Command Palette
Search for a command to run...
DeepSeek Engram にヒントを得たゲノム基本モデルの「外部脳」である Gengram は、最大 22.61 TP3T のパフォーマンス向上を達成しました。

基本ゲノムモデル(GFM)は、生命のコードを解読し、DNA配列を解析することで細胞機能や生物の発達といった重要な生物学的情報を解明するための中核ツールです。しかし、既存のTransformerベースのGFMには致命的な欠陥があります。大規模な事前学習と集中的な計算によってポリヌクレオチドモチーフを間接的に推論する必要があるためです。これは非効率的であるだけでなく、モチーフ駆動型の機能要素検出タスクには限界があります。
最近、BGI生命科学研究所と浙江智江研究所のメンバーで構成されるジェノスチームによって提案されたジェングラム(ゲノムエングラム)モデルは、これはこの問題に対する革新的な解決策を提供します。この設計により、生物学的ルールのハードコーディングを回避しながら、モデルにゲノムの「文法」を明示的に理解させることができます。
ゲノムモチーフモデリング専用に設計された軽量な条件付きメモリモジュールであるGengramの核となる革新性は、高効率なマルチベースモチーフメモリリポジトリを構築するk-merハッシュメモリ機構にあります。モチーフを間接的に推論する従来のモデルとは異なり、1〜6 塩基長の k-mer とその埋め込みベクトルを直接保存し、ローカル ウィンドウ集約メカニズムを通じて機能モチーフのローカル コンテキスト依存性をキャプチャします。モチーフ情報は、ゲート制御モジュールを介してバックボーンネットワークと融合されます。研究チームによると、Gengramを現在の最先端(SOTA)ゲノムモデルGenosに統合し、同じ学習条件下で使用した場合、複数の機能ゲノミクスタスクにおいて大幅なパフォーマンス向上が達成され、最大で22.6%の向上が見られました。

