HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

RAVine:エージェンティック検索におけるリアリティ対応評価

一つのドメインが他のドメインを助けることは可能か? マルチドメイン推論におけるデータ中心の研究:強化学習を用いて






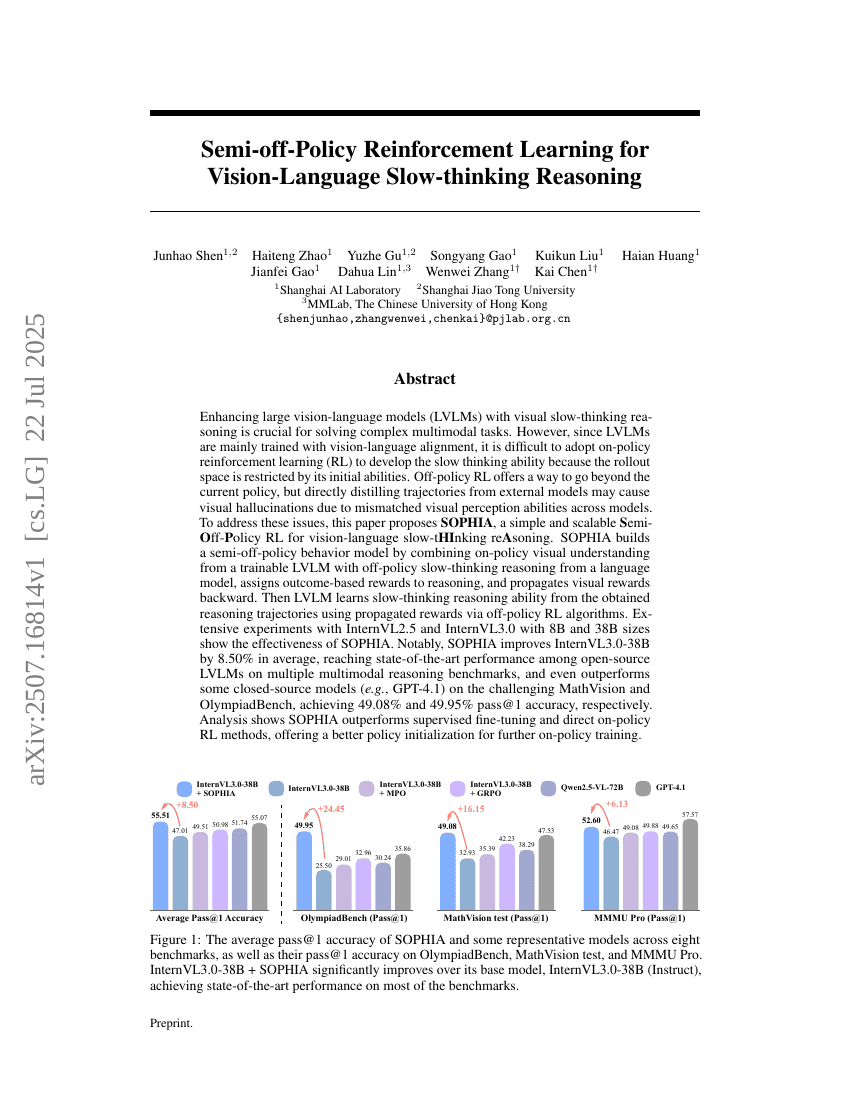

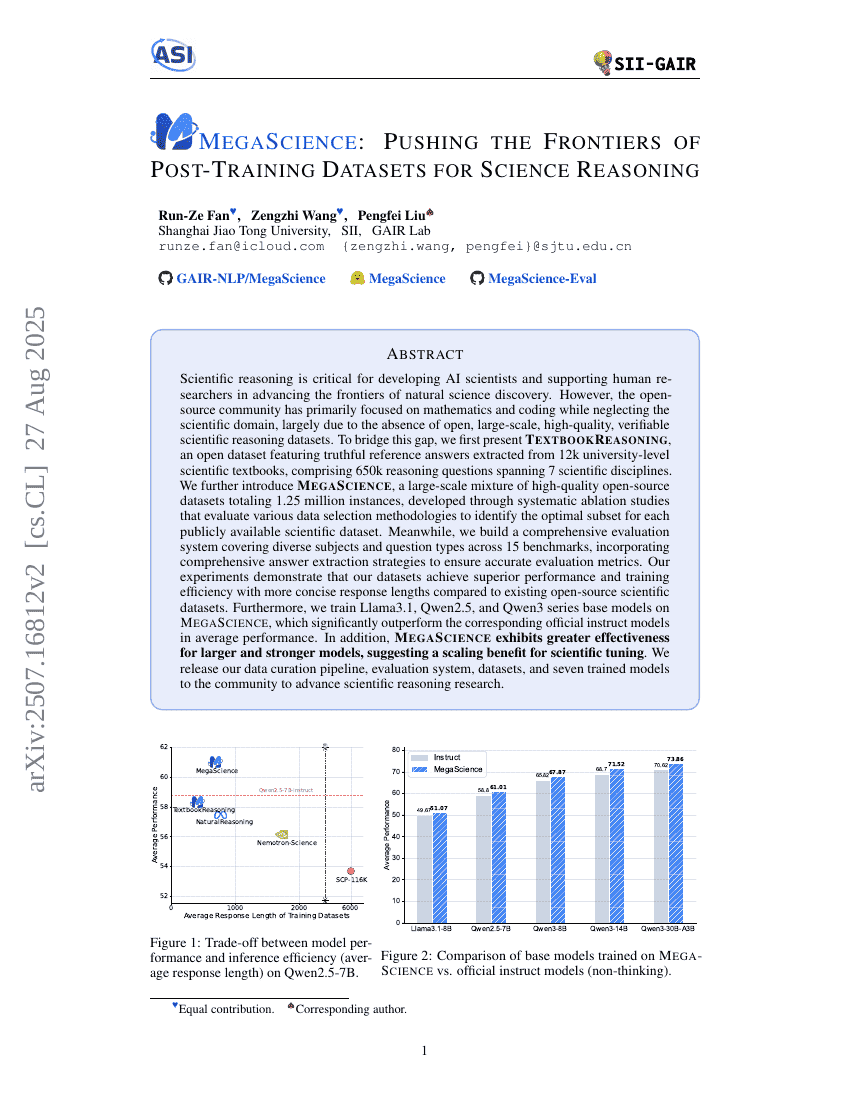






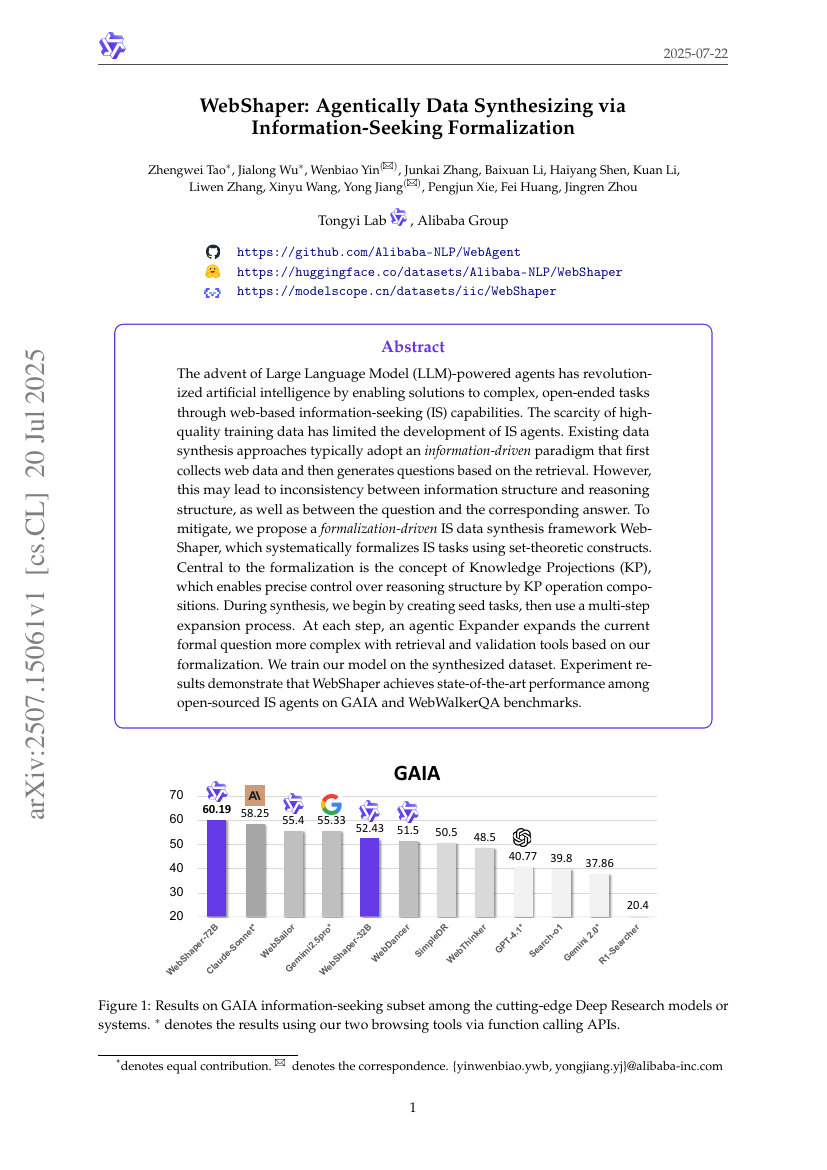

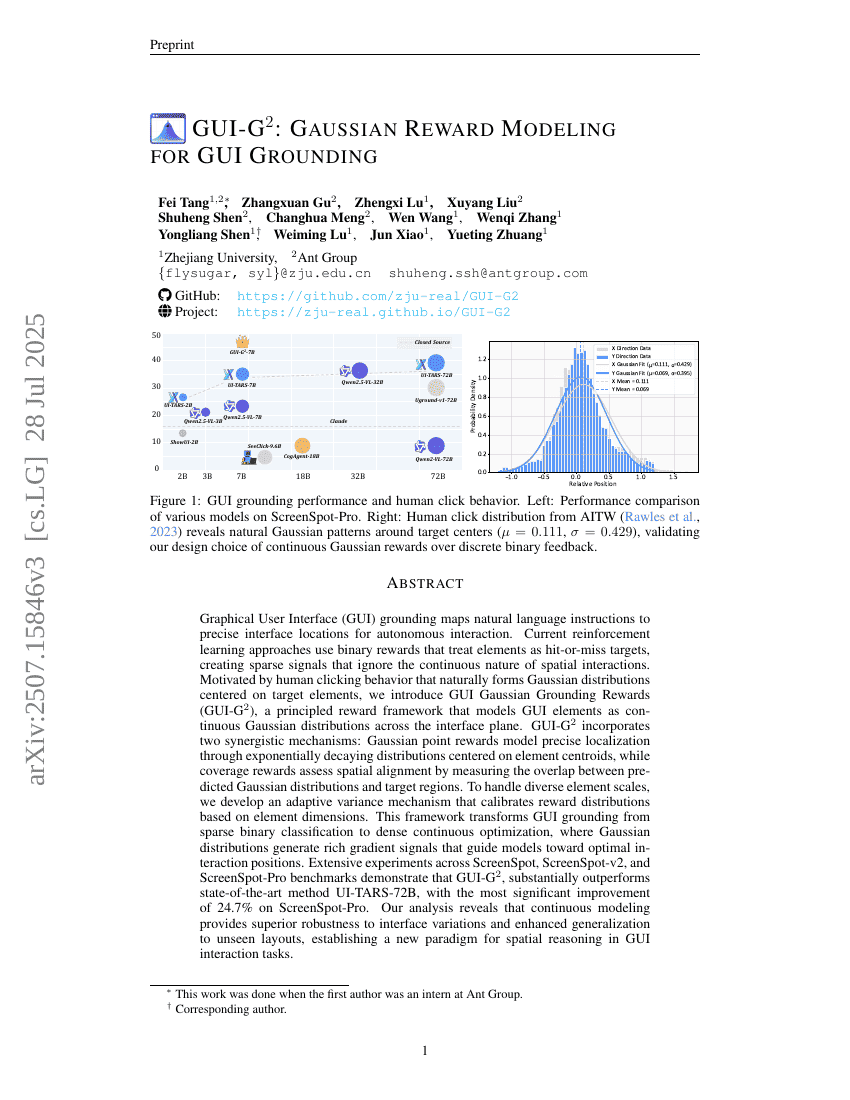









RAVine:エージェンティック検索におけるリアリティ対応評価
一つのドメインが他のドメインを助けることは可能か? マルチドメイン推論におけるデータ中心の研究:強化学習を用いて
