Command Palette
Search for a command to run...
CHIMERA:汎用的LLM推論向けコンパクトな合成データ
CHIMERA:汎用的LLM推論向けコンパクトな合成データ
Xinyu Zhu Yihao Feng Yanchao Sun Xianzhi Du Pingzhi Li Olli Saarikivi Yun Zhu Yu Meng
概要
近年、大規模言語モデル(LLMs)は、高品質な推論データを用いた教師あり微調整(SFT)および強化学習(RL)に基づく後処理によって、顕著な推論能力を示すようになっている。しかし、オープンかつスケーラブルな環境においてこれらの能力を再現・拡張することは、以下の3つのデータ中心的な課題によって阻まれている:(1)初期化段階における「コールドスタート問題」——推論ポリシーを初期化するのに必要な詳細かつ長時間のチェーン・オブ・シンセス(CoT)推論経路を備えた初期データセットが不足していること;(2)ドメインカバレッジの限界——現存する多数のオープンソース推論データセットは数学に偏っており、広範な科学分野へのカバレッジが乏しいこと;(3)アノテーションのボトルネック——先端レベルの推論タスクの難易度が高いため、信頼性の高い人間によるアノテーションが極めて高コストまたは現実的に不可能であること。これらの課題に対処するために、我々は汎用的で跨領域推論に適した合成推論データセット「CHIMERA」を提案する。CHIMERAは9,000サンプルから構成されるコンパクトなデータセットであり、以下の3つの主要な特徴を持つ:(1)最先端の推論モデルによって生成された豊富で長時間のCoT推論経路を提供;(2)8つの主要科学分野をカバーし、モデルによって生成された階層的分類体系により1,000以上に及ぶ細分化されたトピックを体系的に構造化;(3)強力な推論モデルを用いて問題の妥当性と解答の正しさを相互検証する、完全自動化かつスケーラブルな評価パイプラインを採用。本研究では、CHIMERAを用いて4BパラメータのQwen3モデルを後処理学習した。データセットの規模は限定的であるものの、GPQA-Diamond、AIME 24/25/26、HMMT 25、Humanity's Last Examといった難易度の高い推論ベンチマークにおいて、顕著な性能を達成し、DeepSeek-R1やQwen3-235Bといったはるかに大きなモデルと同等またはそれ以上の推論性能を実現した。
One-sentence Summary
Researchers from multiple institutions propose CHIMERA, a compact synthetic reasoning dataset with 9K samples featuring long CoT trajectories across 8 scientific domains, enabling scalable, annotation-free post-training of Qwen3-4B to match larger models on advanced reasoning benchmarks.
Key Contributions
- CHIMERA addresses three key data bottlenecks in LLM reasoning post-training: cold-start scarcity of long CoT trajectories, narrow domain coverage, and prohibitive human annotation costs, by introducing a compact 9K-sample synthetic dataset generated entirely by state-of-the-art models.
- The dataset provides rich, multi-step reasoning trajectories across 8 scientific disciplines and 1K+ fine-grained topics organized via a model-generated taxonomy, enabling broad generalization while maintaining structural coherence without human annotation.
- When used to post-train a 4B Qwen3 model via SFT and RL, CHIMERA enables competitive performance on frontier benchmarks including GPQA-Diamond, AIME, HMMT, and Humanity’s Last Exam, matching or approaching larger models like DeepSeek-R1 and Qwen3-235B.
Introduction
The authors leverage synthetic data to tackle key bottlenecks in training LLMs for generalizable reasoning: the lack of seed datasets with long Chain-of-Thought trajectories, narrow domain coverage (mostly math), and the high cost of human annotation for frontier-level tasks. Prior synthetic datasets often lack structure, diversity, or reliable quality control, limiting their effectiveness for post-training. Their main contribution is CHIMERA, a compact 9K-sample dataset built with three design pillars: long CoT trajectories from strong models, broad coverage across 8 scientific domains and 1K+ topics via a model-generated taxonomy, and fully automated evaluation using cross-model validation to ensure correctness—no human annotation required. Post-training a 4B Qwen3 model on CHIMERA yields performance competitive with much larger models like DeepSeek-R1 and Qwen3-235B across challenging benchmarks.
Dataset

The authors use CHIMERA, a synthetic reasoning dataset built entirely via LLMs, to train models on complex, cross-disciplinary problems without human annotation. Here’s how it’s structured and used:
-
Dataset Composition & Sources
- Built from 8 broad subjects (math, physics, computer science, chemistry, biology, literature, etc.) using GPT-5 for topic expansion and problem generation, and Qwen3-235B for solution synthesis.
- Starts with coarse-grained seed subjects, then expands into 1,179 fine-grained topics via LLM prompting.
- Problems are self-contained, PhD-level, and require multi-step reasoning; each includes subject, topic, problem, answer, detailed solution, and correctness label.
-
Key Subset Details
- Total: 9,225 problems, with math dominating (48.3%) followed by CS, chemistry, and physics.
- Each topic generates multiple problems (n per topic), filtered via dual LLM verifiers (GPT-5 and o4-mini) to ensure clarity, solvability, and answer correctness.
