Command Palette
Search for a command to run...
論文週間レポート|ProgramBenchはAIによるソフトウェアのゼロからの記述を可能にするが、9つの主要モデルが一斉に失敗。ExoActorは追加の実世界データなしで強力なシーン汎化能力を実証…今週の最先端AI論文の概要

言語モデルが長期的なソフトウェア開発でますます利用されるようになるにつれ、既存のベンチマークでは、システムアーキテクチャ設計、モジュール分割、および全体的なエンジニアリング実装におけるパフォーマンスを測定するには不十分になってきています。この課題に対処するため、SWE-BenchチームはProgramBenchベンチマークを提案しました。これは、モデルに実行可能ファイルと使用方法のドキュメントのみを提供し、コードを書き換えてプログラムの動作を再現することを要求するものです。
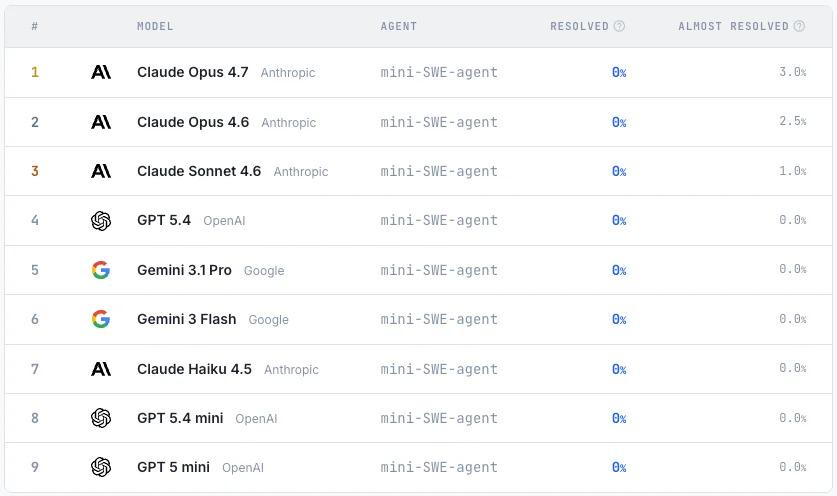
本研究では、データベース、コンパイラ、コマンドラインツールなど、さまざまな種類のソフトウェアを網羅する200のタスクを作成し、動作テストを通じてモデル生成プログラムと元のプログラムとの一貫性を評価した。実験結果によると、現在の主流モデルは依然として複雑なソフトウェア再構築タスクを完了するのに苦労しており、すべてのテストに合格するモデルは存在しない。最も性能の高いClaude Opus 4.7でさえ、高い合格率を達成できたのはごく一部のタスクに限られており、大規模な言語モデルは、ソフトウェアエンジニアリング全般の能力という点で、依然として大きな欠点を抱えていることを示している。
ペーパーリンク:https://go.hyper.ai/wExzR
最新のAI論文:https://go.hyper.ai/hzChC
より多くのユーザーが学術界における人工知能分野の最新動向を理解できるよう、HyperAIのウェブサイト(hyper.ai)に「最新論文」セクションが新設され、最先端のAI研究論文が定期的に更新されるようになりました。おすすめのAI関連論文8選をご紹介します。今週の最新のAI成果を簡単に見ていきましょう⬇️
今週のおすすめ紙
1. プログラムベンチ
論文のタイトル:
ProgramBench:言語モデルはプログラムをゼロから再構築できるか?
