Command Palette
Search for a command to run...
論文週間レポート|Microsoft MAI-Thinkingは純粋な強化学習の自己進化を探求し、AIME精度97%を達成。VLM³は、アーキテクチャの変更なしにプレーンテキスト座標を使用して3Dタスクの汎化を実現…今週の最先端AI論文の概要

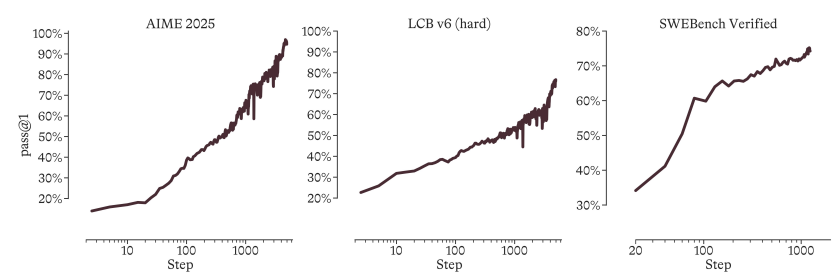
人工知能の進歩は、個々のモデルにおける画期的な進歩だけでなく、より重要なのは、継続的な自己改善が可能なシステムの構築にかかっています。この目的のために、マイクロソフトのAIチームは、モデル開発をシステムレベルの最適化問題として捉えています。迅速かつ持続的な性能向上を実現するために設計された「ヒルクライミングマシン」フレームワークを提案する。」これに基づき、総パラメータ数1T、活性化パラメータ数35BのMoE推論モデルMAI-Thinking-1をゼロから学習させた。
このモデルは、事前学習段階ではサードパーティ製モデルからの蒸留データを完全に破棄し、強化学習(RL)段階では適応型エントロピー制御と自己蒸留メカニズムを備えたGRPOアルゴリズムを導入します。実験結果によると、事前の推論軌跡を一切用いずに開始した場合でも、MAI-Thinking-1は長期的かつ安定した対数線形的な性能向上を達成できることが示された。最終的に、AIME 2025(97.0%)やSWE-Bench Pro(52.8%)などの主要ベンチマークにおいて、最先端のレベルの複雑な推論とコード生成を実現しました。
ペーパーリンク:https://go.hyper.ai/QeSWd
最新のAI論文:https://go.hyper.ai/hzChC
より多くのユーザーが学術界における人工知能分野の最新動向を理解できるよう、HyperAIのウェブサイト(hyper.ai)に「最新論文」セクションが新設され、最先端のAI研究論文が定期的に更新されるようになりました。おすすめの人気AI論文9選をご紹介します。今週の最新のAI成果を簡単に見ていきましょう⬇️
今週のおすすめ紙
1. MAI-Thinking-1
論文のタイトル:
