Command Palette
Search for a command to run...
MITとIBMは、これまでで最大の合成チャートデータセットであるChartNetを公開した。ChartNetは、150万個の多様なチャートサンプルを生成している。

過去2年間で、マルチモーダル大規模モデルの開発は予想をはるかに超える進歩を遂げました。画像コンテンツの認識から複雑な文書の理解、動画情報の解析まで、ビジュアル言語モデル(VLM)は常にその能力の限界を押し広げています。しかし、一見単純でありながら非常に難しい視覚オブジェクトが1つあり、多くの高度なモデルが頻繁に「クラッシュ」してしまう原因となっています。それはグラフです。
人間にとって、棒グラフ、折れ線グラフ、散布図は、傾向、比較、重要な結論を素早く伝える手段となります。しかし、AIにとって、グラフは単なる画像以上のものです。モデルは、視覚要素を認識するだけでなく、軸、データポイント、凡例、ラベル間の関係を理解し、さらに数値抽出、傾向分析、因果推論まで実行する必要があります。つまり、グラフの理解は、視覚、数値、言語の認知能力を網羅する複雑なタスクであり、現在のVLM(視覚言語モデル)では、その一部しか実現できていません。
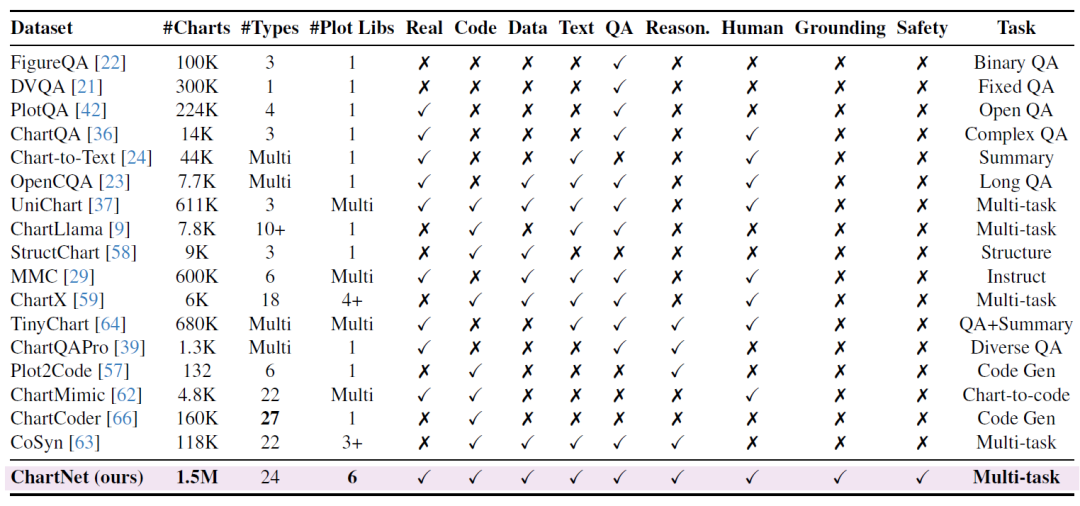
近年、いくつかのデータセットが関連研究の発展を牽引してきたが、それらは一般的に、規模が小さい、グラフの種類が限られている、完全なマルチモーダル情報が不足しているという3つの問題を抱えている。多くのデータセットは、単一のタスク(質問応答やグラフ記述など)にのみ焦点を当てていたり、重要なモダリティが欠けていたりするため、オープンソースモデルは複雑なグラフ推論タスクにおいて、依然としてプロプライエタリシステムに後れを取っている。
このギャップを埋めるために、ChartNetは、MIT、MIT-IBMコンピューティング研究所、およびIBMリサーチの多数の専門家によって提案された。グラフ理解のための数百万件のレコードを含む、高品質でマルチモーダルなデータセット。グラフ理解と推論能力の向上を目的として設計されています。
これは、これまでに作成された中で最大の合成チャートデータセットであり、斬新なコード誘導型合成プロセスを用いて、24種類のチャートタイプと6種類のプロットライブラリを網羅する150万個の多様なチャートサンプルを生成しました。広範な実験によりChartNetの実用性が検証され、最適化されたファインチューニングモデルが、はるかに大規模なモデルやGPT-4oをすべてのタスクで凌駕することが示されました。
データセットをオンラインで利用する:https://go.hyper.ai/lGPsc