研究チームは、ソフトウェアエンジニアリングエージェントがゼロから完全なソフトウェアプロジェクトを構築する能力を評価するために、ProgramBenchを提案した。このベンチマークでは、エージェントはプログラムとドキュメントのみに基づいて、参照実行可能ファイルと一貫した動作をするコードベースを実装し、エージェント主導のファジングテストを通じてエンドツーエンドの評価を実行する必要がある。
ProgramBenchには、CLIツール、FFmpeg、SQLite、PHPインタープリタなど、さまざまなソフトウェアタイプを網羅した200のタスクが含まれています。9つの言語モデルを用いた実験では、現在のモデルの全体的なパフォーマンスが限られていることが示されました。最も優れたモデルでも、3%タスクで95%のテストに合格したのみであり、生成されたコードは一般的にモノリシックな単一ファイル構造を示しており、人間のソフトウェアエンジニアリングの実践とは大きく異なっています。
論文と詳細な解釈:https://go.hyper.ai/wExzR
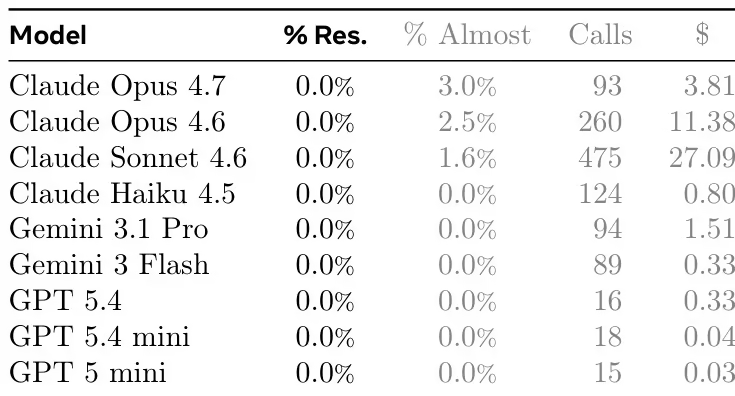
データセットの構成とソース:著者らは、オープンソースのGitHubリポジトリから200個のタスクインスタンスを収集した。ソースは、主にRust、Go、またはC/C++で記述されたスタンドアロン実行可能ファイルを生成するプロジェクトから選定された。このコレクションには、テキスト処理、システムユーティリティ、言語インタープリタなど、多様な機能カテゴリが含まれている。

2. ユニ外来診療所
論文のタイトル:
Uni-OPD:二重視点レシピによる政策蒸留の統合
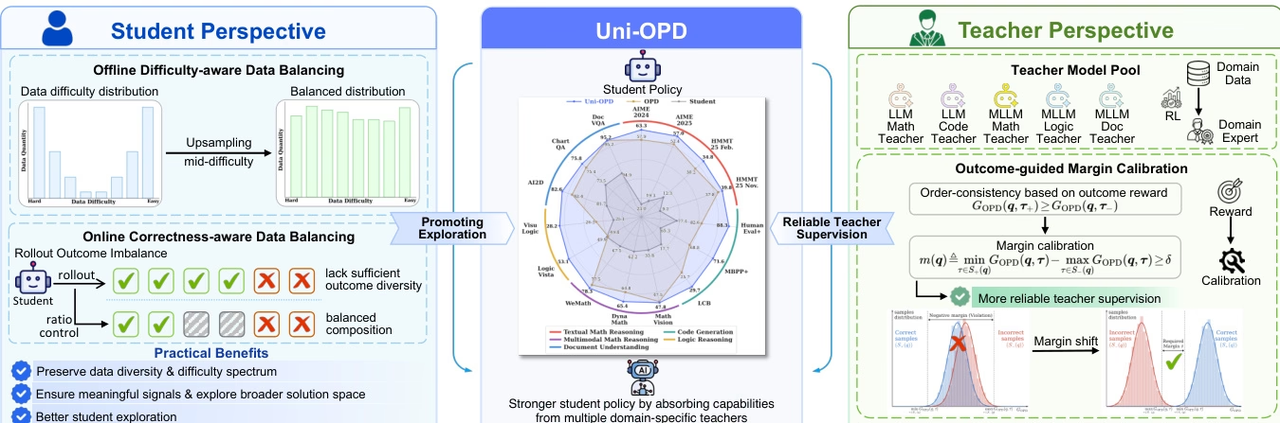
