Command Palette
Search for a command to run...
Autodata: An agentic data scientist to create high quality synthetic data
Autodata: An agentic data scientist to create high quality synthetic data
Abstract
We introduce Autodata, a general method that enables AI agents to act as data scientists who build high quality training and evaluation data. We show how to train (meta-optimize) such a data scientist agent, so that it learns to create even stronger data. We describe the overall formulation, and a specific practical implementation, Agentic Self-Instruct. We conduct experiments on computer science research tasks, legal reasoning tasks and reasoning with mathematical objects, where we obtain improved results compared to classical synthetic dataset creation methods. Further, meta-optimizing the data scientist agent itself delivers an even larger performance uplift. Agentic data creation provides a way to convert increased inference compute into higher quality model training. Overall, we believe this direction has the potential to change the way we build AI data.
One-sentence Summary
Meta AI researchers introduce Autodata, an agentic data scientist that meta-optimizes its own data-generation process via Agentic Self-Instruct to produce high-quality synthetic training and evaluation sets, outperforming classical methods on computer science, legal, and mathematical reasoning tasks while converting increased inference compute into stronger model training.
Key Contributions
- The paper introduces Autodata, a general framework where an AI agent acts as a data scientist to automatically construct high-quality training and evaluation datasets.
- A meta-optimization procedure trains the data scientist agent to iteratively improve its data-generation capabilities, with a concrete implementation called Agentic Self-Instruct.
- Experiments on computer science research, legal reasoning, and mathematical reasoning tasks demonstrate that Autodata outperforms classical synthetic data creation methods, and meta-optimizing the agent yields further performance gains.
Introduction
Progress at the AI frontier increasingly depends on high-quality synthetic training data and challenging benchmarks, as human-written data becomes expensive, scarce, or insufficiently difficult. Prior methods like Self-Instruct and its grounded, reasoning-aware, and self-challenging extensions treat data generation as a mostly fixed prompting or filtering pipeline, lacking direct, iterative control over data quality and difficulty. The authors introduce Autodata, a general framework in which an AI agent acts as a data scientist that generates examples, evaluates their learning utility, analyzes failures, and revises its data-creation recipe in a closed loop, and they further show that meta-optimizing this agent itself yields substantial additional performance gains.
Dataset
The authors construct the Principia dataset using an Agentic Self‑Instruct pipeline that generates challenging question–answer pairs. A random sample of 1,000 verified QA pairs is drawn from the full agentic data to characterize the reasoning demands of the questions.
-
Annotation pipeline and taxonomy discovery
- A two‑phase LLM‑based annotation procedure (Kimi‑K2.6) is applied.
- First, 200 items stratified by challenge score are shown to the model in batches of 20; the model proposes 98 raw question‑type categories, which are consolidated into 11 non‑overlapping types.
- Second, all 1,000 sampled items are classified into exactly one of the 11 types. After filtering out parsing failures, 687 items receive valid annotations.
-
Question‑type distribution (Principia subset)
- The annotated sample (referred to as the Principia questions) shows that roughly half are reasoning‑dominant, about a quarter are mixed, and one‑fifth are knowledge‑oriented.
- This distribution confirms that the Agentic Self‑Instruct pipeline emphasizes multi‑step reasoning over simple recall, producing training data that separates weak and strong solvers.
-
Usage in the paper
- The full agentic dataset (of which the annotated sample is a part) is used for model training; the exact training split and mixture ratios are not detailed in this excerpt.
- The annotation serves as a quality analysis, verifying that the generated questions meet the intended reasoning‑heavy profile. No cropping or additional metadata construction beyond the taxonomy labels is described.
