Command Palette
Search for a command to run...
971 TP3T の精度で!プリンストン大学らは、MOF が合成可能かどうかを効率的に予測する MOFSeq-LMM を提案しました。
金属有機構造体(MOF)は、その高度に調整可能な細孔構造と豊富な化学機能性により、ガス貯蔵、分離、触媒、薬物送達などの用途において大きな可能性を示しています。しかしながら、MOF には、ビルディング ブロックの可能な組み合わせが何兆通りも含まれる広大な設計空間があるため、実験的な探索は極めて非効率的です。
MOFの発見を加速するために、新しいMOFを生成し、その特性を予測し、最終的に合成することを目指す計算パイプラインが登場した。このプロセスでは、主な課題は、スクリーニングから合成への変換率が低いことにあります。これは主に、コンピューター生成MOFの合成の実現可能性をめぐる不確実性に起因しています。例えば、これまでに発表された数千件の計算MOFスクリーニングのうち、MOF合成を伴うものはわずか12件程度です。
自由エネルギーはMOFの熱力学的安定性と合成可能性を評価する上で重要な指標ですが、従来の計算手法は大規模なMOFデータセットではコストが高く、迅速なスクリーニングが困難です。この課題に対処するため、プリンストン大学とコロラド鉱山大学の共同研究チームは、機械学習に基づく効率的な予測手法を提案しました。大規模言語モデル (LLM) を使用して MOF の構造配列から自由エネルギーを直接予測することで、計算コストを大幅に削減し、MOF の高スループットでスケーラブルな熱力学的評価が可能になります。このモデルは、再トレーニングを必要とせずに高い汎用性を発揮します。MOF の自由エネルギーが経験に基づく合成実現可能性閾値より高いか低いかを判断する際の F1 スコアは 97% と非常に高くなります。
「機械学習による MOF 自由エネルギーの高精度かつ高速な予測」と題された関連研究成果が ACS Publications に掲載されました。
研究のハイライト:
* このモデルに基づいて、研究者は自由エネルギーを高精度で予測し、再トレーニングなしで完全な分子シミュレーションの結果をシミュレートして、MOF 合成の実現可能性を判断できます。
* かつては実験室や分子シミュレーションで多くの時間を要していた作業が、今ではごくわずかな時間で実行できるようになりました。
この方法は、パフォーマンスベースの計算 MOF スクリーニングにおける早期または後期のスクリーニング ツールとして機械学習の自由エネルギー予測を使用するための実現可能なアプローチを提供します。

用紙のアドレス:
