Command Palette
Search for a command to run...
4段階の画像出力/4K品質/6倍の高速化、PiDはピクセル拡散を使用してデコードと超解像出力を統合します。SA-3DAO:アーティストが手作業で作成した3Dメッシュとペアになった1000組の実画像を含むデータセット。

PiDは、NVIDIAが発表した新しい潜在空間デコード方式です。従来のVAEデコード処理を条件付きピクセル拡散生成として再定義し、デコードと超解像アップサンプリングを単一の生成モジュールに統合します。従来の潜在拡散モデルでは、VAEによって画像に潜在変数が復元されるため、出力解像度が制限されます。さらに、再構成指向のデコーダでは高周波の詳細を復元することが難しく、潜在変数のアーティファクトを修正することもできません。PiDは、ノイズを考慮した軽量な潜在変数アダプタ(シグマ対応アダプタ)を導入し、ノイズを含む潜在変数をピクセル空間拡散バックボーンネットワークに注入します。これにより、モデルは完全にノイズ除去された潜在変数と、部分的にノイズ除去された潜在変数の両方を処理できるだけでなく、拡散処理を早期に終了させることも可能になります。DMD2蒸留技術の助けを借りれば、推論はわずか4つのノイズ除去ステップで完了できます。
HyperAIのウェブサイトに「PiD:4K超高解像度画像生成・編集」が新たに掲載されましたので、ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/a34Cx
より詳しい情報については、弊社の公式ウェブサイトをご覧ください。
hyper.aiの公式サイトにおける6月19日から6月26日までの更新内容の概要は以下のとおりです。
* 高品質な公開データセット:7件
* 厳選された高品質チュートリアル:14件
* コミュニティ記事の解釈:4件
* 人気のある百科事典のエントリ: 5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. SAM 3Dアーティストオブジェクト 3Dオブジェクト再構築データセット
SAM 3D Artist Objectsは、Metaが2026年6月に公開した3Dメッシュペアリングデータセットです。実世界のシーンにおけるオブジェクトの形状やレイアウトに対する3D再構成アルゴリズムの性能評価を目的としており、画像から3Dオブジェクトを生成するアルゴリズムの性能テスト、モデル最適化、およびコンピュータビジョン関連の研究に広く利用されています。このデータセットには、プロのアーティストが手作業で作成した3Dメッシュと実写画像のペアが1,000組含まれています。