関連研究の成果は、「ChartNet:堅牢なグラフ理解のための100万規模の高品質マルチモーダルデータセット」と題され、IEEEコンピュータビジョン・パターン認識会議で発表される予定です。
研究のハイライト:
ChartNetのコード主導型合成・生成プロセスは、大規模なチャートサンプル生成を可能にすると同時に、チャート理解に関する視覚的、構造的、数値的、およびテキスト的な情報を取得することを可能にする。
ChartNetは、実世界のデータと手動でラベル付けされたデータを統合し、視覚的なポインティングとセキュリティ分析をサポートする特殊なサブセットを含んでいるため、モデルのトレーニングと評価におけるデータセットの価値を高めることができます。
このデータセットで微調整を行うことで、グラフの再構築、データ抽出、グラフの要約といったタスクにおける視覚言語モデルのパフォーマンスを継続的に向上させることができます。

用紙のアドレス:
https://hyper.ai/papers/2603.27064
データセット:150万個のマルチモーダル整列合成サンプルで構成
ChartNetの中核データセットは、150万個のマルチモーダルなアラインメント済み合成サンプルで構成されています。各サンプルには、グラフ画像、プロットコード、表形式データ、自然言語による説明、および連鎖推論(CoT)を含む質問と回答のペアが含まれています。使用されているデータ属性、グラフの種類、およびプロットライブラリの全体像は、次の図に示されています。
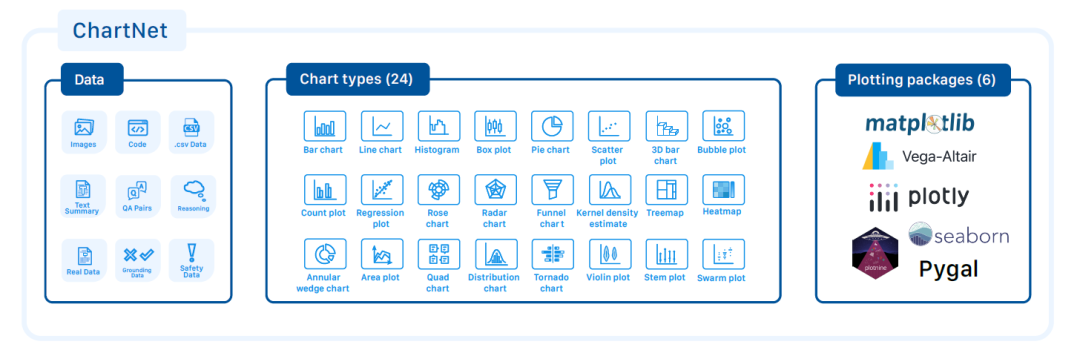
ChartNetは、グラフ理解におけるあらゆる機能を網羅するために、手動でラベル付けされたデータ、実世界のグラフ、グラウンディングデータ、セキュリティデータなど、いくつかの特殊なサブセットも含まれています。
手動でラベル付けされた複合チャートデータ:このデータベースには、96,643点の整列された合成チャート画像、説明、および表形式データが含まれており、これらはすべて厳密な人的検証と注釈を受けています。
高品質な実世界のチャートデータ:合成チャート集積を補完するため、研究者らは世界銀行、ベイン・アンド・カンパニー、ピュー・リサーチ・センター、アワー・ワールド・イン・データなどの権威ある国際的なメディアやデータ視覚化組織、その他世界的に有名な出版社から、3万点の実際のチャートを収集し、注釈を付けました。このコレクションは、経済、テクノロジー、地政学、環境科学、社会動向など、幅広い現代的なトピックを網羅しており、データの多様性と現実世界との強い関連性を確保しています。情報量が少ない、または品質が劣るチャートは、解釈可能性を確保するために意図的に除外されました。
