델 모두 AIME 2024/2025에서 100% maj@16 정확도를 달성하는 등 최첨단(state-of-the-art) 성능을 구현할 수 있습니다.
One-sentence Summary
By leveraging multi-mode supervision from gpt-oss-120b, the researchers introduce Nemotron-Math, a large-scale dataset of 7.5M solution traces featuring diverse reasoning modes and Python tool-integrated reasoning (TIR) that utilizes a sequential bucketed strategy to accelerate 128K context-length fine-tuning while enabling Qwen3-8B and Qwen3-30B-A3B to achieve state-of-the-art performance, including 100% maj@16 accuracy on AIME 2024/2025.
Key Contributions
- The paper introduces Nemotron-Math, a large-scale mathematical reasoning dataset comprising 7.5 million solution traces that feature diverse reasoning modes and both Python-free and Python-integrated tool-integrated reasoning (TIR) settings.
- This work integrates 85,000 curated AoPS problems with 262,000 community-sourced StackExchange-Math problems to provide a combination of structured competition tasks and diverse real-world queries.
- The researchers develop a sequential bucketed strategy for efficient long-context training that accelerates 128K context-length fine-tuning by 2 to 3 times without significant accuracy loss.
Introduction
Developing robust mathematical reasoning in large language models requires high-quality supervision characterized by diverse reasoning styles, long-form traces, and effective tool integration. While existing datasets have scaled mathematical chain-of-thought supervision, they often provide shallow solution traces with limited multi-step deduction or rely on single-mode generation that lacks diversity in reasoning depth and tool-usage behavior. The authors introduce Nemotron-Math, a large-scale dataset featuring 7.5M solution traces across high, medium, and low reasoning modes, provided both with and without Python tool-integrated reasoning. To facilitate efficient training, they also implement a sequential bucketed strategy that accelerates 128K context-length fine-tuning by 2 to 3 times without sacrificing accuracy.
Dataset
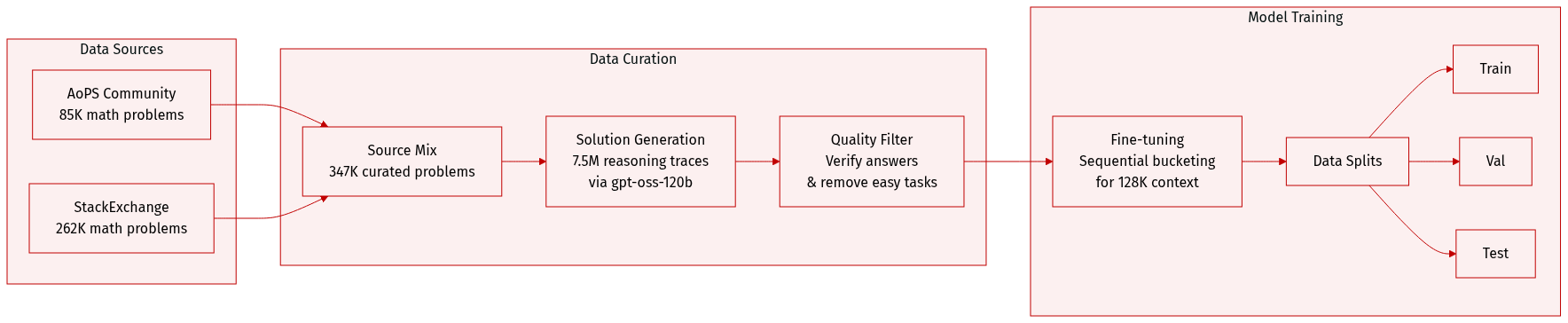
-
Dataset Composition and Sources: The authors constructed Nemotron-Math by integrating mathematical problems from two primary sources: the AoPS community (via the OpenMathReasoning dataset) and community-driven platforms including Math Stack Exchange and MathOverflow. The final dataset contains 347K curated problems and approximately 7.5M reasoning traces.
