Command Palette
Search for a command to run...
AIペーパーウィークリーレポート|最先端OCR技術解釈:DeepSeek、Tencent、Baiduが同じ舞台で競う、文字認識から構造化文書解析まで

ここ数年、OCR(光学式文字認識)は「文字認識ツール」から「画像認識ツール」へと急速に進化してきました。視覚言語モデルに基づく汎用文書理解システムマイクロソフトやグーグルなどのグローバル企業が投資を続ける一方で、百度、テンセント、アリババクラウドなどの中国の大手ベンダーも集中的な導入を進めており、市場はルール駆動型OCRから人工知能と自然言語処理を統合したインテリジェントドキュメント処理(IDP)へと急速に進化し、金融、政府関係、医療などの実際のビジネスシナリオへの応用が継続的に深化しています。
業界の継続的な需要に後押しされて、OCR 研究の焦点も大きく変化しました。このモデルはもはや「認識精度」を追求するだけではなく、複雑なレイアウト、マルチモーダルシンボル、長いコンテキストモデリング、エンドツーエンドの意味理解など、より困難な問題を体系的に解決し始めています。二次元視覚情報をいかに効率的にエンコードするか、テキスト情報をいかに効率的に解析するか、そしてモデルの読み取り順序をいかに人間の認知論理に近づけるかが、学界と産業界が共通して関心を寄せる中核課題となりつつあります。
このような高いインタラクションを背景に、最新の OCR 学術論文を継続的に追跡および分析することは、最先端の技術の方向性を把握し、業界の実際の課題を理解し、さらにパラダイムブレークスルーの次の段階を見つけるために特に重要です。
今週は、OCR に関する人気の AI 論文 5 つをご紹介します。DeepSeek、Tencent、清華大学などのチームが参加しています。一緒に学びましょう!⬇️
さらに、より多くのユーザーが学術界における人工知能分野の最新の動向を理解できるように、HyperAI ウェブサイト (hyper.ai) に「最新論文」セクションが開設され、最先端の AI 研究論文が毎日更新されています。
最新のAI論文:https://go.hyper.ai/hzChC
今週のおすすめ紙
- DeepSeek-OCR 2: 視覚的な因果関係フロー
