Command Palette
Search for a command to run...
STEM: 임베딩 모듈을 활용한 Transformer의 스케일링
STEM: 임베딩 모듈을 활용한 Transformer의 스케일링
Ranajoy Sadhukhan Sheng Cao Harry Dong Changsheng Zhao Attiano Purpura-Pontoniere Yuandong Tian Zechun Liu Beidi Chen
초록
세밀한 희소성은 토큰당 계산량에 비례하지 않는 더 높은 파라미터 용량을 제공할 가능성을 약속하지만, 일반적으로 학습 불안정성, 로드 밸런싱 문제 및 통신 오버헤드 등의 문제를 겪는다. 본 연구에서는 FFN의 업프로젝션을 계층 내 국소적 임베딩 검색으로 대체하면서 게이트 및 다운프로젝션은 밀집 형태로 유지하는 정적이고 토큰 인덱스 기반의 접근법인 STEM(Embedding 모듈을 활용한 트랜스포머 스케일링)을 제안한다. 이 방법은 런타임 라우팅을 제거함으로써 CPU 오프로드와 비동기 프리페치를 가능하게 하며, 파라미터 용량을 토큰당 FLOPs와 장치 간 통신과 완전히 분리한다. 실험적으로 STEM은 극한의 희소성에도 불구하고 안정적인 학습을 가능하게 한다. 밀집 기반 기준 모델에 비해 하류 작업 성능을 향상시키면서 동시에 토큰당 FLOPs와 파라미터 접근 횟수를 감소시킨다(약 1/3의 FFN 파라미터를 제거). STEM은 큰 각도 분산을 가진 임베딩 공간을 학습함으로써 지식 저장 용량을 향상시킨다. 더욱 흥미롭게도, 이러한 향상된 지식 용량은 더 뛰어난 해석 가능성과 함께 나타난다. STEM 임베딩의 토큰 인덱스 특성 덕분에 입력 텍스트에 어떠한 간섭 없이도 간단한 방법으로 지식 편집과 지식 주입을 해석 가능한 방식으로 수행할 수 있으며, 추가적인 계산도 필요하지 않다. 또한 STEM은 장거리 컨텍스트 성능을 강화한다. 시퀀스 길이가 증가함에 따라 더 많은 서로 다른 파라미터가 활성화되며, 이는 실질적인 테스트 시 용량 확장에 기여한다. 3.5억과 10억 규모의 모델을 대상으로 한 실험에서 STEM은 전반적으로 약 3~4%의 정확도 향상을 제공하며, 특히 지식과 추론에 중점을 둔 벤치마크(ARC-Challenge, OpenBookQA, GSM8K, MMLU)에서 두드러진 성능 향상을 보였다. 종합적으로 STEM은 파라미터 메모리 확장에 효과적인 방법을 제시하며, 더 나은 해석 가능성, 더 뛰어난 학습 안정성 및 개선된 효율성을 동시에 제공한다.
One-sentence Summary
Carnegie Mellon University and Meta AI introduce STEM, a static, token-indexed sparse architecture that replaces the FFN up-projection with layer-local embedding lookup, enabling stable training, reduced per-token FLOPs and parameter access by ~one-third, and improved long-context performance through scalable parameter activation. By decoupling capacity from compute and communication, STEM supports CPU offload with asynchronous prefetching and achieves higher knowledge storage capacity via embeddings with large angular spread, while offering interpretable, edit-friendly knowledge injection without modifying input text—outperforming dense baselines by up to ~3–4% on knowledge and reasoning benchmarks.
Key Contributions
-
STEM addresses the challenge of scaling parametric capacity in Transformers without increasing per-token compute by replacing the FFN up-projection with a static, token-indexed embedding lookup, eliminating runtime routing and enabling efficient CPU offload with asynchronous prefetching while maintaining dense gate and down-projection layers.
-
The method achieves stable training under extreme sparsity and improves downstream performance on knowledge and reasoning benchmarks (e.g., ARC-Challenge, GSM8K, MMLU) by up to ~3-4% over dense baselines, while reducing per-token FLOPs and parameter accesses by roughly one-third through a learned embedding space with large angular spread that enhances knowledge storage.
-
STEM’s token-indexed embedding design enables interpretable knowledge editing and injection without modifying input text or adding computation, and its capacity scales practically with sequence length as more distinct parameters are activated, offering improved long-context performance and system efficiency compared to MoE and PKM approaches.
