HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
LLMを活用したエージェントによるドラッグ資産デューデリジェンスにおける競合状況マッピング

SceneGen:1回のフォワードパスによる単一画像からの3Dシーン生成

























LLMを活用したエージェントによるドラッグ資産デューデリジェンスにおける競合状況マッピング
SceneGen:1回のフォワードパスによる単一画像からの3Dシーン生成
大規模言語モデルベンチマークに関する調査
Waver:リアルな動画生成へ向かう波を操る
LiveMCP-101:挑戦的なクエリにおけるMCP対応エージェントのストレステストと診断
自信を持って深く考える
Mobile-Agent-v3:GUI自動化のための基盤エージェント
Intern-S1:科学用マルチモーダル基盤モデル
言語誘導型チューニング:テキストフィードバックを活用した数値最適化の向上
NiceWebRL:強化学習環境を用いた被験者実験用Pythonライブラリ
サイエンスのためのAIからエージェント型サイエンスへ:自律的科学発見に関するサーベイ
MeshCoder:点群からの構造化メッシュコード生成を実現するLLM駆動型手法
Tinker:拡散モデルが3Dにもたらす贈り物——シーン最適化を必要としないスパース入力からの多視点一貫性のある編集
FutureX:未来予測におけるLLMエージェント向け高度なライブベンチマーク
DuPO:二重選好に基づく信頼性のあるLLM自己検証の実現
スコアからスキルへ:金融分野向け大規模言語モデルの評価を目的とした認知診断枠組み
グランアリー:25ヶ国語における音声認識および翻訳データセット
TransLLM:学習可能プロンプトを用いた都市交通向け統合型マルチタスク基盤フレームワーク
量子化とdLLMsの融合:拡散LLMにおける事後量子化の系統的研究
訓練不要なテキスト誘導型カラーディターリング手法:マルチモーダル拡散トランスフォーマーを用いた手法
プロファイルを意識したLLMをジャッジとして用いたポッドキャスト推薦の評価
MultiRef:複数の視覚的参照を用いた制御可能な画像生成
プロンプトオーケストレーションマークアップ言語
LongSplat:カジュアルな長時間動画向けのロバストな非姿勢制約3Dガウススプラッティング
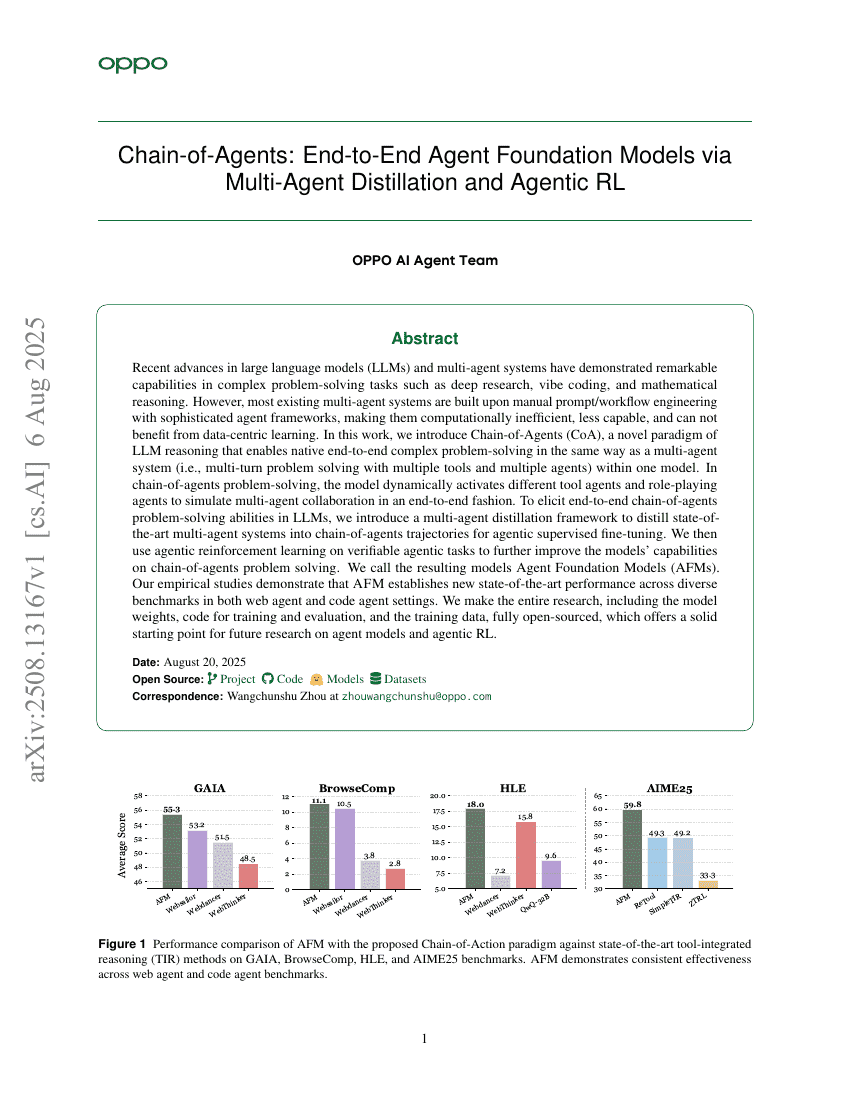
エージェント連鎖:マルチエージェント蒸留とエージェント型RLによるエンドツーエンドエージェント基盤モデル
HPSv3:広範囲な人間の好みスコアへの挑戦
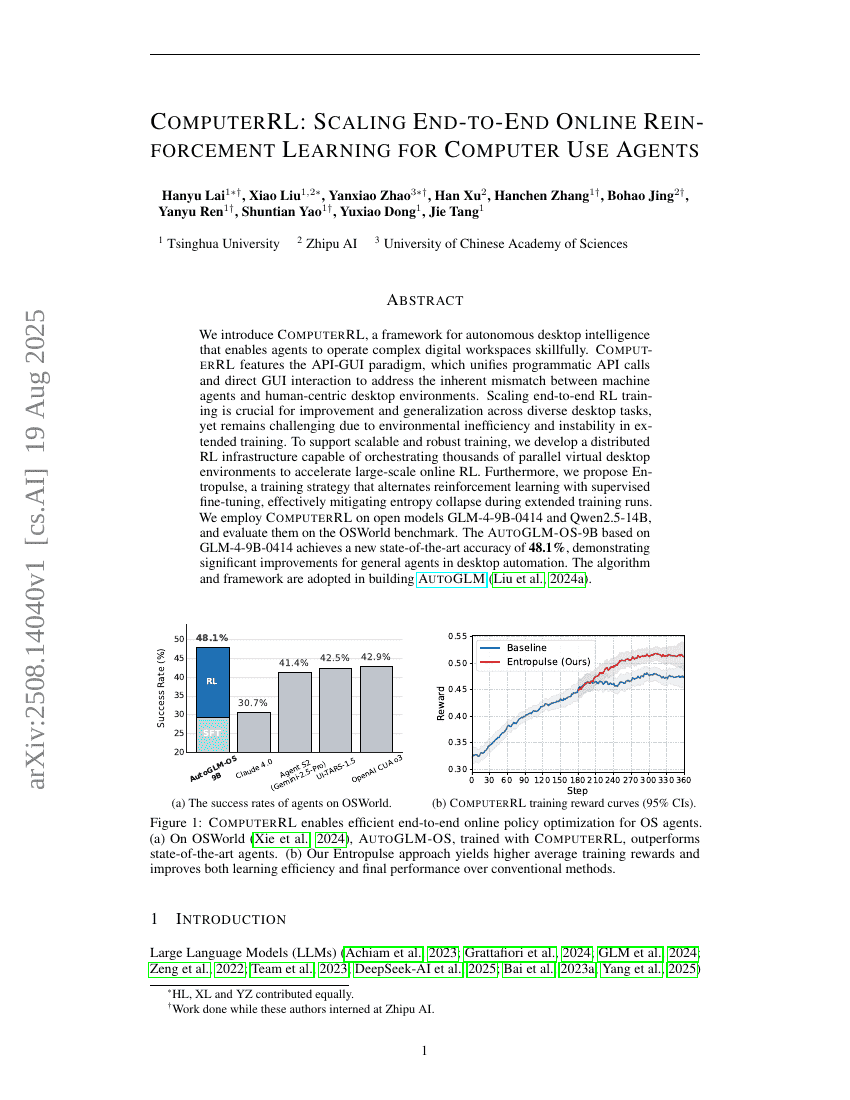
ComputerRL:コンピュータ利用エージェント向けエンドツーエンドオンライン強化学習のスケーリング
