Command Palette
Search for a command to run...
AI ペーパー ウィークリー レポート | 構造的スパース性、メモリ メカニズム、推論組織における最新の進歩を分析した、最先端の Transformer 研究に関する特別レポート。

過去8年間で、Transformerは人工知能研究のあり方をほぼ一変させました。Googleが2017年に「Attention Is All You Need」でこのアーキテクチャを提案して以来、「Attentionメカニズム」はエンジニアリング技術からディープラーニングの汎用パラダイムへと徐々に進化してきました。自然言語処理からコンピュータービジョン、音声・マルチモーダルコンピューティングから科学計算に至るまで、Transformerは事実上の基礎モデルフレームワークとなりつつあります。
Google、OpenAI、Meta、Microsoftといった業界関係者は、スケールとエンジニアリングの限界を絶えず押し広げています。一方、スタンフォード大学、MIT、バークレー大学といった大学は、理論分析、構造改善、そして新たなパラダイムの探求において、着実に重要な成果を生み出しています。モデル規模、学習パラダイム、そして応用範囲の拡大が続く中、Transformer分野の研究もまた、高度な分化と急速な進化の傾向を示しており、体系的なレビューと代表的な論文の選定が特に重要になっています。
学術界における人工知能分野の最新動向をより多くのユーザーに知ってもらうため、HyperAI の公式サイト (hyper.ai) に「最新論文」セクションが開設され、最先端の AI 研究論文が毎日更新されます。
* 最新のAI論文:https://go.hyper.ai/hzChC今週は、Transformers に関する人気の論文 5 つを厳選しました。北京大学、DeepSeek、ByteDance Seed、Meta AIなどのチームが参加しています。一緒に学びましょう!⬇️
