Command Palette
Search for a command to run...
トークンの使用量は30%減少しました。「アバター」に触発された異種インテリジェントエージェントフレームワークであるEywaは、言語モデルとドメイン固有の基本モデルを効率的に組み合わせます。

近年、エージェント型AIは人工知能分野における最も重要な進化の方向性の1つとなっている。自動プログラミングや知識検索からタスクプランニングまで、大規模言語モデル(LLM)は徐々に「チャットボット」から、自律的な推論、行動、および協働能力を備えたインテリジェントエージェントシステムへと進化している。しかし、ますます明白になる問題も同時に現れている。主流のインテリジェントエージェントシステムのほぼすべては、本質的に「言語中心」のシステムである。タスク計画、ツールの呼び出し、インテリジェントエージェント間の連携など、それらはすべて自然言語という統一されたインターフェースに基づいて構築されている。
このパラダイムは、インターネット上の質疑応答やオフィスオートメーションといったシナリオではうまく機能します。しかし、AIが本格的に科学研究の分野に進出し始めると、すぐに問題が生じます。これは、科学の世界が本来言語に属するものではないためです。時系列データ、物質の結晶構造、タンパク質配列、気象グリッド、リモートセンシング観測データなど、これらのデータは高度に構造化されていることが多く、効果的に「テキスト化」することが不可能な場合さえあります。それらを強制的に自然言語に翻訳すると、情報が失われるだけでなく、大規模なモデルではトークンの消費量が極めて高くなり、推論の冗長性も増大する。
この文脈では、イリノイ大学アーバナ・シャンペーン校(UIUC)の研究チームは、言語エージェントとドメイン固有の基礎モデルを接続するための、Eywaと呼ばれる異種エージェントフレームワークを提案した。研究者たちは、ドメイン固有の基盤モデルと言語モデルを組み合わせることで、新しいEywaAgentを開発した。この設計により、言語エージェントは、特定のタスクにおける推論、計画、意思決定のプロセスにおいて、基盤モデルを導くことができる。
研究者らは、物理科学、生命科学、社会科学など複数の分野にわたってEywaの体系的な評価を実施した。その結果、言語モデルのみに依存するベースラインシステムと比較して、Eywaは一貫して有用性とコストのトレードオフを改善していることが示された。単一LLMエージェントのベースラインと比較して、EywaAgentは物理科学、生命科学、社会科学のタスクにおいて、平均で約71 TP3Tの有用性の向上、約301 TP3Tのトークン削減、および約101 TP3Tの実行時間の短縮を達成した。同様に、マルチエージェントシナリオにおいても、EywaMASはトークン消費量と実行時間を削減しながら有用性を向上させた。
関連する研究成果は、「異質な科学的基盤モデルのコラボレーション」と題され、arXivにプレプリントとして公開されている。
研究のハイライト:
* 構造化データやドメイン固有データを扱うタスクにおいて、Eywaはシステムパフォーマンスを効果的に向上させることができます。
* Eywaは、専用の基盤モデルと効果的に連携することで、言語ベースの推論への依存度を低減します。
* Eywaはマルチエージェントシナリオにも拡張可能です。EywaMASでは、EywaAgentが従来のマルチエージェントシステムの言語エージェントを置き換えることができます。EywaOrchestraでは、プランナーが言語エージェントとEywaAgentを動的に調整して複雑なタスクを解決できます。