用紙のアドレス:https://arxiv.org/abs/2601.22203
コードアドレス:https://github.com/BGI-HangzhouAI/Gengram
モデルの重み:https://huggingface.co/BGI-HangzhouAI/ゲングラム
トレーニング データは、ヒトおよび非ヒト霊長類のゲノムをカバーします。
トレーニング データセットには、ヒトおよび非ヒト霊長類のゲノムをカバーする、ハプロタイプ解析およびアセンブルされた 145 個の高品質配列が含まれています。ヒト配列は主にヒトパンゲノムリファレンスコンソーシアム(HPRC、第2版)から取得し、GRCh38およびCHM13リファレンスゲノムを補足しました。ヒト以外の霊長類の配列は、進化的多様性を組み込むため、NCBI RefSeqデータベースから統合しました。すべての配列はワンホットエンコーディングを用いて処理しました。語彙には、4つの標準塩基(A、T、C、G)、曖昧ヌクレオチド(N)、およびドキュメントエンドマーカーが含まれています。
ファイナル、システムは、アブレーション実験と正式な事前トレーニングをサポートするために 3 セットのデータを構築しました。
500億トークン @ 8,192 (アブレーション)
200Bトークン@8k(10B正式な事前トレーニング)
100Bトークン @ 32K(10Bの正式な事前トレーニング)
そして、人間:非人間のデータ混合比率を 1:1 に維持します。
ゲノムモデリングは「注意の導出」から「記憶の強化」へと移行しています。
DeepSeek Engram のメモリ メカニズムにヒントを得て、Genos チームは Gengram を迅速に開発し、展開しました。このモジュールは、基本的なゲノムモデルに明示的なモチーフ保存と再利用機能を提供します。これにより、構造化されたモチーフメモリを欠き、トレーニングデータの「暗黙的メモリ」の拡張にしか依存できない主流のゲノムモデルモデリングの限界を克服します。これにより、ゲノムモデリングは「注意導出」から「メモリ拡張」へと進化します。モジュールのアーキテクチャを下図に示します。