Experiment
The paper evaluates an Agentic Self-Instruct loop that iteratively generates training questions by targeting a performance gap between weak and strong solver models, applied across computer science research, legal reasoning, and scientific reasoning tasks. In CS, the loop transforms overly easy questions into harder, discriminative ones that widen the gap; in legal tasks, it reshapes questions that are too hard (near-zero weak scores) into more learnable prompts with higher variance, improving the RL reward signal. Downstream GRPO training on agentic data consistently outperforms standard CoT Self-Instruct data, with a 4B model even surpassing a 397B baseline on legal benchmarks, and the harder scientific problems transfer to easier distributions while boosting token efficiency. Meta-optimizing the data scientist agent’s prompt further lifts validation pass rates by automatically fixing failure modes like generic answers and context leakage, showing that refining the generation strategy itself yields higher-quality synthetic data.
The authors evaluate out-of-distribution performance on a scientific reasoning benchmark using different training data sources. Results show that training on Agentic Self-Instruct data yields the largest overall improvement in average performance, demonstrating that harder problems build more robust reasoning capabilities. However, combining data sources provides advantages in pass-at-k metrics for certain categories, suggesting that increased data diversity helps the model occasionally solve a broader range of problems. Agentic Self-Instruct data achieves the highest overall average score improvement across the benchmark categories. The Agentic method shows consistent gains in specific domains like RealMath and SuperGPQA compared to other training setups. Combined training data leads in pass-at-k metrics for categories such as ARB and RealMath, indicating benefits from larger dataset diversity.
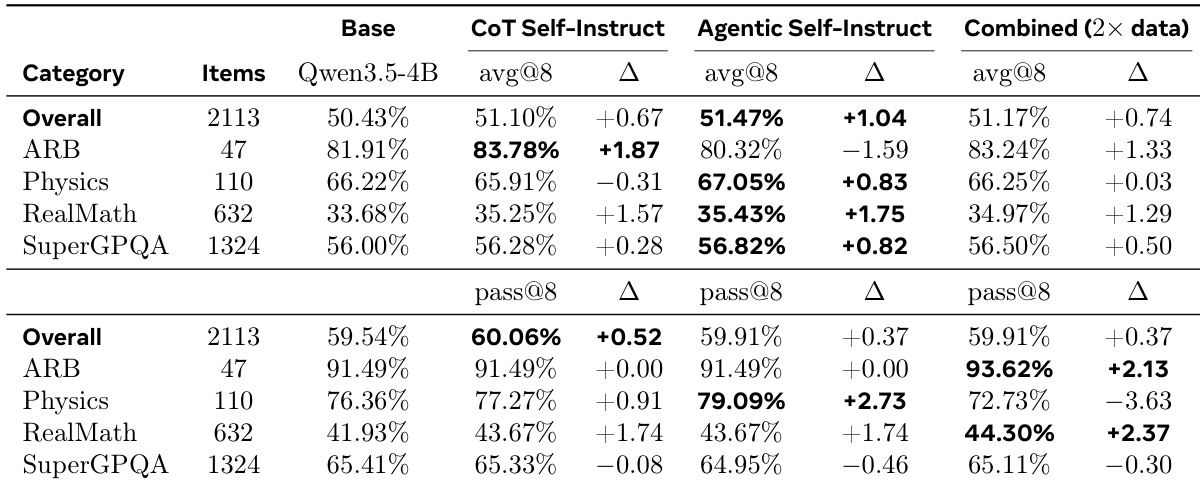
The authors train a small language model using reinforcement learning on data generated by an agentic self-instruct method and compare it to standard chain-of-thought self-instruct data. Results show that training on the agentic data consistently outperforms the standard baseline across both easier and harder held-out test sets. This indicates that the discriminative training data produced by the agentic pipeline translates to stronger reasoning performance and better transfer capabilities. Training on agentic self-instruct data yields higher scores than the standard chain-of-thought baseline on both in-distribution and out-of-distribution test sets. The performance advantage of the agentic method is substantially larger on the harder agentic test set compared to the easier chain-of-thought test set. The agentic-trained model demonstrates strong transferability, improving performance on both the easier and harder evaluation benchmarks.

