Command Palette
Search for a command to run...
MetaはAIデータサイエンティストを提案し、Autodataは高品質なトレーニング/評価データセットを構築する。

近年、大規模モデルの能力が継続的に向上することで、人工知能の発展の道筋は大きく変化しています。しかし、モデル性能の限界は「アルゴリズム革新主導型」から「データ品質主導型」へと徐々に移行しつつあるという認識が、ますます明確になってきています。高品質な人間によるアノテーション付きデータがますます希少化し、高価になる中で、合成データは学習後の段階において重要な支援手法となりつつあります。合成データは、実世界のコーパスでは比較的少ない、極端なケースやロングテールシナリオを生成し、手動アノテーションの難易度と時間を削減し、場合によっては、人間によるデータよりも分布が複雑な学習サンプルを生成することができます。
大規模言語モデル(LLM)の登場に伴い、ゼロショットまたは少数ショットのプロンプトを用いて合成データを生成する手法として「自己指示」が提案されました。これを基に、「グラウンデッド自己指示」は、文書などの外部ソースを制約として組み込むことで、錯覚を減らし多様性を高めています。さらに、「CoT自己指示」は、生成プロセス中に連鎖的な推論を導入することで、より複雑で正確なタスクを構築します。最後に、いわゆる「自己挑戦型」手法では、挑戦者エージェントがタスクとその評価関数を提案する前にツールと対話することができます。しかし、これらの手法はいずれもデータの難易度や品質を直接制御することはできないため、フィルタリング、進化、洗練といった改善戦略が必要となります。
この文脈では、Metaの基礎人工知能研究チーム(MetaのFAIR)は、Autodataと呼ばれる汎用的な手法を提案した。上記の手法はすべて統合され、一般化されています。このフレームワークでは、「データサイエンティスト」として機能するインテリジェントエージェントが、人間のデータサイエンティストのワークフローを模倣して、高品質なデータを生成するために、データの構築と整理を担当します。このプロセスには、初期データ生成だけでなく、データ分析フェーズ(「人間によるレビュー」に相当)、パフォーマンスの評価、経験の要約、そしてこれらの評価に基づいてより良いデータソリューションを反復的に生成するプロセスも含まれます。
研究者らは、コンピュータ科学研究タスク、法的推論タスク、および数学的対象推論タスクに関する実験を実施し、従来の合成データ構築手法と比較して優れた結果を達成した。さらに、データサイエンティストエージェント自体のメタ最適化により、パフォーマンスはさらに大幅に向上した。