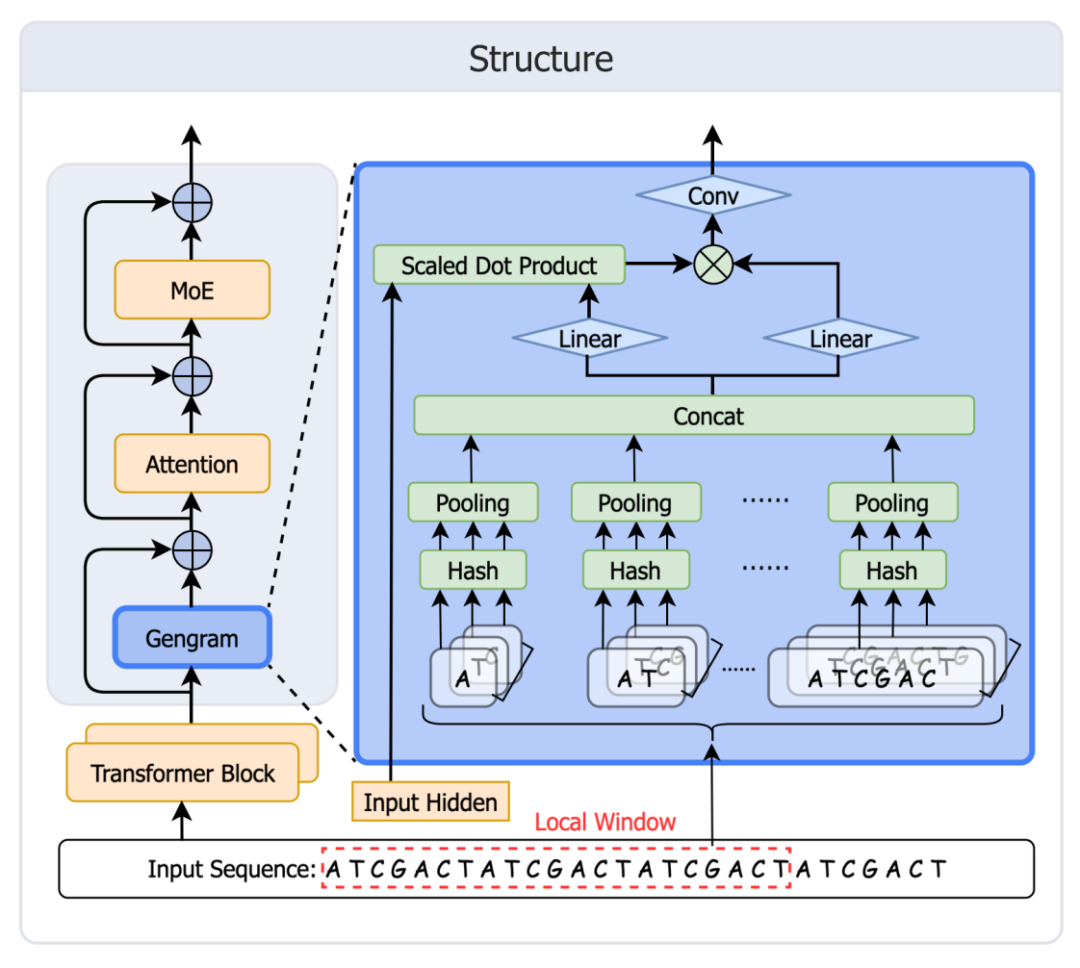
テーブル作成:k=1から6までのすべてのk-mer値に対してハッシュメモリ(静的キー+学習可能な埋め込み値)を構築します。
取得: ウィンドウに表示されるすべての k-mer 値をテーブル エントリにマッピングします。
集約: 最初に各 k で集約し、次に k 全体を連結します。
ゲーティング: ゲートはアクティベーションを制御し、モチーフの証拠を残余ストリームに書き込み、注意を喚起します。
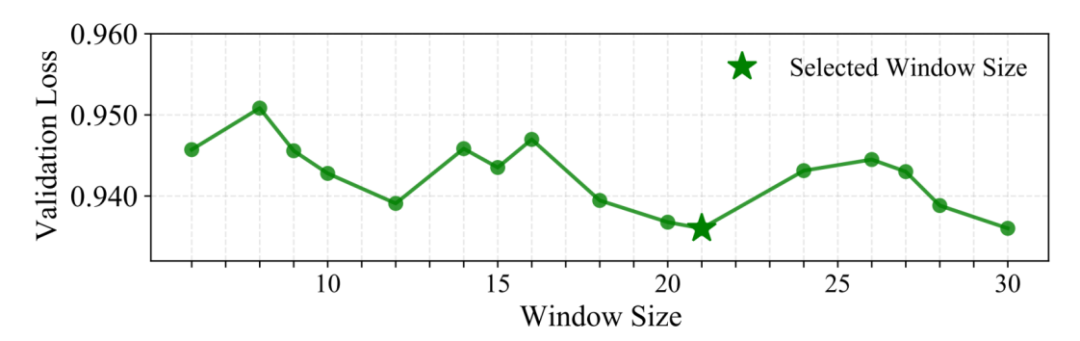
重要な設計特徴: ローカルウィンドウ集約 (W=21bp)
Gengramは、各位置で単一のn-gramを取得する代わりに、固定ウィンドウ内で複数のk-mer埋め込みを集約することで、「局所的かつ構造的に一貫性のある」モチーフ証拠をより確実に挿入します。研究者たちは、ウィンドウサイズ戦略を用いた検索によってこれを検証しました。検証セットでは 21 bp が最適なパフォーマンスを実現することがわかりました。生物学的な説明の一つとして、典型的なDNA二重らせん周期は1回転あたり約10.5塩基対であるため、21塩基対がちょうど2回転する、という可能性が考えられます。これは、21塩基対離れた2つの塩基が3次元空間においてらせんの同じ側に位置し、同様の生化学的環境に面していることを意味します。このスケールでのウィンドウイングは、局所的な配列シグナルの位相整合に、より効果的である可能性があります。
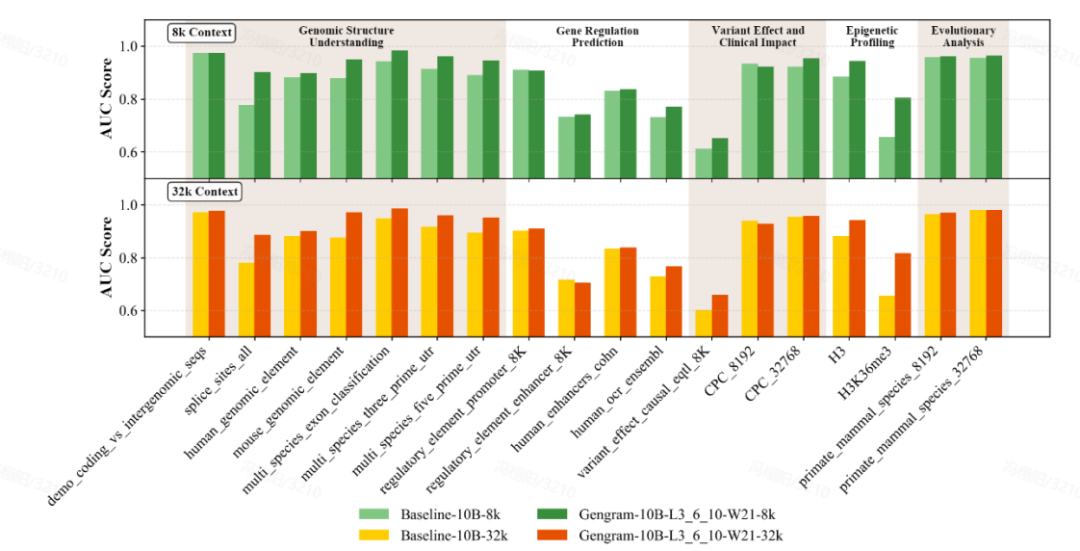
評価の大幅な改善:小さなパラメータ、大きな変化