https://pubs.acs.org/doi/10.1021/jacs.5c13960
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「無料エネルギー予測」と返信すると、完全な PDF を入手できます。
AIフロンティアに関するその他の論文:
MOFMinE: 100万個のMOFプロトタイプをカバー
モデルのトレーニングをサポートするために、研究チームは、約 100 万個の MOF プロトタイプを網羅する大規模な MOF データセット MOFMinE を構築しました。次の図に示すように、コンポーネントの選択とトポロジ テンプレートのマッピングから機能の変更までのプロセス全体に関する情報が含まれています。
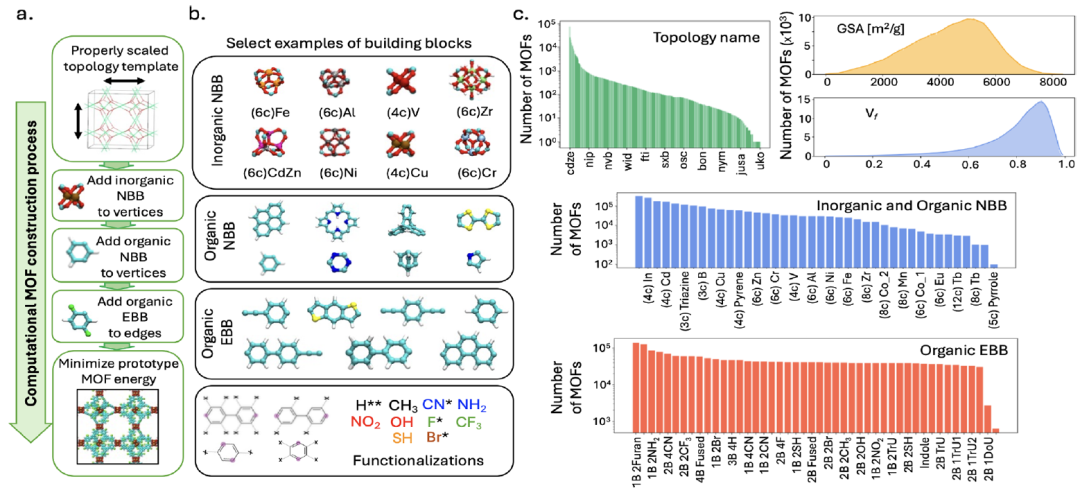
建設方法
このデータセットは、ToBaCCo-3.0 プラットフォームに基づいて生成されています。各 MOF は、その構成要素である構成単位を、適切にスケール調整された(構成単位のサイズに合わせて)位相テンプレートにマッピングすることで生成されます。このテンプレートは、MOF ユニットセル内の構成単位の空間配置と接続性を規定します。ToBaCCo 構成単位は、マッピング位置に基づいて、ノーダル構成単位(NBB)とエッジ構成単位(EBB)に分類されます。ノーダル構成単位はテンプレートの頂点にマッピングされ、エッジ構成単位はテンプレートのエッジにマッピングされます。NBB は無機または有機のいずれでもよく、無機 NBB はいわゆる MOF の二次構成単位(SBU)に相当し、有機 NBB は EBB と結合して MOF コネクタを形成します。
データの規模と多様性
MOFMinE には、1,393 個のトポロジカル テンプレート、27 個の無機 NBB、14 個の有機 NBB、および 19 個の基本 EBB が含まれており、13 個の機能的変更をカバーし、化学構造とトポロジカル構造の多様性を保証します。データベースには、空隙率が 0.01 ~ 0.99、表面積 (GSA) が 26 ~ 8382 m²/g、最大細孔径 (LPD) が 2.6 ~ 127.7 Å の範囲にあり、MOF の構造空間を完全にカバーしています。
自由エネルギーサブセット
これら 100 万個の MOF プロトタイプのうち、65,574 個の構造のサブセットが自由エネルギー データを収集しました。このサブセットには、379個のトポロジカルテンプレート、6個の無機NBB、11個の有機NBB、および13個の官能基修飾を含む12個の基本EBBが含まれています。サブセットの多孔性特性は、Vfが0.01~0.97、GSAが38~7304 m²/g、LPDが2.6~87.8 Åです。このデータセットは、自由エネルギー予測の微調整とLLMのテストに使用されました。
