HyperAI
HyperAI
メイン
ホーム
GPU
コンソール
ドキュメント
料金
パルス
ニュース
リソース
論文
ノートブック
データセット
Wiki
ベンチマーク
SOTA
LLMモデル
GPUランキング
コミュニティ
イベント
ユーティリティ
検索
概要
利用規約
プライバシーポリシー
日本語
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
サインイン
HyperAI
Papers
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
HyperAI
HyperAI
メイン
ホーム
GPU
コンソール
ドキュメント
料金
パルス
ニュース
リソース
論文
ノートブック
データセット
Wiki
ベンチマーク
SOTA
LLMモデル
GPUランキング
コミュニティ
イベント
ユーティリティ
検索
概要
利用規約
プライバシーポリシー
日本語
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
サインイン
HyperAI
Papers
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
CHIMERA:汎用的LLM推論向けコンパクトな合成データ
LLM
Reasoning
Xinyu Zhu, Yihao Feng, Yanchao Sun, et al.
RubricBench:モデル生成ラベルと人間基準の整合性
ベンチマーク
LLM
Qiyuan Zhang, Junyi Zhou, Yufei Wang, et al.
MMR-Life:マルチモーダル・マルチイメージ推論のためのリアルライフシーンの構築
マルチモーダル
Reasoning
Jiachun Li, Shaoping Huang, Zhuoran Jin, et al.
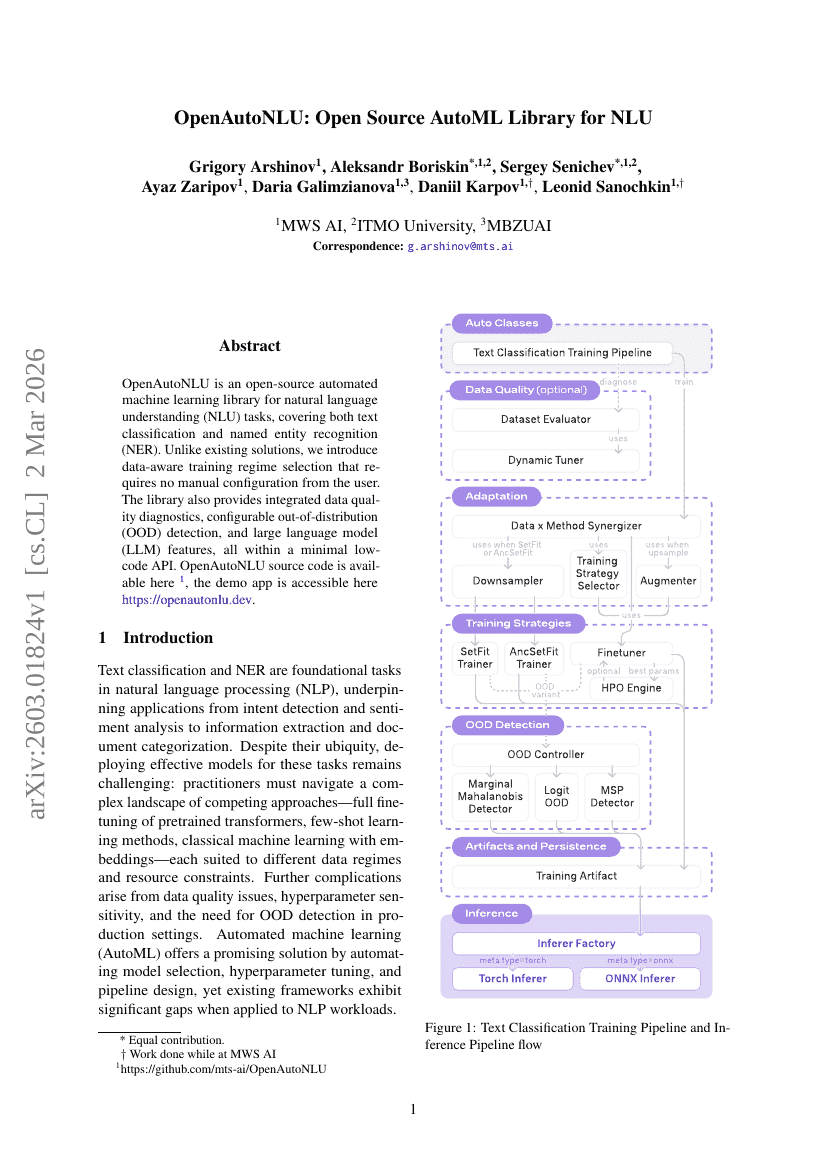
OpenAutoNLU:NLU向けオープンソースAutoMLライブラリ
自然言語処理
LLM
Grigory Arshinov, Aleksandr Boriskin, Sergey Senichev, et al.