Introduction
The authors leverage a static, token-indexed embedding module to scale Transformers efficiently, replacing the feed-forward network's up-projection with a layer-local lookup while keeping the gate and down-projection dense. This design enables significant reductions in per-token FLOPs and parameter accesses—eliminating roughly one-third of FFN parameters—without increasing cross-device communication or runtime routing overhead. Unlike prior sparse methods such as MoE, which rely on dynamic routing and suffer from training instability and load imbalance, or PKM models that face high inference lookup costs and under-training issues, STEM achieves stable training at extreme sparsity levels. Its key innovation lies in decoupling parametric capacity from compute and communication, enabling CPU offload with asynchronous prefetching and scalable long-context performance. The learned embedding spaces exhibit large angular spread, enhancing knowledge storage and interpretability, allowing direct knowledge editing and injection without modifying input text or adding computation. STEM delivers up to 3–4% accuracy gains on knowledge and reasoning benchmarks across 350M and 1B models, offering a robust, efficient, and interpretable path to scaling parametric memory in large language models.
Dataset

- The dataset is composed of multiple sources: OLMo-MIX-1124 (3.9T tokens), a mixture of DCLM and Dolma 1.7; NEMOTRON-CC-MATH-v1 (math-focused); and NEMOTRON-PRETRAINING-CODE-v1 (code-focused).
- For pretraining, the authors subsample 1T tokens from OLMo-MIX-1124.
- During mid-training, the data mix consists of 65% OLMo-MIX-1124, 5% NEMOTRON-CC-MATH-v1, and 30% NEMOTRON-PRETRAINING-CODE-v1.
- For context-length extension, the authors use PROLONG-DATA-64K, which is 63% long-context and 37% short-context, with sequences packed up to 32,768 tokens using cross-document attention masking.
- The data is processed with no explicit cropping, but sequences are packed to fit the model’s maximum context length.
- Metadata for long-context evaluation is constructed to support the Needle-in-a-Haystack benchmark, which tests retrieval in extended contexts.
- The authors use the pretraining data to train 350M models on 100 billion tokens and 1B models on 1 trillion tokens, with mid-training using 100 billion tokens and context extension using 20 billion tokens.
- Training employs AdamW with a cosine learning rate schedule, 10% warmup, and a minimum LR of 0.1 times the peak.
- The model architecture uses separate input embeddings and language model heads, with one-third of FFN layers replaced by sparse alternatives (STEM or Hash layer MoE), maintaining comparable activated FLOPs to the dense baseline.
Method
The authors leverage a modified feed-forward network (FFN) architecture within a decoder-only transformer, building upon the SwiGLU activation function and the key-value memory perspective of FFNs to introduce the STEM (Static Token-Embedded Mixture) model. The standard SwiGLU FFN, as shown in Figure (a), processes an input hidden state xℓ through a gate projection Wℓg, an up projection Wℓu, and a down projection Wℓd. The transformation is defined as yℓ=Wℓd(SiLU(Wℓgxℓ)⊙(Wℓuxℓ)), where the up projection generates an address vector for retrieving information from the down projection, and the gate projection provides context-dependent modulation.
The STEM design, illustrated in Figure (c), fundamentally rethinks this process by replacing the up projection with a token-indexed embedding lookup. For a given layer ℓ and input token t, the model accesses a per-layer embedding table Uℓ∈RV×dff to retrieve the vector Uℓ[t]. The output is then computed as yℓ=Wℓ(d)(SiLU(Wℓ(g)xℓ)⊙Uℓ[t]). This design choice is motivated by the key-value memory view of FFNs, where the up projection acts as a key for content retrieval, and the gate projection acts as a context-dependent modulator. By replacing the up projection with a static, token-specific embedding, STEM decouples the parametric capacity from the per-token computation, enabling a more efficient and interpretable architecture.