関連する研究成果は、「Autodata:高品質な合成データを作成するためのエージェント型データサイエンティスト」と題され、arXivにプレプリントとして公開されている。
研究のハイライト:
エージェントベースのデータ生成手法は、推論計算リソースをより高品質なモデルトレーニングデータに変換する道筋を提供する。
* データサイエンティストエージェント自体もメタ最適化することができ、人間の指示やエンジニアリングを必要とせずに、パフォーマンスを大幅に向上させることができます。
この研究は、将来のタスクやベンチマークの構築方法を変革し、AI開発の最前線を切り開く可能性を秘めている。

用紙のアドレス:
https://hyper.ai/papers/2606.25996
データセット:3つの主要なタスクシナリオを網羅
Autodataフレームワークは、実験において、コンピュータサイエンスの研究課題、法的推論タスク、数学的対象に基づく科学的推論タスクという3つの主要なタスクシナリオを網羅した。これらのタスクは、異なる認知構造の下でのフレームワークの汎化能力をテストするために、異なるデータソースシステムに基づいて構築されています。
コンピュータサイエンスのタスクでは、研究者たちは、S2ORCコーパス(2022年以降)から1万件以上のコンピュータサイエンス論文を処理した。Agentic Self-Instructを使用して、2,800個の承認済みサンプルが生成されました。ループ終了後、これらのサンプルはKimi-K2.6ベースの品質検証器を用いてさらにフィルタリングされ、論文固有の情報が漏洩している、文脈が不十分である、採点基準の形式が間違っているなどの問題のあるサンプルが除外されます。最終的に、1,300個の高品質なサンプルが強化学習(RL)トレーニング用のエージェント自己指導データセットとして保持されます。
法的推論課題において、データは、裁判所の判決や法的意見を含む Pile of Law などの公開されている法的文書から取得され、PRBench-Legal およびその難易度の高いサブセット PRBench-Legal-Hard で評価されます。科学論文とは異なり、法律文書は、より強固な構造的論理制約と判例への依存性を持つため、生成タスクでは事実を抽出し、規則を適用する能力がより重視される。
科学的推論課題において本研究は、Principiaデータセットに基づいています。Principiaデータセットは、CoT Self-Instructメソッドを用いて構築され、MSC2020およびPHYS分類体系における幅広いコース内容を網羅しています。Principiaベンチマークは、既存の数学および物理学ベンチマークのサブセットで構成され、人間によって注釈が付けられています。これらの問題は、解答に数学的対象が含まれるようにスクリーニングされています。