データに基づいた品質保証:現代のビジュアルモデリング(VLM)は、特定の質問に関連するグラフ領域や構文要素を識別するのに依然として苦労している。この能力を向上させるため、研究者らはグラウンディングQAペアを構築した。まず、プロットコード要素(軸、目盛り、グリッド線、凡例、グラフィックブロック)から幾何学的に認識された注釈を抽出し、高密度のグラフグラウンディング注釈を生成した。エントロピーベースの手法を用いて、境界ボックスをさらにフィルタリングした。次に、生成されたグラウンディング注釈を用いて、各グラフごとにテンプレート化された質問と回答のセットを作成し、視覚要素の想定される空間レイアウトとグラフ内の実際の内容との対応関係を捉えた。
想定される位置は、シリアル化された境界ボックス表現を使用して回答文字列にエンコードされます。テンプレートには、インデックス、チャート内のテキストラベル、要素の色などの視覚属性を組み合わせて引用式を生成する、固有の視覚要素と繰り返し出現する視覚要素が含まれます。ジェネレーターは、短い回答と長い回答の両方をサポートし、オプションで根拠情報を含めることができます。最終的なデータセットは、すべてのテンプレートタイプと出力モダリティを均等にサンプリングすることにより、チャートごとに 1 つの QA ペアを生成します。さらに、推論ベースの根拠 QA ペアは、gpt-oss-120b を使用して生成されます。
セキュリティデータ:セキュリティ上の懸念に対処するため、研究者たちはデータ生成プロセスを拡張し、チャート関連のセキュリティに準拠したデータを生成することで、モデル出力における有害なコンテンツと「ジェイルブレイク」のリスクを低減した。
ChartNetの核となるアイデア:コードに基づいたチャートの合成による自動生成。
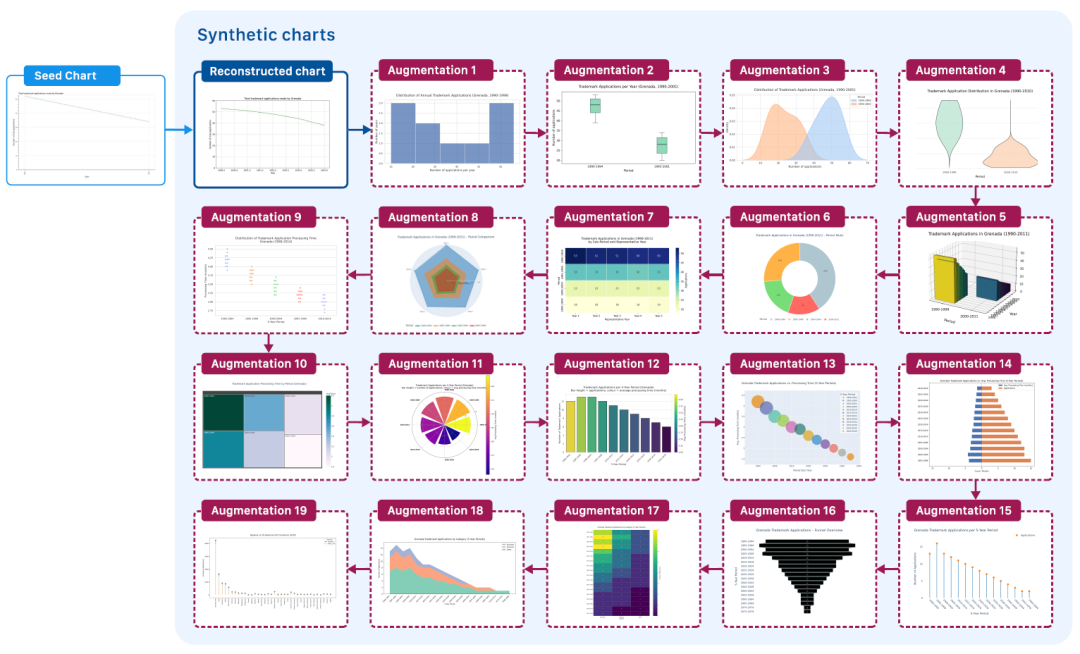
ChartNetのデータ生成の根幹となる考え方は、実行可能なプロットコードをデータ可視化のための構造化された中間表現として用い、プログラムによってチャートを生成できるという点です。研究者らは、限られた量のチャート画像データ(「シード」)から開始し、ビジュアル言語モデル(VLM)を使用してこれらのチャートを大まかに再構築できるコードを出力する、大規模なコード誘導型自動チャート生成プロセスを提案しています(下図参照)。
コードガイドによるチャート拡張プロセス
具体的には、データ生成プロセスは以下の段階から構成されます。
① チャートからコードへの再構築:VLMは、与えられた一連のグラフ画像を大まかに再現するためのPythonプロットコードを生成するために使用されます。この段階では、TinyChartデータセットから15万個の固有のグラフ画像がシードとして選択されますが、このプロセスはシードの選択に特に依存しません。