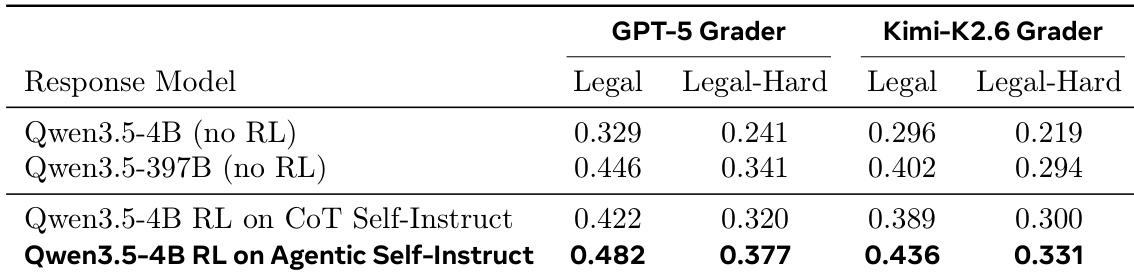
The authors evaluate legal reasoning capabilities by training a smaller language model using reinforcement learning on synthetic data generated through different methods. The results demonstrate that data created via the Agentic Self-Instruct loop enables the smaller model to outperform both a standard CoT baseline and a significantly larger model without reinforcement learning. The Agentic Self-Instruct approach yields the best performance for the smaller model, exceeding the results of standard CoT Self-Instruct training. The smaller model trained on Agentic data surpasses the performance of the much larger baseline model on both standard and hard legal reasoning benchmarks. These performance gains are consistent across different evaluation graders and test set difficulties.
Theauthors apply meta-optimization to iteratively improve the prompts of a data scientist agent responsible for generating computer science research questions. By analyzing failure trajectories and automatically modifying the agent instructions, the system substantially increases the validation pass rate, which measures the ability to generate questions that effectively separate weak and strong solvers. The meta-optimization process successfully identifies and fixes systematic failure modes such as generic answers and context leakage. The validation pass rate shows a clear upward trend from the baseline configuration to the final iteration, demonstrating the effectiveness of automated prompt evolution.

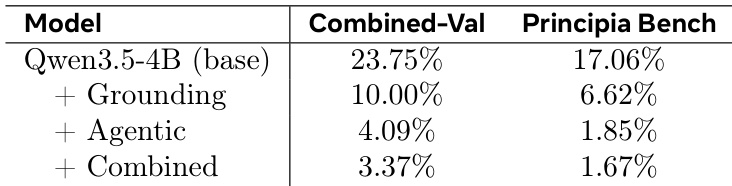
The authors analyze truncation rates across different training configurations to evaluate token efficiency under a fixed token budget. Results show that the base model exhibits high truncation rates, indicating that responses often exceed the budget before completing reasoning. Training substantially reduces these truncation rates, with the Agentic and Combined methods achieving the lowest rates, suggesting that training teaches the model to reason more concisely and efficiently. The base model has the highest truncation rates across both evaluation sets, while all training configurations significantly reduce these rates. The Agentic Self-Instruct method dramatically lowers truncation compared to the base model, demonstrating improved token efficiency. The Combined training configuration achieves the lowest truncation rates overall, indicating the most concise reasoning patterns.
The experiments train small language models with reinforcement learning on synthetic data from an agentic self-instruct pipeline, comparing against standard chain-of-thought self-instruct and combined data sources across scientific reasoning, legal reasoning, and token efficiency benchmarks. Agentic data consistently yields stronger out-of-distribution performance, particularly on harder problems, and teaches the model to reason more concisely, while mixing data sources occasionally improves pass-at-k diversity. A separate meta-optimization loop automatically refines the prompts of a data scientist agent, systematically fixing failure modes and raising the rate of generating discriminative research questions. Overall, agentic self-instruct builds more robust and transferable reasoning, and iterative prompt evolution further enhances data quality.