Autodataの目標は、すべてのタスクにおいて、単に質問と回答のペアを生成することではなく、弱いモデルと強いモデルを効果的に区別できるトレーニングデータを生成することです。
Autodata:自律型インテリジェントエージェントを用いて、データサイエンティストの役割をシミュレートする。
Autodataの最上位設計を以下の図に示す。このフレームワークは、自律型インテリジェントエージェントを用いてデータサイエンティストの役割をシミュレートする。データを反復的に生成し、定性的な検証と定量的な性能評価を実施し、得られた知見を包括的に分析し、それに応じてデータ生成方法を更新することで、このテンプレートに基づいてさまざまな実装形態を構築することができる。
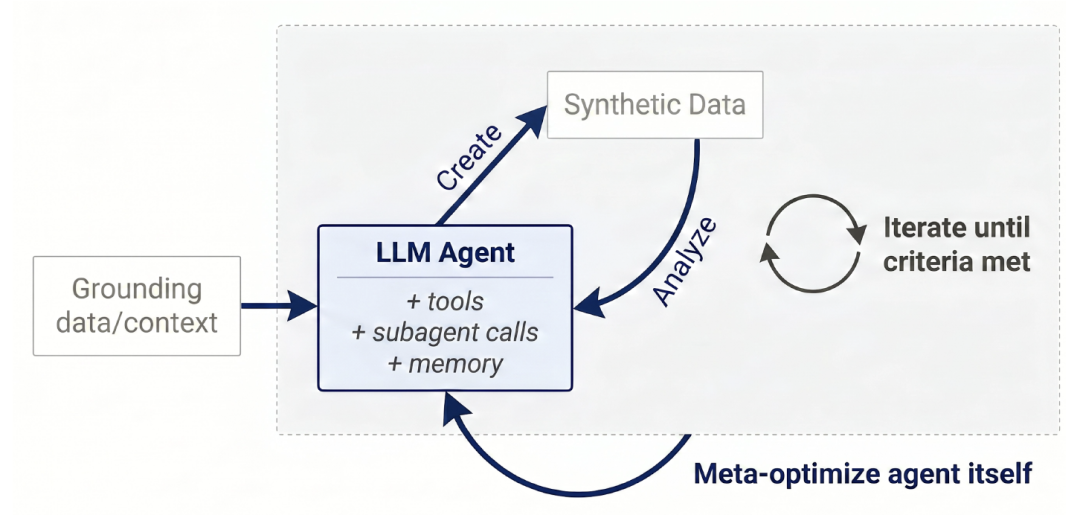
Autodataワークフロー
全体のループは以下のコンポーネントで構成されています。
① データ作成
Autodataエージェントは、データ生成を支援するために、提供されたデータ(例えば、数学、法律、プログラミングなどの分野における特定の文書、またはその他のタスク固有のデータソース)を「基盤」として利用します。このエージェントは、ツールや既存のスキルと経験を活用し、推論フェーズの計算リソースを利用して、モデルのトレーニングや評価のためのトレーニングデータとベンチマークデータを生成できます。このデータ生成ステップは、その後の分析と学習の後に繰り返すことができ、データ品質を継続的に向上・強化します。
② データ分析
エージェントが生成したデータを取得した後、システムはこのデータを分析し、何が「正しかった」か「間違っていた」か、そしてどのように改善できるかをまとめます。この分析はさまざまなレベルで行われます。例えば、単一のサンプルレベル(例が正しいか、高品質か、あるいは十分な難易度があるかを判断する)や、データセット全体レベル(例:サンプルが多様であるか、トレーニングデータとしてモデルのパフォーマンスを向上させることができるか)などです。これらの分析結果はデータ生成段階にフィードバックされ、停止条件が満たされるまで、次の反復でより良いデータが生成されます。
③ データサイエンティストの全体的なループ
エージェントは、データ品質に満足するまで「データ生成とデータ分析」を繰り返し実行し、最終的に高品質のトレーニングデータセットまたはベンチマークを生成します。外側のループには、システムのハッキングを防ぐための特定の安全機構や制約機構を追加できます。このエージェントベースのループにより、モデルはプロセス全体を通して学習成果を継続的に蓄積し、活用することができます。
④ データサイエンティストのメタ最適化