今週のおすすめ紙
- スケーラブルな検索による条件付きメモリ:大規模言語モデルのための新たなスパース性軸
北京大学とDeepSeek-AIの研究者らは、O(1)の探索複雑度を持つスケーラブルな条件付きメモリモジュール「Engram」を提案しました。静的知識検索Transformerの初期層からEngramを抽出し、MoEで補完することで、初期層をより深い推論計算に活用できるようになります。パラメータ数とFLOP数はそのままに、推論タスク(BBH +5.0、ARC-Challenge +3.7)、コードおよび数学タスク(HumanEval +3.0、MATH +2.4)、ロングコンテキストタスク(Multi-Query NIAH:84.2 → 97.0)において大幅な性能向上が達成されました。
論文と詳細な解釈:https://go.hyper.ai/SlcId
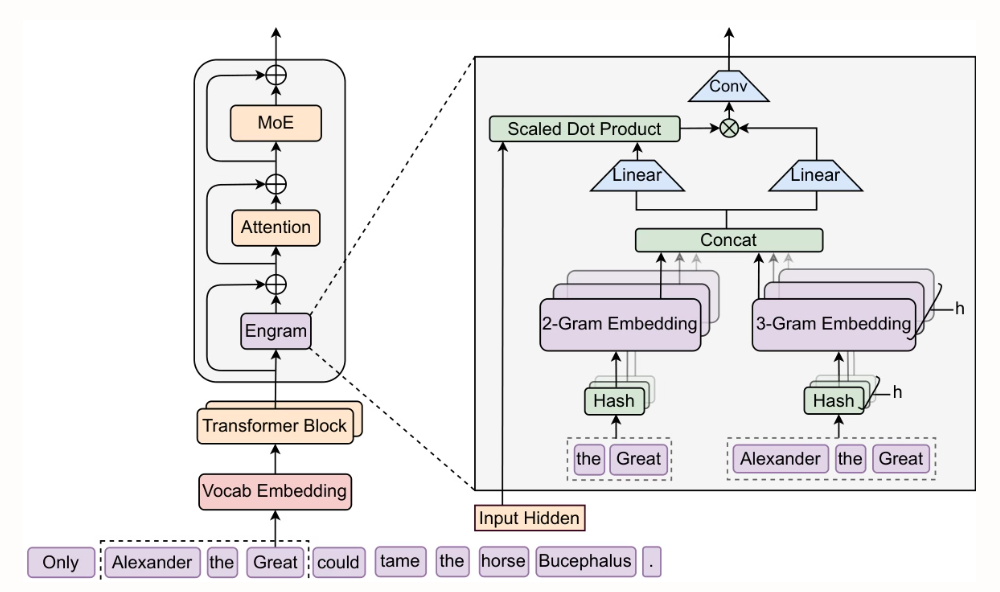
2. STEM: 埋め込みモジュールによるトランスフォーマーのスケーリング
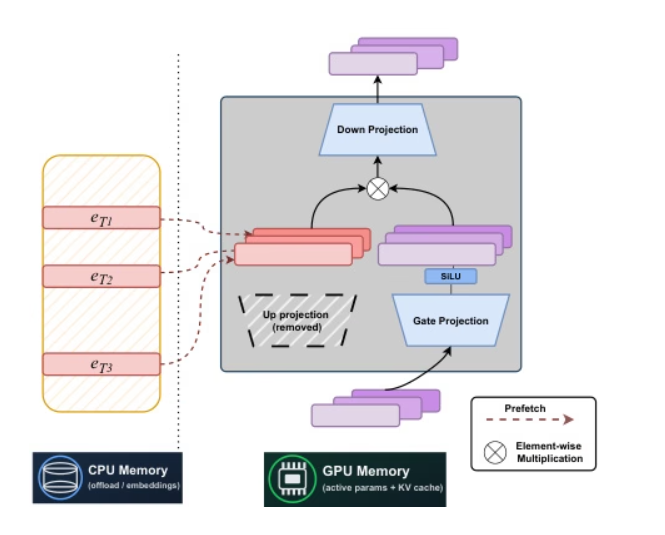
カーネギーメロン大学とMeta AIの研究者は、静的なラベルインデックスベースのスパースアーキテクチャであるSTEMを共同で提案しました。FFNのアッププロジェクションを層内埋め込み検索に置き換えることで、安定した学習が実現され、ラベルごとのFLOPとパラメータアクセスが約3分の1削減されます。また、スケーラブルなパラメータアクティベーションによってロングコンテキスト性能が向上します。STEMは、計算能力と通信能力を切り離すことで、CPUオフロードのための非同期プリフェッチをサポートし、大きな角度分布を持つ埋め込みを活用してより高い知識ストレージ容量を実現し、入力テキストを変更することなく解釈可能かつ編集可能な知識注入を可能にします。知識および推論ベンチマークでは、密なベースラインと比較して最大約3~41 TP3Tの性能向上を達成しています。
