HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

MIDAS:リアルタイム自己回帰型動画生成を活用したマルチモーダルインタラクティブなデジタル人間合成

離散拡散VLA:視覚言語行動方策における行動復元に離散拡散を導入する
























MIDAS:リアルタイム自己回帰型動画生成を活用したマルチモーダルインタラクティブなデジタル人間合成
離散拡散VLA:視覚言語行動方策における行動復元に離散拡散を導入する
推論分解を用いた自己報酬付き視覚言語モデル
転写を越えて:音声認識におけるメカニズム解釈可能性
CODA:分離型強化学習を用いた二大脳コンピュータ利用エージェントにおける大脳と小脳の連携
WebSight:ロバストなWebエージェント向けのビジョンファーストアーキテクチャ
UltraMemV2:1200億パラメータにスケーリングするメモリネットワークと優れた長文脈学習
ヘルメス4 技術報告
OmniHuman-1.5:認知シミュレーションによるアバターへの能動的思考の植え込み
VoxHammer:ネイティブ3D空間における訓練不要な高精度・一貫性のある3D編集
CMPhysBench:凝縮系物理学における大規模言語モデルの評価のためのベンチマーク
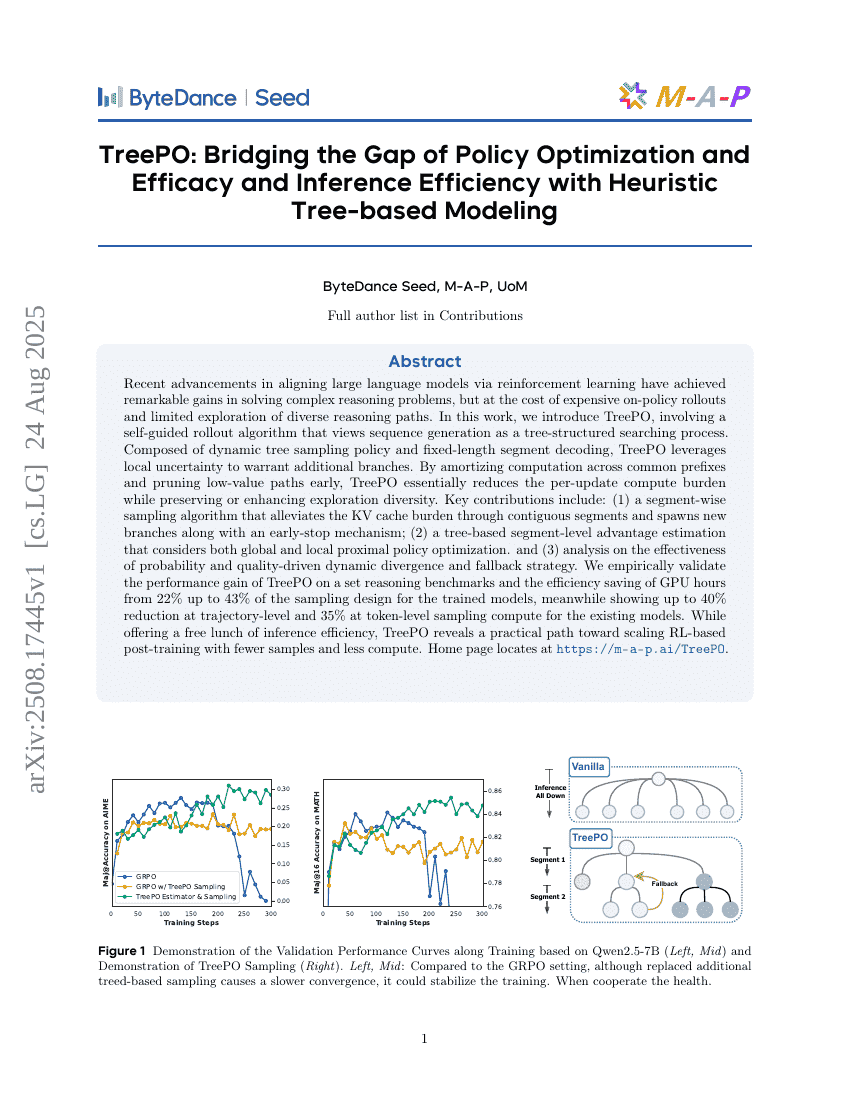
TreePO:ヒューリスティック木ベースモデリングによる方策最適化と効果性、推論効率のギャップ解消
Nemotron-CC-Math:1330億トークン規模の高品質な数学向け事前学習データセット
ツール統合型推論の理解
スペーサー:設計された科学的インスピレーションへ向けて
記憶を超えて:再帰性、記憶、およびテスト時計算スケーリングを活用した推論深度の拡張
バイブボイス技術報告書
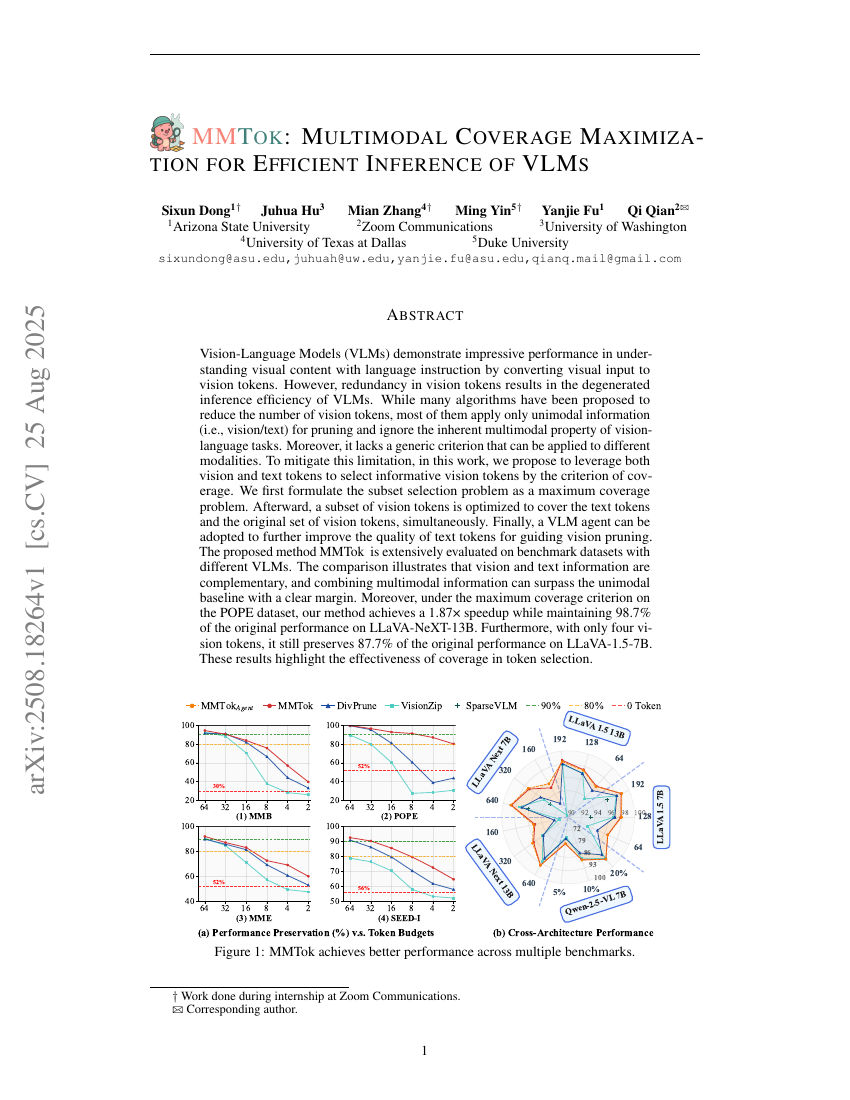