MAI-Thinking-1:坂道登りマシンの構築
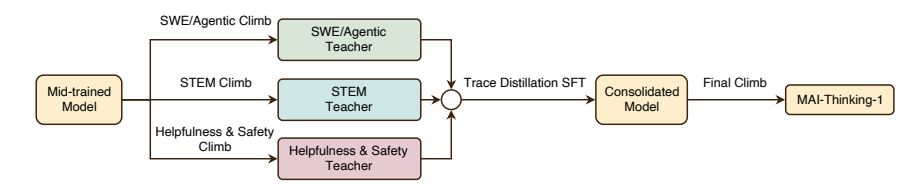
マイクロソフトのAIチームは、モデル開発をシステムレベルの最適化問題として扱う「ヒルクライミング」アプローチを提案しました。彼らは、合計1T個のパラメータと35B個の活性化パラメータを持つMoE推論モデルMAI-Thinking-1をゼロからトレーニングしました。モデルの事前トレーニングは、サードパーティの蒸留データを一切使用せず、完全にクリーンなデータに基づいて行われました。強化学習フェーズでは、適応型エントロピー制御と自己蒸留メカニズムを備えたGRPOアルゴリズムを使用することで、初期推論軌道なしで安定した長期的なパフォーマンス向上を実現しました。このモデルは最終的に、STEM、コードエージェント、セキュリティという3つの専門分野の機能を統合し、AIME 2025(97.0%)やSWE-Bench Pro(52.8%)などのベンチマークでクラス最高の推論およびコードパフォーマンスを発揮しました。
論文と詳細な解釈:https://go.hyper.ai/QeSWd
2. VLM³
論文のタイトル:
VLM³:ビジョン言語モデルはネイティブ3D学習器である
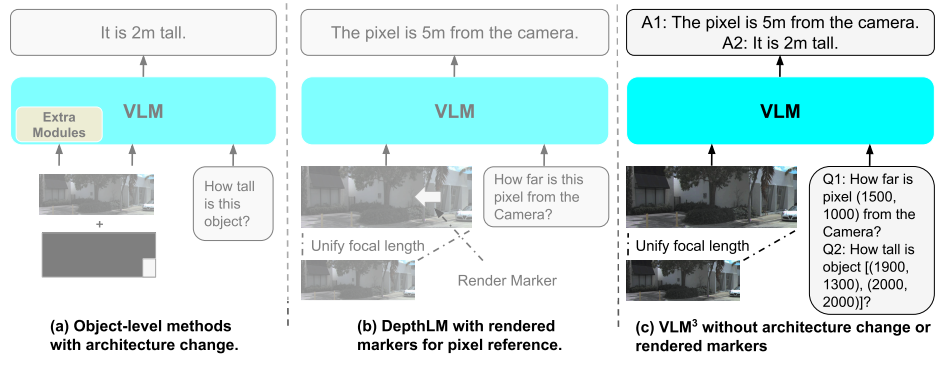
Meta氏とそのチームは、大規模な実験を通して、VLM(視覚モデル)が効率的な3D学習を実行するには、複雑なアーキテクチャや特殊な設計は必要なく、統一された焦点距離、テキストベースのピクセル参照の導入、そして適切なデータ混合と拡張戦略のみが必要であることを発見しました。この発見に基づき、研究チームは、標準的なVLMが深度推定、ピクセルレベルの対応付け、カメラ姿勢推定、オブジェクトレベルの3D理解といったタスクを同時に実行できるミニマルな設計であるVLM³を提案しました。VLM³は、元のアーキテクチャとテキストベースのトレーニング方法を維持しながら、エキスパートレベルの視覚モデルに匹敵する、あるいはそれに近い性能を発揮し、汎用視覚モデルが3D世界を学習するための、よりシンプルで拡張性の高い新たな道筋を示しています。