オンラインでの使用:https://go.hyper.ai/rn2aF
2. RHELM長期記憶評価データセット
RHELMは、2026年にマイクロソフトが公開した長期記憶評価データセットです。複雑で動的なシナリオにおける大規模モデルの長期記憶、マルチホップ推論、および時間情報合成能力の向上を目的としています。このデータセットは、大規模言語モデルの長期時間記憶評価、AIアシスタントの長期対話能力の検証、大規模モデルのマルチホップ推論、時間情報融合、幻覚検出など、幅広い研究シナリオで活用されています。
オンラインでの使用:https://go.hyper.ai/OGkUl
3. MAKIEVAL多言語文化知識評価データセット
MAKIEVALは、ミュンヘン大学のMaiNLP研究室がミュンヘン機械学習センターと共同で2026年に公開した、多言語文化知識評価データセットです。大規模言語モデルにおける多言語文化知識の評価のための大規模なベンチマークを提供することを目的としており、多言語知識表現や文化知識モデリングの研究で広く利用されています。このデータセットには、13言語、19の国・地域、6つの文化領域で7つの大規模言語モデルによって生成されたテキストと、それらから自動的に抽出された文化エンティティ、およびWikidataとのアライメント結果が含まれています。
オンラインでの使用:https://go.hyper.ai/v7zip
4. Verbatim Spansクエリ条件証拠抽出データセット
Verbatim Spansは、TU WienがKRLabsと共同で2026年4月にリリースした、マルチドメインのクエリ条件付き証拠抽出データセットです。このデータセットは、クエリ条件付き証拠抽出モデルのトレーニングのための汎用ベンチマークを構築することを目的としており、検索拡張(RAG)や抽出型質問応答タスクに幅広く適用可能です。データセットには、174,383行のトレーニングデータと20,174行の検証データが含まれており、自然言語処理論文、マルチドメイン質問応答、コードおよびツール出力という3つの主要なタイプのコーパスを網羅しています。
オンラインでの使用:https://go.hyper.ai/hbpjR
5. Nemotron-SFT-Math-v4 数学的推論SFTデータセット
