Command Palette
Search for a command to run...
LFM2 기술 보고서
LFM2 기술 보고서
vLLM+Open WebUI를 사용하여 LFM2.5-1.2B-Thinking 배포하기
초록
우리는 효율적인 디바이스 내 배포와 뛰어난 작업 수행 능력을 갖춘, 액체 기반 모델(Liquid Foundation Models)의 새로운 패밀리인 LFM2를 제안한다. 엣지 환경에서 지연 시간과 메모리 제약 조건 하에서 하드웨어-인-더-루프 아키텍처 탐색 기법을 활용하여, 게이트된 단기 컨볼루션과 소수의 그룹화된 쿼리 어텐션 블록을 결합한 컴팩트한 하이브리드 백본을 도출하였다. 이 구조는 유사한 크기의 모델 대비 CPU에서 프리필(pre-fill) 및 디코딩 속도를 최대 2배 빠르게 구현한다. LFM2 패밀리는 3.5억83억 파라미터 규모를 커버하며, 밀도 모델(3.5억, 7억, 12억, 26억)과 믹스처 오브 엑스퍼트(MoE) 변형 모델(총 83억 파라미터, 활성 파라미터 15억)을 포함하며, 모든 모델은 32K 길이의 컨텍스트를 지원한다.LFM2의 학습 파이프라인은 지원 불일치를 방지하기 위해 온도 조절된, 분리된 Top-K 지식 전달(知識傳達, knowledge distillation) 목적 함수를 포함하며, 난이도 순서로 정렬된 데이터를 활용한 커리큘럼 학습과 함께, 감독적 미세조정, 길이 정규화된 선호도 최적화, 모델 병합을 포함하는 3단계 후처리 훈련 절차를 수립하였다. 1012조 토큰으로 사전 훈련된 LFM2 모델은 다양한 벤치마크에서 뛰어난 성능을 보이며, 예를 들어 LFM2-2.6B는 IFEval에서 79.56%, GSM8K에서 82.41%의 성능을 기록하였다.또한 다중모달 및 검색 기능을 지원하는 변형 모델도 개발하였다. LFM2-VL은 시각-언어 작업을 위한 모델로, 토큰 효율적인 시각 처리를 통해 정확도와 지연 시간 간의 조절 가능한 트레이드오프를 제공한다. LFM2-Audio는 음성 입력과 출력 경로를 분리하여, 크기가 3배 큰 모델과 경쟁 가능한 실시간 음성-음성 상호작용을 가능하게 한다. LFM2-ColBERT는 쿼리와 문서에 대한 저지연 인코더를 제공하여, 다국어 환경에서도 고성능 검색을 구현할 수 있다.모든 LFM2 모델은 오픈 웨이트(open weights)와 ExecuTorch, 이 웹 URL, vLLM을 위한 배포 패키지와 함께 공개되어 있으며, 빠르고 메모리 효율적인 추론이 요구되는 엣지 응용 분야에서 실용적인 기반 모델로 활용될 수 있다.
One-sentence Summary
The Liquid AI Team introduces LFM2, a family of edge-optimized foundation models featuring a hardware-in-the-loop co-designed hybrid backbone with gated short convolutions and sparse grouped-query attention, enabling up to 2× faster prefill and decode on CPUs while maintaining strong task performance across 350M–8.3B parameters; the models leverage a tempered, decoupled Top-K distillation objective and a three-stage post-training pipeline for enhanced small-model quality, with extensions to multimodal (LFM2-VL, LFM2-Audio) and retrieval (LFM2-ColBERT) tasks, all released with open weights and deployment support for ExecuTorch, llama.cpp, and vLLM, making them practical for on-device applications requiring low-latency, memory-efficient inference.
Key Contributions
-
LFM2 introduces an edge-first architecture co-designed for on-device deployment, featuring a minimal hybrid backbone of input-aware gated convolutions and grouped-query attention (GQA), optimized via hardware-in-the-loop search to balance quality, latency, and memory under strict device constraints across CPUs and heterogeneous NPUs.
-
The LFM2 training pipeline includes a 10–12T token pre-training phase with long-context mid-training and a novel tempered, decoupled Top-K distillation objective that improves small-model performance without support mismatch, followed by a three-stage post-training process that enhances robustness and downstream accuracy.