MOF自由エネルギーの効率的な予測のためのMOFSeq-LMMモデル
MOFMinEデータセットのサポートにより、研究チームは、MOFの自由エネルギーを効率的に予測し、構造から特性に至るまでデータ駆動型設計を実現するためのMOFSeq-LMMモデルフレームワークを構築しました。このフレームワークの核となるアイデアは、MOFの構造情報をコンピューターが理解できる配列表現(MOFSeq)に変換し、それを学習と予測のための大規模言語モデルと組み合わせることで、物理化学的情報を保持しながら計算コストを大幅に削減することです。
MOFSeqの特性評価
既存の表現戦略の限界を克服し、大規模な言語モデルを最大限に活用して広範なMOFプロパティ予測を行うために、研究者たちはMOFSeqを開発しました。この新しい文字列ベースの配列表現法は、コンパクトでありながら非常に情報量が多く、MOFの局所的および全体的な構造的特徴を最適化された方法でエンコードします。これにより、言語モデルを効率的かつスケーラブルに処理できるようになります。
MOFSeqにおけるローカル情報には、主にビルディングブロックの原子構成と内部接続情報が含まれます。一方、グローバル情報には、主にMOFビルディングブロックの高レベル記述とビルディングブロック間の接続パターンが含まれます。ローカル情報はMOFidツールによって取得され、グローバル情報はToBaCCo-3.0によって取得されます(下図参照)。
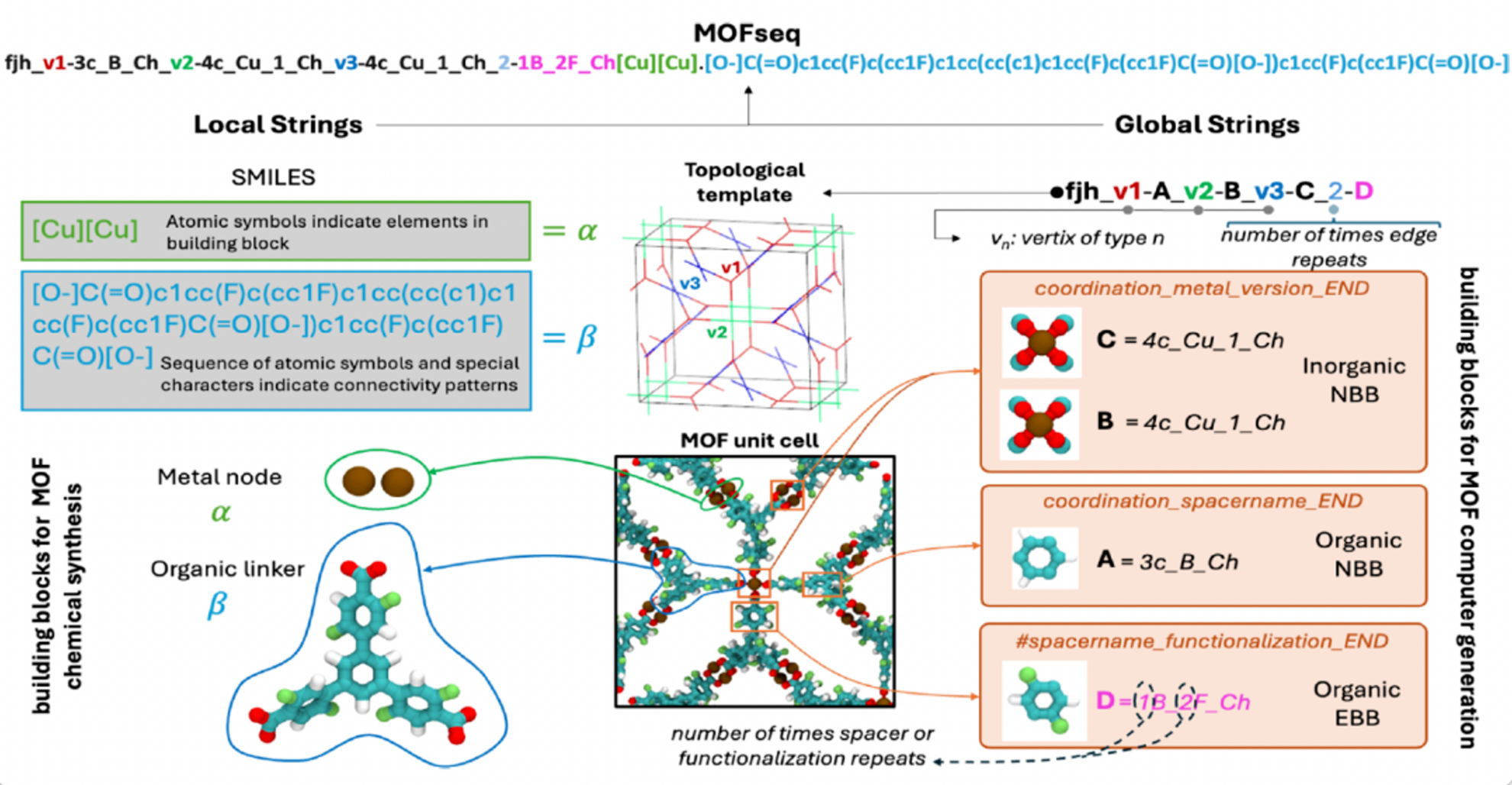
MOFデータベース構築とデータ処理
上記の方法に基づいて MOFMinE データセットを構築した後、ToBaCCo によって生成されたすべての MOF プロトタイプを LAMMPS (2020 年 10 月 29 日バージョン) の UFF4MOF 力場を使用して最適化し、最終的な MOF 構造を取得しました。
ToBaCCo-3.0を使用して生成されたデータセットには、各MOFを表すMOFnameとそれに対応するCIFファイルのみが含まれています。ただし、MOFSeqではMOFnameとMOFidの両方が必要です。MOFidを取得するために、研究者らはBuciorらによって開発されたMOFidジェネレータを使用しました。このジェネレーターは、MOF の CIF 構造に基づいて、MOFid と MOFkey を同時に生成できます。
最終的に、793,079個のMOFSeq事前トレーニングサンプルは、634,463個のトレーニングセット、79,308個の検証セット、79,308個のテストセットに分割されました。54,443個のMOFSeq微調整データポイントは、43,554個のトレーニングセット、5,444個の検証セット、5,445個のテストセットに分割されました。