論文と詳細な解釈:https://go.hyper.ai/5ks6r
3. あらゆるものを探す
論文のタイトル:
LocateAnything:並列ボックスデコードによる高速かつ高品質な視覚言語グラウンディング
既存のビジュアル言語モデルでは、通常、オブジェクトの位置特定を座標トークンの段階的な生成プロセスとしてモデル化しており、境界ボックスの座標を順次予測する必要があります。これは、ボックス内の幾何学的関係を無視するだけでなく、推論速度も制限します。この問題を解決するために、NVIDIAチームは、並列ボックスデコード(PBD)メカニズムを使用して境界ボックスを原子単位として扱い、完全な座標セットを単一のステップで並列に生成するLocateAnythingを提案しました。1億3800万件のクエリを含む大規模なデータセットと、インテリジェントなエラーフォールバックを備えたハイブリッド推論モードを組み合わせることで、このモデルは、複数のベンチマークでより高いデコードスループットと優れた高IoU位置特定精度を実現し、統合ビジュアル位置特定および検出タスクの速度と精度の限界を押し上げています。
論文と詳細な解釈:https://go.hyper.ai/C8jXC
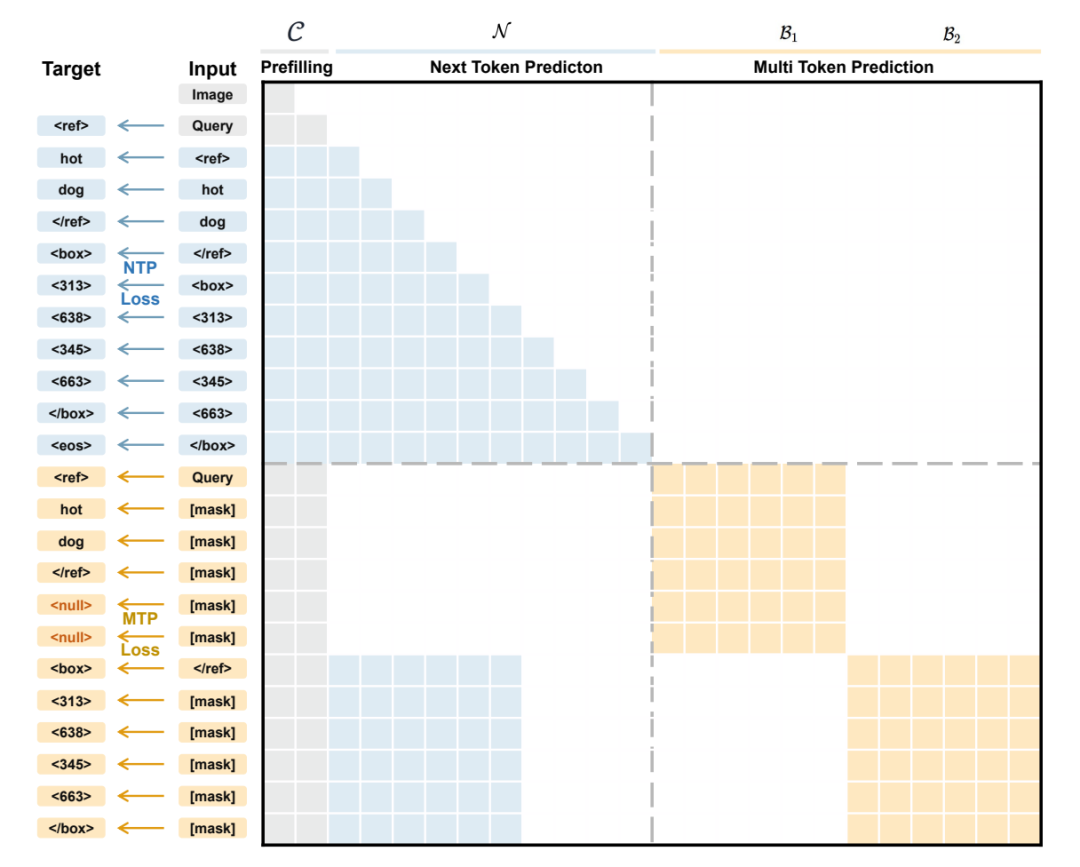
データセットの構成とソース:研究チームは、1200万枚のユニークな画像、1億3800万件の自然言語クエリ、および7億8500万件のラベル付きバウンディングボックスを含む大規模なコーパスであるLocateAnything-Dataを構築しました。

4. クウェンVLA
論文のタイトル:
Qwen-VLA:タスク、環境、ロボットの形態を横断した視覚・言語・動作モデリングの統合
身体化された知能の研究は、これまで単一タスクに特化したモデルに依存してきたため、機能が断片化され、汎化能力が制限されていました。Qianwenチームは、視覚・言語・動作を統合した基盤モデルであるQwen-VLAを提案します。DiTベースの動作デコーダーを通して、視覚・言語の知覚、理解、推論を連続動作と軌道生成に拡張します。このモデルは、ロボットの動作軌道、人間の一人称視点デモンストレーション、シミュレーションデータ、ナビゲーションタスク、補助的な視覚・言語信号を含む大規模な共同事前学習を採用しています。