HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

言語中心のオムニモーダル表現学習のスケーリング

DITING:ウェブ小説翻訳のベンチマーク評価を目的としたマルチエージェント評価フレームワーク
























言語中心のオムニモーダル表現学習のスケーリング
DITING:ウェブ小説翻訳のベンチマーク評価を目的としたマルチエージェント評価フレームワーク
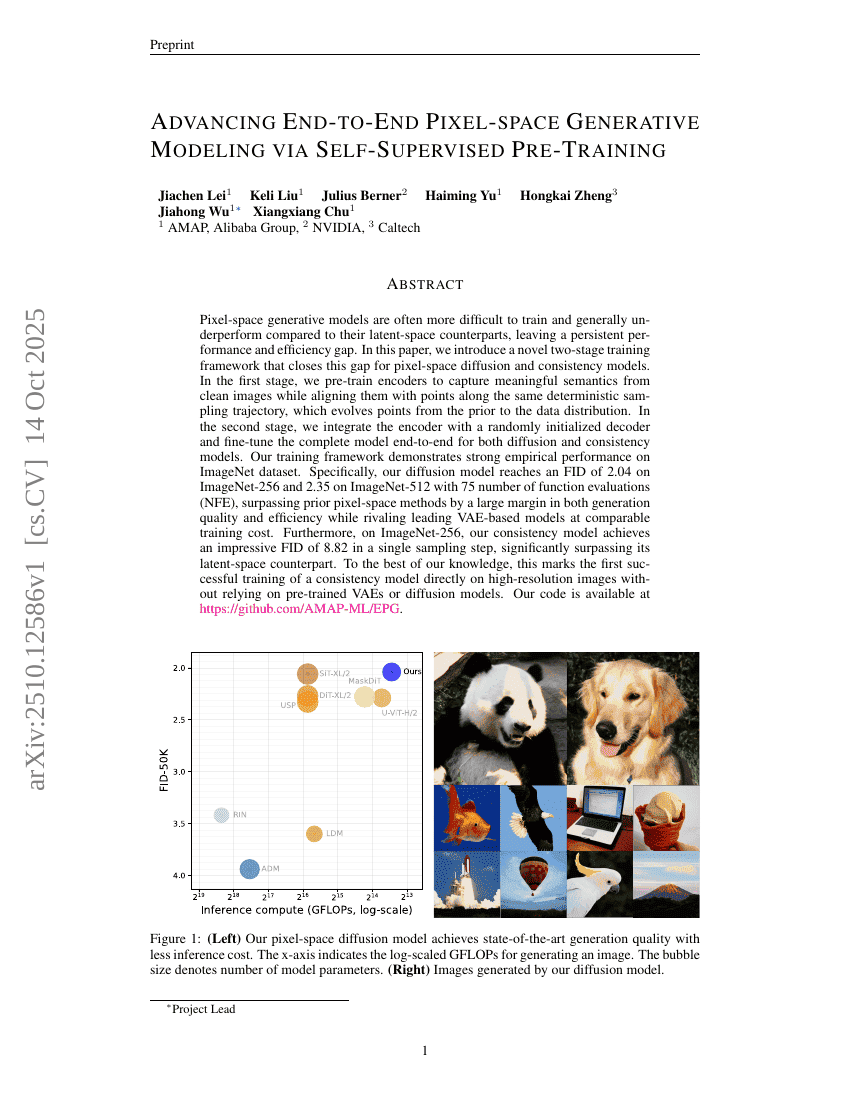
自己教師あり事前学習を活用したエンドツーエンド型ピクセル空間生成モデリングの進展
空間的強制:視覚言語行動モデルにおける暗黙的空間表現の整合
大規模言語モデルを用いた好みの獲得における明確化質問の提示
CTRL-Rec:自然言語によるレコメンデーションシステムの制御
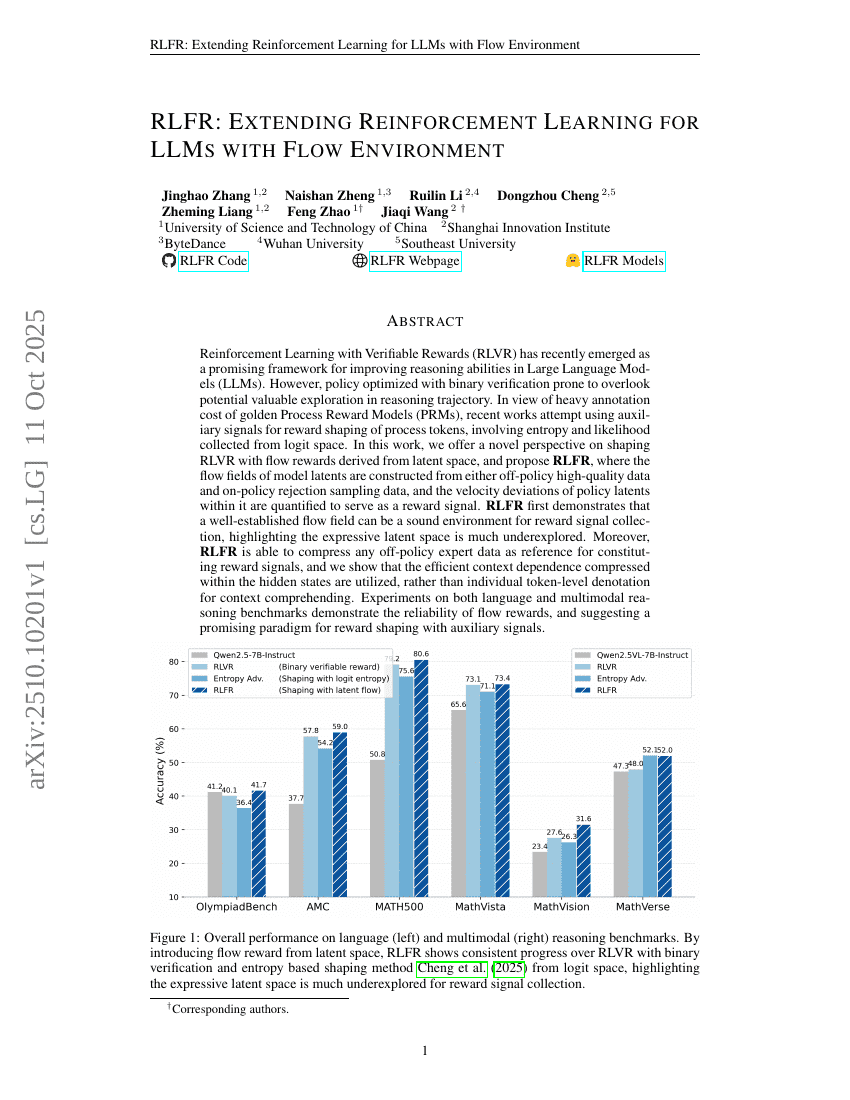