LLM-Propモデル設計
研究チームは、MOFSeq の特性評価に基づいて、材料特性の予測用に特別に設計された大規模言語モデルである LLM-Prop を採用しました。 LLM-Propモデルは約3500万のパラメータと比較的中程度のサイズであり、学習能力と計算効率の両方を確保しています。モデルの入力長は2000トークンに設定されており、ほとんどのMOFの構造配列情報を収容できます。アテンションメカニズムを通じて、モデルは異なるコンポーネントとトポロジーが配列の自由エネルギーに与える影響を適応的に捉え、グローバルおよびローカルな特徴のインタラクティブな表現を形成します。
事前トレーニングと微調整
* 事前トレーニング段階:
研究者らは、MOFSeq表現を用いてMOFのひずみエネルギーを予測するようにLLM-Propを訓練した。ひずみエネルギーは計算コストが低く、自由エネルギーとの相関が高いことから選択された。事前訓練ではドロップアウト率0.2と0.5が使用され、事前訓練と下流タスクの両方でドロップアウト率0.2の方が優れたパフォーマンスを示した。MOFSeqの入力長は2000トークンに設定された。
微調整フェーズ:
セットアップは事前学習と同じですが、モデルの目的を自由エネルギーの予測に変更し、学習エポック数を200に増やしています。LLM-Propは、計算効率を優先し、Llama 2の約2000分の1のサイズの軽量モデルとして設計されています。この設計にはトレードオフがあります。Llama 2やGPT-2などの大規模なLLMを微調整する場合と比較して、LLM-Propは高いパフォーマンスを実現するためにより多くの学習エポックを必要としますが、サイズが小さいため、学習は実現可能かつ効率的です。
MOF合成の予測精度は97%に達しました。
MOFSeq-LMMモデルを学習させた後、研究チームは自由エネルギー予測、合成実現可能性評価、多形性MOFスクリーニングにおける性能を体系的に評価しました。実験結果は、モデルの高い精度を実証しただけでなく、ハイスループットMOF設計およびスクリーニングへの応用可能性も示しました。
自由エネルギー予測性能
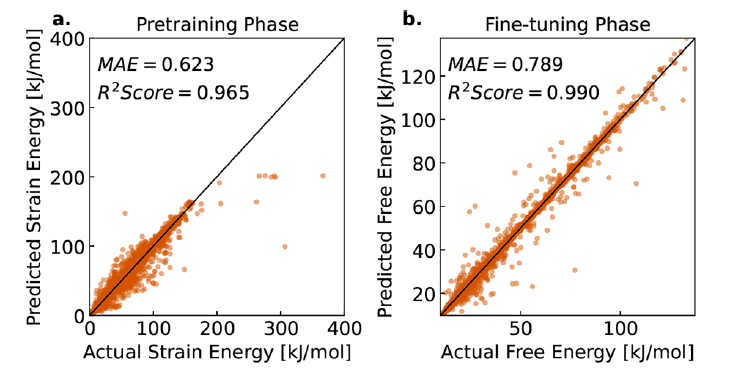
初め、研究チームは、未知の MOF サンプルに対する LLM-Prop の自由エネルギー予測性能を評価しました。結果は、モデルが平均絶対誤差 (MAE) 0.789 kJ/mol MOFatom で自由エネルギーを正確に予測でき、R² = 0.990 という高い相関関係を達成できることを示しています (下の図 b を参照)。これは、モデルが MOF サンプルの大部分において実際の値に近い予測を提供できることを意味します。