OmniLottie:パラメータ化Lottieトークンを用いたベクターアニメーション生成
マルチモーダル
動画生成
Yiying Yang, Wei Cheng, Sijin Chen, et al.
スケールからスピードへ:画像編集における適応的テスト時スケーリング
画像生成
画像間変換
Xiangyan Qu, Zhenlong Yuan, Jing Tang, et al.
コンテキスト内における共同プレイヤー推論を用いたマルチエージェント協調
強化学習
エージェント
Marissa A. Weis, Maciej Wołczyk, Rajai Nasser, et al.
ActionEngine:状態遷移記憶を用いた反応型からプログラム型GUIエージェントへ
エージェント
コード生成
Hongbin Zhong, Fazle Faisal, Luis França, et al.
CiteAudit:あなたは引用しましたが、読んだでしょうか?LLM時代における科学的引用の検証のためのベンチマーク
検索拡張生成
ベンチマーク
Zhengqing Yuan, Kaiwen Shi, Zheyuan Zhang, et al.
モード探索が平均探索と融合した高速な長時間動画生成
動画生成
拡散モデル
Shengqu Cai, Weili Nie, Chao Liu, et al.
CUDA Agent:高性能CUDAカーネル生成のための大規模エージェント型強化学習
AI コンパイラ
コード生成
Weinan Dai, Hanlin Wu, Qiying Yu, et al.
翻訳による回復:ベンチマークおよびデータセットの自動翻訳を効率的に行うパイプライン
翻訳
LLM
Hanna Yukhymenko, Anton Alexandrov, Martin Vechev
画像生成における空間理解の向上:報酬モデリングを活用して
画像生成
テキストから画像生成
Zhenyu Tang, Chaoran Feng, Yufan Deng, et al.
dLLM:シンプルなディフュージョン言語モデリング
拡散モデル
テキスト生成
Zhanhui Zhou, Lingjie Chen, Hanghang Tong, et al.
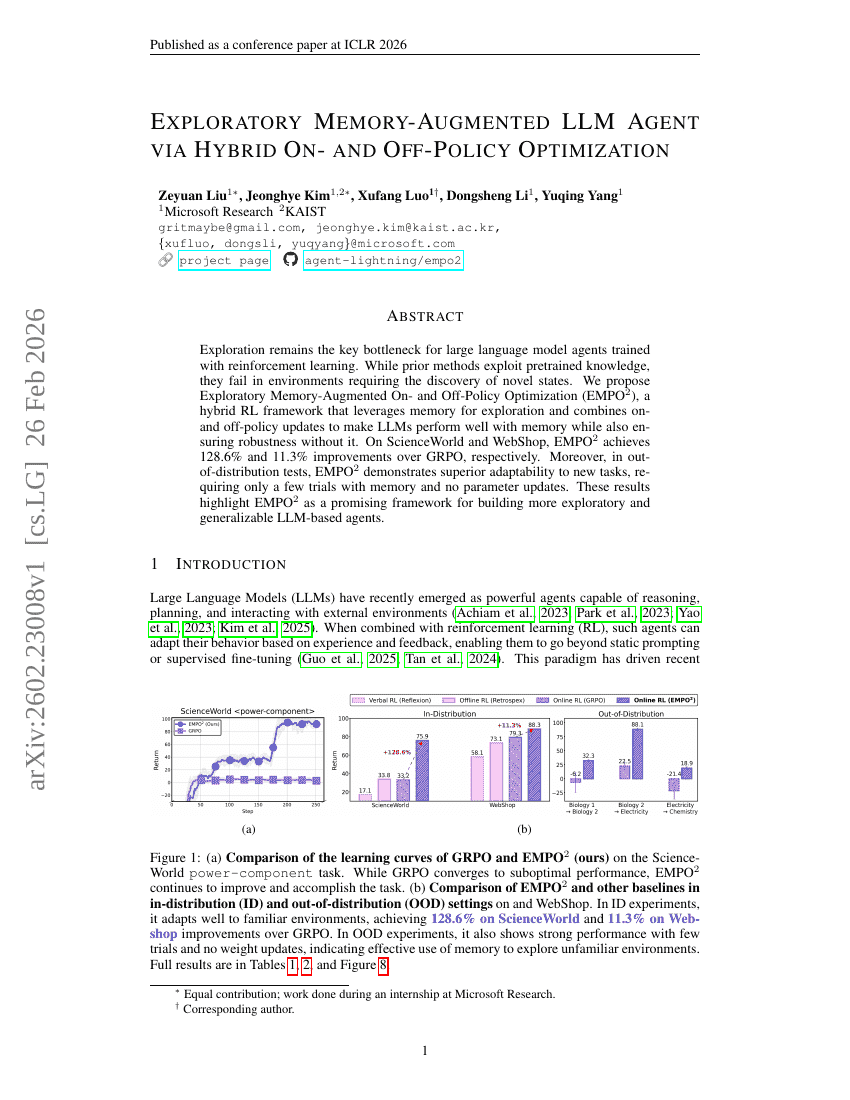