RLFR:フローエンバイロメントを用いた大規模言語モデル向け強化学習の拡張
潜在精製デコーディング:信念状態の精製による拡散型言語モデルの性能向上
OmniVideoBench:オムニマルチモーダル大規模言語モデルにおける音声視覚理解評価への道標
BEAR:原子的な身体的機能を備えたマルチモーダル言語モデルのベンチマーク設定と性能向上
表現自己符号化器を用いた拡散変換器
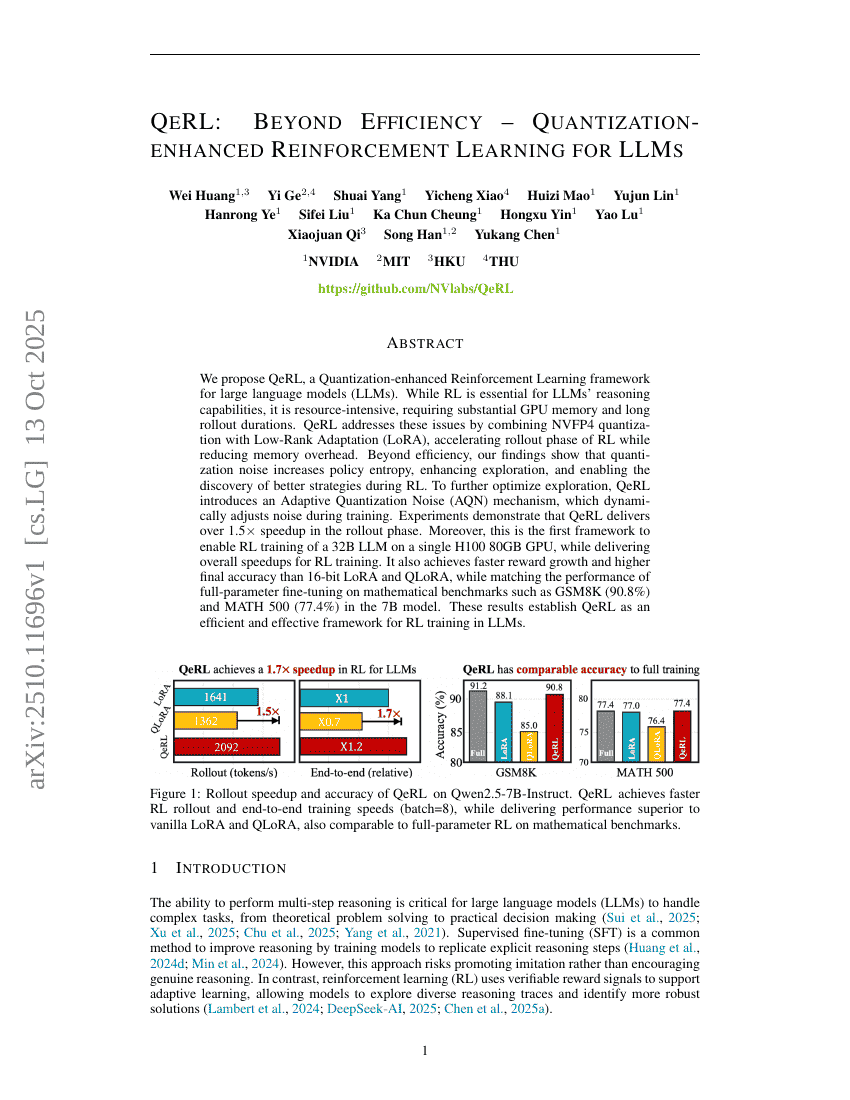