② コードガイドによるチャート拡張:生成されたプロットコードを入力として使用し、大規模言語モデル(LLM)を用いてコードを繰り返し書き換えます。前回の反復との関連性を維持しながら、基となるデータ値とラベルを修正して、目的のグラフタイプにより適合するようにします。下の図は、反復的なコード強化とグラフレンダリングのプロセスを示しています。この段階はデータセットのスケーリングにおける重要なステップであり、各シード画像から任意の数のバリアントを生成できます。
③ グラフ表示:生成されたすべてのプロットコードを実行してグラフ画像を生成し、正常に実行されたスクリプトには生成された画像が関連付けられます。
④ 品質フィルタリング:各グラフ画像はVLMを使用して評価され、テキストの重なり、ラベルの切り抜き、グラフ要素の遮蔽など、さまざまな潜在的なレンダリング欠陥カテゴリが検出されます。視覚的な問題のある画像とそのプロットコードは削除されます。
⑤ コードガイドによる属性生成:最後に、VLMを用いて、チャート画像とコードのペアに対する補足的な意味属性を生成します。コードのコンテキスト内でチャートからデータ値とラベルを抽出し、表形式のデータ表現を生成します。さらに、視覚情報、コード、表形式データを組み合わせることで、根拠に基づいたチャート記述を生成します。
これは、あらゆるグラフ理解タスクにおいて、顕著かつ一貫した改善をもたらします。
ChartNetがモデルのチャート理解能力を向上させる上でどれほど効果的かを検証するため、研究者らはChartNetデータセットを用いて、超小型(パラメータ数10億以下)、小型(パラメータ数40億以下)、中型(パラメータ数70億以下)など、様々なサイズの視覚言語モデルを訓練した。
全体として、ChartNetデータセットでの微調整は、すべてのチャート理解タスクにおいて、顕著かつ一貫した改善をもたらします(下表参照)。これらの改善の均一性と規模は、モデルのサイズとは無関係です。これは、既存のVLMには高品質なマルチモーダルなグラフ教師あり学習の機会が不足していることを示している一方、ChartNetはこのギャップを効果的に埋めている。
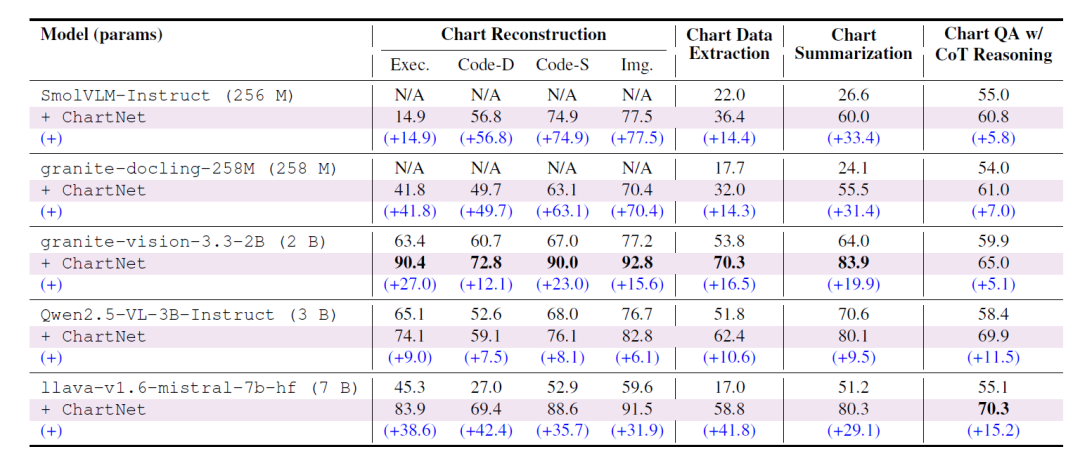
① チャートの再構築