Uni-OPDは、LLMとMLLMのための統一されたオンライン蒸留フレームワークであり、複数の専門家の知識を学生モデルに伝達する能力を向上させるように設計されています。研究によると、既存のOPD手法は主に2つの問題によって制限されています。それは、情報量の多い状態の探索が不十分であることと、教師による監督シグナルが信頼できないことです。
この課題に対処するため、Uni-OPDは二重の視点からの最適化戦略を採用しています。学生側では、高情報状態の探索を強化するためにデータバランス戦略を導入し、教師側では、正解と不正解の軌跡間の連続的な一貫性を回復し、監視の信頼性を向上させるために、結果主導型の周辺較正メカニズムを提案しています。単一教師、複数教師、強弱変換、クロスモーダル蒸留など、さまざまな設定を含む5つのドメインと16のベンチマークを対象とした実験により、この手法の有効性が検証されました。
論文と詳細な解釈:https://go.hyper.ai/8k4du
3. 忠実な不確実性
論文のタイトル:
幻覚は信頼を損なう。メタ認知は前進への道である。
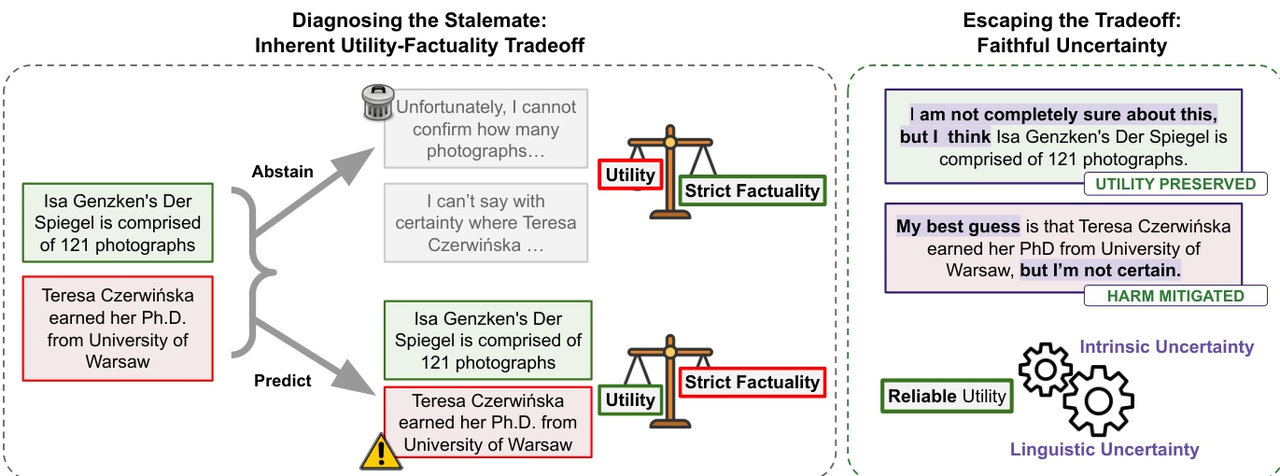
研究チームは、大規模言語モデルは事実の信頼性という点で絶えず改善されているものの、「錯覚」の問題は依然として蔓延しており、特に外部ツールが不足している事実に関する質問応答シナリオで顕著であると指摘している。この研究は、現在の進歩は、モデルが「既知」と「未知」を真に区別する能力よりも、知識規模の拡大に大きく起因していると主張している。したがって、錯覚を完全に排除することは、モデルの実用性との自然なトレードオフとなる可能性がある。
この観点に基づき、本研究は「誠実な不確実性」という概念を提唱し、モデルは自身の不確実性を正直に表現し、言語的不確実性と内部認知との一貫性を確保すべきであることを強調する。このメタ認知能力は、モデルの信頼性向上に役立つだけでなく、インテリジェントエージェントシステムにおける探索と意思決定のための、より信頼性の高い制御メカニズムを提供する。