QeRL:効率性を越えて――量子化拡張型強化学習による大規模言語モデル向けアプローチ
逆行列を必要としないウィルソン環:変換器における不変性および順序敏感性の実用的診断
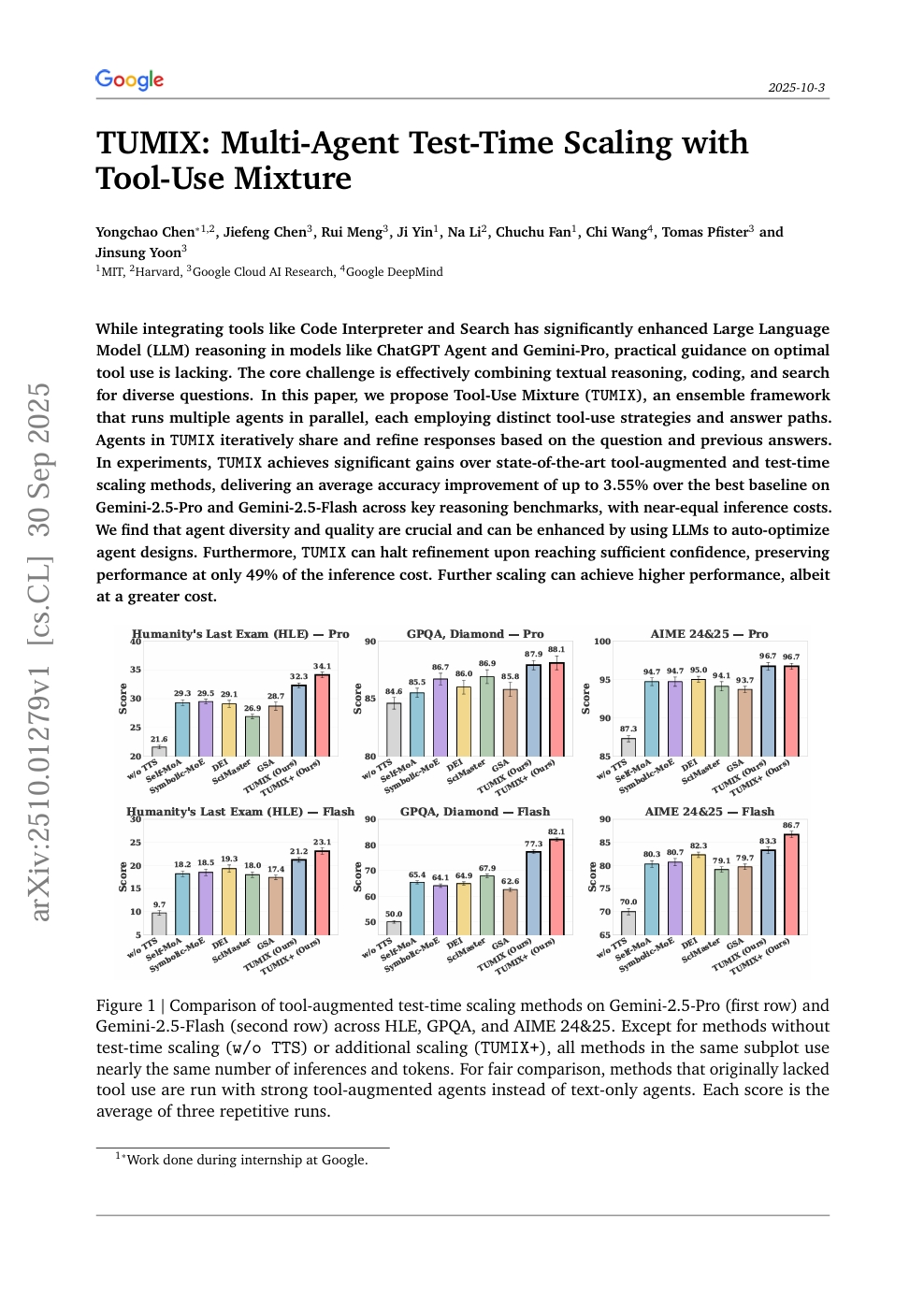
TUMIX:ツール利用混合を用いたマルチエージェントのテスト時スケーリング
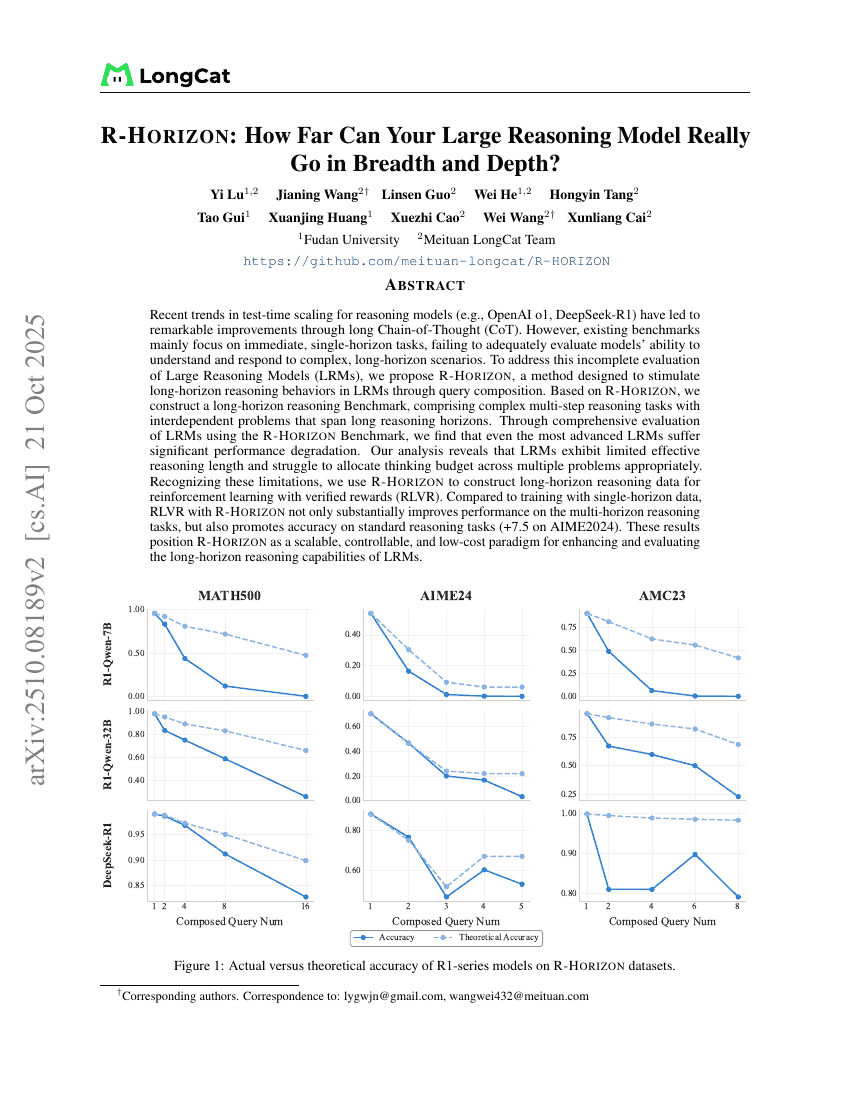
R-Horizon:大規模な推論モデルの広がりと深さにおける到達可能範囲はどこまでか?