論文を見る:
https://hyper.ai/papers/2604.27351
EywaBench:マルチタスク、マルチドメイン、マルチモーダルな科学的評価システム。
研究チームは、モデルフレームワークを提案する前に、まず現在の科学的AIベンチマークにおける長年の問題点を指摘した。言い換えれば、現在の科学的なベンチマークのほとんどは、単一のタスクタイプのみを対象としているか、単一の領域のみに焦点を当てているか、または単一のデータ形式のみをサポートしているかのいずれかである。そのため、科学的なエージェントシステムに真に必要とされる能力を十分に反映できない場合が多い。
研究チームは特に、既存のベンチマークでは時系列データと表形式データという2つの主要なデータ形式の評価が長らく不十分であったことを指摘している。これら2種類のデータは、現実世界の科学計算システムや産業システムの基盤を構成するものである。そこで、本論文では新たな評価フレームワークを提案する。EywaBenchは、異種環境、マルチタスク、マルチドメインの科学的推論のための拡張性の高いベンチマークです。
EywaBenchは、以下を含む(ただしこれらに限定されない)複数の既存データセットに基づいて構築されています。
* ディーププリンシプル
* MMLU-Pro
* fev-bench
* TabArena
EywaBenchは、マルチタスクおよびマルチドメインのカバレッジ機能を備えています。これには、自然言語、時系列データ、表形式データという3つの主要なデータ形式が含まれます。すべての業務は、3つの科学分野に分類されます。1つ目は、材料、エネルギー、航空宇宙を含む物理科学。2つ目は、生物学、臨床、医薬品開発を含む生命科学。3つ目は、経済、ビジネス、インフラなどの分野を網羅する社会科学です。
さらに重要なのは、EywaBench自体が拡張性を備えているため、研究チームは新しい時間枠、変数の組み合わせ、コンテキスト構成を追加することで、タスクの規模を継続的に拡大できる点です。また、新しい時系列データセットや表形式データセットにアクセスして、新たな科学分野に進出することも可能です。
Eywa:言語エージェントとドメイン固有の基盤モデルを接続する
エイワの核となる着想は、映画『アバター』に登場する「ツァヘイル」という概念から来ている。パンドラでは、ナヴィ族は神経接続を通して、ドラゴンや軍馬といった様々な種族と直接的な協力関係を築くことができ、それによって異なる生物が一体となって行動する能力を発揮できるのだ。
研究チームは、現在のエージェントシステムも同様の問題に直面していると考えている。 LLMは高度な推論能力と計画能力を備えているが、生の科学データの処理には長けていない。一方、ドメインベースモデルは高い専門能力を備えているが、複雑なタスク推論を実行することはできない。したがって、本論文では、言語モデルとドメイン基盤モデル間の双方向通信メカニズムを確立するFM-LLM「Tsaheylu」インターフェースを提案する。これは以下の図に示すとおりである。
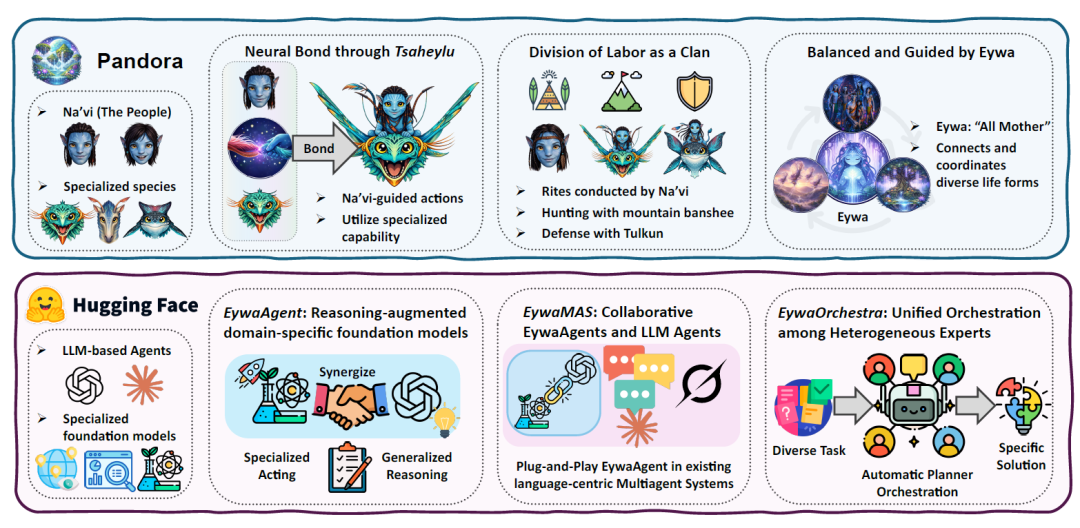
ステップ1:EywaAgentを構築する
Eywaエージェントフレームワークへの第一歩は、EywaAgentを提案することです。EywaAgentは、基本モデルに言語ベースの推論インターフェースを追加し、エージェントシステム内の高レベルの推論プロセスに参加できるようにする、統一された抽象フレームワークです。その核心となる考え方は、高度な計画と制御を実行するための言語モデルと、専門的な能力を提供するドメイン固有の基本モデルとの間に強固な結びつきを確立することである。