論文と詳細な解釈:https://go.hyper.ai/G77rj
データセットの構成とソース: 著者らは、Nakkiran et al. (2025) によって記録された経験的信頼分布特性を再現するために、25,000 サンプルを含む合成データセットを構築しました。

4. プリズム
論文のタイトル:
SFTからRLへの変換を超えて:マルチモーダルRLのためのブラックボックスオンポリシー蒸留による事前アライメント
大規模マルチモーダルモデルの微調整中に、分布シフトが後続の強化学習に影響を与えるという問題に対処するため、研究チームはPRISMと呼ばれる3段階プロセスを提案した。この手法では、教師あり微調整と強化学習の間に、ポリシー内蒸留に基づく分布整合段階を挿入し、ハイブリッドエキスパート(MoE)識別器を利用してデカップリング補正信号を提供する。
PRISMは、113,000個の高品質なGeminiデモデータセットを使用することで、Qwen3-VL実験における下流の強化学習のパフォーマンスを大幅に向上させ、4Bモデルと8Bモデルの精度をそれぞれ4.4ポイントと6.0ポイント向上させた。
論文と詳細な解釈:https://go.hyper.ai/5fsD3
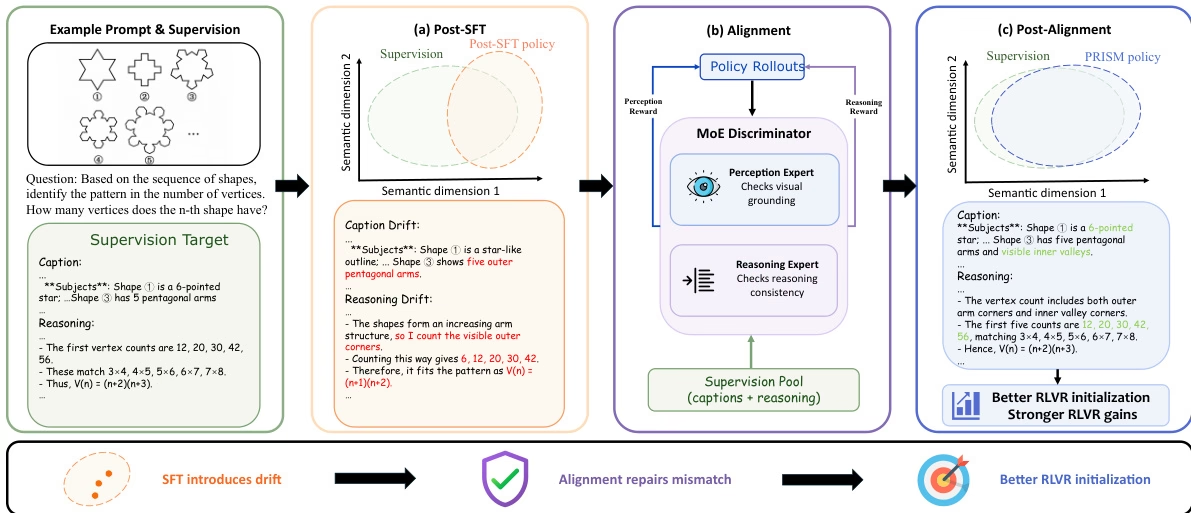
データセットの構成とソース:本論文では、数学的推論、科学的グラフの理解、グラフの解釈、空間推論を網羅する公開ベンチマークテストから得られたデータを用いて、マルチモーダル推論コーパスを構築します。網羅性と安定性を向上させるため、この厳選されたデータセットには、同じGeminiモデルシリーズによって生成された126万件の公開デモデータが補足されています。
5. ExoActor