DesignLab:反復的な検出と修正を通じたスライドの設計
ユメ:インタラクティブな世界生成モデル
画素、パターン、しかし詩はなし:人間のように世界を見る
眼科用MLLMの構築:臨床的認知チェーン推論を用いた位置診断協働
HySafe-AI:AIシステムのためのハイブリッドセーフティアーキテクチャ分析フレームワーク:ケーススタディ
ゼブラ・コット:インタリーブドビジョン言語推論のためのデータセット
視覚言語におけるスローサイティングのためのセミオフポリシーバイアス強化学習
重要な部分をアップサンプルする:拡散トランスフォーマーのための領域適応型潜在サンプリング
メガサイエンス:サイエンス推論のためのトレーニング後データセットの限界を突き進める
ステップオーディオ2 技術報告書
文脈の限界を越えて:長期的な推論のための無意識的なつながり
実践におけるフロントランクAIリスク管理枠組み:リスク分析技術報告書
不確実性を考慮した知識トランスフォーマーを用いたマルチエージェント強化学習によるピアツーピアエネルギー取引
人間不要:自律型高品質画像編集三つ組み抽出
3Dガウススパッタリングにおける正則化スコア分散サンプリングを用いたロバストな3Dマスク付きパーツレベル編集
WebShaper:情報探索を用いたエージェンティックなデータ合成の形式化
見えないリード:なぜRLVRはその起源から逃れられないのか
GUI-G^2:GUIの基盤におけるガウス報酬モデル化
MiroMind-M1:コンテキストに配慮したマルチステージポリシー最適化による数学的推論のオープンソースな進展
内在的不順序領域結合タンパク質の設計
全原子生成モデルによるタンパク質複合体の設計
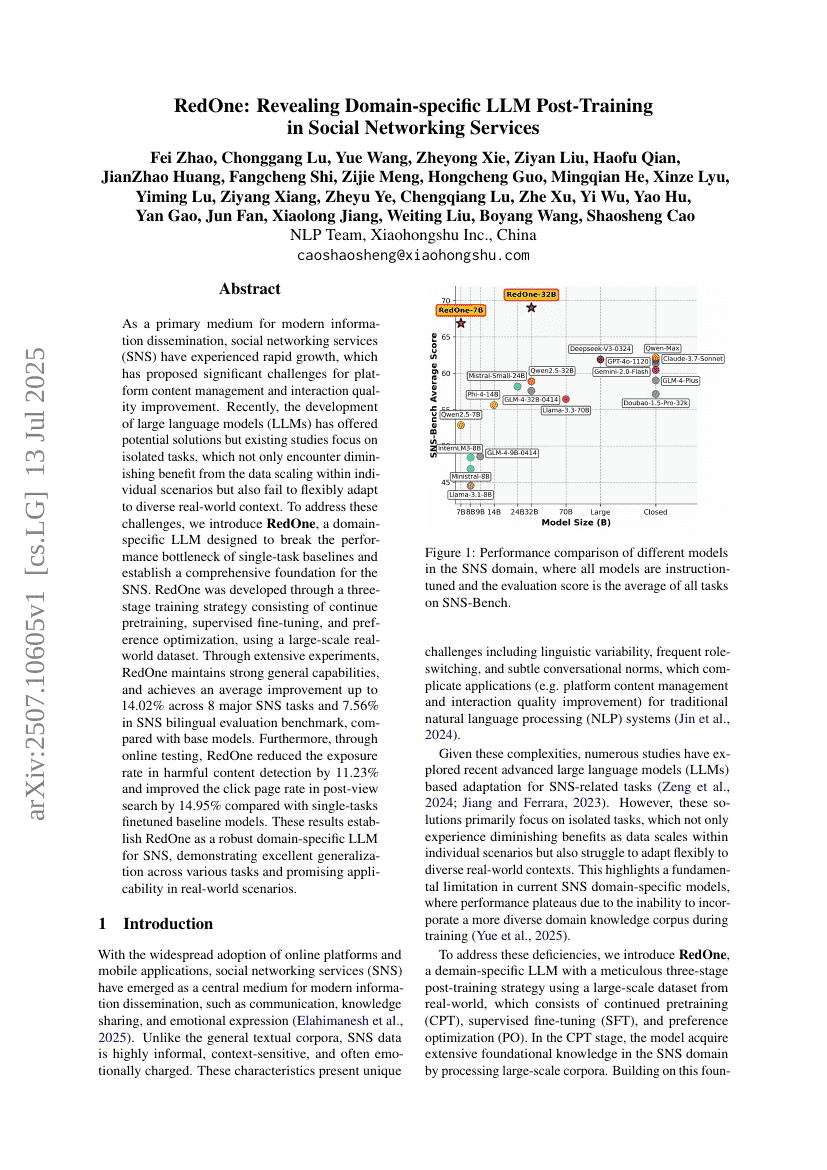