Nemotron-SFT-Math-v4は、NVIDIAが2026年5月にリリースした数学的推論データセットです。従来の数学データセットにおける品質のばらつき、非標準的な推論経路、低い精度、限られたシナリオの多様性といった問題に対処することを目的としており、モデルの構造化推論、マルチ経路推論、および解答検証機能を効果的に向上させます。このデータセットには、545,431個のトレーニングサンプルが含まれており、その内訳はCOT(Content-Oriented Reasoning)推論サンプル285,516個とTIR(Tracking Inference)ツール推論サンプル259,915個です。代数、幾何学、数論、組み合わせ論などの分野における競技レベルおよび研究レベルの数学シナリオを網羅しています。
オンラインでの使用:https://go.hyper.ai/6ooPw
6. AIが雇用と解雇リスクに与える影響:AIを活用した雇用影響データセット
AIが雇用と解雇リスクに与える影響に関する合成構造化機械学習データセットは、人工知能が雇用に与える影響を分析することを目的としています。AIの導入、業務の自動化、職務特性、および労働者のスキルが現代経済における雇用結果に与える影響を探究します。分類モデリング、労働力分析、自動化の影響調査、人事意思決定支援など、幅広い用途で活用されています。
オンラインでの使用:https://go.hyper.ai/38bZl
7. 地球規模の気候・エネルギー転換 2000年~2026年 地球規模の気候・エネルギーデータセット
「地球規模の気候・エネルギー転換2000~2026」データセットは、気候変動、エネルギー転換、炭素排出削減に関する研究のための地球規模の気候・エネルギー転換データセットであり、地球規模の気候変動とエネルギー転換のプロセスを体系的に描写することを目的としています。このデータセットは、2000年から2026年までの地球規模の気候変動とエネルギー転換のプロセスを記録し、地球規模および地域規模の気温異常を網羅しています。
オンラインでの使用:https://go.hyper.ai/ogrSa
選択された公開チュートリアル
1. PiD:4K超解像画像の生成と編集
PiDは、NVIDIAチームが開発したプラグアンドプレイ方式の超解像デコーダです。従来の拡散モデルでは、VAEデコーダを使用して潜在表現を画像に復元しますが、出力解像度は約1024ピクセルに制限されます。PiDは、VAEデコードの最終ステップをピクセル空間拡散処理に置き換えることで、わずか4ステップのノイズ除去だけで、後処理技術を一切必要とせずに鮮明な4K画像を直接生成します。これにより、従来のモデルアーキテクチャを変更することなく、従来の手法における解像度のボトルネックを大幅に解消します。
オンラインで実行:https://go.hyper.ai/a34Cx
2. LTX-2.3-turbo ビデオジェネレーター