-
Subset Details:
- AoPS Source: This subset consists of 85K challenging questions spanning algebra, geometry, number theory, and combinatorics. The authors initially collected 175K items but filtered out theorem-proving tasks and easy questions (those with a pass rate above 0.8 in low-reasoning modes) to ensure high quality and nontriviality.
- StackExchange-Math Source: This subset includes 262K problems derived from Math Stack Exchange and MathOverflow. The authors applied a decontamination process to prevent overlap with public benchmarks and used Qwen2.5-32B-Instruct to filter out proof-style questions. The initial pool of 651K problems was reduced to 262K after removing easy questions.
-
Data Generation and Processing:
- Solution Generation: The authors used the gpt-oss-120b model to generate solutions across six configurations, varying between three reasoning modes (high, medium, and low) and two settings (with and without Python Tool-Integrated Reasoning, or TIR). For each configuration, eight solutions were generated per problem using different random seeds.
- Quality Control and Verification: To ensure correctness, Qwen2.5-32B-Instruct acted as an LLM-as-a-judge to compare generated answers against expected answers. The authors also used model-generated solutions to verify or replace noisy or incomplete reference answers from the original forums, utilizing a majority vote system for reliability.
- Final Filtering: Any generated solutions that failed to reach the correct expected answer were discarded, resulting in a dataset that emphasizes high-quality, successful reasoning paths.
-
Usage and Training Strategy:
- Training Splits and Mixtures: The authors conducted controlled experiments using an "AoPS-only" subset and an "AoPS+StackExchange-Math" subset (created by randomly replacing half of the AoPS examples with StackExchange-Math examples) to evaluate the impact of community-sourced data on reasoning robustness.
- Efficiency Optimization: To facilitate efficient long-context training, the authors implemented a sequential bucketed strategy. This approach allows for 128K-context fine-tuning that is 2 to 3 times faster than full joint training while maintaining nearly identical accuracy.
Method
The authors implement a supervised fine-tuning pipeline to optimize large language models, specifically focusing on the Qwen3-8B and Qwen3-30B-A3B architectures. The training process is orchestrated using the Nemo-Skills framework, which integrates NeMo-RL with a Megatron backend to manage the end-to-end workflow. This workflow encompasses several critical stages, including problem extraction, data generation, model training, and subsequent evaluation.
To enhance computational efficiency, especially when processing long-context reasoning data, the authors employ sequence packing techniques. The optimization is conducted using the AdamW optimizer with a fixed learning rate of 2×10−4. This learning rate was determined through a dedicated learning-rate sweep, and the training is performed with a global batch size of 2048 without the use of a warmup period.
A critical component of the evaluation and data validation process is the answer judgment mechanism. Because mathematical solutions can often be expressed in multiple equivalent forms, the authors utilize a specialized prompt-based approach to determine if a predicted answer matches the expected answer. This judgment module requires the model to first provide a brief reasoning explanation before delivering a final "Yes" or "No" verdict. The logic accounts for trivial simplifications, such as recognizing that 3/2 is equivalent to 1.5 or that the order of factors in an expression like 7x(x−1)(x−2) does not change its mathematical validity. However, the module is designed to remain strict regarding non-trivial differences, such as when the number of solutions in a set differs or when expressions cannot be simplified to the same form.
Experiment
The researchers evaluated the Nemotron-Math dataset and a proposed sequential bucketed training strategy using competition-style benchmarks and open-domain mathematical reasoning tasks. Experiments validate that the dataset provides superior reasoning supervision compared to existing collections, particularly when incorporating diverse reasoning depths and tool-integrated Python traces. Furthermore, the staged training approach significantly improves computational efficiency and throughput while maintaining high accuracy across various model scales and architectures.