- Topics are deduplicated and hierarchically organized; math receives extra sampling due to breadth.
- Solutions average 11K words — significantly longer than prior datasets — to encourage deep, long-horizon reasoning.
-
Usage in Training
- Used as a training split for supervised fine-tuning (SFT), with no mixture ratios mentioned — appears to be used monolithically.
- Designed to complement existing benchmarks (like GSM8K, MATH, GPQA) by emphasizing structured diversity over scale.
- Problems are not mixed with other datasets in the paper; focus is on training advanced LLMs via complex, domain-spanning reasoning.
-
Processing & Metadata
- No cropping — all problems are full-length and self-contained.
- Metadata includes subject-topic hierarchy, problem statement, answer, solution trajectory, and correctness flag (True/False).
- Filtering is automated: problems failing dual-verifier checks (clarity, answer correctness) are discarded.
- Prompts for all stages (expansion, generation, validation) are provided in Appendix A; full samples in Appendix C.
Method
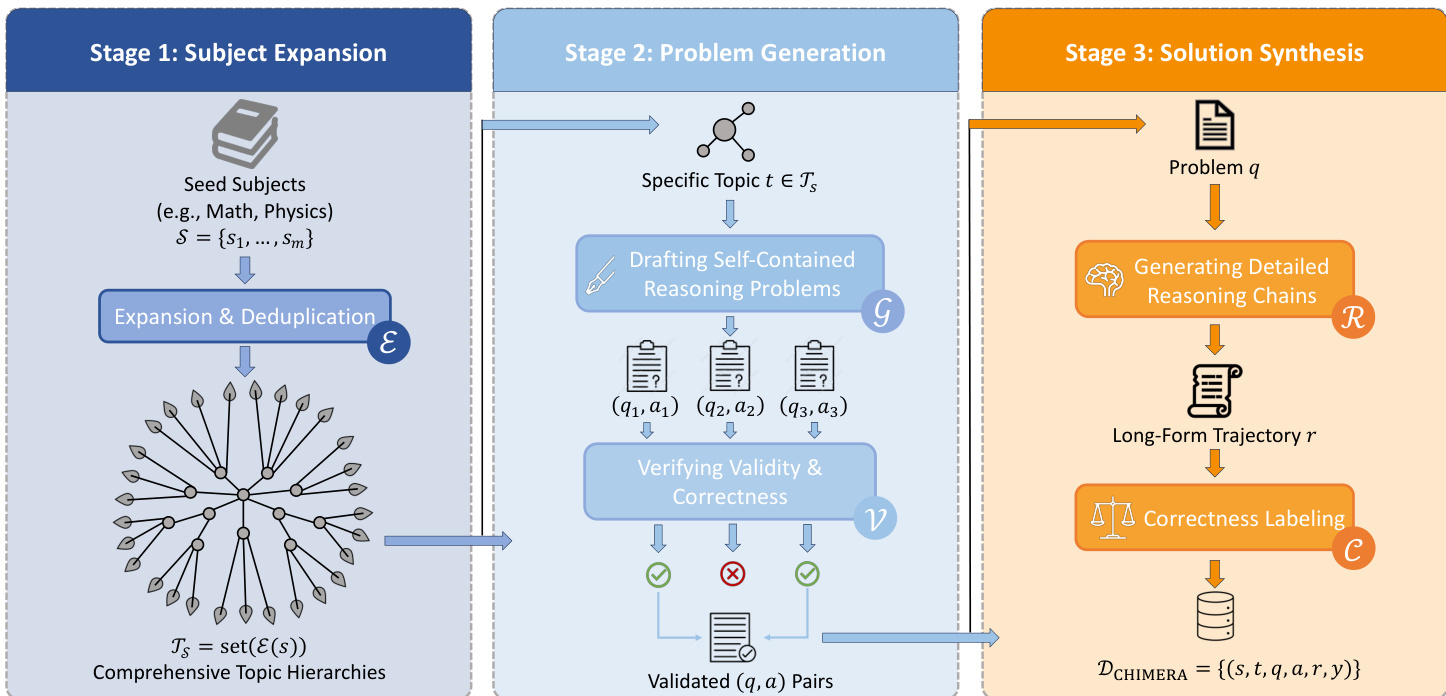
The authors leverage a three-stage pipeline to construct a high-quality, reasoning-intensive dataset named CHIMERA. The overall framework is designed to systematically expand subject domains, generate self-contained problems, and synthesize detailed reasoning trajectories with correctness labels, enabling both supervised fine-tuning and reinforcement learning applications.
In Stage 1, titled “Subject Expansion,” the process begins with a set of seed subjects (e.g., Math, Physics) denoted as S={s1,...,sm}. These are expanded and deduplicated via a module E to produce a comprehensive set of topic hierarchies TS=set(E(S)). This stage ensures broad coverage across disciplines and subtopics, forming the foundation for subsequent problem generation.
Stage 2, “Problem Generation,” operates on each specific topic t∈TS. A problem drafting module G generates self-contained reasoning problems (qi,ai), where qi is the problem statement and ai is the reference answer. These candidate problems are then passed to a validation module V, which verifies their validity and correctness. Only validated (q,a) pairs proceed to the next stage, ensuring that all problems meet quality and accuracy thresholds before further processing.