LTX-2.3-turboは、オープンソースのビデオ生成モデルであり、Lightricks社が2026年3月にリリースしました。オープンソースのビデオ生成機能の限界を押し上げることを目指して設計されたこのモデルは、高度な拡散トランスフォーマーアーキテクチャを採用し、マルチモーダル理解機能と組み合わせることで、高品質かつマルチ解像度のビデオコンテンツ生成を実現しています。
オンラインで実行:https://go.hyper.ai/oepch
3. DiffBrush: 手書きのテキスト行を生成する
南開大学と崑崙科技大学は、2025年8月に手書きテキスト行生成モデル「DiffBrush」を共同で発表し、同年10月にICCV 2025に正式に採択されました。このモデルは、Stable Diffusion VAE+UNetアーキテクチャに基づいており、任意の英語テキスト入力とIAMデータセットからの496種類の手書きスタイルをサポートし、1024×64のグレースケール画像を出力します。テキストの内容と手書きスタイルは独立して制御可能です。推論の展開は軽量で、OCRトレーニングセットの生成、手書きデータの拡張、文書シミュレーションに直接使用できます。
オンラインで実行:https://go.hyper.ai/qVvl5
4. 再利用:一般的な音声強調モデル
RE-USEは、NVIDIAが2026年3月にリリースした汎用音声強調モデルです。Mambaアーキテクチャに基づいており、様々なサンプリングレートや劣化タイプのノイズの多い音声信号に対応でき、言語に依存しません。
オンラインで実行:https://go.hyper.ai/MJ0p5
5. TADA-1b:統合音声言語モデル
TADA-1bは、HumeAIチームが2026年2月にリリースした統合型音声・言語モデルで、音声合成、音声クローニング、多言語吹き替えなどの音声生成タスク向けに特別に設計されています。Llama 3.2-1Bをベースとしたこのモデルは、軽量で高速かつ安定した音声生成機能を備えており、英語のテキスト音声合成(TTS)、ゼロショット音声クローニング、長編ナレーション、音声継続などに適しています。
オンラインで実行:https://go.hyper.ai/nCSpT
6. Gsplat 3D ガウススプラッシュのトレーニングと可視化
Gsplatは、バークレー大学、NVIDIA、上海科技大学などが共同開発したオープンソースの3DGS CUDAアクセラレーション対応ラスタライズライブラリです。オリジナルの実装をベースに徹底的に最適化されており、トレーニングメモリ使用量を4分の1に削減し、トレーニング時間を151 TP3T短縮しています。主な技術的特長としては、高効率CUDA差分ラスタライズエンジン、適応型ガウス密度制御戦略、COLMAPなどの主流データフォーマットに対応した柔軟なデータバックエンド、ViserベースのリアルタイムWeb可視化インターフェースなどが挙げられます。応用分野は、デジタルツイン、自動運転環境認識、文化遺産のデジタル化、eコマースのビジュアル合成など多岐にわたります。