論文と詳細な解釈:https://go.hyper.ai/NPuoj
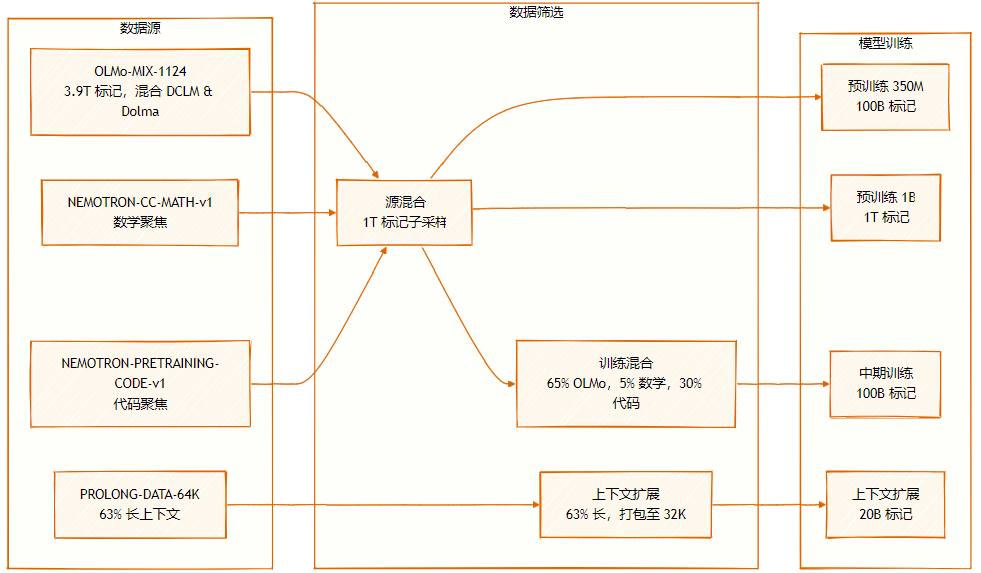
データセットは、OLMo-MIX-1124 (3.9T ラベル付き)、DCLM と Dolma1.7 の混合、NEMOTRON-CC-MATH-v1 (数学指向)、および NEMOTRON-PRETRAINING-CODE-v1 (コード指向) という複数のソースで構成されています。
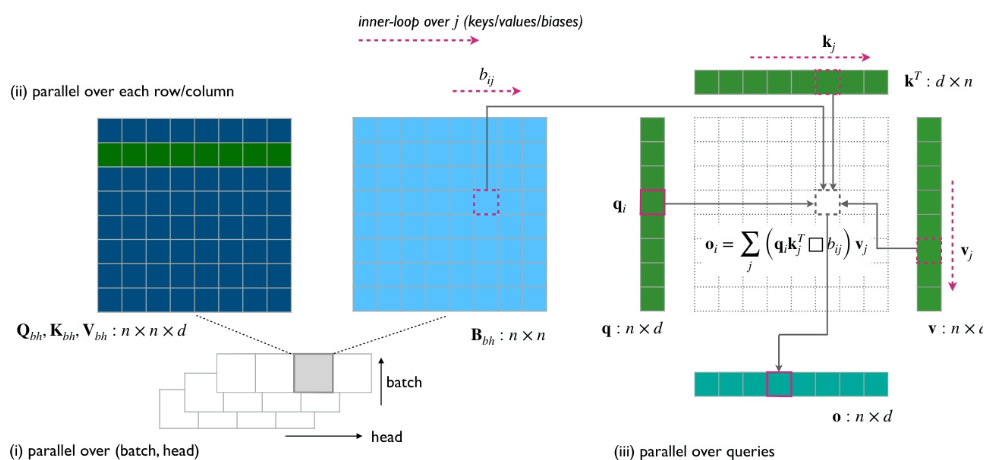
3. SeedFold: 生体分子構造予測のスケーリング
ByteDanceのSeedチームは、スケーラブルな生体分子構造予測モデルSeedFoldを提案しました。SeedFoldは、Pairformerの幅を拡張することでモデル容量を増大させ、線形三角アテンション機構を用いることで計算量を削減し、2,650万サンプルの蒸留データセットを用いたFoldBenchで最先端のパフォーマンスを達成しました。また、タンパク質関連タスクにおいてはAlphaFold3を凌駕しています。
論文と詳細な解釈:https://go.hyper.ai/9zAID
SeedFold データセットには 2,650 万のサンプルが含まれており、実験データセット (0.18M) と AFDB および MGnify からの蒸留データセットという 2 つの主なソースからの大規模なデータ蒸留によって拡張されています。
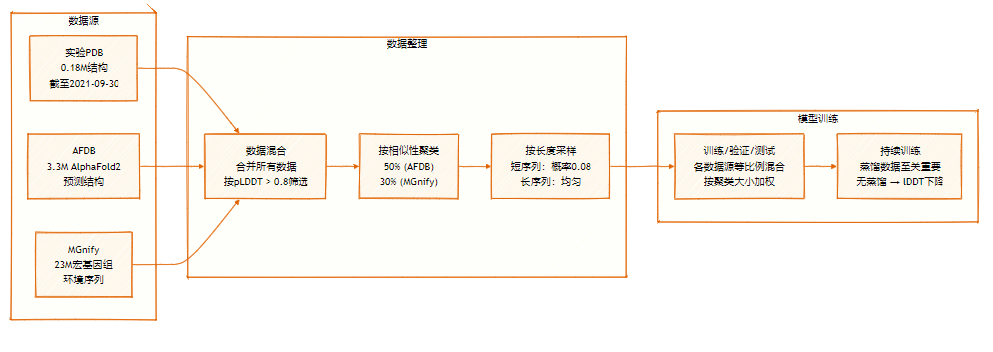
4. トランスフォーマーは時系列予測に効果的ですか?