EywaAgentは、FM-LLM「Tsaheylu」チェーンと呼ばれる双方向通信インターフェースを介して、言語ベースの推論とドメイン固有の計算を組み合わせます。このリンクにより、言語モデルが正しく構成され、特殊な計算のために基盤となるモデルを呼び出すことができるようになります。同時に、出力は推論プロセスにシームレスに再統合されます。
Tsaheyluインターフェースは、2つの関数として形式化されています。クエリコンパイラϕkは、タスクの状態を基本モデルへの構造化された呼び出しに変換する役割を担い、応答アダプタψkは、基本モデルの出力を互換性のある言語の表現に変換する役割を担います。この通信パイプラインにより、エージェントは計算を内部で実行するか、基本モデルに委任するかを動的に決定できるため、一般的な推論と特殊な実行を柔軟に切り替えることができます。
ステップ2:Eywaエージェントシステムに拡張する
EywaAgentをプラグアンドプレイ型のエージェントモジュールとして定義した後、研究チームはこのパラダイムをマルチエージェントシナリオに拡張し、より複雑で異質な協調作業をサポートするようにしました。この目的のために、本論文では2つの補完的なシステムレベルの抽象化を提案しています。
エイワマス
EywaAgentは分散型マルチエージェント環境にも対応しており、複数の専門エージェントが相互に作用し、連携することを可能にします。EywaMASの通信および状態更新のダイナミクスは、標準的なマルチエージェントシステムモデルに準拠しており、エージェントは受信した情報に基づいて状態を更新し、メッセージを生成し、通信トポロジーによって相互作用が制御されます。この手法は、さまざまな言語モデル、基本モデル、およびエージェントタイプの柔軟な組み合わせをサポートします。
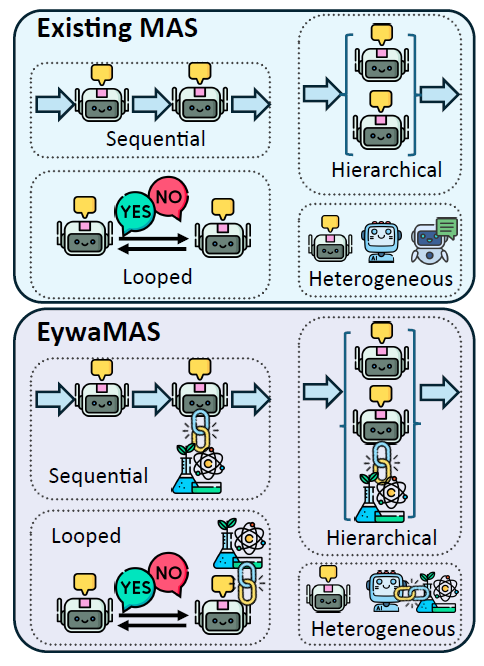
EywaMASは、既存のマルチエージェントシステムを拡張したものです。
エイワオーケストラ
多様なエージェント構成とトポロジー構成に対する現実世界のタスク要件の多様性に対応するため、本フレームワークは動的オーケストレーションシステムであるEywaOrchestraを導入します。EywaOrchestraはディレクターとして機能し、入力タスクに基づいて適切な言語モデル、ベースモデル、および通信トポロジーを選択することで、異種マルチエージェントシステムを動的にインスタンス化します。この適応型オーケストレーションにより、システムは静的設計の限界を克服し、モデルと構造の適応性を活用して各タスクに最適な構成を選択できます。
Eywaは、「効用とコスト」のトレードオフにおいて継続的な改善を実現しています。
研究チームは、統一された実験プロトコルに基づき、EywaBenchを用いてすべての手法をテストしました。以下の表は、EywaBenchの科学的タスクにおけるすべての手法の全体的なパフォーマンスを示しており、実験結果からいくつかの重要な結論が明らかになりました。
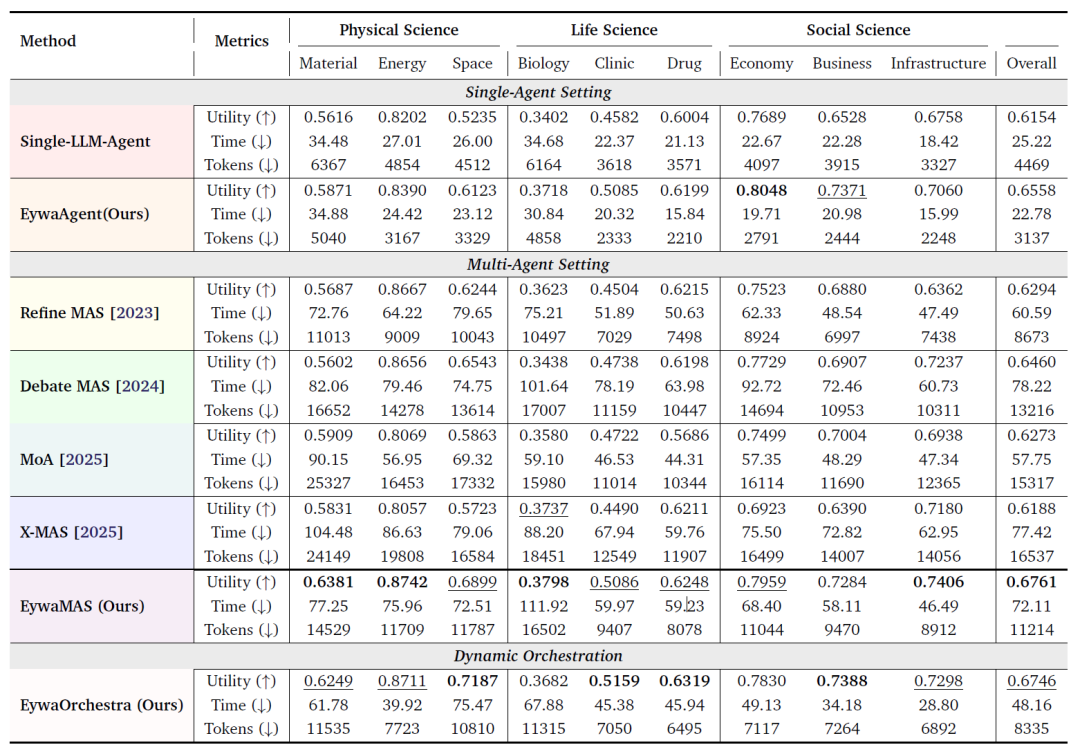
科学ミッションにおけるEywaBenchの総合的な性能比較
注:この表は、有用性(↑値が高いほど優れている)、推論時間(↓値が低いほど優れている)、トークン消費量(↓値が低いほど優れている)という3つの側面から、すべての手法を比較しています。最適な結果は太字で、次点の結果は下線で示されています。