探索的メモリ拡張型LLMエージェント:ハイブリッドオンポリシーおよびオフポリシー最適化による実現
強化学習
エージェント
Zeyuan Liu, Jeonghye Kim, Xufang Luo, et al.
想像力は視覚的推論を支援するが、まだ潜在空間では実現していない
マルチモーダル
視覚質問応答
You Li, Chi Chen, Yanghao Li, et al.
オムニGAIA:ネイティブなオムニモーダルAIエージェントへ向けて
マルチモーダル
エージェント
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, et al.
MobilityBench:現実世界のモビリティシナリオにおけるルート計画エージェント評価のためのベンチマーク
インテリジェントな質問応答
ベンチマーク
Zhiheng Song, Jingshuai Zhang, Chuan Qin, et al.
盲点から利益へ:大規模なマルチモーダルモデルにおける診断駆動型反復学習
マルチモーダル
モデル学習
Hongrui Jia, Chaoya Jiang, Shikun Zhang, et al.
一貫性の三位一体が汎用世界モデルの定義的原則としての役割
マルチモーダル表現
Any-to-Any
Jingxuan Wei, Siyuan Li, Yuhang Xu, et al.
GUI-Libra:アクション認識型の監督と部分検証可能なRLを用いたネイティブGUIエージェントの推論・実行訓練
監視付き微調整
エージェント
Rui Yang, Qianhui Wu, Zhaoyang Wang, et al.
SkyReels-V4:マルチモーダルな動画・音声生成、インペインティングおよび編集モデル
テキストから動画
拡散モデル
Guibin Chen, Dixuan Lin, Jiangping Yang, et al.
ARLArena:安定したエージェント強化学習を実現する包括的フレームワーク
強化学習
LLM
Xiaoxuan Wang, Han Zhang, Haixin Wang, et al.
DreamID-Omni:制御可能かつ人間中心型音声・映像生成のための統合枠組み
マルチモーダル
Any-to-Any
Xu Guo, Fulong Ye, Qichao Sun, et al.