論文のタイトル:
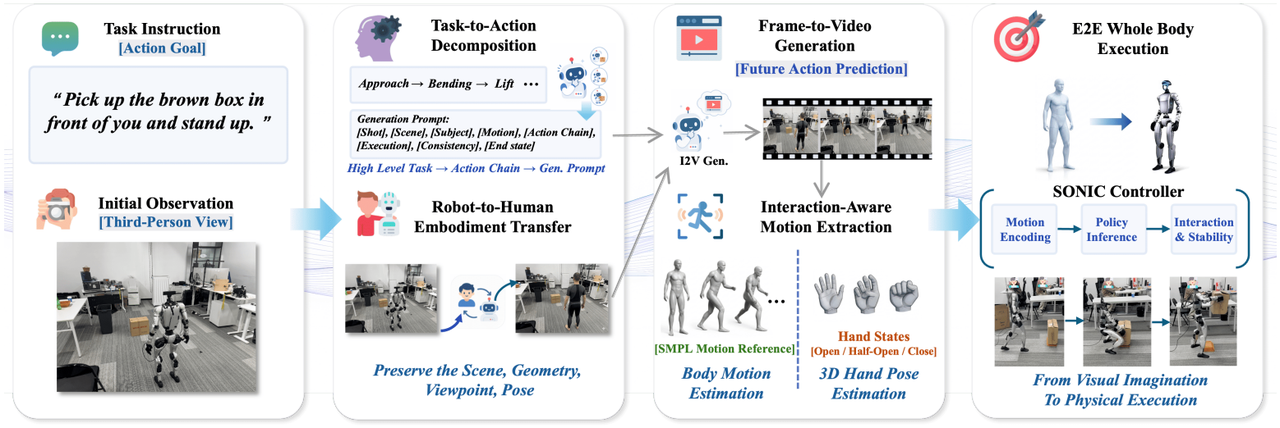
ExoActor:汎用的なインタラクティブなヒューマノイド制御としての外部中心型ビデオ生成
研究チームは、ロボット、環境、および物体間の協調的な相互作用を暗黙的に符号化するための統一インターフェースとして、外部中心型ビデオ生成を用いるExoActorフレームワークを提案した。また、合成された実行ビデオを人間の動作推定と汎用モーションコントローラを通して実行可能なヒューマノイドロボットの動作に変換することで、追加の現場データ収集を必要とせずに新たなシナリオに一般化できる能力を実証した。
論文と詳細な解釈:https://go.hyper.ai/OE5IH
6. 編集-R1
論文のタイトル:
画像編集における検証者ベースの強化学習の活用
研究チームは、画像編集のための強化学習フレームワークであるEdit-R1を提案した。従来の報酬モデルは総合スコアのみを出力するのに対し、Edit-R1は編集指示を複数の原則に分解し、思考連鎖推論に基づいて編集結果を項目ごとに検証することで、よりきめ細かく解釈可能な報酬シグナルを生成する。さらに、本研究では、教師あり微調整とGCPO強化学習戦略を組み合わせることで、報酬モデルが人間の好みをより正確にモデル化できるよう改善し、GCPOを用いて下流の編集モデルを訓練する。
実験結果によると、Edit-RRMは画像編集評価においてSeed-1.5-VLやSeed-1.6-VLなどの強力なVLMを凌駕し、FLUX.1-kontextなどの編集モデルのパフォーマンスを大幅に向上させるとともに、パラメータ拡張による大きなメリットも実証している。
論文と詳細な解釈:https://go.hyper.ai/MtBLB
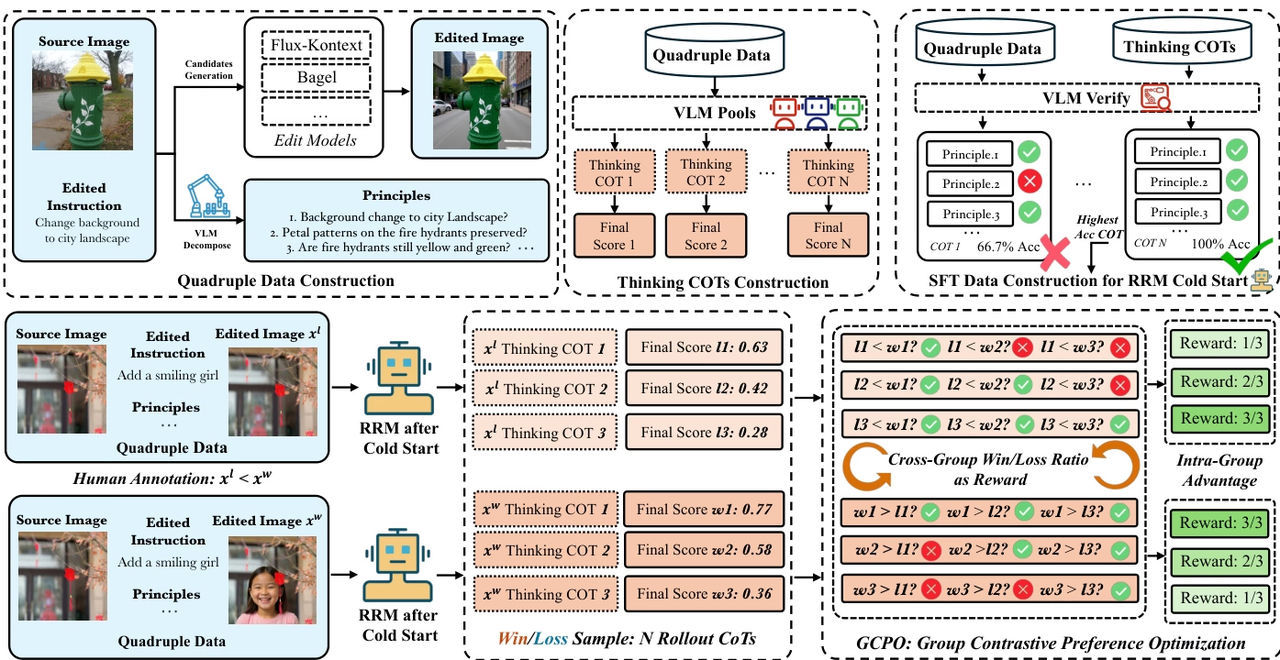