また、身体化された知覚キュー条件付けメカニズムを通して、様々なロボットプラットフォームに適応します。Qwen-VLAは、動作、ナビゲーション、軌道予測を統一されたフレームワークに統合し、タスク、環境、ロボットの形態を超えた転移性を実現します。実験では、このモデルが複数の動作およびナビゲーションベンチマークにおいて、安定したマルチタスク性能と分布外汎化能力を示すことが実証されています。
論文と詳細な解釈:https://go.hyper.ai/5x2Tj
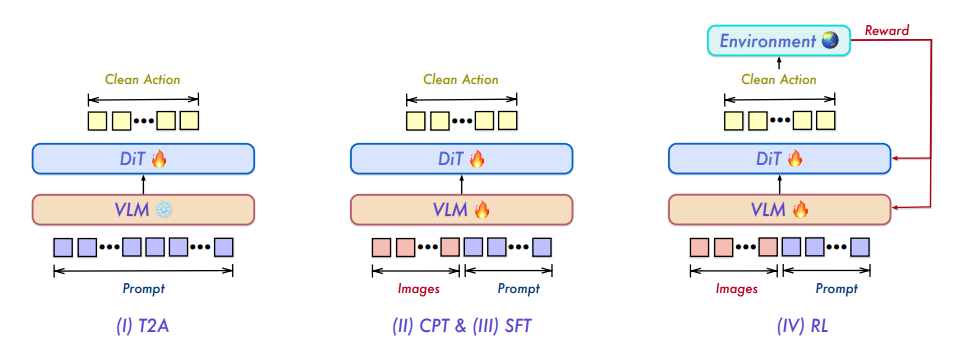
データセットの構成とソース:研究チームは、視覚、言語、および動作モデリングを統合するために、大規模で多様な事前学習済みコーパスを構築しました。データソースには、10を超える公開ロボットベンチマーク、大規模な人間のビデオコーパス、独自に収集した社内データ、および社内で生成されたシミュレーションパイプラインが含まれます。

5. SDPG
論文のタイトル:
自己蒸留政策勾配
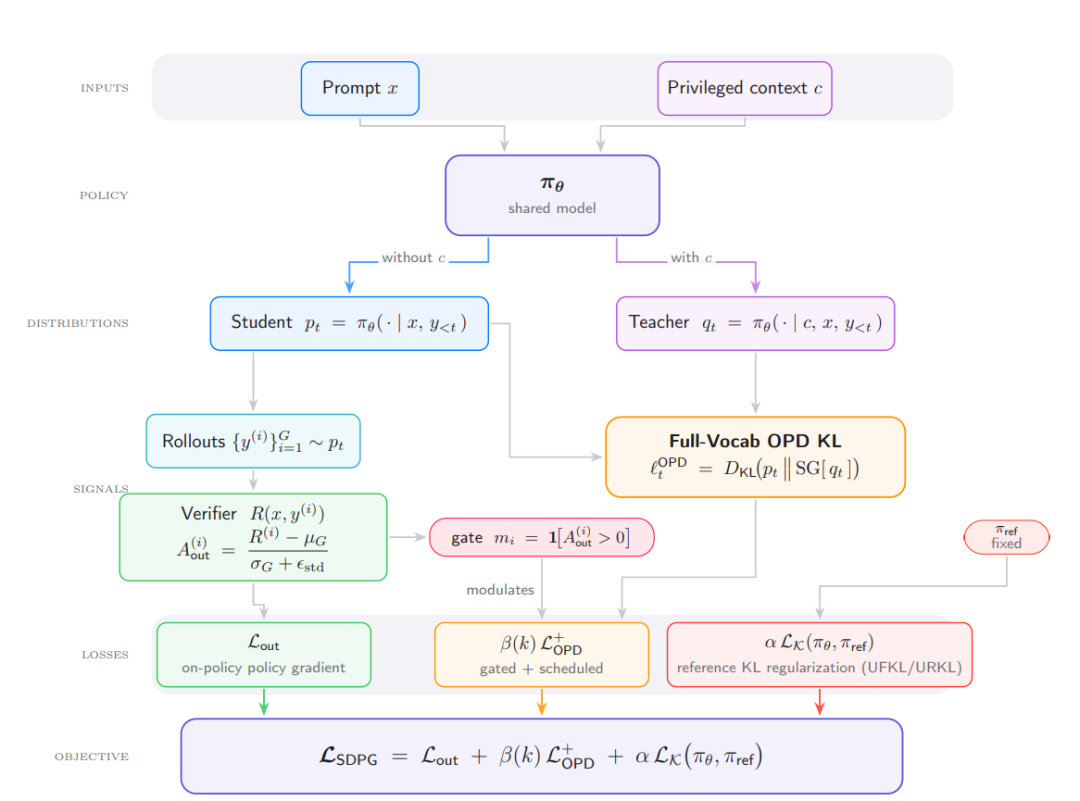
ポリシーベース自己蒸留(SDPG)は、モデルの特権的なコンテキストを利用して、モデル自身が生成した結果を監視し、スパース報酬強化学習のためのより密度の高い学習シグナルを提供します。これは、語彙全体に対する逆KL生徒教師損失として定式化できます。これを基に、UCLAとプリンストン大学の研究者は、グループ相対検証者優位性、標準偏差正規化、オンライン全語彙自己蒸留、および参照ポリシーKL正則化を組み合わせたSDPGフレームワークを共同で提案しました。実験では、SDPGがRLVRおよび既存の自己蒸留手法と比較して安定性とパフォーマンスを向上させることが示されています。
論文と詳細な解釈:https://go.hyper.ai/p5irp
6. GSMシンボル
論文のタイトル:
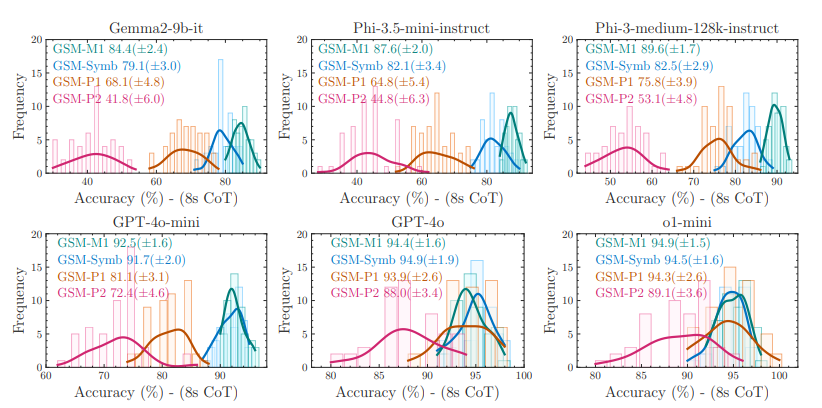
GSM-Symbolic:大規模言語モデルにおける数学的推論の限界を理解する