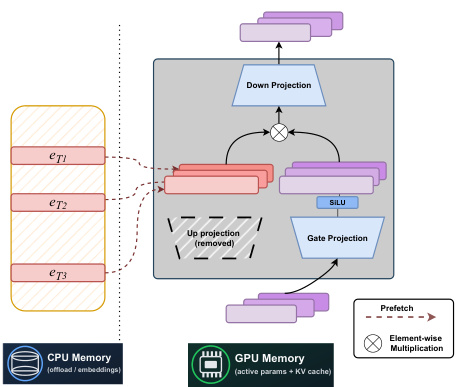
The system architecture, as depicted in the figure, highlights the key components of the STEM model. The model's forward pass begins with the input hidden state xℓ, which is processed by the gate projection Wℓg and passed through the SiLU activation function. Simultaneously, the token t is used to index the CPU memory, where the corresponding STEM embedding Uℓ[t] is prefetched. This embedding is then elementwise multiplied with the output of the SiLU function. The result is passed to the down projection Wℓd to produce the final output yℓ. The figure also shows that the STEM embeddings are stored in CPU memory, which allows for offloading and asynchronous prefetching, reducing the GPU memory footprint and communication overhead. The down projection and gate projection remain in GPU memory as active parameters, while the STEM embeddings are stored in CPU memory, enabling efficient memory management.
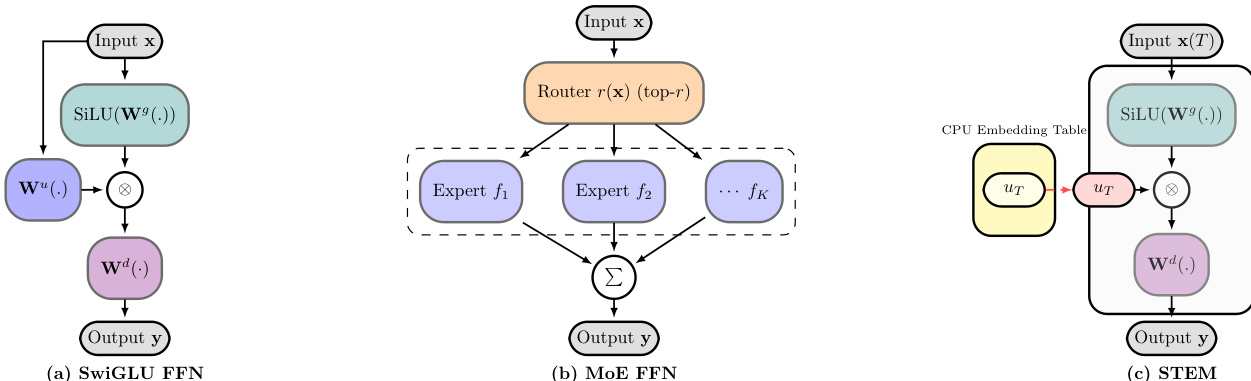
The comparison of architectures in Figure (a), (b), and (c) illustrates the evolution from a standard SwiGLU FFN to a Mixture-of-Experts (MoE) FFN and finally to the STEM FFN. The standard SwiGLU FFN (a) uses a single, dense up projection. The MoE FFN (b) replaces this with multiple expert FFNs and a router that selects a subset of experts based on the input. In contrast, the STEM FFN (c) replaces the up projection with a token-indexed embedding lookup, which is stored in CPU memory. This design avoids the need for a trainable router and the associated communication overhead of expert parallelism, making it more efficient and scalable. The STEM architecture also allows for better interpretability, as the embeddings are directly tied to specific tokens and can be used for knowledge editing.