オンラインで実行:https://go.hyper.ai/Zihdr

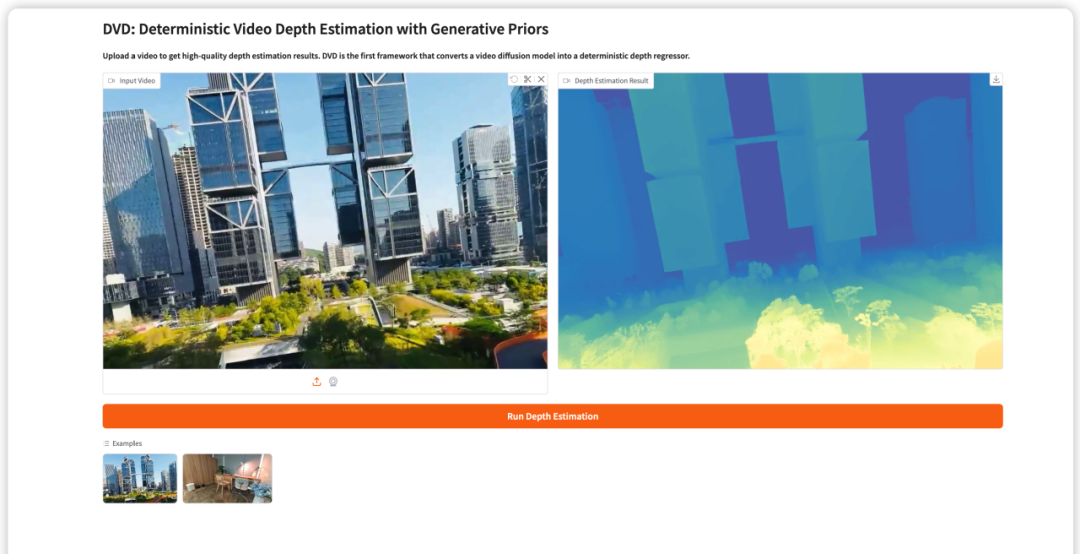
7. DVD:生成事前分布に基づく決定論的ビデオ深度推定
DVD(Deterministic Video Depth Estimation)は、2026年3月に香港科技大学(広州)チームが提案した、初の決定論的なビデオ深度推定フレームワークです。事前学習済みのビデオ拡散モデル(Wan2.1)を単一の順伝播深度回帰器に変換することで、ランダム性によって引き起こされる幾何学的錯覚の問題を完全に解消しつつ、生成モデルの強力な意味的事前情報を維持しています。
オンラインで実行:https://go.hyper.ai/AisLp
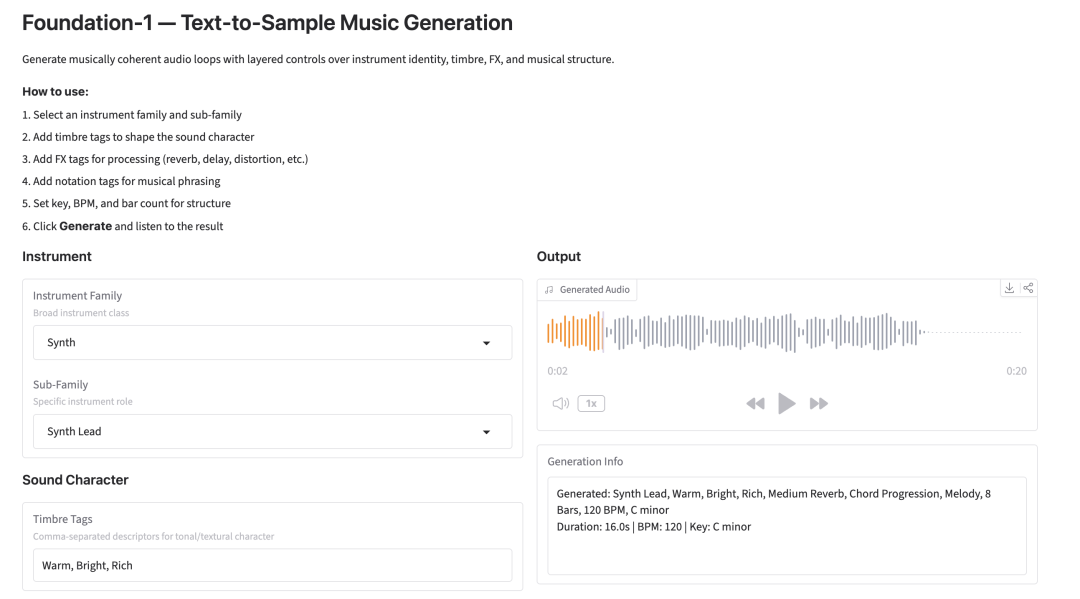
8. 基礎編-1:構造化テキストから音楽サンプル生成
RoyalCitiesチームが2026年3月にリリースしたFoundation-1は、プロの音楽制作ワークフロー向けに設計されたテキスト・トゥ・サンプル方式のオーディオ生成モデルです。公式バージョンでは、レイヤー化された制御可能な生成をサポートしており、ユーザーは楽器ファミリー、サブジャンル、音色、エフェクト、理論的なコード、テンポ/調号、小節の長さなどをカスタマイズして、リズム的に同期し、音程がロックされた音楽ループを生成できます。さらに、このソフトウェアは、完全なインタラクティブ生成機能を提供する統合Webデモも提供しています。
オンラインで実行:https://go.hyper.ai/NxUAC
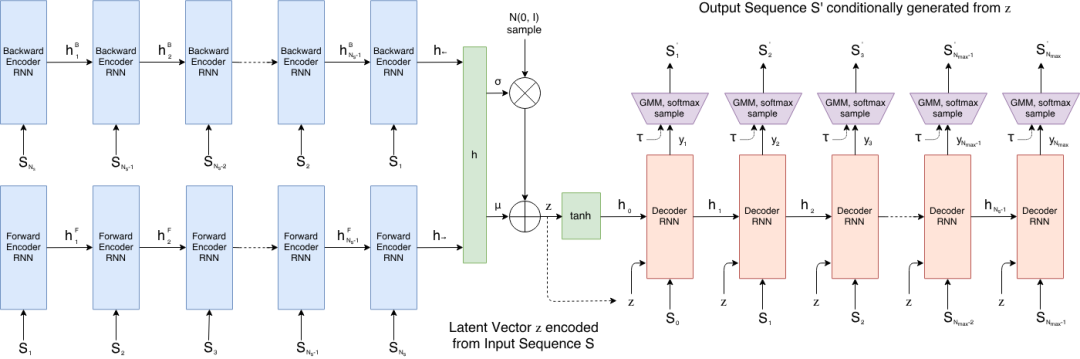
9. Sketch-RNN: ベクトルスケッチ生成と潜在空間補間
Sketch-RNNは、2017年にGoogle Brainチームが発表したベクトルスケッチシーケンス生成モデルです。この手法は、ストロークオフセットやペン状態情報を含む手描きスケッチデータに特化して設計されています。スケッチの連続的な潜在表現を学習し、新しいベクトルスケッチシーケンスを生成できます。Sketch-RNNはエンコーダー・デコーダーアーキテクチャを採用しています。入力スケッチを潜在空間にマッピングし、リカレントニューラルネットワークデコーダーを使用してストロークを段階的に生成します。