エージェント自体も、データサイエンティストとしてより適切に機能するように最適化することができます。一つのアプローチは、自動研究やメタハーネスと同様の手法を用いてエージェントフレームワークを最適化し、同じ内部ループの目的(つまり、「より良いデータを生成する」こと)を活用して外部ループの最適化を誘導することで、エージェントシステム全体を改善することです。
本論文では、その実装において、以下の図に示すように、Autodataのインスタンス化方法としてAgentic Self-Instructを提案している。
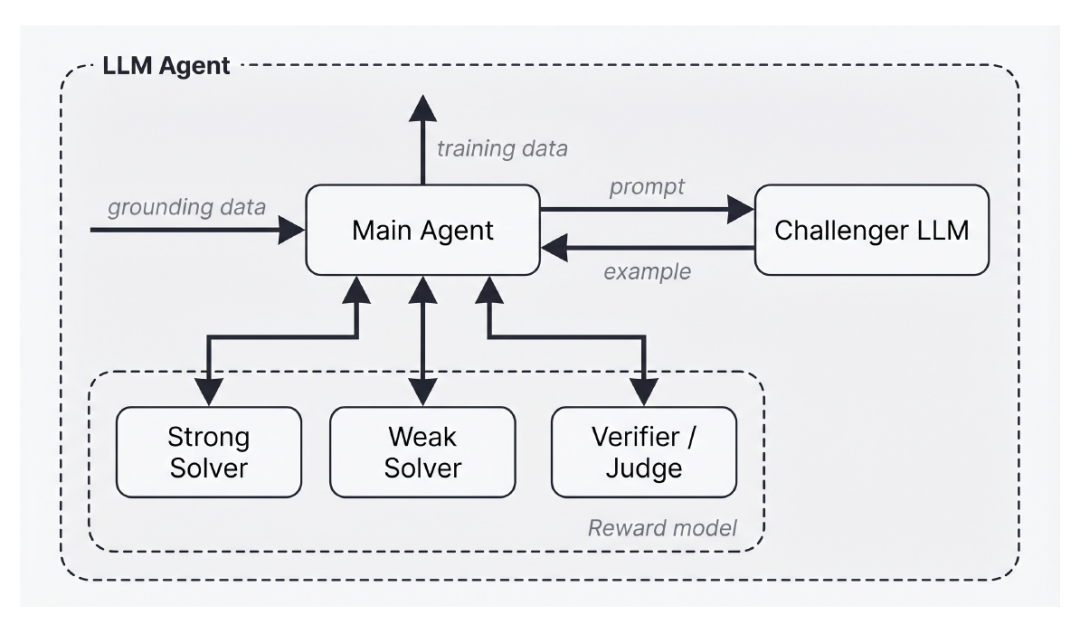
弱-強コントラスト エージェント自己指導法
この方式におけるメインのオーケストレーターエージェントは、大規模言語モデル(LLM)に基づいて4つのサブエージェントにアクセスできます。
* チャレンジャー: メインエージェントが提供する詳細なプロンプトに基づいてトレーニングサンプルを生成します。
* 弱いソルバー:生成されたトレーニングデータを解決するのに苦労するモデル。
* 強力なソルバー:生成されたトレーニングデータを通常、正常に解決できるモデル。
* 検証者/審査員: サンプルとモデルソリューションを提供した後、検証者/審査員はソリューションの品質をチェックし、学習結果をメインエージェントにフィードバックします。
このシステムの目的は、優秀なソルバーがタスクを成功裏に完了できる一方で、能力の低いソルバーは苦戦するようなトレーニングデータを生成することです。マスターLLMはレビュー担当者からのフィードバックを分析し、それに応じて挑戦者へのヒントを更新します。このサイクルを継続的に繰り返すことで、能力の低いソルバーをトレーニングするための高難易度サンプルが生成されます。
成果紹介:従来の合成データ構築手法と比較して優れた結果を達成
研究者らの実験は3つのタスク領域を対象としており、これによりAutodataフレームワークの有効性が複数の側面で検証された。
コンピュータサイエンスのタスク
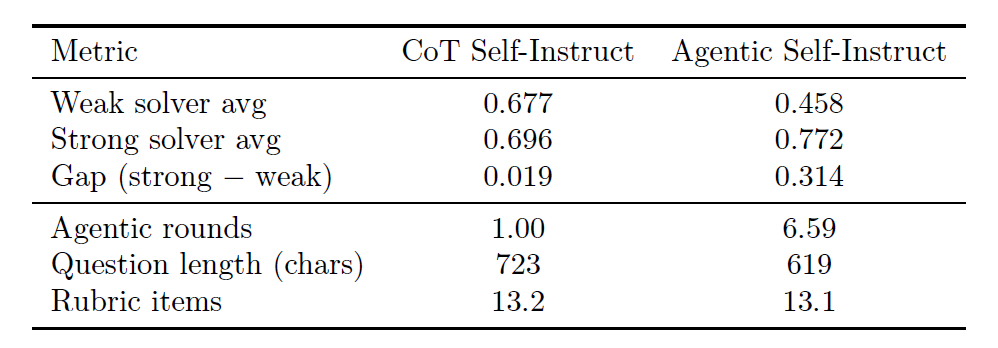
コンピュータサイエンスのタスクにおいて、エージェント自己指導によって生成されたデータは、弱いモデルと強いモデル間の混同率を大幅に低減し、トレーニングシグナルをより明確にする。
ベースラインのCoT自己指導法を用いて生成された問題では、弱いソルバーの平均スコアは0.677でした。しかし、同じソース資料(論文)を用いてエージェント自己指導法で生成された問題では、弱いソルバーのスコアは22パーセントポイント低下し(0.677 → 0.458)、強いソルバーのスコアは8パーセントポイント上昇しました(0.696 → 0.772)。詳細は以下の表をご覧ください。これは、最終的に受け入れられた質問が、強力なモデルの深い推論能力に対してより大きなインセンティブ効果を持つことを示している。