-
LFM2 achieves strong efficiency-accuracy trade-offs on-device, with dense models (350M–2.6B) showing up to ~2× speedup in prefill and decode latency over comparable baselines on CPUs, while the 8.3B MoE variant delivers 3–4B-class performance with only ~1.5B active parameters, and supports native multimodal (vision, audio) and retrieval capabilities.
Introduction
The authors leverage the growing demand for on-device generative AI in applications like voice assistants, local copilots, and agentic workflows, where strict latency, memory, and energy constraints on CPUs and NPUs make cloud-based inference impractical. Prior work has focused on large-scale models optimized for datacenter deployment, leaving a gap in efficient, high-quality small models tailored for edge environments. To address this, the authors introduce LFM2, a second-generation family of Liquid Foundation Models co-designed from architecture to training for edge-first performance. Their key contribution is a hardware-in-the-loop optimized hybrid backbone combining gated convolutions and grouped-query attention, enabling dense and MoE models (350M–8.3B active parameters) to achieve 2× faster prefill and decode speeds on CPUs while maintaining strong accuracy. The framework also includes efficient pre-training with a decoupled Top-K distillation objective, a three-stage post-training pipeline, and native multimodal variants for vision, audio, and retrieval—all with open weights and deployment support across major edge runtimes.
Dataset

-
The LFM2 dense models are pre-trained on a mixed dataset composed of approximately 75% English text, 20% multilingual text, and 5% code. The multilingual component prioritizes Japanese, Arabic, Korean, Spanish, French, and German, with additional support for Chinese, Italian, and Portuguese. The MoE model LFM2-8B-A1B uses a similar mixture but with a stronger emphasis on code—60% English, 25% multilingual, and 15% code—where 50% of code examples are trained using a fill-in-the-middle (FIM) objective.
-
The dense LFM2 models are pre-trained for 10 trillion tokens at a 4,096-token context length, followed by a mid-training phase on 1 trillion higher-quality tokens with a 32,768-token context window and accelerated learning-rate decay. The LFM2-8B-A1B model follows the same two-stage process but is pre-trained for 12 trillion tokens initially.
-
Supervised Fine-Tuning (SFT) data consists of 5.39 million samples for the 350M to 2.6B models and 9.24 million for the 8B-A1B model, drawing from 67 and 79 curated sources respectively. These include open-source datasets, licensed data, and synthetic data optimized for on-device deployment. The corpus is 80% English, with the remaining 20% evenly distributed across Arabic, Chinese, French, German, Japanese, Korean, and Spanish. Multilingual content is integrated across all task categories, not isolated, to enable natural cross-lingual transfer.
-
A comprehensive data quality pipeline ensures high-fidelity training data. It begins with human evaluation of candidate datasets, followed by automated filtering using an ensemble of judge LLMs to assess factual accuracy, relevance, and helpfulness. Malformed samples, refusal patterns, and overused phrases are removed via rule-based and automated methods. Exact, near-duplicate, and semantic deduplication are applied using CMinHash and sentence embeddings with high similarity thresholds. Decontamination via n-gram and semantic matching prevents leakage from evaluation benchmarks.
-
A data-driven curriculum learning strategy ranks training examples by difficulty using a model ensemble of 12 diverse LLMs. For each item, the empirical success rate across models determines its difficulty level. A secondary model predicts this ranking based on prompt features, enabling training to progress from simpler to more complex examples.
-
For vision-language models, image preprocessing uses two regimes: single-frame for images up to 512×512 pixels, where resizing aligns with the SigLIP2 encoder’s patch grid; and dynamic tiling for larger images, which are split into 512×512 tiles (2–10 tiles), optionally with a thumbnail frame. Tiles and the thumbnail are interleaved with positional tokens and wrapped with image start/end tokens. Image token count ranges from 128 to 2,800, depending on resolution.
-
VLM training uses a multi-stage mixture: connector pre-training with diverse image-text captioning data, mid-training with broad captioning, document VQA, OCR, and fine-grained reasoning data (some re-captioned and augmented), and SFT with multi-turn, multi-image, and task-diverse vision-language interactions. Multilingual vision-language data is translated into Arabic, Chinese, French, German, Italian, Japanese, Korean, Portuguese, and Spanish to strengthen cross-lingual visual understanding. No explicit grounding supervision (e.g., bounding boxes) is used.