本論文では、時系列予測におけるTransformerの急速な普及にもかかわらず、その自己注意機構の順列不変性が重要な時間情報の喪失につながることを明らかにしました。比較実験の結果、複数の実世界データセットにおいて、単純な単層線形モデルが複雑なTransformerモデルを大幅に上回る性能を示しました。この知見は既存の研究の方向性に疑問を投げかけ、時系列タスクにおけるTransformerの有効性の再評価を促しています。
論文と詳細な解釈:https://go.hyper.ai/Hk05h
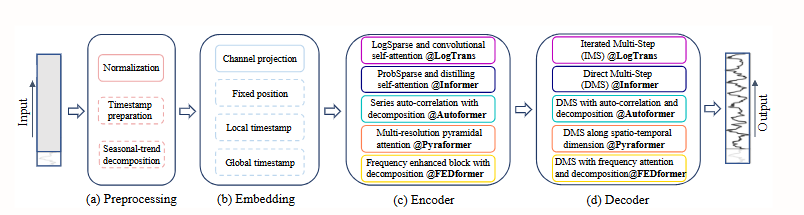
関連するベンチマークは次のとおりです。
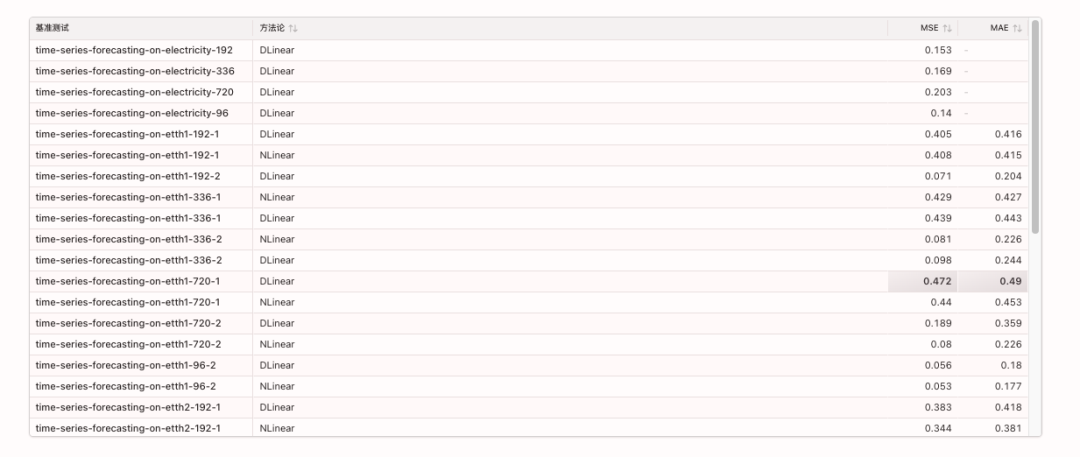
5. 推論モデルは思考社会を生み出す
Google、シカゴ大学、サンタフェ研究所の研究者たちは、DeepSeek-R1やQwQ-32Bといった高度な推論モデルの優れた性能は、思考連鎖の長さだけでなく、モデル内で多様な視点を持つ、異なる個性と専門知識を持つマルチエージェント的な対話である「思考の社会」を暗黙的にシミュレートすることによるものだと提唱しています。