RL トレーニングでは、より単純な CoT Self-Instruct テスト セット (下の表の左側) では、CoT データを使用したトレーニングにより、基本 4B モデルの mean@3 が 0.630 から 0.727 に改善され、Agentic データを使用したトレーニングではさらに 0.774 に改善されます。より難しい Agentic テスト セット (下の表の右側) では、対応する結果は次のとおりです。0.366 (基本モデル) → 0.500 (CoT トレーニング) → 0.632 (Agentic トレーニング)。このテスト セットでは、2 つの方法の差がかなり大きく (CoT テスト セットの 2 倍以上)、best@3 メトリックでも同じ順位が示されています。
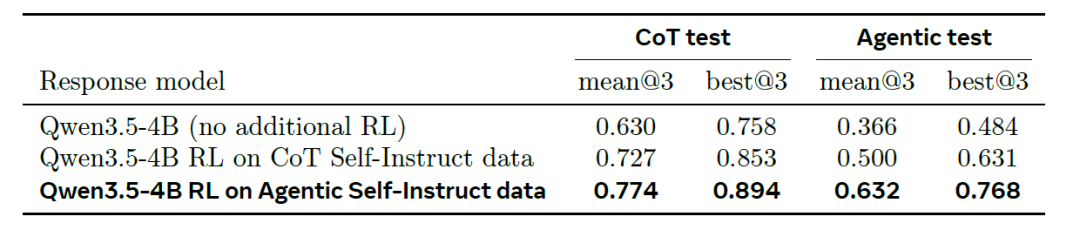
Agenticで学習させたモデルは、双方向の転移性を示しました(CoTテストセットで+0.05、より難易度の高いAgenticテストセットで+0.13)。この顕著な利点は、Agenticパイプラインによって生成される識別力の高い学習データが、より強力な推論能力につながることを示唆しています。
法的推論課題
法的推論タスクにおいて、対照的ではあるものの同様に重要な現象が研究によって明らかになった。それは、従来のCoTによって生成されるデータが難しすぎるため、弱いモデルでは有効な勾配信号がほとんど得られず(結果として、多数のゼロスコア出力が発生する)、問題が生じるというものである。Autodataは、よりきめ細かな評価フィードバック機構を導入することで、データの難易度を「学習可能な範囲」に戻し、GRPOトレーニングの安定性と有効性を大幅に向上させる。
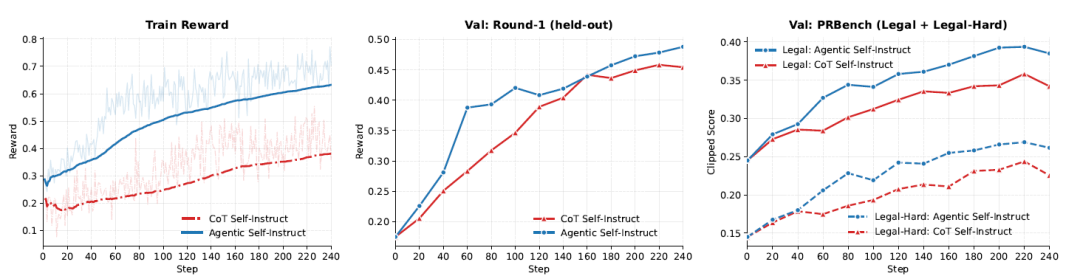
研究者らはGRPOを用いて、2つのデータソース(2,800組の法律問題とルーブリックのペア(Agentic Self-InstructとCoT Self-Instruct))でQwen3.5-4Bをトレーニングした。トレーニング中、20ステップごとに、データセットは2つの評価セット(100個のプロンプトを含むCoTホールドアウトセットとPRBench Legal/Legal-Hardの分割)でテストされた。すべての報酬とスコアはKimi-K2.6を用いて評価された。下の図のトレーニング曲線は、各評価チェックポイントで…エージェント型手法は、トレーニング報酬、CoT検証セット、およびPRBench-Legalにおいて一貫して優れた結果を示しています。
科学的推論課題