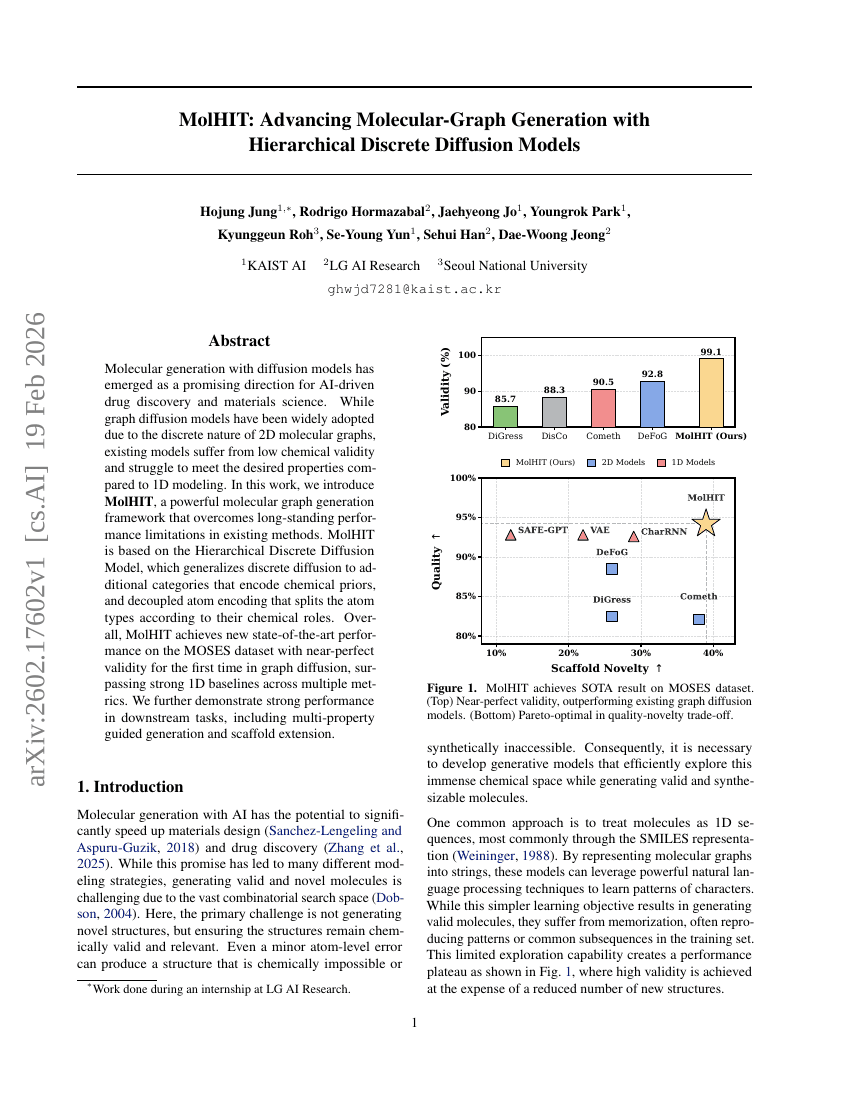
MolHIT:階層的離散拡散モデルによる分子グラフ生成の進展
拡散モデル
サイエンスのためのAI
Hojung Jung, Rodrigo Hormazabal, Jaehyeong Jo, et al.
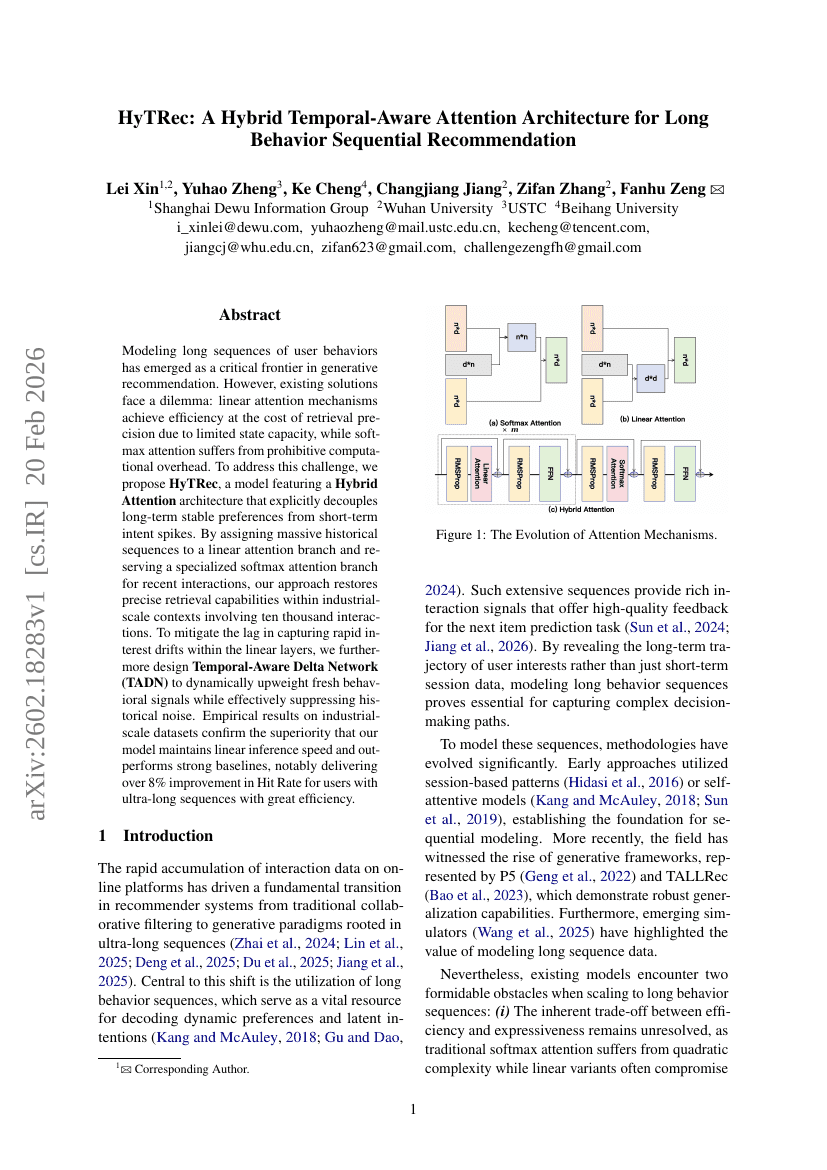
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
Transformer
Preference Modeling
Lei Xin, Yuhao Zheng, Ke Cheng, et al.