オンラインで実行:https://go.hyper.ai/HmcT9
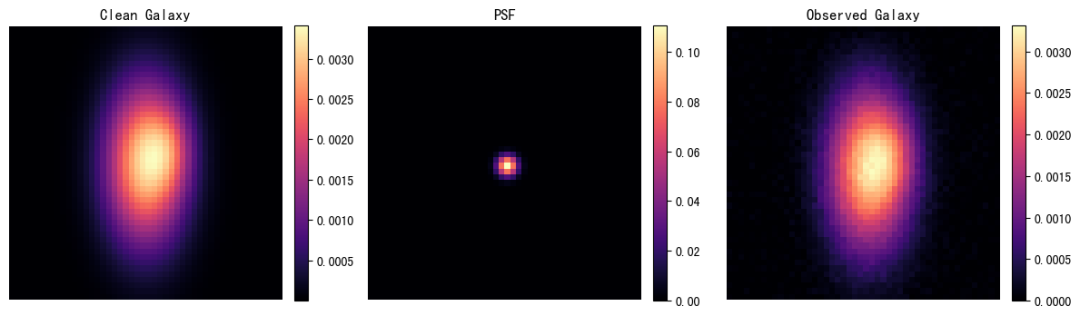
10. Galaxy-Deconv: 弱い重力レンズ効果を受けた銀河画像のデコンボリューションフレームワーク
Galaxy-Deconvは、清華大学のTianyao Li氏とノースウェスタン大学のEmma Alexander氏によって開発されました。このプロジェクトは、重力レンズ効果が弱い銀河の画像復元に焦点を当てています。展開されたプラグアンドプレイADMMアルゴリズムを使用して、点像分布関数(PSF)のぼけやノイズの影響を受けた銀河の画像をデコンボリューションします。このチュートリアルでは、一般的な銀河デコンボリューションのワークフローをノートブックにまとめ、画像シミュレーション、COSMOSデータの読み込み、デコンボリューション推論、HDF5データセットのチェック、および基本的なデコンボリューション演習を網羅しています。
オンラインで実行:https://go.hyper.ai/qGvI1
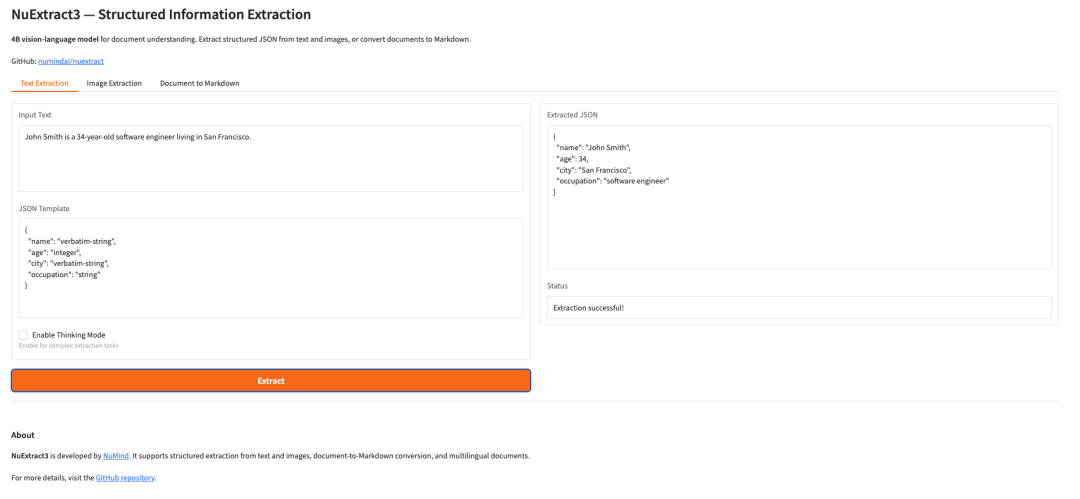
11. NuExtract3:マルチモーダル文書理解および構造化情報抽出モデル
NuExtract3は、NuMindが2026年6月にリリースした40億パラメータのマルチモーダル視覚言語モデルで、文書理解のために特別に設計されています。このモデルは、構造化情報抽出機能と文書画像からMarkdownへの変換機能を統合しており、テキスト、画像、およびテキストと画像の混合入力に対応しています。また、ユーザーが提供するJSONテンプレートに基づいて構造化された結果を直接出力でき、表、数式、レイアウト情報を完全に保持します。
オンラインで実行:https://go.hyper.ai/xirTj
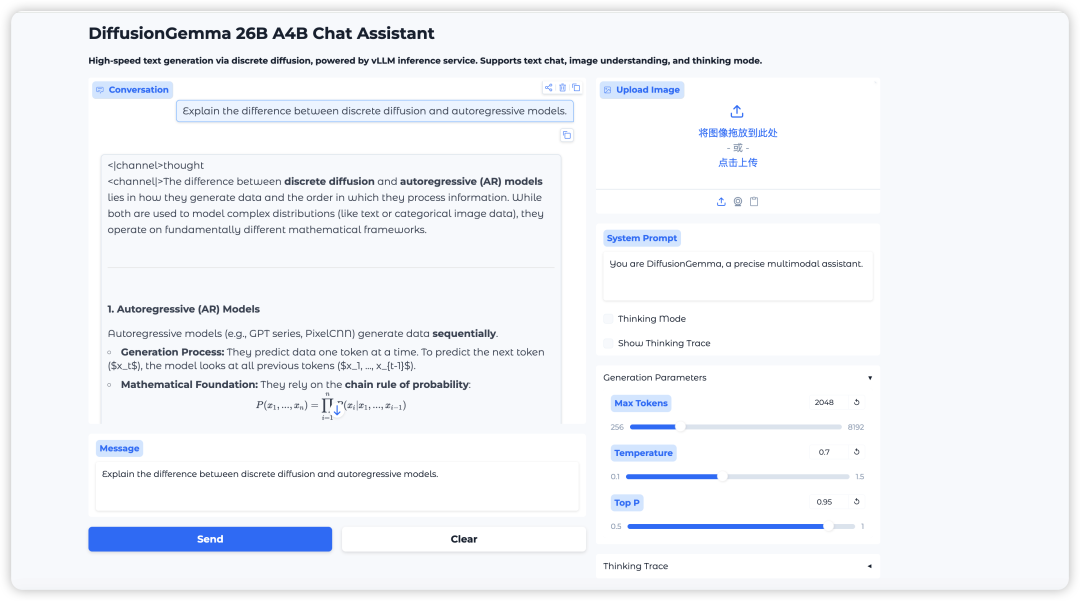
12. DiffusionGemma:離散拡散に基づく高速テキスト生成モデル
DiffusionGemmaは、Google DeepMindが離散拡散技術を用いて構築したテキスト生成モデルです。260億個のパラメータを持つエキスパート混合モデル(MoE)アーキテクチャを採用しており、合計252億個のパラメータのうち、有効なパラメータはわずか38億個です。並列ブロックレベル拡散サンプリングにより、超高速なテキスト生成速度を実現し、単一のH100 GPUで毎秒1100トークン以上を生成できます。