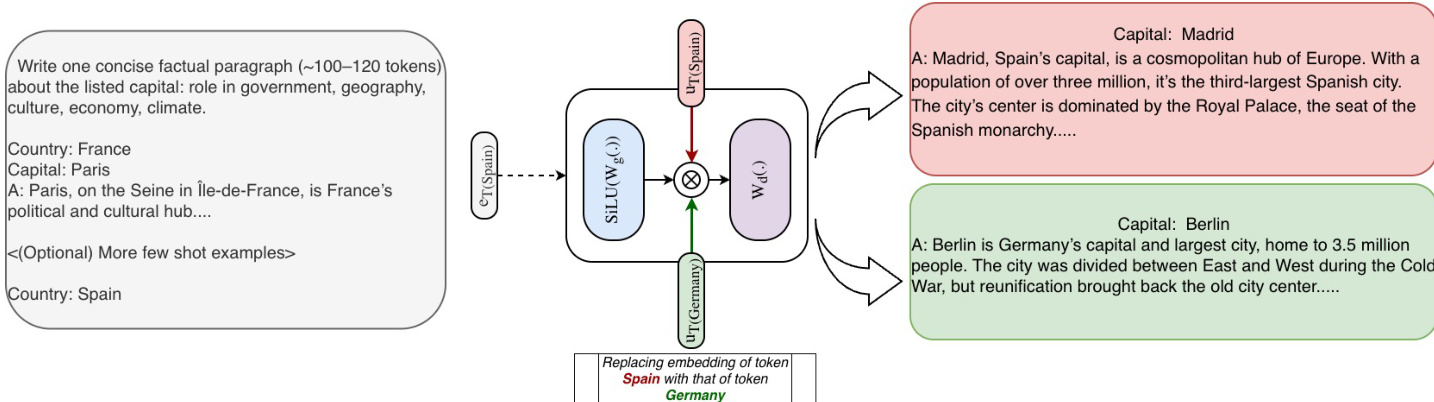
The knowledge editing demonstration in the figure shows how STEM embeddings can be used to modify the model's output by changing the embeddings for specific tokens. The prompt "Country: Spain" is used to generate a paragraph about Madrid. By replacing the STEM embedding for the token "Spain" with the embedding for "Germany", the model generates a paragraph about Berlin instead. This demonstrates the ability of STEM to perform precise, token-indexed knowledge editing, which is a direct consequence of the clear mapping between the embeddings and the tokens. The figure also shows that this editing can be done even when the source and target entities have different tokenization lengths, using strategies such as padding, copying, or subset selection. This ability to manipulate the model's knowledge in a targeted and interpretable way is a key advantage of the STEM architecture.
Experiment
- STEM replaces the up-projection in gated FFNs with token-indexed embeddings, achieving stable training without loss spikes, unlike fine-grained MoE models.
- On ARC-Challenge and OpenBookQA, STEM outperforms the dense baseline by ~9–10% and shows improved performance with more STEM layers.
- STEM improves long-context inference: on Needle-in-a-Haystack, it achieves 13% higher accuracy than the dense baseline at 32k context length.
- STEM reduces per-token FLOPs and parameter accesses by up to one-third, with training ROI improvements of 1.08x (1/3 layers), 1.20x (1/2 layers), and 1.33x (full layers) over the dense baseline.
- STEM exhibits large angular spread in embedding space (low pairwise cosine similarity), enhancing information storage capacity and reducing representational interference.
- STEM enables interpretable, reversible knowledge editing: swapping token-specific embeddings shifts factual predictions (e.g., Madrid → Berlin) without changing input.
- STEM outperforms the dense baseline on GSM8K, MMLU, BBH, MuSR, and LongBench multi-hop/code-understanding tasks, demonstrating superior reasoning and knowledge retrieval.
- STEM maintains efficiency across batch sizes, with sustained FLOPs and memory access savings due to static, token-indexed sparsity and reduced parameter traffic.
The authors use a consistent learning rate schedule across all configurations, with cosine decay for pretraining and linear decay for midtraining, while adjusting the peak learning rate and batch size to match the computational demands of each setting. Training steps are reduced for midtraining and context-extension tasks, and cross-document masking is enabled only for the context-extension experiment.
Results show that the STEM model achieves higher performance than the dense baseline across all context lengths, with the largest improvement observed in the 0–2k range, where STEM scores 27.6 compared to the baseline's 24.0. The performance gap narrows at longer contexts, but STEM maintains a consistent advantage, indicating improved long-context capabilities.

The authors compare the computational and communication costs of standard FFN and STEM architectures during prefill and decoding. For prefill and training, STEM reduces FLOPs by replacing the up-projection with token-indexed embeddings, resulting in a saving of B(dffL) FLOPs. During decoding, STEM reduces parameter loading cost by half and eliminates communication, achieving a saving of ddff per step.

The authors use STEM to replace the up-projection in gated FFNs with token-indexed embeddings, achieving better training stability and improved performance on knowledge-intensive tasks compared to dense and MoE baselines. Results show that STEM consistently outperforms the dense baseline on benchmarks like ARC-Challenge and OpenBookQA, with gains increasing as more FFN layers are replaced, while also reducing per-token FLOPs and parameter accesses.

The authors compare the STEM model with a dense baseline on a 1B-scale mid-trained model across multiple downstream tasks. Results show that STEM consistently outperforms the baseline on knowledge-intensive tasks such as ARC-E, PIQA, and OBQA, with improvements of 2.1 to 4.1 points, while achieving comparable or slightly better performance on other tasks. The average score across all evaluated tasks increases from 57.50 to 58.49, indicating a general improvement in model performance.