DREAM:エージェンティックメトリクスを用いたディープリサーチ評価
ベンチマーク
LLM
Elad Ben Avraham, Changhao Li, Ron Dorfman, et al.
LongCLI-Bench:コマンドラインインターフェースにおける長期視野型エージェントプログラミングのための初期ベンチマークと研究
エージェント
ベンチマーク
Yukang Feng, Jianwen Sun, Zelai Yang, et al.
PyVision-RL:RLを活用したオープン型エージェント視覚モデルの構築
ビデオ理解
エージェント
Shitian Zhao, Shaoheng Lin, Ming Li, et al.
知覚から行動へ:視覚推論のためのインタラクティブベンチマーク
マルチモーダル
マルチモーダル表現
Yuhao Wu, Maojia Song, Yihuai Lan, et al.
クエリ中心型かつメモリ認識型リランカーによる長文脈処理
LLM
検索拡張生成
Yuqing Li, Jiangnan Li, Mo Yu, et al.
LLM端末機能のスケーリングのためのデータ工学
LLM
モデル学習
Renjie Pi, Grace Lam, Mohammad Shoeybi, et al.
1
2
3
4
52
CHIMERA:汎用的LLM推論向けコンパクトな合成データ
LLM
Reasoning
Xinyu Zhu, Yihao Feng, Yanchao Sun, et al.
RubricBench:モデル生成ラベルと人間基準の整合性
ベンチマーク
LLM
Qiyuan Zhang, Junyi Zhou, Yufei Wang, et al.
MMR-Life:マルチモーダル・マルチイメージ推論のためのリアルライフシーンの構築
マルチモーダル
Reasoning
Jiachun Li, Shaoping Huang, Zhuoran Jin, et al.
OpenAutoNLU:NLU向けオープンソースAutoMLライブラリ
自然言語処理
LLM
Grigory Arshinov, Aleksandr Boriskin, Sergey Senichev, et al.
OmniLottie:パラメータ化Lottieトークンを用いたベクターアニメーション生成
マルチモーダル
動画生成
Yiying Yang, Wei Cheng, Sijin Chen, et al.
スケールからスピードへ:画像編集における適応的テスト時スケーリング
画像生成
画像間変換
Xiangyan Qu, Zhenlong Yuan, Jing Tang, et al.
コンテキスト内における共同プレイヤー推論を用いたマルチエージェント協調
強化学習
エージェント
Marissa A. Weis, Maciej Wołczyk, Rajai Nasser, et al.
ActionEngine:状態遷移記憶を用いた反応型からプログラム型GUIエージェントへ
エージェント
コード生成
Hongbin Zhong, Fazle Faisal, Luis França, et al.
CiteAudit:あなたは引用しましたが、読んだでしょうか?LLM時代における科学的引用の検証のためのベンチマーク
検索拡張生成
ベンチマーク
Zhengqing Yuan, Kaiwen Shi, Zheyuan Zhang, et al.
モード探索が平均探索と融合した高速な長時間動画生成
動画生成
拡散モデル
Shengqu Cai, Weili Nie, Chao Liu, et al.