-
Audio training data spans transcription, language classification, text-to-speech, and audio chat instruction tuning. It includes open-source datasets like CommonVoice and LibriSpeech, as well as in-house synthetic conversations generated via proprietary pipelines. Synthetic data emphasizes paralinguistic features (pauses, fillers, intonation) and diverse user voices via voice cloning. Data is filtered using rule-based and LLM-based methods for coherence and quality. The total audio volume is ~472,000 hours per epoch, equivalent to ~21.5 billion audio embeddings.
-
The model is evaluated on a range of benchmarks: MMLU (5-shot, chat template), MMLU-Pro (5-shot CoT, system prompt), GPQA Diamond (10 runs with permuted answers), IFBench (strict/loose accuracy), Multi-IF (3-turn average), GSM8K, GSMPlus, MATH 500, MATH Level 5, MMMLU (0-shot, multilingual), and MGSM (5-shot per language). All use greedy decoding with context-appropriate token limits and consistent parsing strategies.
Method
The LFM2 architecture is designed as a family of foundation models optimized for on-device deployment, emphasizing efficiency and strong task capabilities. The core design is a minimal hybrid backbone, which is the result of a hardware-in-the-loop architecture search process. This search prioritizes downstream quality while adhering to strict device-side constraints on latency and peak memory, particularly on CPUs and heterogeneous NPUs. The resulting architecture is a decoder-only stack that combines two primary block types: a majority of inexpensive gated short convolution blocks and a minority of grouped-query attention (GQA) blocks, augmented with SwiGLU feed-forward blocks. This hybrid design is selected because it achieves the best quality–latency–memory trade-off, outperforming more complex hybrid architectures that include linear attention or state-space models under the same on-device performance budgets. The framework diagram illustrates the overall structure, showing the LFM2-Base model as the foundation, from which specialized variants like LFM2-VL, LFM2-Audio, and LFM2-ColBERT are derived. The LFM2-Base model itself is composed of a sequence of identical layers, each containing a gated short convolution block, a GQA block, and a SwiGLU block, arranged in a specific interleaved pattern. The model's efficiency is further enhanced by the use of pre-norm RMSNorm and RoPE with QK-Norm, which are standard components in modern transformer architectures.
The gated short convolution block is a key component of the LFM2 backbone, providing fast local mixing with excellent cache behavior on CPUs. This block operates on an input hidden sequence h∈RL×d by first applying a linear map to generate three feature vectors, B, C, and h~. It then uses element-wise multiplication to apply input-dependent gating around a depthwise 1D convolution with kernel size k. The output of the convolution is then modulated by another element-wise multiplication with C before being projected to the final output dimension. This operator is closely related to the short-range components found in other efficient sequence blocks, and the search results indicate that its local mixing capability is sufficient for most tasks when combined with a small number of global attention layers. The GQA block, which handles long-range dependencies, reduces key-value (KV) memory traffic by sharing keys and values across head groups while maintaining multi-head queries. The SwiGLU block, a position-wise multi-layer perceptron, uses a size-dependent expansion ratio chosen by the search to provide non-linear transformation. The model's tokenizer is a byte-level BPE with a 65,536-token vocabulary, designed for efficient encoding of multiple languages and structured data.
The LFM2 family includes both dense and mixture-of-experts (MoE) variants. The dense models, ranging from 350M to 2.6B parameters, are built directly from the hybrid backbone. The MoE variant, LFM2-8B-A1B, has 8.3B total parameters but only 1.5B active parameters per token, making it suitable for on-device regimes where compute per token is the primary constraint. This model retains the fast LFM2 hybrid backbone but replaces the dense MLPs in most layers with sparse MoE MLPs. For stability, the first two layers remain dense, while all subsequent layers include an MoE block. Each MoE layer has 32 experts, and the model selects the Top-k=4 experts per token using a normalized sigmoid router with adaptive routing biases for load balancing. The experts themselves are SwiGLU MLPs. This sparse architecture allows the model to achieve the quality of a 3–4B-class model at the decode cost of a 1.5B-class model.