データセットの構成とソース:研究チームは、公開されている画像編集ベンチマークから20万個のサンプルを収集し、コールドスタート推論報酬モデル用の教師ありデータセットを構築しました。この初期セットは、マルチモデル生成と体系的な検証を通じて、約200万個のデータクワッドに拡張されました。

7. 共進化する政策抽出
論文のタイトル:
共進化する政策抽出
研究チームは、主流の研修後パラダイムであるRLVRとOPDの2つを統一的に分析し、複数の専門家能力を統合するプロセスにおいて、それぞれ異なる限界があることを指摘した。ハイブリッドRLVRは「能力の乖離コスト」が発生しやすい一方、従来の「まず専門家を育成し、その後OPDを実施する」プロセスは能力の衝突を回避できるものの、教師と生徒の行動パターンに大きな違いがあるため、専門家能力を完全に継承することは難しい。
この課題に対処するため、本研究では、双方向OPD(Optical Processing Derivative)を導入しつつ、専門家がRLVR(Reference-Based RLVR)の学習を継続的に行う共進化戦略であるCoPD(Co-Evolutionary Processing)を提案する。これにより、専門家同士が教師として協力し、共進化することで、補完的な能力を維持しながら行動の一貫性を向上させることができる。実験結果によると、CoPDはテキスト、画像、動画の推論能力を効果的に統合し、ハイブリッドRLVRやMOPDといった強力なベースラインを大幅に上回り、一部のタスクではドメインエキスパートモデルをも凌駕する性能を発揮する。
論文と詳細な解釈:https://go.hyper.ai/cCyrG
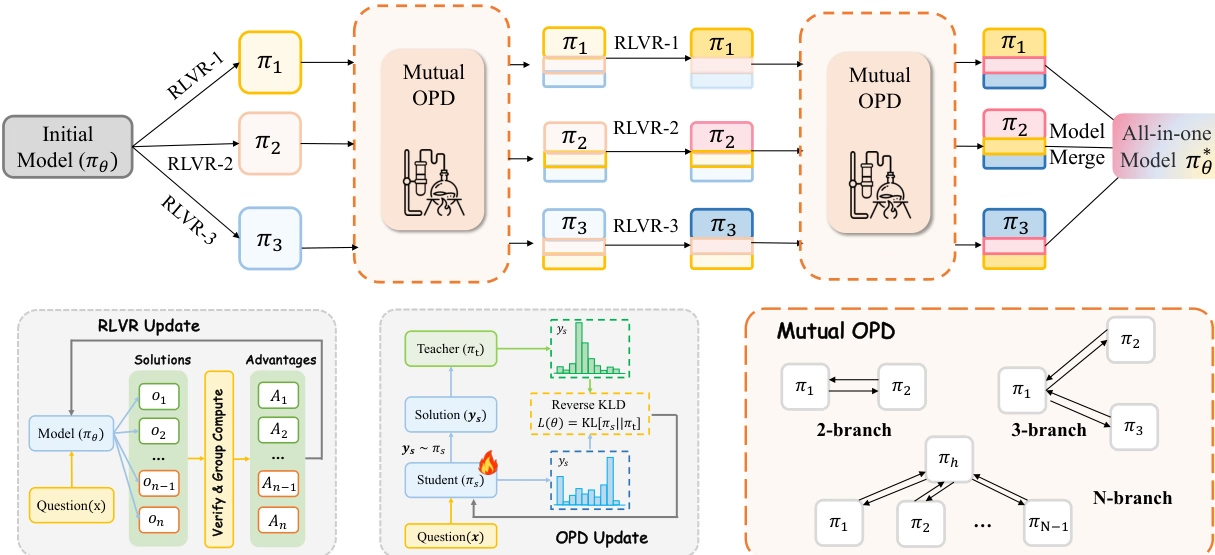

8. クロージム
論文のタイトル:
ClawGym:効果的な爪型エージェントを構築するための拡張可能なフレームワーク
研究チームは、ローカルファイル、ツール呼び出し、永続的なワークスペース状態を含む複雑な多段階ワークフローをサポートするために、Clawスタイルのパーソナルエージェント開発のライフサイクル全体に対応する拡張性の高いフレームワークであるClawGymを提案した。
このフレームワークには、13,500の厳選されたタスクを網羅する合成データセットClawGym-SynDataが含まれており、人間の意図、スキル操作、シミュレーションされた作業空間、およびハイブリッド検証メカニズムを組み合わせています。ClawGymエージェントはブラックボックス展開軌跡に基づいてトレーニングされ、軽量強化学習パイプラインを通じてその能力が向上します。さらに、信頼性の高い評価のために、自動的に選択され、人間とLLMによって共同でレビューおよび較正されたベンチマークセットClawGym-Benchが構築されています。
論文と詳細な解釈:https://go.hyper.ai/yZwa5
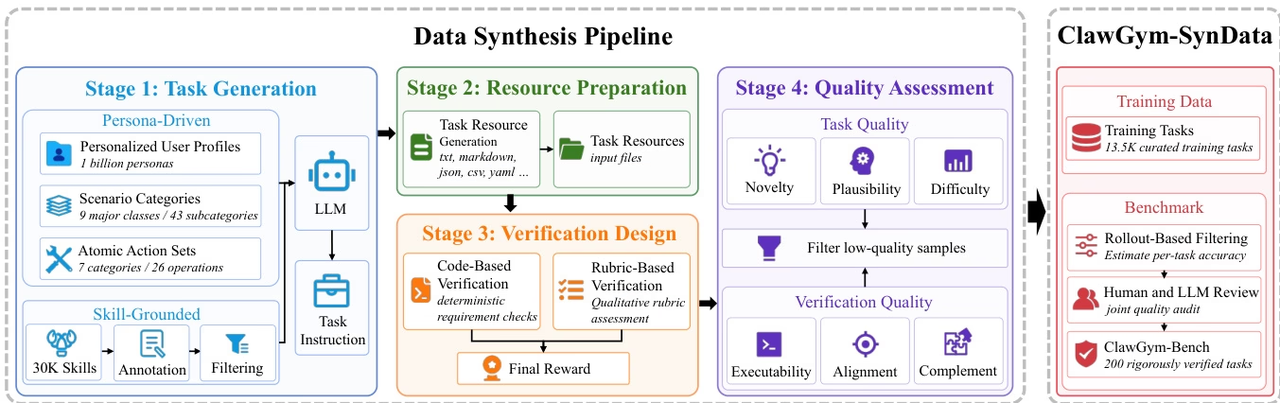
データセットの出典:研究チームは、多様なユーザーシナリオに対応するパーソナリティ主導型のトップダウン合成と、OpenClawの機能を実際のワークフローに接続する技術に基づくボトムアップ合成を組み合わせたClawGym-SynDataフレームワークを使用してトレーニングデータを生成しました。
今週の論文推薦は以上です。さらに最先端のAI研究論文をご覧になりたい方は、hyper.ai公式サイトの「最新論文」セクションをご覧ください。
質の高い研究成果や論文の提出を歓迎いたします。ご興味のある方は、NeuroStar WeChat(WeChat ID: Hyperai01)にご登録ください。
また来週お会いしましょう!