科学的推論タスクにおいても、Agentic Self-Instructは一貫して優位性を示しています。結合検証セット(下表参照)では、Agentic Self-Instructデータを用いたトレーニングが全体的な改善度(+3.20% avg@8)が最も大きく、CoT Self-Instructの直接使用(+2.42%)および結合データ(+2.70%)を上回りました。
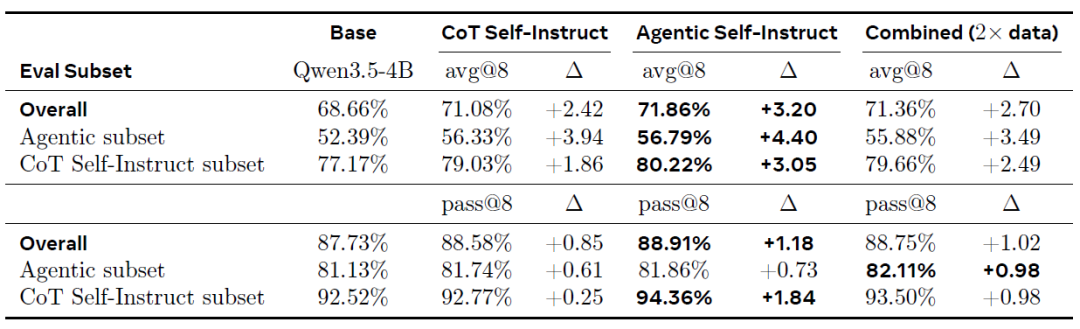
強化学習訓練結果の科学的推論課題における評価
重要な発見は、最適化されていないCoT検証サブセットにおいても、Agentic Self-Instructは依然としてより高いパフォーマンス向上(+3.05% vs. CoTの+1.86%)を実現している点である。これは、...より難しいタスクでの訓練は、より単純なタスクにも応用できる。エージェントプロセスによって生成された高難易度のサンプルを繰り返し処理することで、特定の難易度分布に限定されることなく、汎用的な推論能力を習得できる。
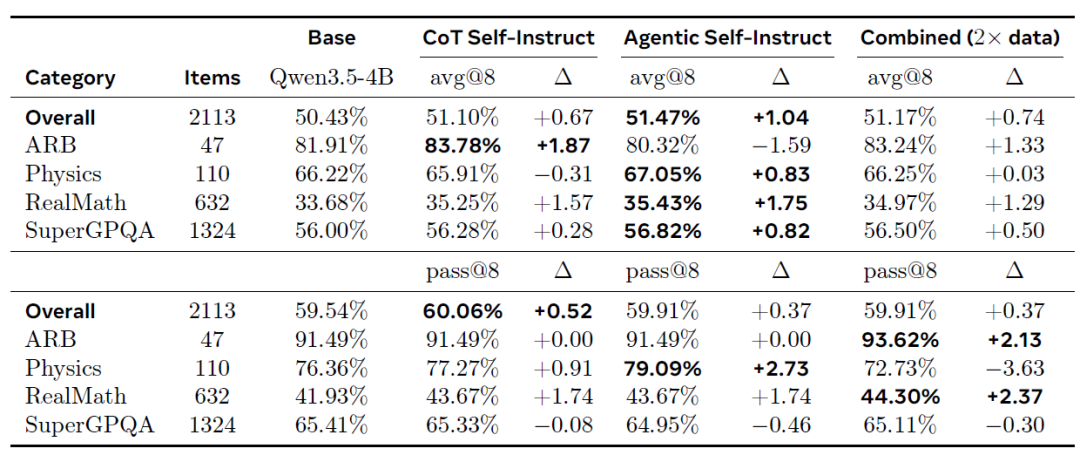
分布外のPrincipiaベンチマーク(下表参照)においても、Agentic Self-Instructは最高の平均改善度(+1.04% avg@8)を達成し、特にRealMath(+1.75%)とSuperGPQA(+0.82%)など、複数のカテゴリで一貫してトップの成績を収めました。この転移効果は、Agentic Self-Instructが生成するより難易度の高い問題が、堅牢な推論能力を向上させることができることをさらに証明しています。
結論
要約すると、Autodataは、インテリジェントエージェントによって駆動されるデータサイエンスループとしてデータ生成プロセスをモデル化する、斬新なデータ生成パラダイムを提案しています。このフレームワークでは、データ生成、評価、障害分析、およびポリシー最適化が単一の閉ループシステム内で統合されます。さらに、メタ最適化実験により、データサイエンスエージェント自体も最適化できることが実証されており、人間の介入なしにデータ品質を向上させることが可能です。
総じて、本研究の核心的な貢献は、推論フェーズで使用される計算リソースを、より高品質な訓練データを生成する能力へと変換するメカニズムを提供することにある。今後、この方向性には、より大規模なタスク適応、より複雑な複数ターンエージェント間の協調、データセットレベルでのグローバル最適化など、大きな拡張の余地がある。さらに、エージェントとの協調最適化メカニズムを構築するために、人間のフィードバックをループに再導入することも、今後の開発における重要な方向性と考えられる。