The training pipeline for LFM2 is a multi-stage process designed for small, on-device models. It begins with pre-training on a large-scale dataset of 10–12T tokens, using a standard next-token prediction objective combined with a tempered, decoupled Top-K knowledge distillation (KD) objective. This KD objective leverages an internal version of LFM1-7B as a teacher model. To address the support mismatch that arises when distilling from a large teacher model, the authors decompose the Kullback–Leibler (KL) divergence into two terms: a binary term that matches the total probability mass assigned to the teacher's Top-K set, and a conditional KL term that matches the relative probabilities within the Top-K set. This "decoupled, tempered Top-K" objective avoids the instability of naive Top-K distillation by applying temperature only to the conditional term, preventing the support mismatch that occurs when tempering the truncated distribution over the full vocabulary. The overall loss is a balanced combination of this KD term and the standard next-token cross-entropy loss.
Following pre-training, each LFM2 checkpoint undergoes a three-stage post-training pipeline to enhance its capabilities for end-user applications. The first stage is Supervised Fine-Tuning (SFT), which uses a large general-purpose mixture of data to teach the model conversational skills, instruction following, and multi-turn coherence. The second stage is Preference Alignment, which enables efficient direct alignment on offline data, including on-policy samples generated from the SFT checkpoint. This stage employs a family of length-normalized alignment objectives, such as a generalized loss function that combines relative and absolute loss components based on the implicit reward. The third stage is Model Merging, which involves the systematic evaluation and combination of candidate models to increase robustness and optimize performance. This pipeline is designed to improve downstream capabilities relevant to end users, such as Retrieval-Augmented Generation (RAG) and function calling. The overall training taxonomy is illustrated in the framework diagram, showing the progression from a base model through SFT, alignment, and merging to a final, optimized model.
Experiment
- LFM2 models demonstrate superior inference efficiency on smartphone (Samsung Galaxy S25) and laptop (AMD Ryzen AI 9 HX 370) CPUs, achieving 1.4–3.7× higher prefill and decode throughput than similarly sized open baselines such as Qwen3, Gemma, and Llama-3.2 across multiple scales, with LFM2-8B-A1B showing 2.8–3.7× higher decode throughput than dense 4B models.
- On-device performance is validated through consistent throughput gains across 350M to 8B parameter scales, with LFM2-1.2B achieving 2.3–2.8× higher prefill and 1.7–2.2× higher decode throughput than comparable models, while maintaining competitive quality.
- LFM2 models achieve state-of-the-art performance on knowledge, instruction following, and mathematical reasoning benchmarks: LFM2-1.2B scores 74.89% on IFEval (surpassing 30% larger Qwen3-1.7B), LFM2-2.6B reaches 82.41% on GSM8K, and LFM2-8B-A1B improves by +10.6 points on MATH 500.
- LFM2-VL models outperform similarly sized open-source VLMs on multimodal benchmarks: LFM2-VL-3B scores 76.55 on SEEDBench and 71.37 on RealWorldQA, exceeds Qwen2.5-VL-3B on multilingual MMBench (+1.51) and MMB (+3.92), and maintains strong language-only performance (62.70 on MMLU).
- LFM2-Audio-1.5B achieves competitive performance in speech-to-speech chat (VoiceBench) and ASR, matching or approaching larger models like Qwen2.5-Omni-3B and Whisper, with strong real-time, low-latency suitability.