チームは、ゲノムベンチマーク (GB)、ヌクレオチドトランスフォーマーベンチマーク (NTB)、ロングレンジベンチマーク (LRB)、ジェノスベンチマーク (GeB) を網羅するマルチスタンダードベンチマークデータセットを使用して、モデルの包括的な評価を実施しました。5 つの主要なタスク カテゴリをカバーする 18 の代表的なデータセットが選択されました。ゲノム構造の理解、遺伝子調節の予測、エピジェネティックプロファイリング、変異体の影響と臨床的影響、進化分析。
Gengramは、わずか約2,000万個のパラメータを持つ軽量プラグインです。数千億個のパラメータを持つベースモデルのごく一部を占めるに過ぎませんが、それでも大幅なパフォーマンス向上を実現します。同じ学習条件で、コンテキスト長を8kと32kとした場合…Gengram と統合されたモデルは、ほとんどのタスクにおいて統合されていないバージョンよりも優れたパフォーマンスを発揮しました。具体的な症状としてはスプライス サイト予測タスクの AUC スコアは 0.776 から 0.901 に改善され、TP3T は 16.11 増加しました。エピジェネティック予測タスク (H3K36me3) の AUC スコアは 0.656 から 0.804 に改善され、TP3T が 22.61 増加しました。
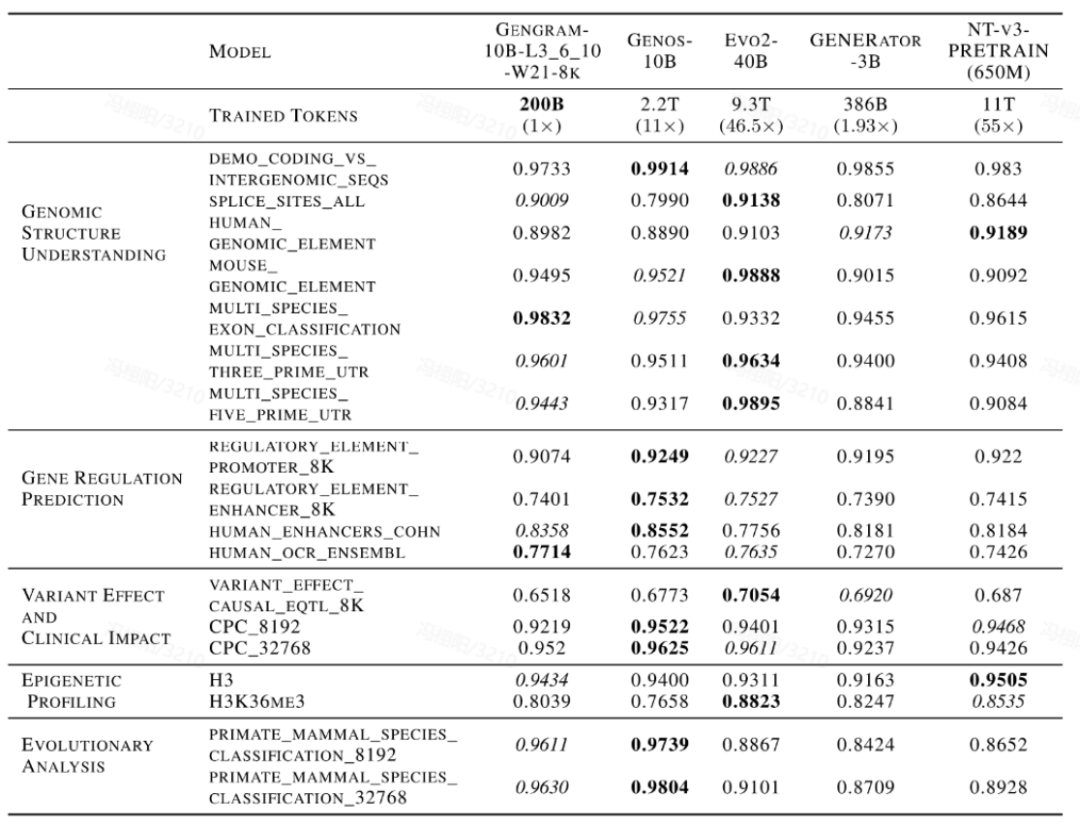
さらに、このパフォーマンス向上は、顕著な「データレバレッジ」効果を伴います。Evo2、NTv3、GENERATOR-3Bといった主流のDNAベースモデルとの横並び比較では、Gengrams を統合したモデルは、コアタスクで数倍から数十倍のトレーニングデータを持つ公開モデルに匹敵するために、ごく少量のトレーニングデータとより少ないアクティベーションパラメータのみを必要とします。高いデータトレーニング効率を実証します。
ジェングラムの詳細な分析
Gengram がトレーニングを加速できるのはなぜですか?