研究によると、従来のGSM8Kベンチマークではモデルの真の性能を正確に反映するには不十分であることが示されています。そこで、Appleチームは、記号テンプレートに基づいて制御可能なベンチマークであるGSM-Symbolicを構築しました。実験では、質問内の数値やエンティティ名を変更するだけで大規模モデルのパフォーマンスが大きく変動し、無関係な妨害条項を追加すると精度がさらに大幅に低下することが示されています。研究チームは、現在のLLMは真の論理的推論能力を備えているのではなく、トレーニングデータで観察された推論ステップを再現しようとしているだけだと仮説を立てています。
論文と詳細な解釈:https://go.hyper.ai/n3UfJ
7. MUSE-Autoskill
論文のタイトル:
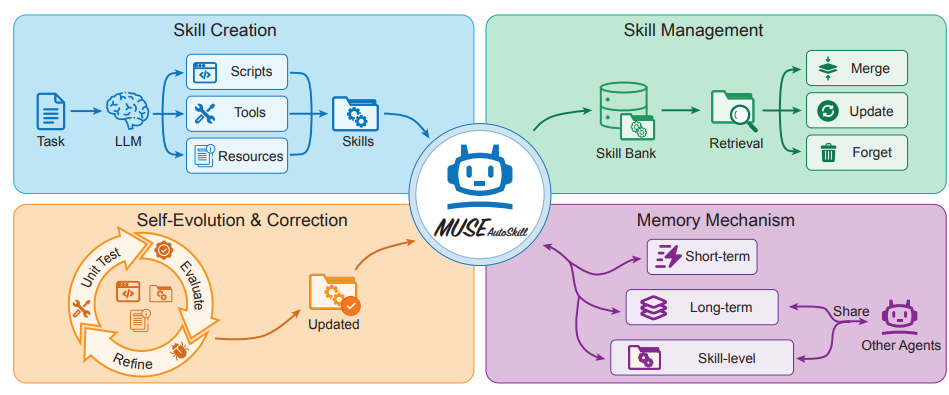
MUSE-Autoskill:スキル作成、記憶、管理、評価による自己進化型エージェント
ByteDanceを含むチームは、スキルの作成、記憶、管理、評価、最適化を完全なライフサイクルに統合するインテリジェントエージェントフレームワーク「MUSE-Autoskill」を提案しました。このフレームワークは、スキルレベルのメモリを導入してタスク間で経験を蓄積することで、従来の静的で孤立したスキルの限界を打破します。SkillsBenchでの実験では、ライフサイクル管理されたスキルがタスクの成功率、実行効率、再利用性、エージェント間の転送性を向上させることができるという予備的な証拠が得られ、スキルを長期ライフサイクルで経験を考慮し、テスト可能な資産として扱うことの重要性が強調されています。
論文と詳細な解釈:https://go.hyper.ai/mdgB2
8. ネモトロン3ウルトラ
論文のタイトル:
Nemotron 3 Ultra:エージェント推論のためのオープンで効率的なエキスパート混合型ハイブリッドMamba-Transformerモデル
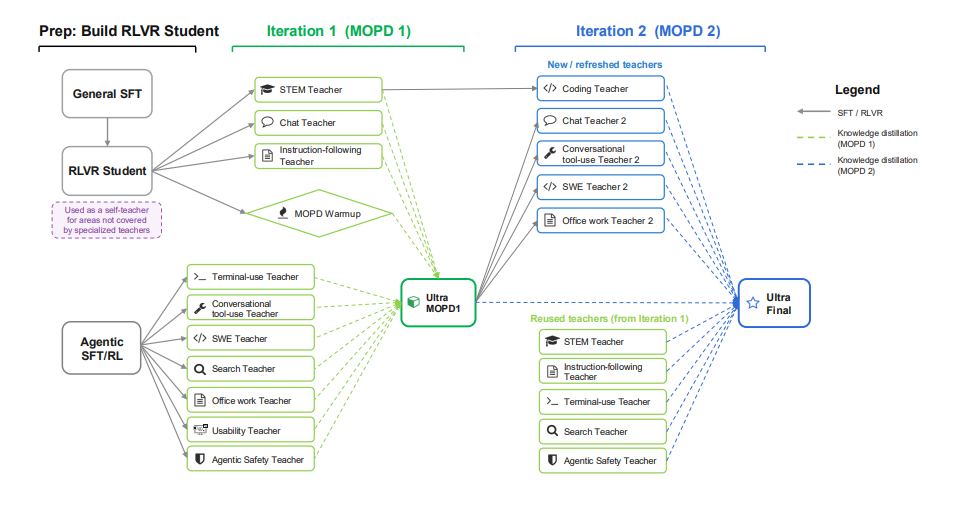