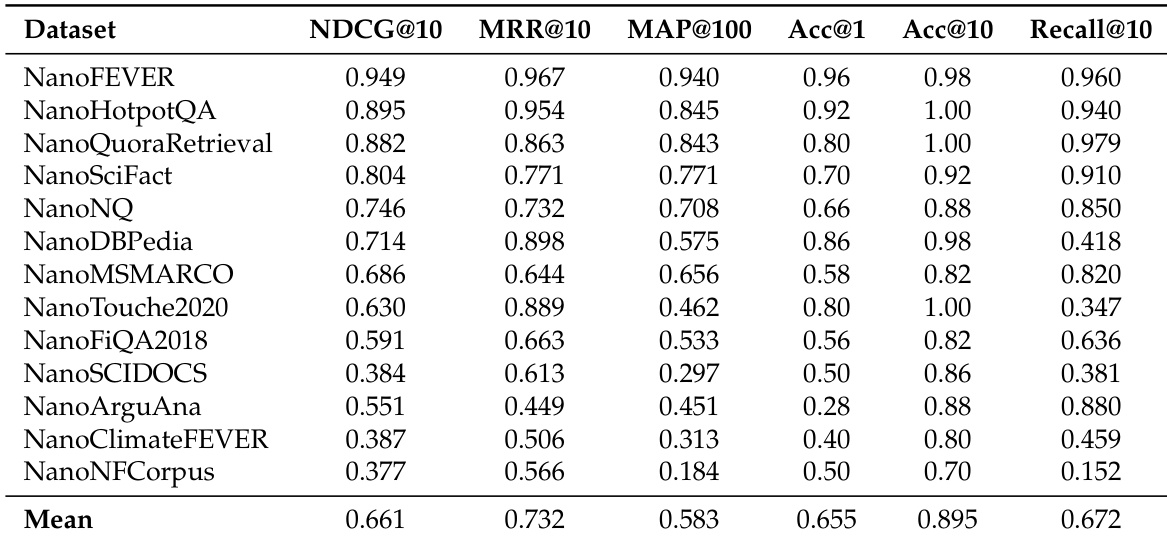
- LFM2-ColBERT-350M achieves 0.661 mean NDCG@10 on multilingual retrieval (NanoBEIR), outperforming GTE-ModernColBERT-v1 in cross-lingual transfer, with 26% smaller performance gap between English and low-resource languages (e.g., Arabic, Japanese, Korean).
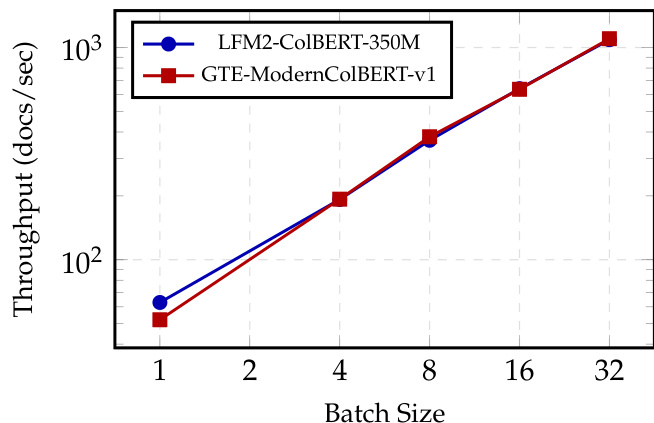
- LFM2-ColBERT-350M matches GTE-ModernColBERT-v1 in query and document encoding throughput on NVIDIA H100 GPUs despite being 2.37× larger, demonstrating high efficiency in retrieval workloads.
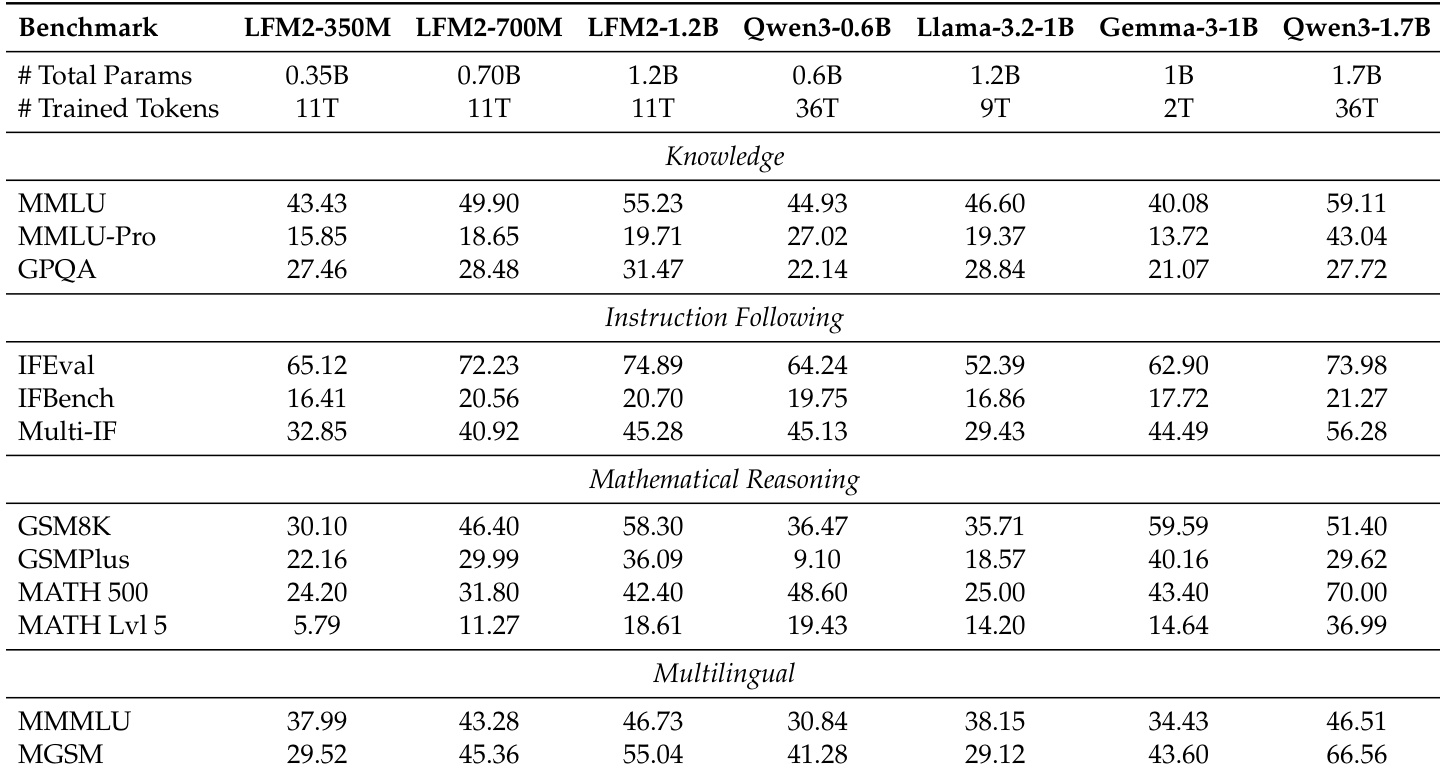
The authors use the table to compare LFM2 models with several open-source baselines across knowledge, instruction following, mathematical reasoning, and multilingual benchmarks. Results show that LFM2 models achieve competitive performance relative to their size, with LFM2-2.6B outperforming larger models like Llama-3.2-3B and SmolLM3-3B on instruction following and mathematical reasoning tasks, while LFM2-8B-A1B demonstrates strong gains in knowledge and reasoning capabilities compared to smaller variants.