Stage 3, “Solution Synthesis,” is where the core reasoning enrichment occurs. For each validated problem q, a strong open reasoning-intensive model R—in this case, Qwen3-235B-A22B-Thinking-2507—is employed to generate a detailed, step-by-step reasoning trajectory r. This trajectory is then compared against the original answer a to produce a binary correctness label y∈{0,1} via a labeling module C. The final output is a structured dataset DCHIMERA={(s,t,q,a,r,y)}, where each entry includes subject, topic, problem, answer, reasoning chain, and correctness label.
Refer to the framework diagram for a visual overview of the three-stage pipeline and its modular components.
Experiment
- Fine-tuning Qwen3-4B on CHIMERA significantly boosts reasoning performance across diverse benchmarks, matching or surpassing models up to 235B parameters, demonstrating exceptional data efficiency.
- CHIMERA’s synthetic problems are substantially harder than existing datasets, providing stronger training signals and leaving room for improvement even in strong base models.
- Supervised fine-tuning alone delivers most of the performance gains; reinforcement learning offers only incremental improvements, underscoring the dataset’s inherent quality.
- LLM-generated problems in CHIMERA are rated by independent evaluators as comparable or superior to human-written ones in clarity, well-posedness, and reasoning depth.
- Near-zero lexical overlap with evaluation benchmarks confirms no data contamination, validating that performance gains stem from genuine reasoning improvement.
- Inference-time scaling shows consistent gains across increasing sample sizes, indicating enhanced robustness and broader solution coverage rather than mere single-shot accuracy.
- Performance degrades when fine-tuning on OpenScience, likely due to its multiple-choice format encouraging shortcut strategies over deep reasoning.
- CHIMERA’s structured, multi-step, free-form problems with detailed solution traces are key to advancing modern LLM reasoning capabilities.
The authors use a synthesized dataset called CHIMERA to fine-tune a 4B-parameter base model, achieving performance competitive with models up to two orders of magnitude larger. Results show consistent gains across multiple reasoning benchmarks, with supervised fine-tuning alone accounting for most of the improvement, indicating the dataset’s high quality and difficulty. Inference-time scaling further reveals enhanced reasoning robustness, as performance gaps widen with increased sampling, suggesting broader coverage of valid solution paths.
Fine-tuning the Qwen3-4B base model on the CHIMERA dataset consistently improves performance across multiple reasoning benchmarks, with supervised fine-tuning alone accounting for most of the gains and reinforcement learning providing incremental improvements. The resulting model achieves competitive performance with much larger models, demonstrating strong data efficiency. These improvements persist under inference-time scaling, indicating enhanced reasoning robustness and broader solution coverage rather than just better single-shot accuracy.
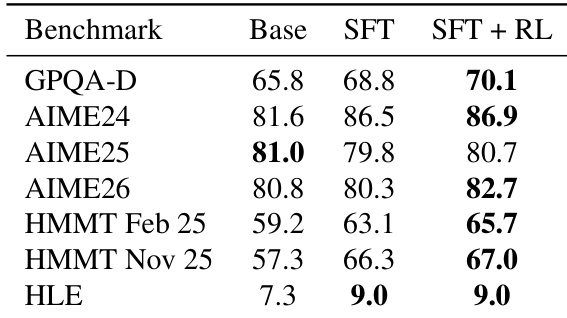
The authors use a synthesized dataset called CHIMERA to fine-tune a 4B-parameter base model, achieving performance competitive with models up to two orders of magnitude larger. Results show consistent gains across multiple reasoning benchmarks, with supervised fine-tuning alone accounting for most of the improvement, indicating the dataset’s high quality and difficulty. Inference-time scaling further reveals enhanced reasoning robustness, as performance gaps widen with increased sampling, suggesting broader coverage of valid solution paths.
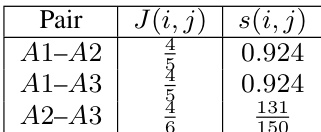
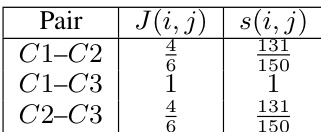
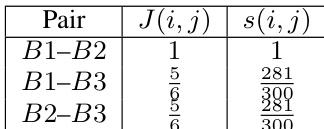
The authors evaluate lexical overlap between their synthesized training data and evaluation benchmarks using n-gram Jaccard similarity, finding near-zero contamination across both GPQA-Diamond and HLE. This indicates that performance gains are not due to memorization or data leakage, but reflect genuine improvements in reasoning capability. The results support the validity of the model’s generalization to unseen, challenging problems.

The authors use a synthesized dataset called CHIMERA to fine-tune a 4B-parameter base model, achieving performance competitive with models up to two orders of magnitude larger. Results show consistent gains across multiple reasoning benchmarks, with supervised fine-tuning alone accounting for most of the improvement, indicating the dataset’s high quality and difficulty. Inference-time scaling further reveals enhanced reasoning robustness, as performance gaps widen with increased sampling, suggesting broader coverage of valid solution paths.