研究チームは、学習プロセスの表現診断指標としてKLダイバージェンスを導入し、LogitLens-KLを用いて各層の「予測準備度」を定量化し追跡しました。その結果、…Gengramsを導入することで、モデルは浅い層でより早い段階で安定した予測分布を形成できます。ベースラインモデルと比較して、層間 KL 値はより速く減少し、より早く低値範囲に入ります。これは、有効な監督信号が使用可能な表現に早く編成され、勾配の更新がより直接的になり、最適化パスがよりスムーズになり、最終的に収束速度が速くなり、トレーニング効率が高くなることを示しています。
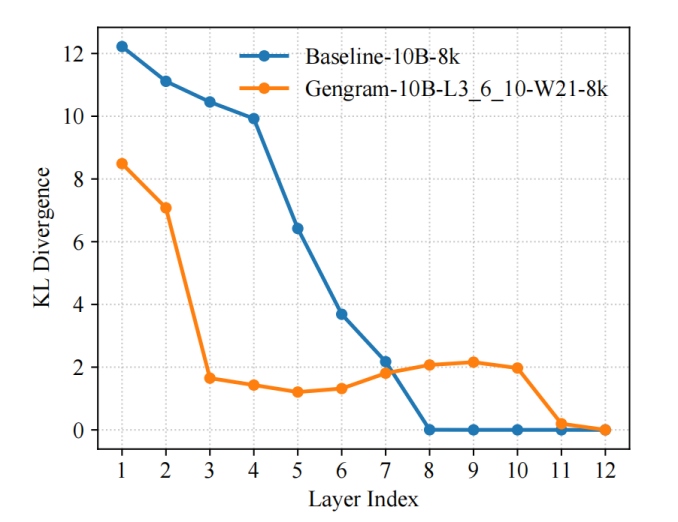
この現象は突然起こったわけではなく、ジェングラムの構造設計によって直接引き起こされたものです。
明示的なモチーフメモリ検索は、証拠から表現への経路を短縮します。ゲノムタスクでは、短くまばらなモチーフ(スプライスされたコンセンサス配列、プロモーター関連断片、低複雑性領域など)によって監視信号がトリガーされることがよくあります。Baseline Transformerは、これらの局所的な証拠を多層のAttention/MLPを通して徐々に「導出し、強化」する必要があります。一方、Gengramは、k-merへの明示的なアクセスを通じて、これらの高情報密度の局所パターンをメモリの形でネットワークに直接提供します。これにより、モデルは深層がモチーフ検出器を徐々に形成するのを待つ必要がなくなり、最初から予測可能な状態に近づきます。
ウィンドウ集約と動的ゲーティングにより、注入された証拠は「安定的かつ制御可能」になります。 ジェングラムは位置ごとのハードインジェクションを実行しません。代わりに、固定ウィンドウ内で複数の k-mer 埋め込みを集約します。さらに、残差ストリームへのゲート制御された選択的書き込みが採用されています。これにより、機能領域では想起が活性化されやすく、大きな背景領域では想起が抑制されます。この「疎で整列した機能要素」書き込み手法は、一方でノイズ干渉を低減し、ネットワークがより高い信号対雑音比のトレーニング信号をより早く取得できるようにすることで、最適化の難易度を低減します。
モチーフ記憶はどこから来るのか? ジェングラムの筆記メカニズムを詳しく解説。
研究チームはまず、下流の評価におけるタスク全体にわたって明確かつ一貫した現象を観察しました。同じトレーニング設定において、Gengramsの導入により、典型的なモチーフ駆動型タスク、特にスプライス部位同定やエピジェネティックヒストン修飾部位予測といった短いプログラム配列に依存するシナリオにおいて、モデルの性能が大幅に向上しました。例えば、代表的なタスクにおいて、スプライス部位予測のAUCは0.776から0.901に、H3K36me3予測のAUCは0.656から0.804に向上し、安定的かつ大幅な向上を示しました。