MMTok:VLMの効率的推論のためのマルチモーダルカバレッジ最大化
MV-RAG:リトリーブ拡張マルチビュー拡散
マルチモーダル機械学習を用いた金属有機フレームワークの合成と応用の接続
適応型輸送システムにおけるモデルコンテキストプロトコル:サーベイ
複数の集団を伴うアルゴリズム的集団行動
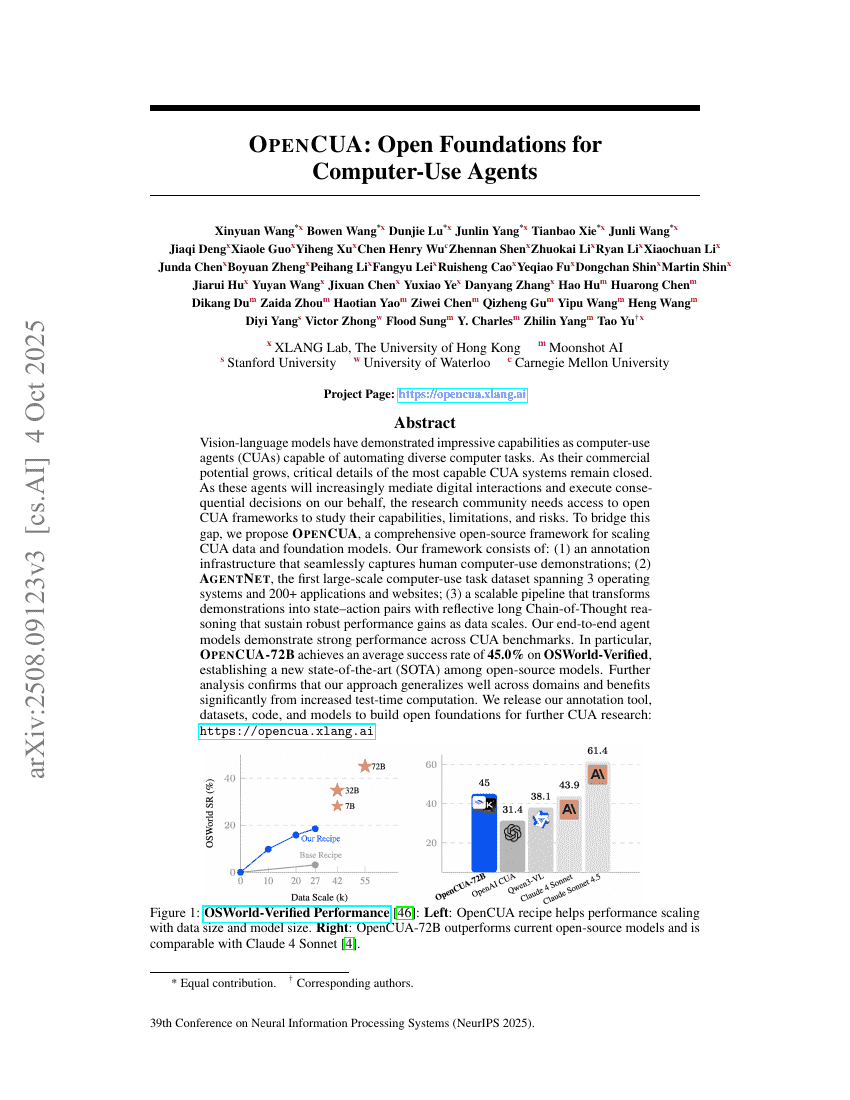
OpenCUA:コンピュータ利用エージェントのためのオープン基盤
空間政策:空間認識モデリングおよび推論を用いた視覚運動ロボット操作のガイドライン
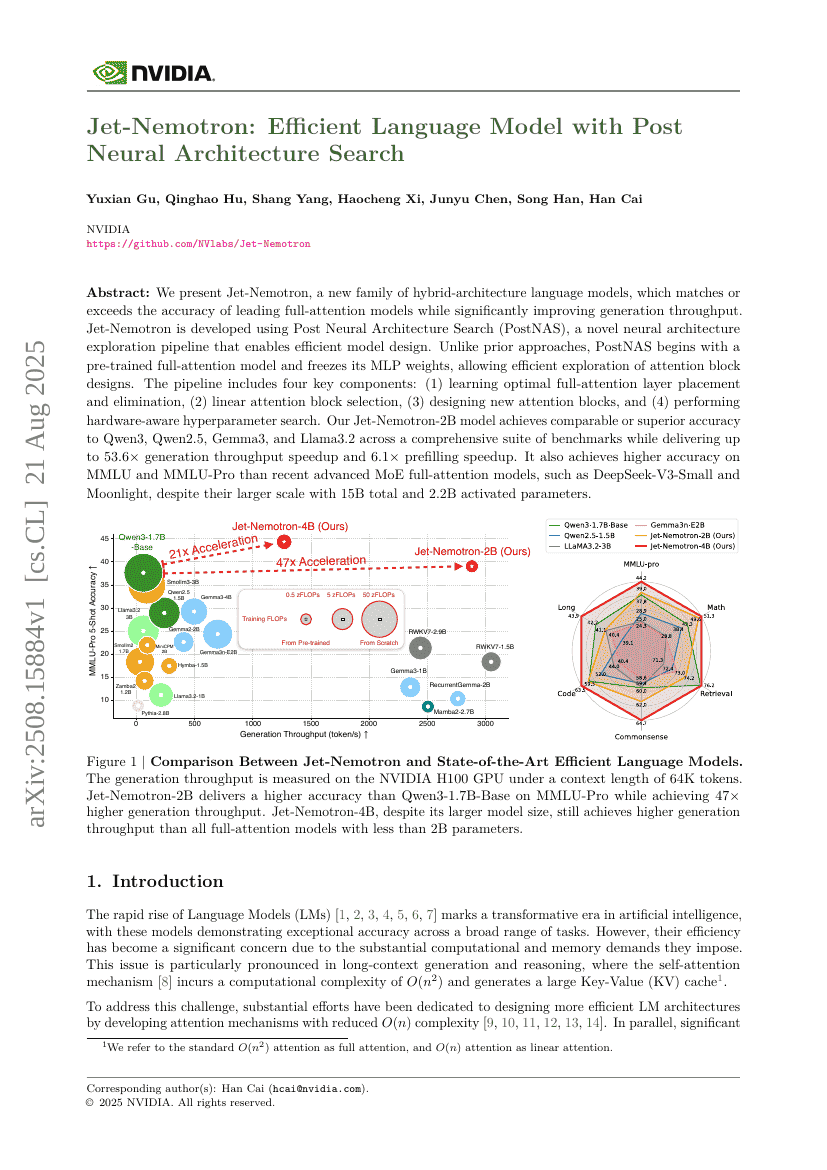
Jet-Nemotron:後段ニューラルアーキテクチャ探索を用いた効率的な言語モデル
CRISP:スパース自己符号化器を用いた恒常的コンセプトの忘却
弱教師付きアフォーダンスのグランドイングにおける選択的コントラスト学習