The authors compare the effectiveness of Nemotron-Math against the OpenMathReasoning dataset and a mixed dataset using a controlled setup. Results show that models fine-tuned with Nemotron-Math consistently achieve higher accuracy across all evaluated mathematical benchmarks. Nemotron-Math outperforms both the original OpenMathReasoning and the Mixed dataset in pass@1 accuracy. The Mixed dataset, which combines both sources, shows improved performance over OpenMathReasoning alone. The performance gains from Nemotron-Math are consistent across AIME24, AIME25, and HMMT-24-25 benchmarks.

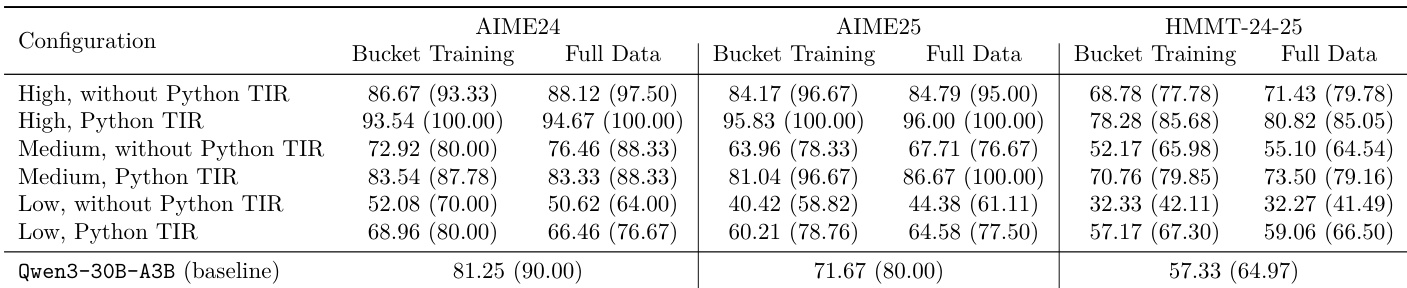
The authors evaluate a sequential bucketed training strategy that progressively expands the model context from short to long windows. This method aims to optimize training throughput and resource utilization by tailoring parallelism configurations to different sequence lengths. The sequential training approach achieves a significant speedup compared to training with a fixed full context window. Training efficiency is improved by using optimized parallelism settings for shorter context buckets. The strategy allows for more efficient processing of the majority of reasoning traces that fall within shorter context lengths.

The results compare the performance of a sequential bucketed training strategy against full-length joint training across multiple mathematical benchmarks. The findings indicate that the bucketed approach achieves accuracy levels that are highly comparable to full-length training across various reasoning modes and tool configurations. Bucketed training maintains performance levels nearly identical to full-data training for high reasoning modes both with and without Python tool-integrated reasoning. For medium and low reasoning modes, bucketed training shows competitive accuracy compared to full-length training, with some configurations even showing slight improvements. The sequential bucketed strategy effectively preserves model performance across diverse reasoning depths and tool-use settings while optimizing training efficiency.
