Command Palette
Search for a command to run...
GPT-5 が全面的にリード。OpenAI は「推論 + 研究」の二重のアプローチを使用して大規模モデルの機能をテストする FrontierScience をリリース。
モデルの推論機能と知識機能が継続的に向上するにつれて、科学研究を加速させるモデルの能力を測定および予測するために、より困難なベンチマーク テストが重要になります。 2025 年 12 月 16 日、OpenAI は専門家レベルの科学的能力を測定するために設計されたベンチマークである FrontierScience を立ち上げました。予備評価によると、GPT-5.2はFrontierScience-OlympiadタスクとResearchタスクでそれぞれ25%と77%のスコアを獲得し、他の最先端モデルを上回りました。
OpenAIは公式声明で、「科学の進歩を加速させることは、人工知能が人類に利益をもたらす最も有望な機会の一つです。そのため、私たちは複雑な数学的・科学的タスクのためのモデルを改良し、科学者がこれらのモデルを最大限に活用できるツールの開発に取り組んでいます」と述べた。
これまでの科学ベンチマークは、多肢選択式問題が中心で、問題形式が過度に複雑であったり、科学的な視点が欠けていたりすることがほとんどでした。対照的に、FrontierScienceは、これまでのベンチマークとは異なり、物理学、化学、生物学の専門家によって作成・検証されています。オリンピック形式と研究ベースの両方の質問タイプが含まれており、科学的推論と科学的研究能力の両方を測定できます。さらに、FrontierScience-Research には、博士号取得科学者が設計した 60 個の独自の研究サブタスクが含まれており、その難易度は博士号取得科学者が研究中に遭遇する可能性のある難易度に匹敵します。
ベンチマークの将来と限界について、OpenAIは公式レポートで次のように述べています。「FrontierScienceは対象範囲が狭く、科学者の日常業務のあらゆる側面を網羅することはできません。しかし、この分野にはより挑戦的で、より独創的で、より意義深い科学的ベンチマークが必要であり、FrontierScienceはその方向への一歩です。」
このプロジェクトの研究結果は、「FrontierScience: 専門家レベルの科学的タスクを実行する AI の能力の評価」というタイトルで公開されています。
用紙のアドレス:
https://hyper.ai/papers/7a783933efcc
その他の論文:
その他のベンチマークを表示:

FrontierScience データセットは、「推論 + 研究」の二重アプローチを可能にします。