「これらの改善はどこから来るのか?」という質問にさらに答えるために、チームはメトリック レベルで止まらず、モデルの順方向伝播から Gengram の残余書き込みを抽出し、分析用のヒートマップとしてシーケンス次元での強度分布を視覚化しました。結果は、書き込まれた信号が非常にまばらでコントラストの高い構造を示していることを示しています。ほとんどの場所はベースラインに近く、いくつかの場所だけが鋭いピークを形成しています。さらに重要なのは、これらのピークはランダムではなく、プロモーター付近の TATA ボックス断片、複雑性の低いポリ T 断片、遺伝子/エクソンなどの機能領域の境界付近の重要な場所など、機能的に関連する領域と境界に大幅に濃縮され、整列していることです。つまり、ジェングラムへの書き込みは、シーケンス全体にわたって無差別に情報を注入するのではなく、「その決定的な機能のローカルな証拠を把握する」ことに似ています。
上記の現象と一連の証拠に基づいて、研究者は、ジェングラムのモチーフ記憶のメカニズムを「オンデマンド検索 - 選択的書き込み - 構造化されたアライメント」と要約することができます。このモジュールは、ゲーティングによって検索と書き込みの強度を制御し、機能情報密度の高い領域には再利用可能なモチーフ証拠をより積極的に注入し、背景領域への書き込みを抑制することでノイズ干渉を低減します。その結果、モデルによるモチーフの習得は、大規模データによってもたらされる「暗黙記憶」に主に依存するのではなく、表現に明示的にアクセスし、解釈可能に書き込む構造化された能力へと移行します。

結論
近年、ゲノムモデリングの分野では、「配列統計学習」から「構造認識モデリング」への重要な転換が起こっています。
Gengram に代表される条件付きモチーフ メモリ メカニズムは、従来の集中コンピューティングとは異なる技術的な道筋を示しています。つまり、マルチベースの機能モチーフを検索可能な構造化メモリとして明示的にモデル化することにより、モデルは一般的なアーキテクチャの互換性を維持しながら、機能情報のより効率的で安定した利用を実現できます。このアプローチは、複数の機能ゲノミクスタスクで大幅なパフォーマンス上の利点を示しただけでなく、スパース計算、長いシーケンスモデリング、およびモデルの解釈可能性のための統合されたエンジニアリングソリューションも提供しました。
さらに、産業界の観点から見ると、Gengramが体現する「構造化事前確率+モジュール型拡張」パラダイムは、大規模ゲノムモデルの計算能力、データ、学習サイクルといった限界費用を大幅に削減し、医薬品開発、バリアントスクリーニング、遺伝子制御解析といった高価値シナリオへの大規模導入を実用的に実現可能にします。さらに将来的には、これらの再利用可能かつプラグイン可能なアーキテクチャコンポーネントが次世代ゲノム基盤モデルの標準構成となり、産業界を「大規模モデル」から「よりスマートなモデル」へと導き、学術研究成果を産業プラットフォームや臨床応用へと継続的に転換していくことを加速させる可能性があります。