DeepSeek-OCRを基盤として、DeepSeek-AIの研究者たちはDeepSeek-OCR 2を提案しました。DeepSeek-OCRが2次元光学マッピングによる長文圧縮の実現可能性を探る予備的な研究であったとすれば、DeepSeek-OCR 2は、画像セマンティクスに基づいて視覚トークンを動的に並べ替える新しいエンコーダー、DeepEncoderV2の実現可能性を探ることを目的としています。DeepEncoder V2は、エンコーダーに因果推論機能を持たせるように設計されており、LLMベースのコンテンツ理解の前に視覚トークンをインテリジェントに並べ替えることで、従来のラスタースキャン処理を置き換えることができます。これにより、より人間的で意味的に一貫性のある画像理解が実現され、OCRおよび文書分析機能が向上します。
論文と詳細な解釈:https://go.hyper.ai/ChW45
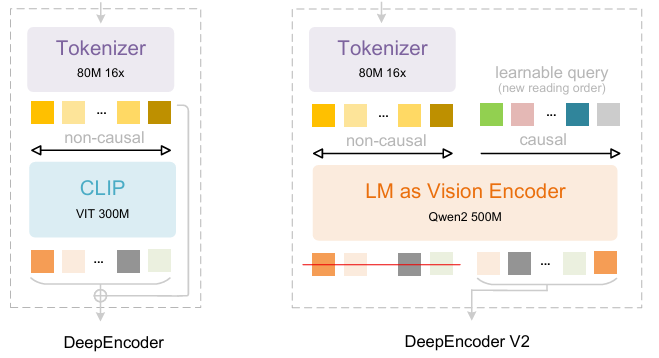
トレーニングデータセットは、OCR 1.0、OCR 2.0、および一般的な視覚データで構成されており、OCRデータは混合トレーニングデータの80%を占めています。評価には、9つのカテゴリにわたるジャーナル、学術論文、研究報告書を含む1,355ページの中国語と英語の文書を含むベンチマークであるOmniDocBench v1.5を使用しました。
2. LightOnOCR: 最先端のOCRのための1Bエンドツーエンド多言語視覚言語モデル
LightOnの研究者らは、10億パラメータのコンパクトな多言語視覚言語モデルLightOnOCR-2-1Bをリリースしました。このモデルは、文書画像からクリーンで整然としたテキストを直接抽出し、大規模なモデルを凌駕する性能を発揮します。また、RLVRによる画像ローカリゼーション機能の強化と、チェックポイントのマージによる堅牢性の向上も実現しています。モデルとベンチマークはオープンソースです。
論文と詳細な解釈:https://go.hyper.ai/zXFQs
ワンクリック展開チュートリアルのリンク:https://go.hyper.ai/vXC4o
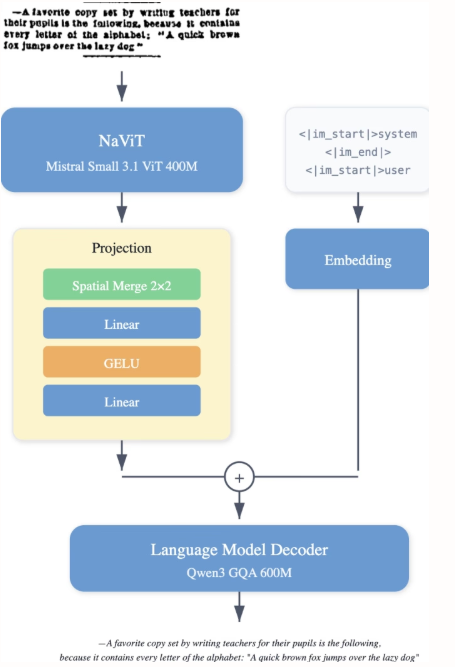