このプロジェクトでは、研究チームは、専門家レベルの科学的推論と研究サブタスクにおける大規模モデルの機能を体系的に評価するために、FrontierScience 評価データセットを構築しました。このデータセットは、「専門家の作成 + 2 レベルのタスク構造 + 自動採点メカニズム」という設計メカニズムを採用し、挑戦的でスケーラブルかつ再現可能な科学的推論評価ベンチマークを形成します。
データセットアドレス:
https://hyper.ai/datasets/47732
さまざまなタスク形式と評価目標に基づいて、FrontierScience データセットは、クローズドエンド型の正確な推論とオープンエンド型の科学的推論という 2 種類の能力に対応する 2 つのサブセットに分割されます。
* オリンピックデータセット: 国際物理、化学、生物オリンピックのメダリストやナショナルチームのコーチによって設計されたデータセットで、IPhO、IChO、IBO などのトップクラスの国際大会に匹敵する問題の難易度を備えています。短答式の推論タスクに重点を置いており、結果の検証可能性と自動評価の安定性を確保するために、モデルが単一の数値、代数式、またはあいまい一致が可能な生物学用語を出力することを要求します。
* 研究データセット:博士課程の学生、ポスドク研究員、教授、その他の現役研究者によって構築されたこれらの問題は、物理学、化学、生物学の3つの主要分野を網羅し、実際の科学研究で遭遇する可能性のあるサブ問題をシミュレートしています。各問題には10点満点のきめ細かいスコアが付与され、回答の正確性だけでなく、モデリングの前提、推論パス、中間結論の完成度など、いくつかの重要な側面におけるモデルのパフォーマンスを評価します。
質問の独創性と厳密性を確保するため、研究チームは内部モデルテスト段階で質問を精査し、既存のモデルで容易に解ける質問は除外することで評価の飽和リスクを軽減しました。トレーニングタスクは、作成、レビュー、解決、修正という合計4つのフェーズを経ます。独立した専門家が互いのタスクをレビューし、基準を満たしていることを確認します。最終的に、チームは数百の候補質問の中から 160 のオープンソース質問を選択し、残りの質問はその後の汚染検出と長期評価のための予備として保管しました。
独立したサブセット サンプリングと GPT-5.2 などの他のモデルは、印象的なスコアを達成しました。
外部検索に頼らずに大規模モデルの科学的推論能力を安定的かつ再現性のある形で評価するために、研究チームは厳密な評価プロセスとスコアリングのメカニズムを設計しました。
本研究では、科学的推論分野における現在の汎用大規模モデルの総合的な能力レベルを可能な限り反映するために、異なる制度や技術的アプローチを網羅するいくつかの主流の最先端大規模モデルを評価対象として選択した。評価プロセス中は、すべてのモデルがインターネットから無効化され、出力が内部の知識と推論能力のみに基づいており、リアルタイムの情報検索や外部ツールの影響を受けないことが保証されました。これにより、異なるモデル間の情報取得能力の違いが結果に及ぼす影響を軽減します。