エゴツイン:第一人称視点における身体と視界の夢
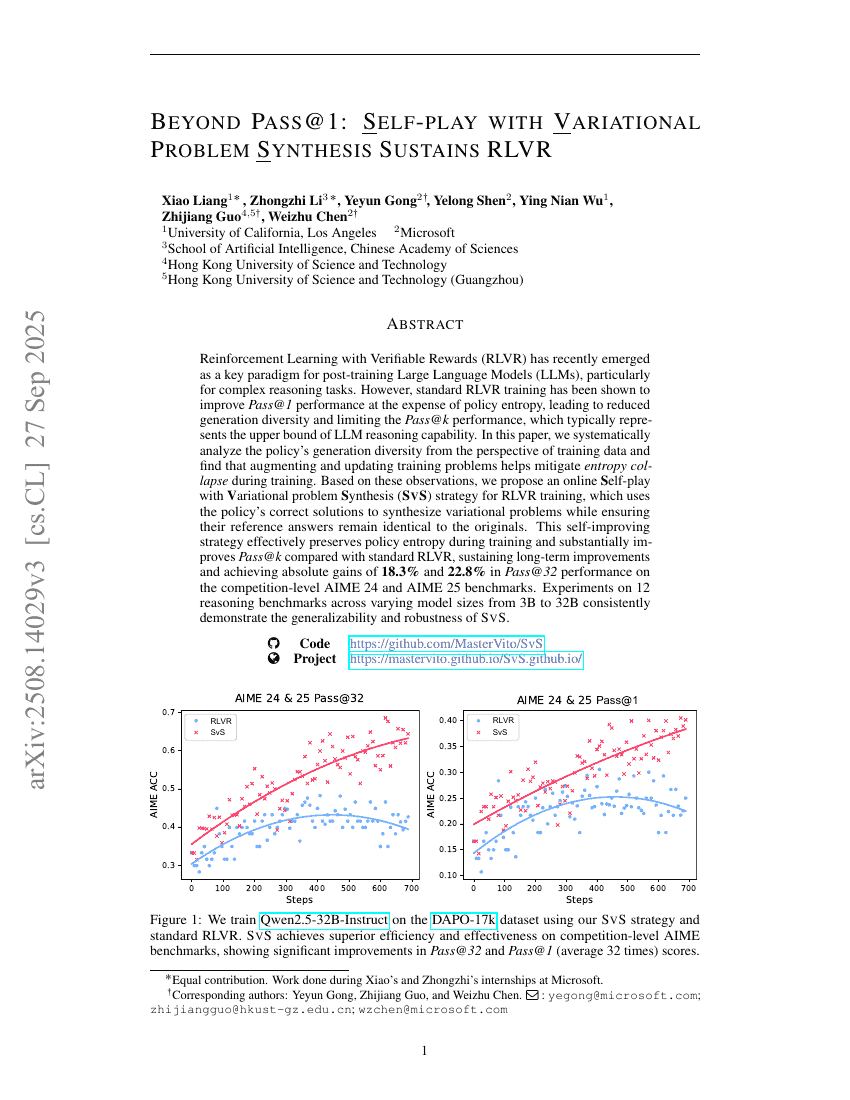
Pass@1を越えて:変分問題生成を用いた自己対戦がRLVRの持続性を支える
ODYSSEY:長時間枠タスクにおけるオープンワールド四足歩行ロボットの探索と操作
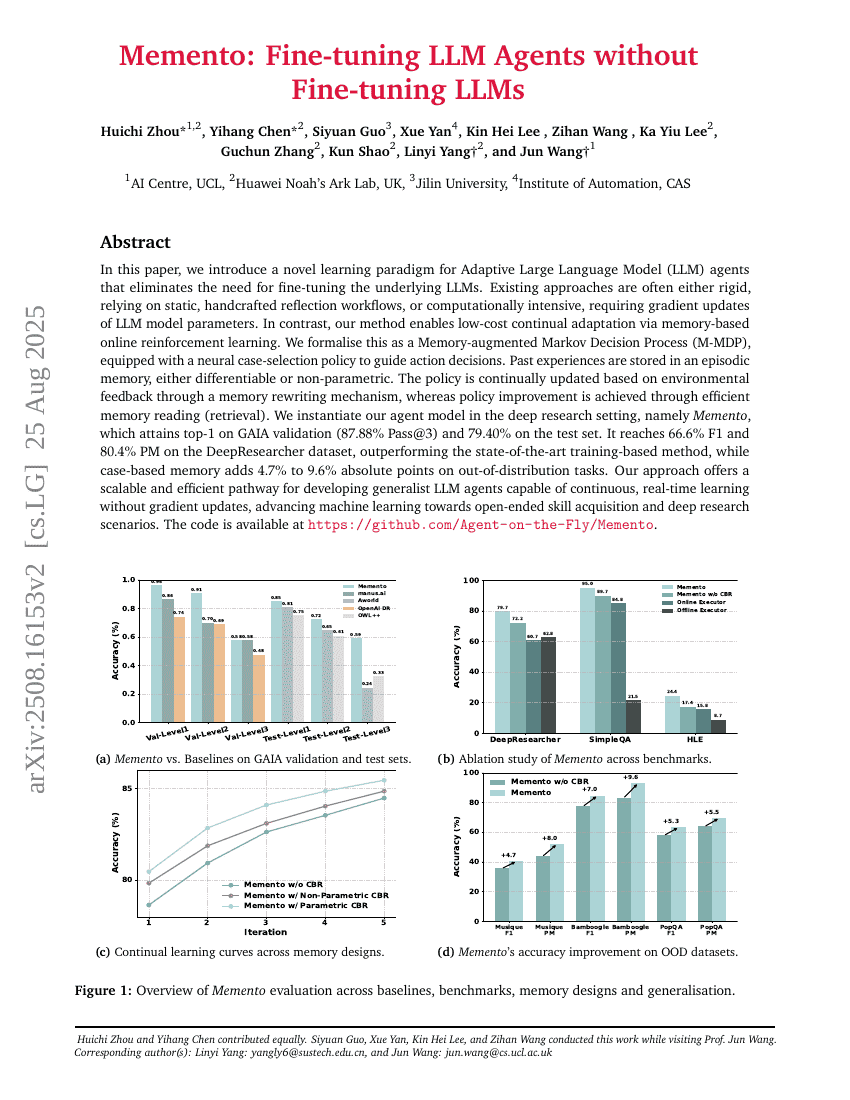
AgentFly: LLMエージェントのファインチューニングによるLLMのファインチューニングなし
制約誘導型拡散推論機構による神経記号学習
推論分解を用いた自己報酬付き視覚言語モデル
転写を越えて:音声認識におけるメカニズム解釈可能性
CODA:分離型強化学習を用いた二大脳コンピュータ利用エージェントにおける大脳と小脳の連携
WebSight:ロバストなWebエージェント向けのビジョンファーストアーキテクチャ
UltraMemV2:1200億パラメータにスケーリングするメモリネットワークと優れた長文脈学習