LightOnOCR-2-1Bデータセットは、堅牢性を高めるためのスキャン文書や、レイアウトの多様性を高めるための補足データなど、複数のソースから教師が注釈を付けたページを統合しています。GPT-4oで注釈付けされた切り抜き領域(段落、見出し、要約)、錯覚を抑制するための空白ページの例、そしてnvpdftexパイプラインを介してarXivから取得したTeXベースの教師データが含まれています。多様性を高めるために、公開OCRデータセットも追加されています。
3. HunyuanOCR技術レポート
本論文では、テンセントとその協力者によって開発された、10億個のパラメータを持つオープンソースの視覚言語モデル「HunyuanOCR」を提案する。データ駆動型学習と革新的な強化学習戦略を基盤とし、軽量アーキテクチャ(ViT-LLM MLPアダプタ)を採用することで、テキストローカリゼーション、ドキュメント解析、情報抽出、翻訳といったエンドツーエンドのOCR機能を統合する。その性能は、より大規模なモデルや商用APIを凌駕し、産業・科学研究アプリケーションへの効率的な導入を可能にする。
論文と詳細な解釈:https://go.hyper.ai/F9fni
ワンクリック展開チュートリアルのリンク:https://go.hyper.ai/C4srs

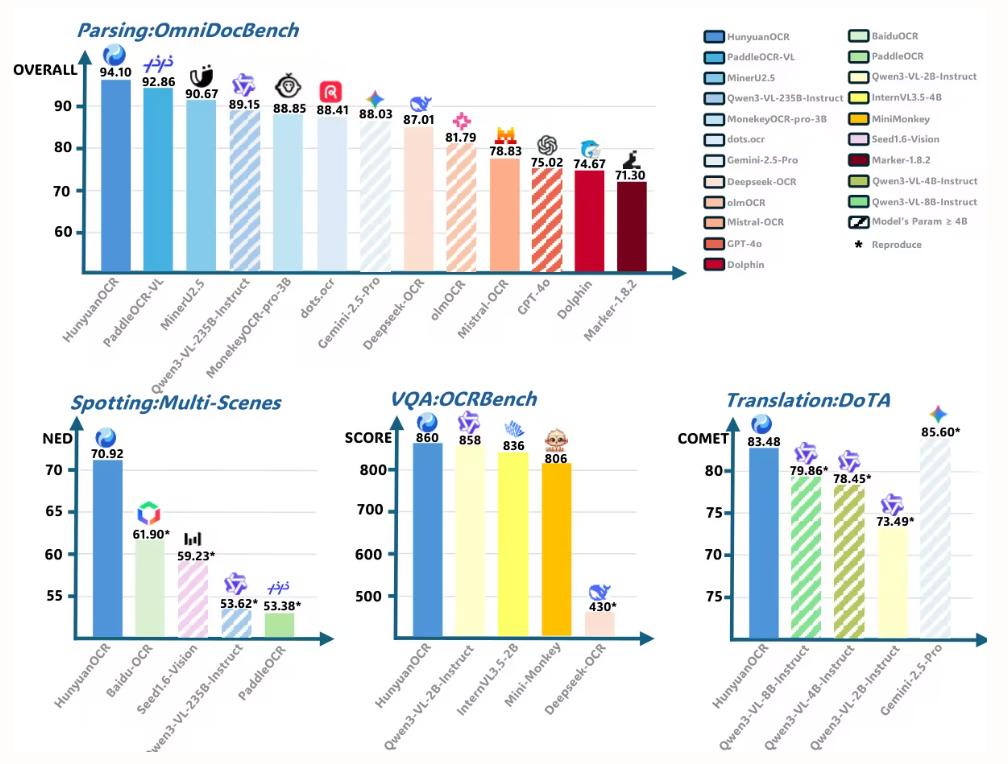
本論文では、HunyuanOCRを用いてOmniDocBenchにおける文書解析性能を評価しました。HunyuanOCRは94.10という最高のスコアを獲得し、他のすべてのモデル(より大規模なモデルも含む)を上回りました。
4 .PaddleOCR-VL: 0.9B の超コンパクトな視覚言語モデルによる多言語ドキュメント解析の強化
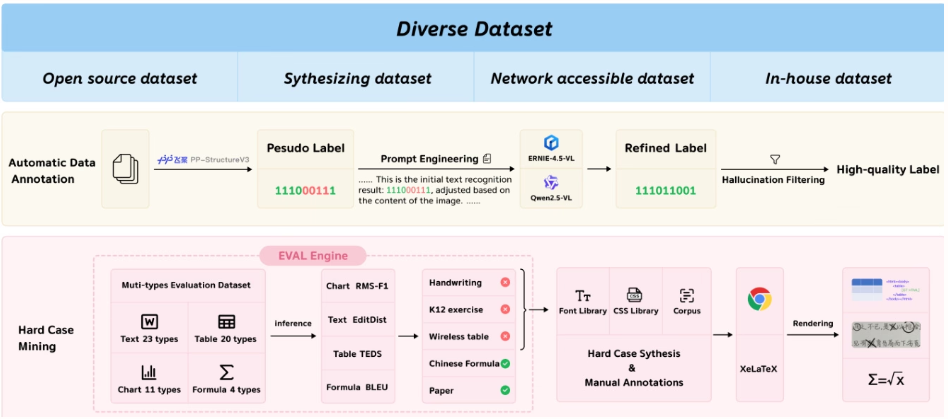
Baiduのチームは、NaViTスタイルの動的解像度エンコーダーとERNIE-4.5-0.3Bモデルを統合した、リソース効率の高い視覚言語モデルであるPaddleOCR-VLを提案しました。このモデルは、多言語文書解析において最先端の性能を実現し、表や数式などの複雑な要素を正確に認識します。高速推論能力を維持しながら、既存のソリューションを凌駕し、実世界のシナリオへの導入に適しています。
論文と詳細な解釈:https://go.hyper.ai/Rw3ur
ワンクリック展開チュートリアルのリンク:https://go.hyper.ai/5D8oo