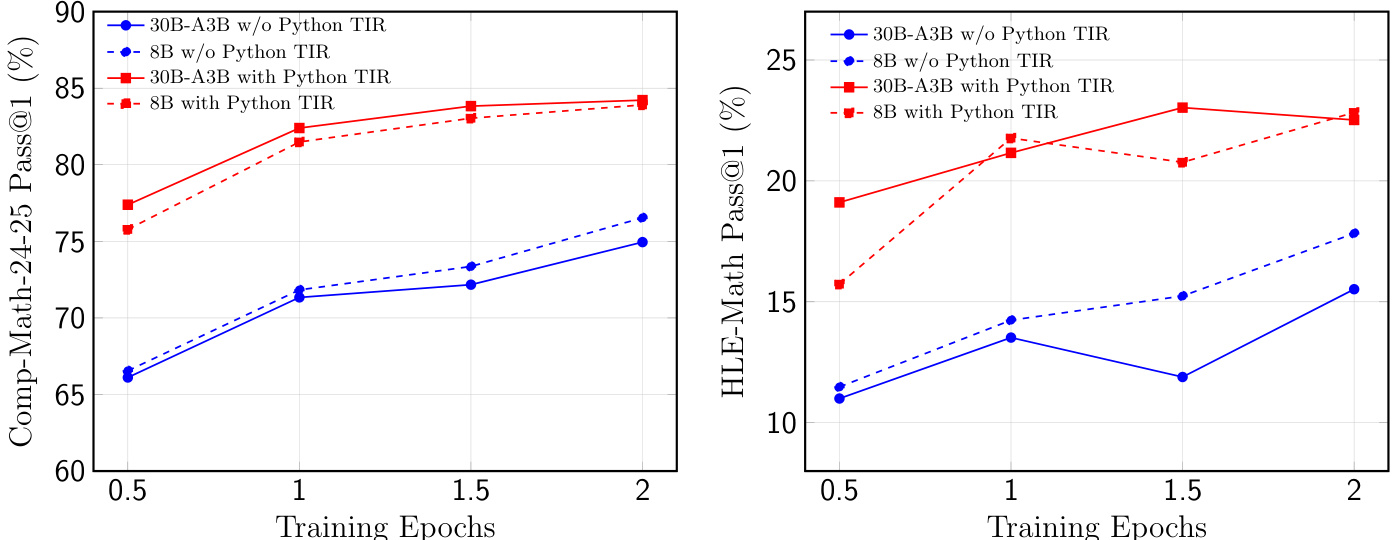
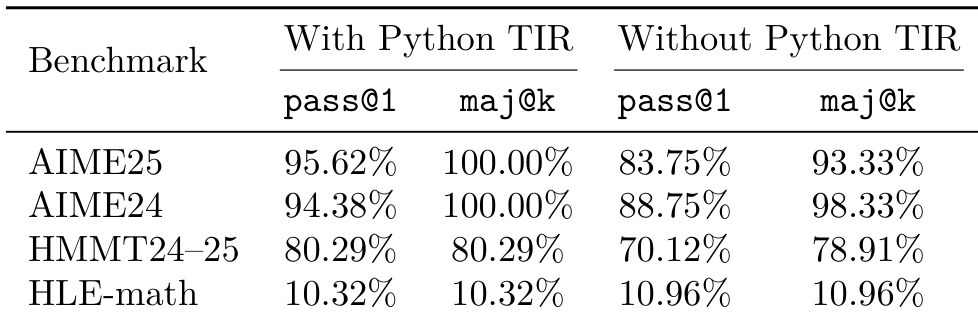
The authors evaluate model performance across various mathematical benchmarks under two distinct settings: with and without Python tool-integrated reasoning (TIR). Results show that integrating Python tools consistently improves accuracy on competition-style benchmarks such as AIME and HMMT. Models using Python TIR achieve perfect majority voting accuracy on AIME benchmarks The inclusion of Python TIR leads to substantial performance gains on AIME24, AIME25, and HMMT24-25 Performance on the HLE-math benchmark remains relatively stable regardless of Python TIR usage
The authors conduct a learning rate grid search on the Qwen3-30B-A3B model to determine the optimal hyperparameter for training across various reasoning configurations. Results show that performance generally improves as the learning rate increases toward a specific threshold, after which accuracy begins to decline. A learning rate of 2e-4 yields the highest accuracy across most reasoning modes and tool-use settings Models trained with Python tool-integrated reasoning consistently achieve higher accuracy than those without tools across all tested learning rates Higher reasoning modes generally outperform lower reasoning modes regardless of the chosen learning rate

The authors evaluate the effectiveness of the Nemotron-Math dataset, a sequential bucketed training strategy, and the integration of Python tool-integrated reasoning across various mathematical benchmarks. Results demonstrate that Nemotron-Math consistently improves accuracy over existing datasets, while the bucketed training approach significantly enhances efficiency without sacrificing model performance. Furthermore, integrating Python tools provides substantial gains in competition-style reasoning, and hyperparameter tuning identifies an optimal learning rate to maximize these performance benefits.