RedOne: ソーシャルネットワーキングサービスにおけるドメイン固有のLLMポストトレーニングの解明
CSD-VAR: 可視自己回帰モデルにおける内容-スタイル分解
Mono-InternVL-1.5: 安価で高速なモノリシックマルチモーダル大規模言語モデルへの道
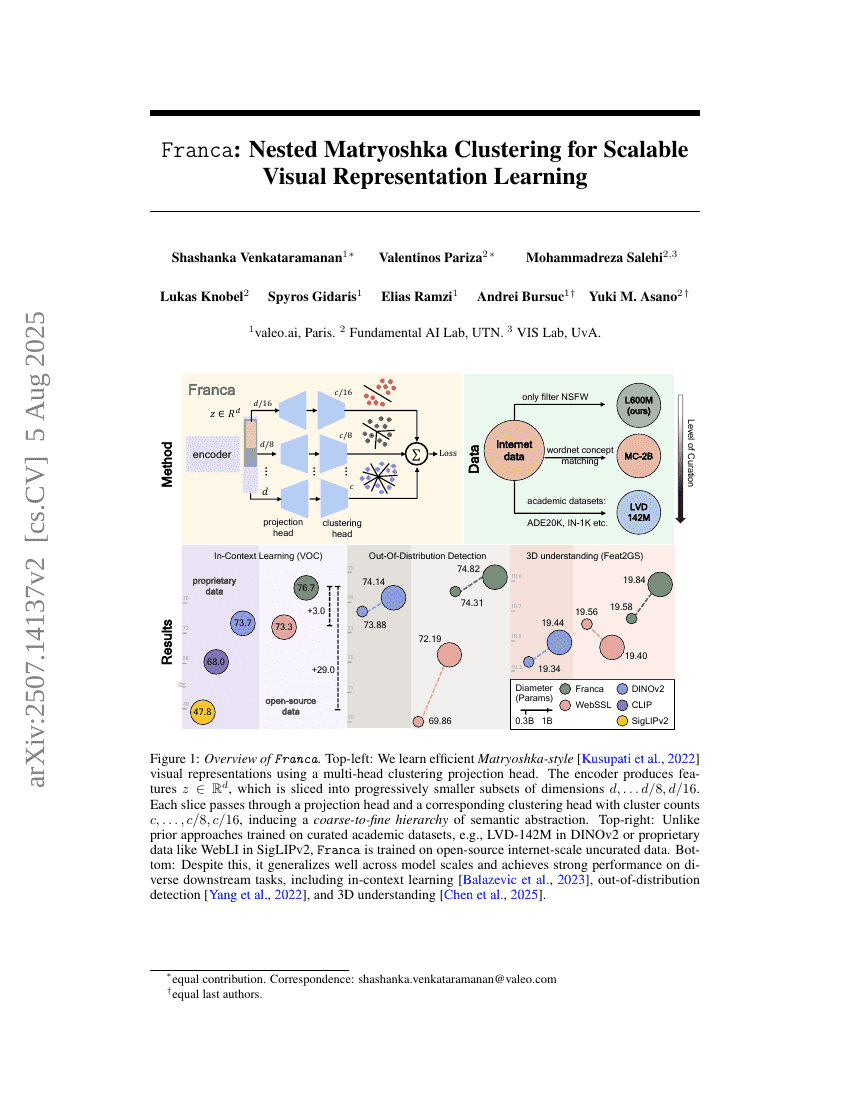
フランカ: スケーラブルな視覚表現学習のためのネストされたマトリョーシカクラスタリング
データ中心のフレームワークによるロシア語音声生成モデルにおける音韻と抑揚の課題解決
マスクの裏の悪魔:拡散LLMの新規安全性脆弱性
PrefPalette: 潜在属性を用いたパーソナライズされた嗜好モデリング
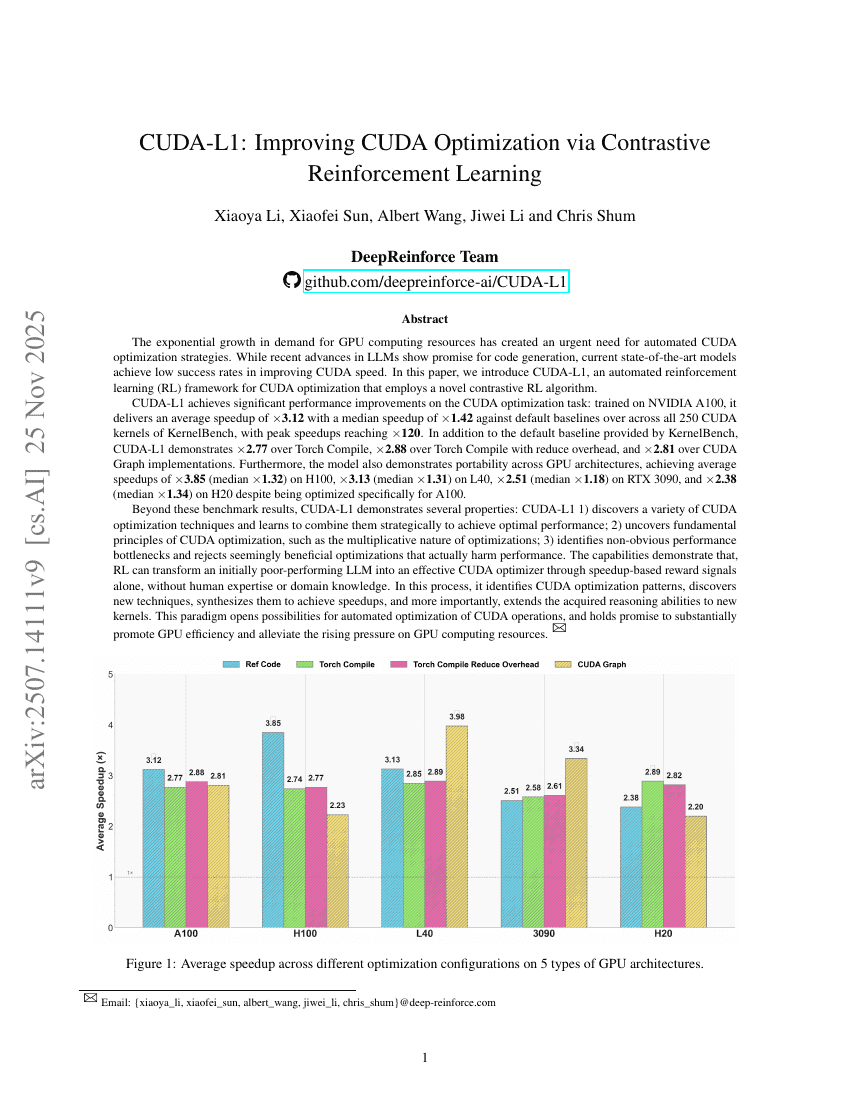
CUDA-L1:対照強化学習を活用したCUDA最適化の向上