オンラインで実行:https://go.hyper.ai/HV3eM
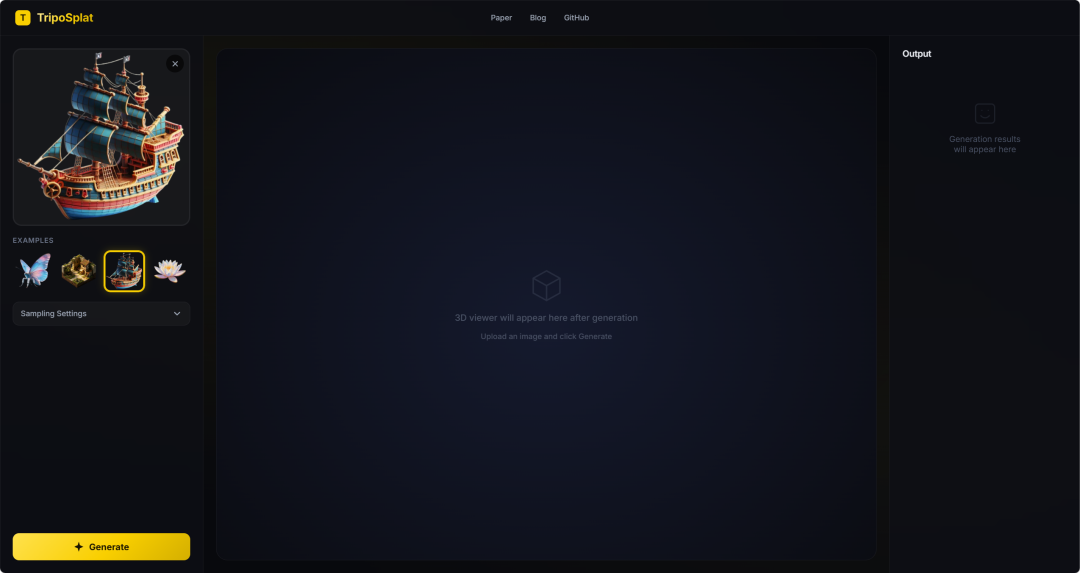
13. TripoSplat: 1枚の画像から高品質な3Dガウス分布アセットを生成します。
TripoSplatは、VAST-AI ResearchとTripoAIが2026年5月に共同で発表した、単一画像から3Dガウス分布を生成する手法です。このモデルは、単一の2D画像を高品質な3Dガウス分布モデルに変換でき、ガウス分布の数を制御できます。密度サンプリングガウス(DeG)技術を採用し、対象物の幾何学的複雑さに応じてガウス中心を適応的に分布させ、VecSeqを用いて無秩序な潜在変数を決定論的に並べ替えることで、生成学習の安定性を向上させています。
オンラインで実行:https://go.hyper.ai/wOxUG
14. North Mini Code 1.0:コード生成とソフトウェアエンジニアリングタスクのためのエージェントモデル
North Mini Code 1.0は、CohereとCohere Labsが2026年6月にリリースした、コード生成、エンドポイントタスク、エージェントソフトウェアエンジニアリングのシナリオ向けに最適化された、オープンウェイトのコードモデルです。このモデルは、長時間のコーディングセッション、コード推論、ツール呼び出し、インターリーブ思考をサポートし、機能実装、スクリプト作成、デバッグ、エンドポイントタスク計画、複数ラウンドのソフトウェアエンジニアリングワークフローにおいて優れた性能を発揮します。
オンラインで実行:https://go.hyper.ai/ycCuG

コミュニティ記事の解釈
1. MITとIBMは、これまでで最大の合成チャートデータセットであるChartNetを公開した。ChartNetは、150万個の多様なチャートサンプルを生成している。
MIT、MIT-IBMコンピューティング研究所、およびIBMリサーチの専門家グループは、グラフ理解と推論能力の向上を目的として設計された、数百万件のレコードからなる高品質なマルチモーダルデータセットであるChartNetを提案した。
レポート全体を表示します。https://go.hyper.ai/Kk87Q
2. Google DeepMindの最新論文は、AIの究極の目標を明らかにしている。AGIからASIへ、4つの道と6つのハードルが存在する。
Google DeepMindは、複数のトップ大学と共同で、汎用人工知能(AGI)から超知能人工知能(ASI)への進化を取り巻く深遠な問題を考察した新たな論文を発表しました。この研究は、知能を連続体として捉え、平均的な人間のレベルを超えた後も進化を続けるAIが直面するであろう潜在的な道筋とボトルネックを冷静に分析しています。この論文は、AI開発の長期的な軌跡を理解するための、構造化された客観的な参考資料を提供します。