ヘルメス4 技術報告
OmniHuman-1.5:認知シミュレーションによるアバターへの能動的思考の植え込み
VoxHammer:ネイティブ3D空間における訓練不要な高精度・一貫性のある3D編集
CMPhysBench:凝縮系物理学における大規模言語モデルの評価のためのベンチマーク
TreePO:ヒューリスティック木ベースモデリングによる方策最適化と効果性、推論効率のギャップ解消
Nemotron-CC-Math:1330億トークン規模の高品質な数学向け事前学習データセット
ツール統合型推論の理解
スペーサー:設計された科学的インスピレーションへ向けて
記憶を超えて:再帰性、記憶、およびテスト時計算スケーリングを活用した推論深度の拡張
バイブボイス技術報告書
MMTok:VLMの効率的推論のためのマルチモーダルカバレッジ最大化
MV-RAG:リトリーブ拡張マルチビュー拡散
マルチモーダル機械学習を用いた金属有機フレームワークの合成と応用の接続
適応型輸送システムにおけるモデルコンテキストプロトコル:サーベイ
複数の集団を伴うアルゴリズム的集団行動
OpenCUA:コンピュータ利用エージェントのためのオープン基盤
空間政策:空間認識モデリングおよび推論を用いた視覚運動ロボット操作のガイドライン
Jet-Nemotron:後段ニューラルアーキテクチャ探索を用いた効率的な言語モデル
CRISP:スパース自己符号化器を用いた恒常的コンセプトの忘却
弱教師付きアフォーダンスのグランドイングにおける選択的コントラスト学習
エゴツイン:第一人称視点における身体と視界の夢
Pass@1を越えて:変分問題生成を用いた自己対戦がRLVRの持続性を支える
ODYSSEY:長時間枠タスクにおけるオープンワールド四足歩行ロボットの探索と操作
AgentFly: LLMエージェントのファインチューニングによるLLMのファインチューニングなし
制約誘導型拡散推論機構による神経記号学習