AutoPR:学術昇進を自動化しましょう!
マルチモーダル・プロンプト最適化:MLLMsにおいて複数のモダリティを活用しない理由は何か
補正方向誘導による妄想耐性のある拡散サンプリング
カメラで考える:カメラ中心の理解と生成のための統合型マルチモーダルモデル
D2E:エムボディドAIへの転移を目的としたデスクトップデータ上の視覚-行動事前学習のスケーリング
Code2Video:教育用動画生成のためのコード中心型パラダイム
バイアス博士:AIを活用した医療支援における社会的格差
大規模言語モデルにおける2次最適化の可能性:フル・ガウス・ニュートン法を用いた研究
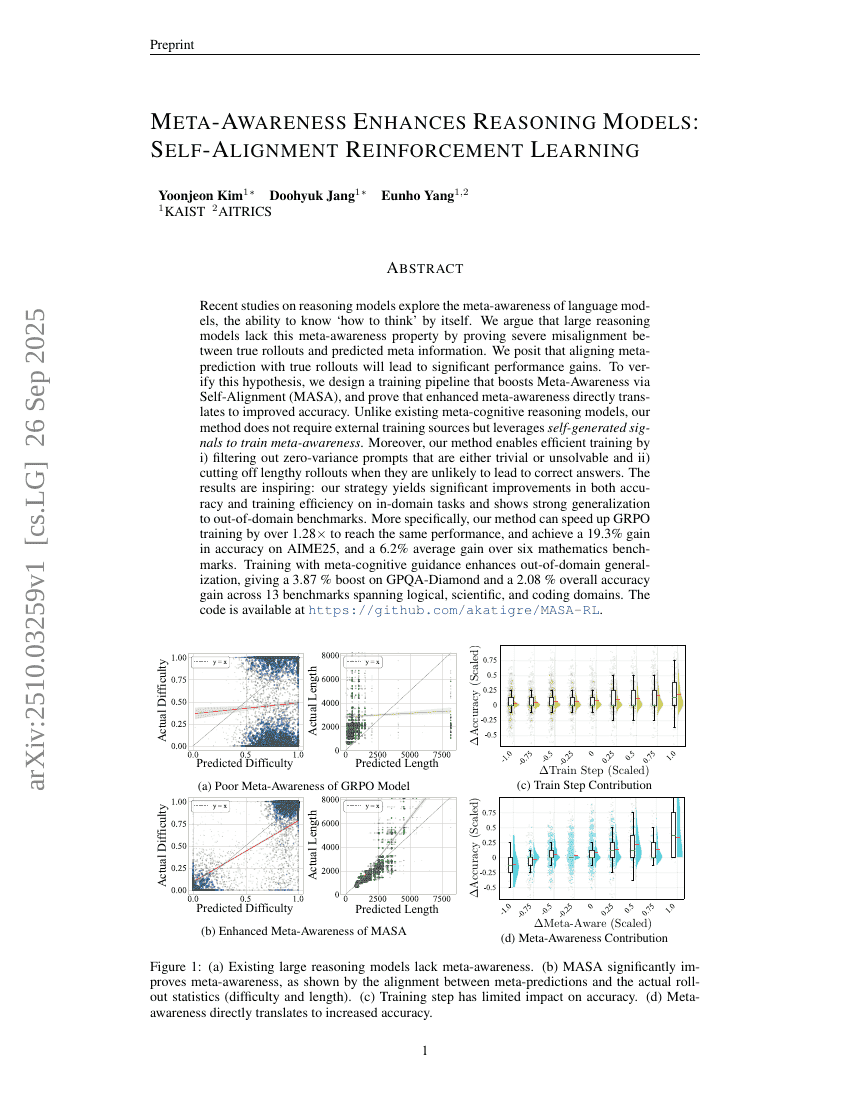
メタ認識が推論モデルを向上させる:自己整合強化学習
何が起こったかからなぜ起こったかへ:根拠に基づく化学反応条件の推論のためのマルチエージェントシステム
DreamOmni2:マルチモーダルな指示ベースの編集と生成
VideoCanvas:文脈条件付きによる任意の時空間パッチからの統一的動画補完
UniVideo:動画の統合的理解・生成・編集
MemMamba:状態空間モデルにおけるメモリパターンの再考
PromptCoT 2.0:大規模言語モデル推論のためのプロンプト生成のスケーリング
抽出-0:ドキュメント情報抽出のための専門化された言語モデル
オムニリターゲット:ヒューマノイド全身運動と操作およびシーンインタラクションのためのインタラクション保持型データ生成
自己教師あり事前学習を活用したエンドツーエンド型ピクセル空間生成モデリングの進展
空間的強制:視覚言語行動モデルにおける暗黙的空間表現の整合
大規模言語モデルを用いた好みの獲得における明確化質問の提示
CTRL-Rec:自然言語によるレコメンデーションシステムの制御
RLFR:フローエンバイロメントを用いた大規模言語モデル向け強化学習の拡張
潜在精製デコーディング:信念状態の精製による拡散型言語モデルの性能向上