発話者識別情報の漏洩評価に関する研究
次に視覚的粒度生成を実行する
4DNeX:フォワード・プロパゲーションによる4D生成モデリングの簡便化
ComoRAG:状態保持型長文推論のための認知にインスパイアされた記憶組織型RAG
広帯域計算および通信を実現する統合型マイクロ波ニューラルネットワーク
大規模言語モデルベンチマークに関する調査
Waver:リアルな動画生成へ向かう波を操る
LiveMCP-101:挑戦的なクエリにおけるMCP対応エージェントのストレステストと診断
自信を持って深く考える
Mobile-Agent-v3:GUI自動化のための基盤エージェント
Intern-S1:科学用マルチモーダル基盤モデル
言語誘導型チューニング:テキストフィードバックを活用した数値最適化の向上
NiceWebRL:強化学習環境を用いた被験者実験用Pythonライブラリ
サイエンスのためのAIからエージェント型サイエンスへ:自律的科学発見に関するサーベイ
MeshCoder:点群からの構造化メッシュコード生成を実現するLLM駆動型手法
Tinker:拡散モデルが3Dにもたらす贈り物——シーン最適化を必要としないスパース入力からの多視点一貫性のある編集
FutureX:未来予測におけるLLMエージェント向け高度なライブベンチマーク
DuPO:二重選好に基づく信頼性のあるLLM自己検証の実現
スコアからスキルへ:金融分野向け大規模言語モデルの評価を目的とした認知診断枠組み
グランアリー:25ヶ国語における音声認識および翻訳データセット
TransLLM:学習可能プロンプトを用いた都市交通向け統合型マルチタスク基盤フレームワーク
量子化とdLLMsの融合:拡散LLMにおける事後量子化の系統的研究
訓練不要なテキスト誘導型カラーディターリング手法:マルチモーダル拡散トランスフォーマーを用いた手法
プロファイルを意識したLLMをジャッジとして用いたポッドキャスト推薦の評価
MultiRef:複数の視覚的参照を用いた制御可能な画像生成
プロンプトオーケストレーションマークアップ言語
LongSplat:カジュアルな長時間動画向けのロバストな非姿勢制約3Dガウススプラッティング
エージェント連鎖:マルチエージェント蒸留とエージェント型RLによるエンドツーエンドエージェント基盤モデル
HPSv3:広範囲な人間の好みスコアへの挑戦
ComputerRL:コンピュータ利用エージェント向けエンドツーエンドオンライン強化学習のスケーリング
発話者識別情報の漏洩評価に関する研究
次に視覚的粒度生成を実行する
4DNeX:フォワード・プロパゲーションによる4D生成モデリングの簡便化
ComoRAG:状態保持型長文推論のための認知にインスパイアされた記憶組織型RAG
広帯域計算および通信を実現する統合型マイクロ波ニューラルネットワーク