AnyCapプロジェクト:制御可能なオムニモーダルキャプショニングの統一フレームワーク、データセット、およびベンチマーク
DesignLab:反復的な検出と修正を通じたスライドの設計
ユメ:インタラクティブな世界生成モデル
画素、パターン、しかし詩はなし:人間のように世界を見る
眼科用MLLMの構築:臨床的認知チェーン推論を用いた位置診断協働
HySafe-AI:AIシステムのためのハイブリッドセーフティアーキテクチャ分析フレームワーク:ケーススタディ
ゼブラ・コット:インタリーブドビジョン言語推論のためのデータセット
視覚言語におけるスローサイティングのためのセミオフポリシーバイアス強化学習
重要な部分をアップサンプルする:拡散トランスフォーマーのための領域適応型潜在サンプリング
メガサイエンス:サイエンス推論のためのトレーニング後データセットの限界を突き進める
ステップオーディオ2 技術報告書
文脈の限界を越えて:長期的な推論のための無意識的なつながり
実践におけるフロントランクAIリスク管理枠組み:リスク分析技術報告書
不確実性を考慮した知識トランスフォーマーを用いたマルチエージェント強化学習によるピアツーピアエネルギー取引
人間不要:自律型高品質画像編集三つ組み抽出
3Dガウススパッタリングにおける正則化スコア分散サンプリングを用いたロバストな3Dマスク付きパーツレベル編集
WebShaper:情報探索を用いたエージェンティックなデータ合成の形式化
見えないリード:なぜRLVRはその起源から逃れられないのか
GUI-G^2:GUIの基盤におけるガウス報酬モデル化
MiroMind-M1:コンテキストに配慮したマルチステージポリシー最適化による数学的推論のオープンソースな進展
内在的不順序領域結合タンパク質の設計
全原子生成モデルによるタンパク質複合体の設計
RedOne: ソーシャルネットワーキングサービスにおけるドメイン固有のLLMポストトレーニングの解明
CSD-VAR: 可視自己回帰モデルにおける内容-スタイル分解
Mono-InternVL-1.5: 安価で高速なモノリシックマルチモーダル大規模言語モデルへの道
フランカ: スケーラブルな視覚表現学習のためのネストされたマトリョーシカクラスタリング
データ中心のフレームワークによるロシア語音声生成モデルにおける音韻と抑揚の課題解決
マスクの裏の悪魔:拡散LLMの新規安全性脆弱性
PrefPalette: 潜在属性を用いたパーソナライズされた嗜好モデリング
CUDA-L1:対照強化学習を活用したCUDA最適化の向上
AnyCapプロジェクト:制御可能なオムニモーダルキャプショニングの統一フレームワーク、データセット、およびベンチマーク