レポート全体を表示します。https://go.hyper.ai/AOObx
3. Googleの対話型医療システムAMIEは、Gemini 1.5の長い文脈認識能力を活用することで、複数回の患者診察を含む100のシナリオにおいて、一般開業医と同等の推論レベルを達成した。
Google DeepMindとGoogle Researchによる最近の研究では、対話型ヘルスケアシステムAMIEをベースとした、LLM(論理言語管理)に基づく新たなインテリジェントエージェントシステムが開発されました。このシステムは、臨床管理を可能にし、複数のフォローアップシナリオにおける医師と患者の対話を最適化します。AMIEは、Geminiモデルの長文コンテキスト機能を活用し、コンテキスト検索と構造化推論を組み合わせることで、最新の臨床診療ガイドラインや処方薬カタログに沿った出力を実現します。
レポート全体を表示します。https://go.hyper.ai/65aHo
4. 材料AIは「説明可能な時代」へと向かっている:日本のチームが高次元分光法のブラックボックスを解き明かし、新素材発見のための重要な特徴を特定した。
日本の東京理科大学の研究チームは、材料科学における高次元スペクトルデータを処理できる深層学習モデル解釈手法を提案した。研究チームは、2681種類の酸化物、カルコゲニド、および関連化合物の光吸収スペクトルを含む第一原理計算データセットを構築した。標準的な密度汎関数計算と比較し、スペクトルの開始エネルギーと形状を補正した後、計算結果は報告されている実験スペクトルとの一致が大幅に向上した。
レポート全体を表示します。https://go.hyper.ai/VJbaU
人気のある百科事典の項目を厳選
1. 大規模言語モデル(LLM)
2. 構造
3. 世界行動モデル(WAM)
4. 回転位置符号化(RoPE)
5. 大規模マルチタスク言語理解MMLU
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 2100以上の公開データセット向けに、国内高速ダウンロードノードを提供
* 700以上の定番かつ人気のオンラインチュートリアルを収録
* 300件以上のAI4Science論文事例を分析
* 700以上の関連用語の検索に対応
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