NVIDIAは、5500億個のパラメータと550億個のアクティベーションパラメータを持つMamba-Attention MoE言語モデルであるNemotron 3 Ultraをリリースしました。このモデルは、20兆個のトークンで事前学習され、コンテキスト長は100万トークンに拡張されています。また、SFT、RL、およびマルチティーチャーオンラインポリシー蒸留(MOPD)を使用して事後学習されています。LatentMoE、マルチトークン予測、NVFP4、RLVR、MOPD、推論予算制御などの技術を採用したNemotron 3 Ultraは、高い精度を維持しながら、既存の公開LLMよりも約6倍高い推論スループットを実現しており、長期的な自律エージェントタスクに適しています。
論文と詳細な解釈:https://go.hyper.ai/lm6S1
9. コスモス3
論文のタイトル:
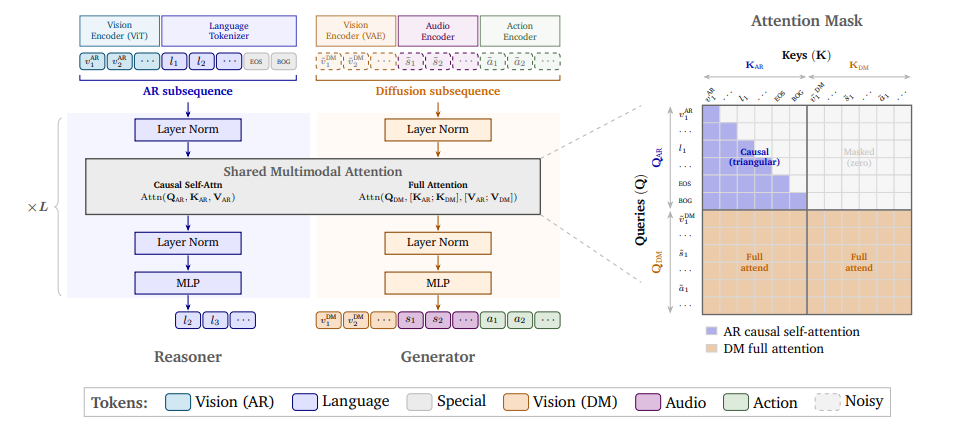
Cosmos 3: 物理AIのためのオムニモーダル世界モデル
NVIDIAは、言語、画像、動画、音声、アクションシーケンスを統合されたハイブリッドTransformerアーキテクチャ内で処理および生成するマルチモーダルワールドモデルスイートであるCosmos 3をリリースしました。Cosmos 3は、視覚言語モデル、動画ジェネレータ、ワールドシミュレータ、アクションモデルを単一のフレームワークに統合することで、非常に柔軟な入出力構成をサポートします。評価では、多様な理解および生成タスクにおいて最先端の結果を達成し、マルチモーダルワールドモデルが具現化されたエージェントの汎用バックボーンネットワークとして有効であることが実証されています。学習済みモデルは、オープンソースのテキストから画像/画像から動画へのモデルおよびポリシーモデルとして最高評価を獲得しました。
論文と詳細な解釈:https://go.hyper.ai/RoY2u
今週の論文推薦は以上です。さらに最先端のAI研究論文をご覧になりたい方は、hyper.ai公式サイトの「最新論文」セクションをご覧ください。
質の高い研究成果や論文の提出を歓迎いたします。ご興味のある方は、NeuroStar WeChat(WeChat ID: Hyperai01)にご登録ください。
また来週お会いしましょう!