彼らは、機械論的解釈可能性と制御された強化学習を通して、会話行動(質問、対立、和解など)と視点の多様性との間に因果関係があり、その正確性は「驚き」という発話マーカーを誘導することで推論性能が2倍になることを示しました。この思考の社会的組織化は、解空間の体系的な探索を可能にし、集合知の原則、すなわち多様性、議論、役割調整が効果的な人工推論の中核的な基盤であることを示唆しています。
論文と詳細な解釈:https://go.hyper.ai/0oXCC
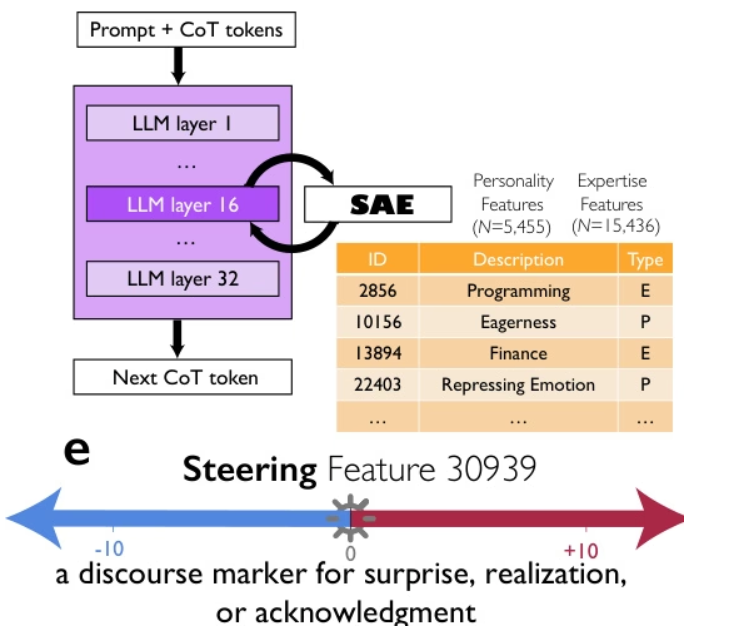
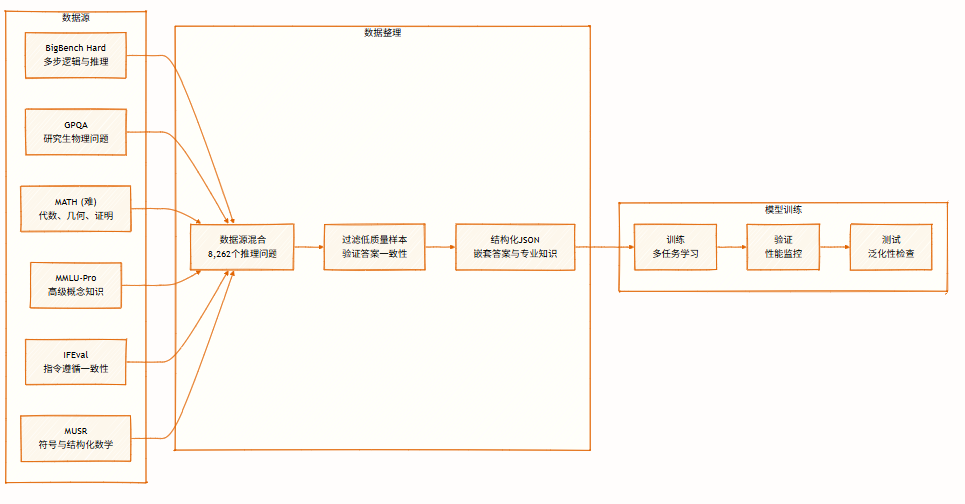
このデータセットには、記号論理、数学的解法、科学的推論、指示追従、マルチエージェント推論など、複数の分野にわたる8,262件の推論問題が含まれています。多視点推論をサポートし、モデルの学習と評価に使用されます。
今週の論文推薦は以上です。さらに最先端のAI研究論文をご覧になりたい方は、hyper.ai公式サイトの「最新論文」セクションをご覧ください。
質の高い研究成果や論文の提出を歓迎いたします。ご興味のある方は、NeuroStar WeChat(WeChat ID: Hyperai01)にご登録ください。
また来週お会いしましょう!