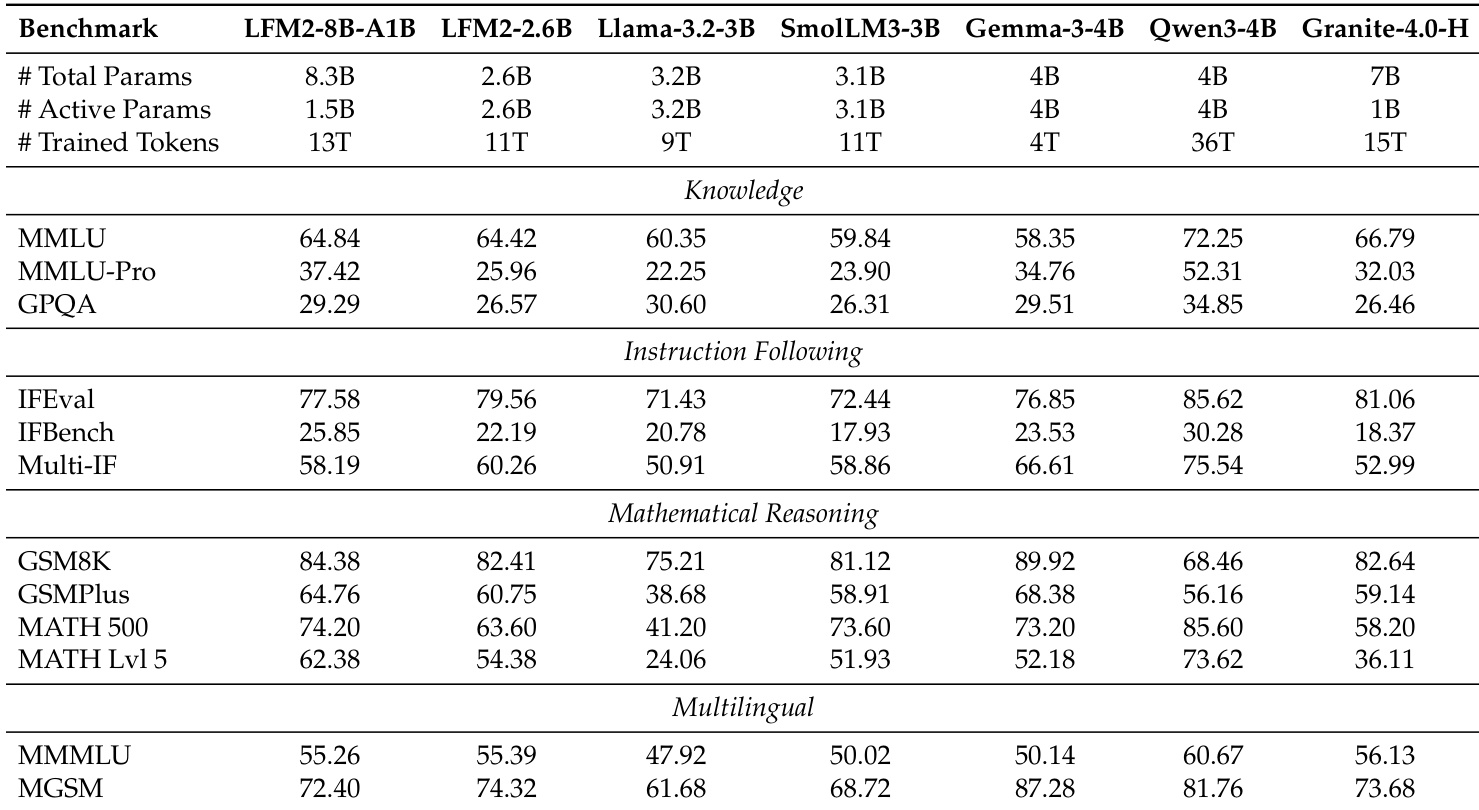
The authors evaluate LFM2 models on a range of benchmarks, showing that LFM2-350M achieves competitive performance in knowledge tasks such as MMLU and GPQA, while LFM2-700M and LFM2-1.2B outperform similarly sized baselines in instruction following and mathematical reasoning. The results indicate that LFM2 models maintain strong performance across diverse evaluation dimensions, particularly excelling in instruction following and mathematical reasoning relative to their size.
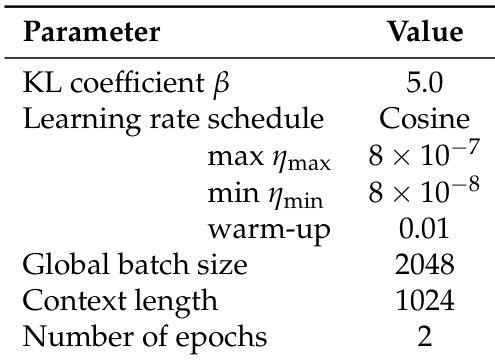
The authors use a cosine learning rate schedule with a maximum learning rate of 8×10−7, a minimum of 8×10−8, and a warm-up factor of 0.01, along with a global batch size of 2048, a context length of 1024, and 2 training epochs. These settings are applied during the training of the LFM2 models, which are optimized for efficient inference on edge devices.
The authors use a custom evaluation harness to measure the performance of LFM2-ColBERT-350M on monolingual and cross-lingual retrieval tasks, demonstrating strong multilingual capabilities and consistent performance across diverse languages. Results show that LFM2-ColBERT-350M achieves a mean NDCG@10 of 0.661 across all tasks and languages, with particularly strong performance in English and robust cross-lingual transfer for European languages.
The authors evaluate LFM2-ColBERT-350M on the NanoBEIR Multilingual benchmark, achieving a mean NDCG@10 of 0.661 across 13 diverse retrieval tasks and languages. The model demonstrates strong multilingual capabilities, maintaining consistent performance across both high-resource and low-resource languages, with significantly reduced performance gaps compared to the GTE-ModernColBERT-v1 baseline.