Chart-to-Code サブセットでトレーニングされたモデルは、コード実行率、データの一貫性、構造/コードの類似性、および画像の類似性において大幅な改善を達成しました。以前はチャートをまったく再構築できなかった超小型モデル (SmolVLM-256M、Granite-Docling-258M) は、完全な機能を備えています。より小さなモデル (Granite-Vision-2B など) は、複数の指標が 90% を超えるほぼ完璧な再構築を達成しました。LLaVA-7B モデルは、データの一貫性で最大 +42.4 ポイントの改善を達成しました。このスケールに依存しない傾向は、ChartNet の画像とコード間のマルチモーダルアライメントが、以前はデータセットに欠けていた構造化された教師をモデルに提供していることを示しています。
② チャートデータの抽出
ChartNetは、すべてのモデルがチャートから数値テーブルを直接復元する能力を大幅に向上させ、Granite-Vision-2Bは70.31 TP3Tという最高のパフォーマンスを達成しました。さらに、微調整されたLLaVA-7Bは+41.8ポイントのパフォーマンス向上を示し、すべてのオープンソースベースラインを上回り、GPT-4o(わずか46.71 TP3T)をも凌駕しました。これは、ChartNetがコード生成チャートとCSVデータを密接に連携させることで、モデルが視覚的な形状と基となる数値構造の両方にアクセスできるようにするという利点を示しています。
③ 図表の要約
すべてのモデルファミリーの要約精度が大幅に向上し、増加率は+9.5(Qwen2.5-VL-3B)から+31.4(Granite-Docling-2B)に及びました。ファインチューニングされたGranite-Vision-2Bは83.9%に達し、GPT-4oおよび表3のすべてのオープンソースベースライン(パラメータサイズが1桁大きいモデルを含む)を上回りました。これは、ChartNetの合成要約(コードとレンダリングされたチャートによって共同で構築される)が、記述的なチャート理解のための構造化された意味的に完全な教師信号を提供することを示しています。
④ 質疑応答(CoT推論を含む)
複雑な多段階推論タスクにおいて、各モデルは着実に精度が向上しました。LLaVA-7Bは最大の改善(+15.17)を示し、70.3%に達し、専用のチャート推論モデルであるChartGemmaや、同等以上のすべてのオープンソースモデル(GPT-4oを含む)を上回りました。
⑤市販モデルとの比較
下の表は、ChartNetでファインチューニングされたモデルが、ほぼすべての指標において、より大きなパラメータを持つ既製モデルを上回る性能を発揮することを示しています。ファインチューニング後、2Bまたは7Bのパラメータを持つモデルは、20B~72Bのパラメータを持つモデルを常に上回ります。特に、グラフの再構築とデータ抽出タスクにおいて、ChartNetでファインチューニングされたモデルはGPT-4oをはるかに凌駕します。