CUDA Agent:高性能CUDAカーネル生成のための大規模エージェント型強化学習
AI コンパイラ
コード生成
Weinan Dai, Hanlin Wu, Qiying Yu, et al.
翻訳による回復:ベンチマークおよびデータセットの自動翻訳を効率的に行うパイプライン
翻訳
LLM
Hanna Yukhymenko, Anton Alexandrov, Martin Vechev
画像生成における空間理解の向上:報酬モデリングを活用して
画像生成
テキストから画像生成
Zhenyu Tang, Chaoran Feng, Yufan Deng, et al.
dLLM:シンプルなディフュージョン言語モデリング
拡散モデル
テキスト生成
Zhanhui Zhou, Lingjie Chen, Hanghang Tong, et al.
探索的メモリ拡張型LLMエージェント:ハイブリッドオンポリシーおよびオフポリシー最適化による実現
強化学習
エージェント
Zeyuan Liu, Jeonghye Kim, Xufang Luo, et al.
想像力は視覚的推論を支援するが、まだ潜在空間では実現していない
マルチモーダル
視覚質問応答
You Li, Chi Chen, Yanghao Li, et al.
オムニGAIA:ネイティブなオムニモーダルAIエージェントへ向けて
マルチモーダル
エージェント
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, et al.
MobilityBench:現実世界のモビリティシナリオにおけるルート計画エージェント評価のためのベンチマーク
インテリジェントな質問応答
ベンチマーク
Zhiheng Song, Jingshuai Zhang, Chuan Qin, et al.
盲点から利益へ:大規模なマルチモーダルモデルにおける診断駆動型反復学習
マルチモーダル
モデル学習
Hongrui Jia, Chaoya Jiang, Shikun Zhang, et al.
一貫性の三位一体が汎用世界モデルの定義的原則としての役割
マルチモーダル表現
Any-to-Any
Jingxuan Wei, Siyuan Li, Yuhang Xu, et al.
GUI-Libra:アクション認識型の監督と部分検証可能なRLを用いたネイティブGUIエージェントの推論・実行訓練
監視付き微調整
エージェント
Rui Yang, Qianhui Wu, Zhaoyang Wang, et al.
SkyReels-V4:マルチモーダルな動画・音声生成、インペインティングおよび編集モデル
テキストから動画
拡散モデル
Guibin Chen, Dixuan Lin, Jiangping Yang, et al.
ARLArena:安定したエージェント強化学習を実現する包括的フレームワーク
強化学習
LLM
Xiaoxuan Wang, Han Zhang, Haixin Wang, et al.
DreamID-Omni:制御可能かつ人間中心型音声・映像生成のための統合枠組み
マルチモーダル
Any-to-Any
Xu Guo, Fulong Ye, Qichao Sun, et al.
MolHIT:階層的離散拡散モデルによる分子グラフ生成の進展
拡散モデル
サイエンスのためのAI
Hojung Jung, Rodrigo Hormazabal, Jaehyeong Jo, et al.
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
Transformer
Preference Modeling
Lei Xin, Yuhao Zheng, Ke Cheng, et al.
DREAM:エージェンティックメトリクスを用いたディープリサーチ評価
ベンチマーク
LLM
Elad Ben Avraham, Changhao Li, Ron Dorfman, et al.
LongCLI-Bench:コマンドラインインターフェースにおける長期視野型エージェントプログラミングのための初期ベンチマークと研究
エージェント
ベンチマーク
Yukang Feng, Jianwen Sun, Zelai Yang, et al.
PyVision-RL:RLを活用したオープン型エージェント視覚モデルの構築
ビデオ理解
エージェント
Shitian Zhao, Shaoheng Lin, Ming Li, et al.
知覚から行動へ:視覚推論のためのインタラクティブベンチマーク
マルチモーダル
マルチモーダル表現
Yuhao Wu, Maojia Song, Yihuai Lan, et al.
クエリ中心型かつメモリ認識型リランカーによる長文脈処理
LLM
検索拡張生成
Yuqing Li, Jiangnan Li, Mo Yu, et al.
LLM端末機能のスケーリングのためのデータ工学
LLM
モデル学習
Renjie Pi, Grace Lam, Mohammad Shoeybi, et al.
1
2
3
4
52