研究チームは、生成応答における大規模モデルの固有のランダム性を考慮して、ランダムな変動を避けるために、複数の独立したサンプルを取り出し、2 つのサブセット (オリンピアードとリサーチ) の結果を平均化することで統計分析を実施しました。採点方法に関しては、この論文では、2 種類のタスクの異なる特性を考慮して、自動評価戦略を設計しています。
* FrontierScience-Olympiad サブセット: クローズドエンド型の推論を重視し、採点は主に回答の同等性の判断に基づいて行われ、妥当な誤差範囲内での数値近似、代数式の同等の変換、生物学の質問における用語または名前のあいまい一致が許可されますが、表現形式に対する過敏さは避けられます。
* FrontierScience-Researchサブセット:現実世界の研究サブタスクに非常に近いもので、各設問は研究推論プロセスを複数の独立した検証可能な主要ステップに分解します。モデルの解答は、最終的な結論の正確さのみではなく、ルーブリックに基づいて項目ごとに採点されます。
全体的に、FrontierScience ベンチマークは、2 種類のタスクでパフォーマンスの差が明確に表れていることを示しています。
オリンピックのサブセットでは、ほとんどの最先端モデルが高得点を獲得しました。その中でも、総合スコアが最も高かった上位 3 つのモデルは GPT-5.2、Gemini 3 Pro、Claude Opus 4.5 で、GPT-4o と OpenAI-o1 のパフォーマンスは比較的低かった。研究によると、条件が明確で、推論パスが比較的閉じており、答えが検証可能なこの種の問題では、ほとんどのモデルが複雑な計算と論理的推論を安定して完了することができ、全体的なパフォーマンスは高度な人間の問題解決者のパフォーマンスに近いことが示されています。
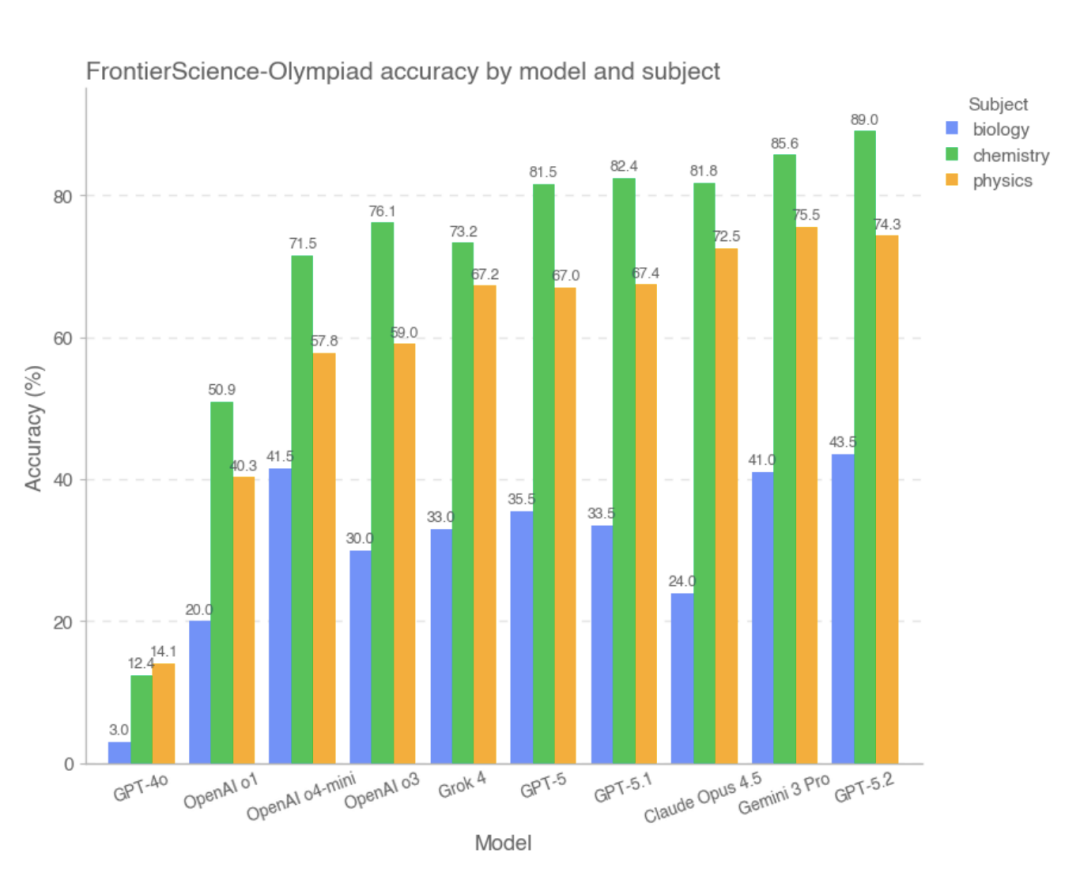
ただし、FrontierScience-Research サブセットでは、モデルの全体的なスコアが大幅に低下しました。。研究サブセットでは、複雑な研究問題の分解中にモデルにバイアスが生じやすくなります。例えば、問題の目的の理解が不完全であったり、主要な変数や仮定が適切に扱われていなかったり、長い推論の連鎖の中で論理的な誤りが徐々に蓄積されていく可能性があります。オリンピック形式の問題と比較すると、大規模モデルは、よりオープンエンドで現実世界の研究プロセスに近い課題に直面した場合、依然として大きな能力のギャップを示しています。実験データに基づくと、研究セクションで優れたパフォーマンスを示したモデルは、GPT-5、GPT-5.2、GPT-5.1 でした。
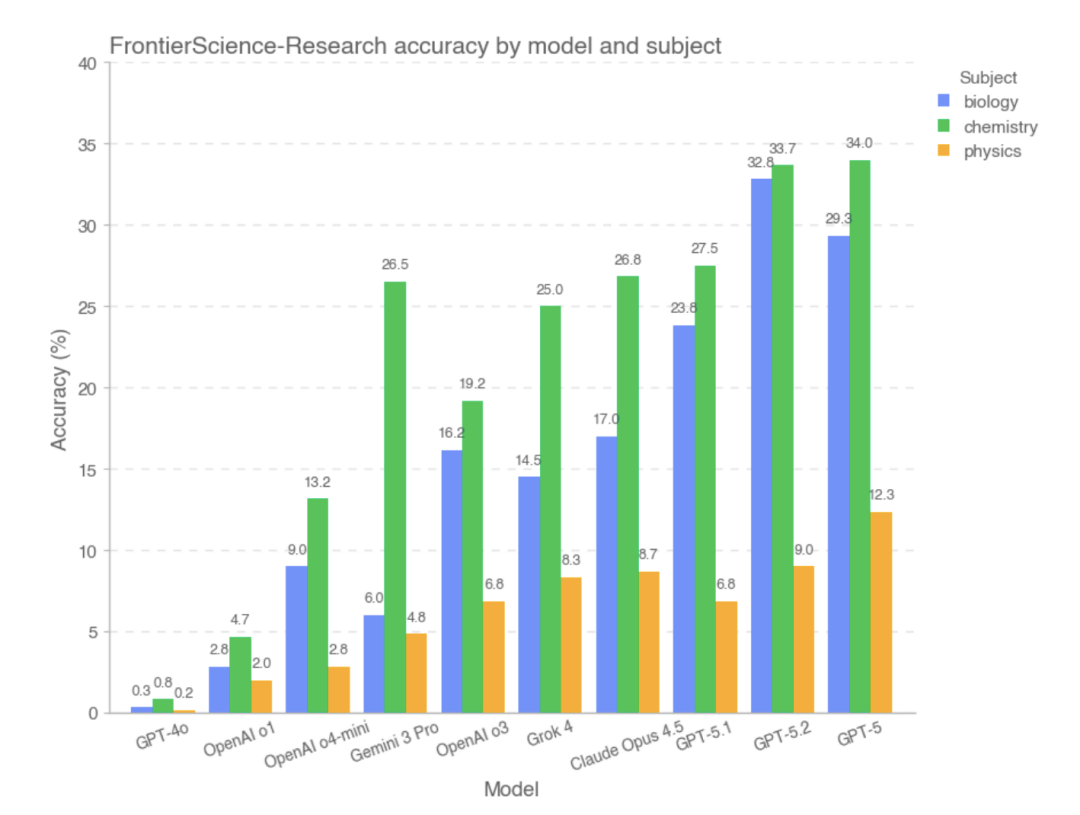