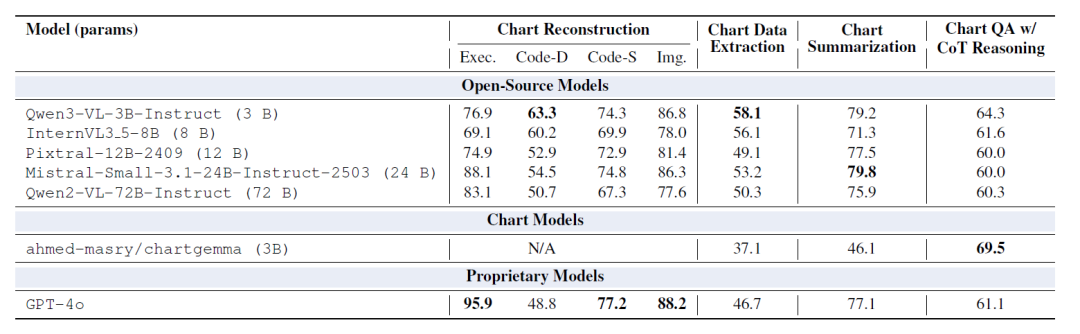
これは、グラフ理解のように、視覚、数値データ、言語が密接に結びついている領域では、単にモデルのサイズを大きくするよりも、高品質でコードに整合したマルチモーダルな監視を提供する方が効果的であることを示唆している。
⑥ 公的ベンチマークへの一般化
下の表に示すように、コアとなるChartNetデータセットで微調整を行った後、すべてのモデルが公開ベンチマークで大幅な改善を達成しました。Granite-Vision-2BはChartCapでBLEUスコアが1.6から12.4に、ChartMimic-v2で30.8から58.4に向上しました。超小型モデル(SmolVLM-256M)でさえ、かなりの性能向上を実現しました。この改善は、チャート要約タスクとチャートからコードへの生成タスクの両方で一貫しており、ChartNetのマルチモーダルアライメント監視が、合成トレーニング分布だけでなく、実世界のベンチマークにも効果的に適用できることを示しています。
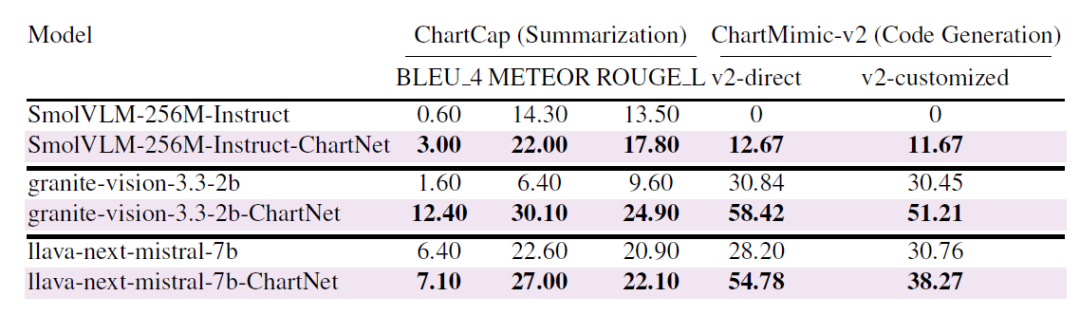
ChartNetの合成データを、2つの実世界の公開ベンチマークに適用することで、その汎化能力を向上させる。
結論
ChartNetは、チャート理解分野における根本的なボトルネック、すなわち画像、プロットされたコード、数値データ、テキスト記述、推論軌跡を整合させるための大規模かつ高精度な監視信号の不足という課題に取り組むことを目的としています。数値推論、視覚化理解、文書インテリジェンス、コード整合におけるマルチモーダルモデリング研究のための拡張可能でオープンな基盤プラットフォームを提供し、ビジュアルモデリング(VLM)を「チャートを記述する」段階から「チャートに符号化された構造化情報を理解する」段階へと発展させます。
「これまでの多くのトレーニングデータセットは、グラフに関する単純な質問に答えることにしか焦点を当てていませんでした」と、MITの電気工学・コンピュータ科学科(EECS)の大学院生であり、ChartNet関連論文の筆頭著者であるジョバナ・コンディック氏は述べています。「ChartNetでは、それを超え、グラフを包括的かつ深く理解するためのデータを生成することを目指しました。」
今後、研究者たちはChartNetをさらに拡張し、より複雑なデータを取り入れることで、より多くの業界に現実的な価値を提供していく計画だ。
参考文献:
https://arxiv.org/abs/2603.27064
https://news.mit.edu/2026/mit-researchers-teach-ai-models-to-interpret-charts-0603