本研究では、OmniDocBench v1.5、olmOCR-Bench、OmniDocBench v1.0を用いてページレベルの文書解析を評価しました。OmniDocBench v1.5では92.86という最高スコアを達成し、MinerU2.5-1.2B(90.67)を上回りました。また、テキスト(編集距離0.035)、数式(CDM 91.22)、表(TEDS 90.89、TEDS-S 94.76)、読み順(0.043)においてもトップの成績を収めました。
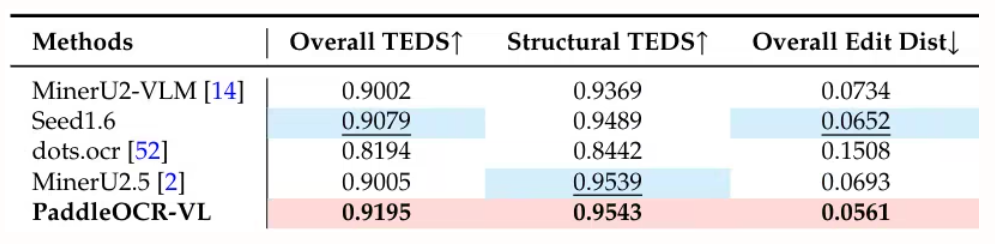
5. 一般的なOCR理論:統一されたエンドツーエンドモデルによるOCR-2.0への道
StepFun、Megvii Technology、中国科学院大学、清華大学の研究者らは、5億8000万のパラメータを持つ統合エンドツーエンドOCR-2.0モデル「GOT」を提案しました。高圧縮エンコーダとロングコンテキストデコーダーを搭載し、テキストから数式、表、グラフ、幾何図形といった様々な人工光信号まで認識機能を拡張します。スライス/フルページ入力、フォーマット出力(Markdown/TikZ/SMILES)、インタラクティブな領域レベル認識、動的解像度、複数ページ処理をサポートし、インテリジェントな文書理解技術の開発を大きく前進させます。
論文と詳細な解釈:https://go.hyper.ai/9E6Ra
ワンクリック展開チュートリアルのリンク:https://go.hyper.ai/HInRr
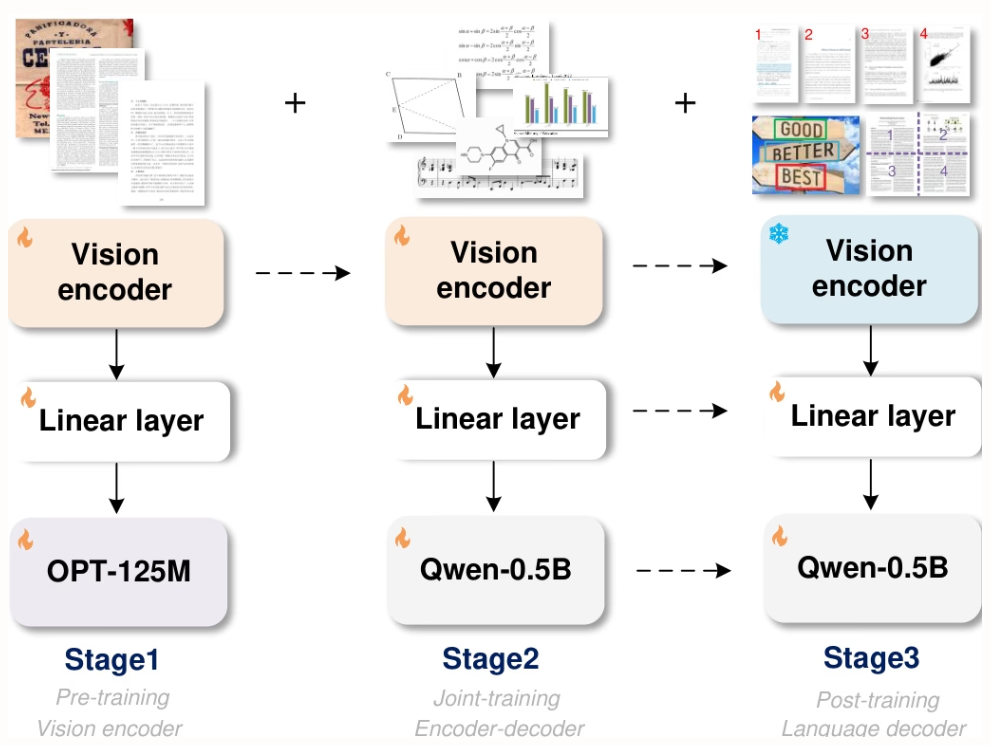
本論文の実験は8×8 L40s GPU上で実施され、3段階の学習が行われた。事前学習(3ラウンド、バッチサイズ128、学習率1e-4)、ジョイント学習(1ラウンド、最大トークン長6000)、事後学習(1ラウンド、最大トークン長8192、学習率2e-5)。第1段階では、パフォーマンスを維持するために80%のデータを保持した。
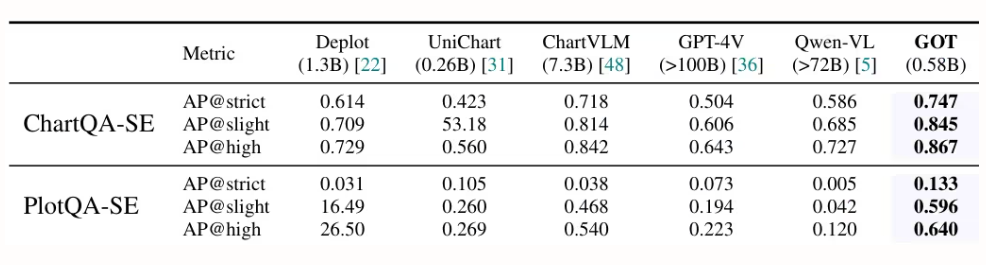
今週の論文推薦は以上です。さらに最先端のAI研究論文をご覧になりたい方は、hyper.ai公式サイトの「最新論文」セクションをご覧ください。
質の高い研究成果や論文の提出を歓迎いたします。ご興味のある方は、NeuroStar WeChat(WeChat ID: Hyperai01)にご登録ください。
また来週お会いしましょう!