まず、EywaAgentは同じ基幹ネットワーク条件下で、システム品質と効率の両方を向上させます。対応するシングルエージェントLLMベースラインと比較して、EywaAgentは平均効用を6.61 TP3T向上させます。同時に、ドメイン固有の基盤モデルへの計算の大幅な委譲により、推論レイテンシが大幅に短縮され、トークン消費量も約301 TP3T削減されます。
第二に、EywaMASは科学的なシナリオにおいて、従来の同型マルチエージェントシステムを大幅に上回る性能を発揮します。実験結果によると、EywaMASは全ての手法の中で最も高い総合的な有用性を実現しています。Refineと比較すると、EywaMASはパフォーマンス面で大きな優位性を持ち、Debateと比較すると、EywaMASは有用性が高いだけでなく、同じディベートトポロジーにおいて必要なトークン数も少なくて済みます。
3つ目の重要な発見は、「異質な言語モデル」だけに頼るだけでは、科学的な課題を解決するには不十分であるということだ。本論文で紹介した異種混合型LLMのみのMAS手法(MoAやX-MASなど)は、均質性の高いマルチエージェントベースラインを常に上回る性能を発揮するわけではありませんでした。このことから、科学的なタスクにおいては、真に重要な要素は「複数の異なるLLMの組み合わせ」ではなく、「クロスモーダルな異質性」の導入であることが示唆されます。言い換えれば、言語モデルを追加するよりも、金融時系列モデルや生物学的予測モデルの方が、多くの場合、より価値があるということです。
本論文では、より複雑なマルチエージェント連携がすべての領域で有効とは限らないことも指摘している。経済やビジネスといったサブドメインでは、シングルエージェントのEywaAgentが既に高い競争力を有している。つまり、複雑なマルチエージェント構成が常に最適な選択肢とは限らないということだ。場合によっては、過剰な連携によって余分なオーバーヘッドが発生する可能性さえある。
また、この実験では、EywaOrchestra は、より低コストで自動化の度合いが高く、専門家が設計した EywaMAS と比較してほぼ完璧なパフォーマンスを達成したことも示されました。手動設定が必要な EywaMAS とは異なり、EywaOrchestraのシステムアーキテクチャは、Conductorによって完全に自動的に構築されます。しかしながら、その有用性は手動で設計されたシステムに匹敵するレベルに達しつつあり、いくつかのサブドメインにおいてはそれを凌駕するほどです。同時に、動的なオーケストレーション機構により、推論の遅延とトークン消費量が大幅に削減されます。これは、タスク適応型システムオーケストレーションが自動化レベルを向上させるだけでなく、推論コストを効果的に最適化することを示しています。
結論
ここ数年、AI業界の主要なテーマはほぼ常に「大規模モデル」、つまりより大きなパラメータ、より長いコンテキスト、そしてより強力な推論能力を中心に展開されてきた。業界全体が「あらゆる問題を解決できる汎用モデル」の構築を目指しているのだ。
しかし、Eywaが示す方向性は、「モダリティネイティブなコラボレーション」が科学シナリオにおけるマルチエージェントシステムの能力を効果的に向上させ、将来的に異種基本モデルの協調推論のための新たな発展の道筋を提供することを示しています。言い換えれば、将来本当に重要になるのは「万能のAI」ではなく、「異種の専門家を組織して協調的に作業できるAIシステム」なのです。
参考文献:
https://arxiv.org/abs/2604.27351
https://hyper.ai/cn/papers/2604.27351