OmniVideoBench:オムニマルチモーダル大規模言語モデルにおける音声視覚理解評価への道標
BEAR:原子的な身体的機能を備えたマルチモーダル言語モデルのベンチマーク設定と性能向上
表現自己符号化器を用いた拡散変換器
QeRL:効率性を越えて――量子化拡張型強化学習による大規模言語モデル向けアプローチ
逆行列を必要としないウィルソン環:変換器における不変性および順序敏感性の実用的診断
TUMIX:ツール利用混合を用いたマルチエージェントのテスト時スケーリング
R-Horizon:大規模な推論モデルの広がりと深さにおける到達可能範囲はどこまでか?
AutoPR:学術昇進を自動化しましょう!
マルチモーダル・プロンプト最適化:MLLMsにおいて複数のモダリティを活用しない理由は何か
補正方向誘導による妄想耐性のある拡散サンプリング
カメラで考える:カメラ中心の理解と生成のための統合型マルチモーダルモデル
D2E:エムボディドAIへの転移を目的としたデスクトップデータ上の視覚-行動事前学習のスケーリング
Code2Video:教育用動画生成のためのコード中心型パラダイム
バイアス博士:AIを活用した医療支援における社会的格差
大規模言語モデルにおける2次最適化の可能性:フル・ガウス・ニュートン法を用いた研究
メタ認識が推論モデルを向上させる:自己整合強化学習
何が起こったかからなぜ起こったかへ:根拠に基づく化学反応条件の推論のためのマルチエージェントシステム
DreamOmni2:マルチモーダルな指示ベースの編集と生成
VideoCanvas:文脈条件付きによる任意の時空間パッチからの統一的動画補完
UniVideo:動画の統合的理解・生成・編集
MemMamba:状態空間モデルにおけるメモリパターンの再考
PromptCoT 2.0:大規模言語モデル推論のためのプロンプト生成のスケーリング
抽出-0:ドキュメント情報抽出のための専門化された言語モデル
オムニリターゲット:ヒューマノイド全身運動と操作およびシーンインタラクションのためのインタラクション保持型データ生成