本研究では、FrontierScience-OlympiadとFrontierScience-Researchのテストセットにおいて、異なる推論強度におけるGPT-5.2とOpenAI-o3の精度パフォーマンスを比較しました。結果は…テストで使用されるトークンの数が増えるにつれて、GPT-5.2 の精度は、オリンピック データセットでは 67.51 TP3T から 77.11 TP3T に、研究データセットでは 181 TP3T から 251 TP3T に向上しました。注目すべきは、研究データセットでは、o3 モデルは実際には中程度の推論強度よりも高い推論強度でのパフォーマンスがわずかに低下しているということです。
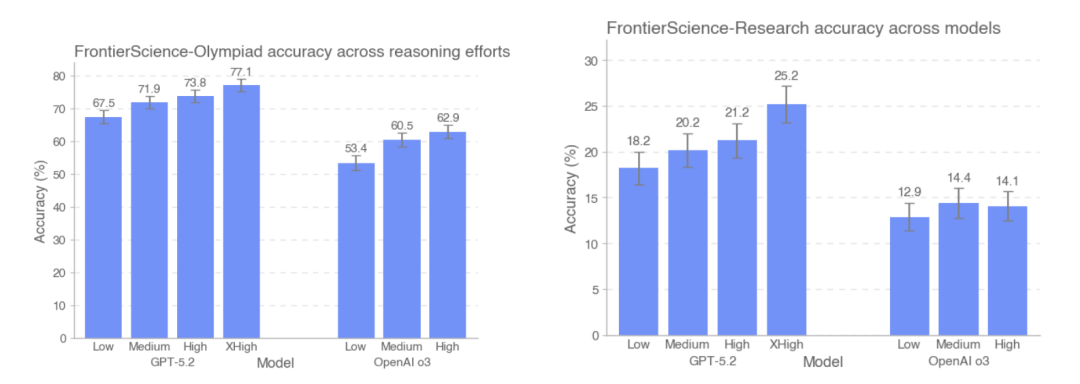
FrontierScienceの全体的な設計と実験結果に基づいて、この大規模モデルは、明確な構造と閉じた条件を持つ科学的問題において安定したパフォーマンスを発揮することができ、いくつかのタスクにおけるパフォーマンスは人間の専門家のレベルに近づいています。しかし、継続的なモデリング、問題の分解、長鎖推論における一貫性の維持を必要とする研究サブタスクに入ると、その機能は大幅に制限されたままになります。
答えの正確さを超えて、大規模モデルは新たな機能基準をもたらします。
OpenAIは公式説明の中で、FrontierScienceが科学者の日常業務のあらゆる側面を網羅しているわけではないことを明確に指摘しています。FrontierScienceのタスクは依然として主にテキストベースの推論であり、実験操作、マルチモーダル情報、あるいは現実世界の研究協力プロセスには未だ関与していません。しかしながら、既存の科学的評価方法が一般的に飽和状態にあることを踏まえ、FrontierScienceはより挑戦的で診断的に価値のある評価パスを提供します。それは、モデルの回答の正確性に焦点を当てるだけでなく、モデルが研究サブタスクを完了する能力を備えているかどうかを体系的に測定し始めることです。この観点から、FrontierScienceの価値は、リーダーボード自体だけでなく、その後のモデル改良と科学的知能研究のための新たなベンチマークを提供することにもかかっています。モデルの推論能力が進化し続けるにつれ、独創性、専門家の参加、プロセス評価を重視するこの種のベンチマークは、人工知能が真に研究協力の段階へと進んでいるかどうかを判断するための重要な窓口となる可能性があります。
参考リンク:
1.https://cdn.openai.com/pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/frontierscience-paper.pdf
2.https://openai.com/index/frontierscience/
3.https://huggingface.co/datasets/openai/frontierscience