事前学習段階では、モデルはひずみエネルギーデータを用いて学習され、図aに示すように、MAE 0.623 kJ/mol MOFatom、R² 0.965を達成しました。この高い相関は、ひずみエネルギーデータが自由エネルギー予測のための有効な予備情報を提供できることを示しており、研究チームの事前学習戦略の合理性を検証しています。さらに分析を進めると、事前学習済みのひずみエネルギーと微調整後の自由エネルギーの間に高い相関が見られ、モデル学習における低コストの代替指標としてのひずみエネルギーの価値が実証されています。
アブレーション実験結果
モデルのパフォーマンスの源泉をより深く理解するために、研究チームは体系的なアブレーション実験を実施しました。実験では、局所特徴、大域特徴、そして事前学習が自由エネルギー予測に与える影響を検証しました。結果は以下の表に示されています。
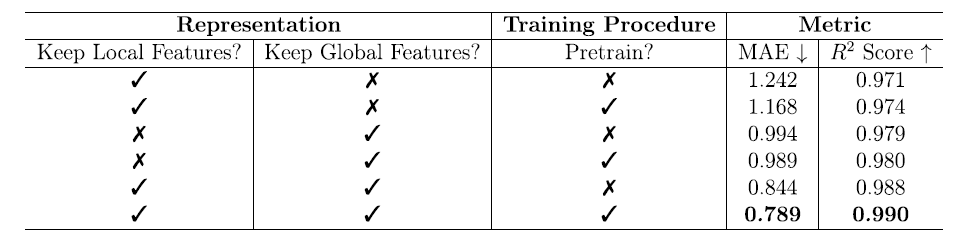
ローカル特徴のみ: 事前トレーニングにより、MAE は 1.242 kJ/mol MOFatom から 1.168 kJ/mol MOFatom に減少し、R² は 0.971 から 0.974 に増加しました。これは、ローカル特徴が制限されている場合、事前トレーニングによってモデルの一般化能力を向上できることを示しています。
* グローバル機能のみ:
ローカル特徴量のみを使用した場合と比較して、パフォーマンスが大幅に向上し、MAEは1.0 kJ/mol MOFatom未満に低下し、R²は約0.980に増加しました。この場合、事前学習の影響は比較的小さく(MAEは0.994 kJ/mol MOFatomから0.989 kJ/mol MOFatomに低下し、R²は0.979から0.980に増加)、グローバル特徴量自体により多くのタスク情報が含まれており、効果的な学習を実現するために事前学習への依存度が低いことを示しています。
* ローカル機能とグローバル機能の組み合わせ:
事前トレーニングのサポートにより、モデルは MAE 0.789 kJ/mol MOFatom、R² 0.990 という最適なパフォーマンスを達成し、2 種類の機能の相乗効果が予測精度の向上に重要であることが実証されました。
このアブレーション実験は、グローバル機能とローカル機能の設計と MOFSeq の事前トレーニング戦略が、モデルの予測能力を向上させるための中核要素であることを明確に示しています。
合成の実現可能性評価
産業用途においては、自由エネルギーの絶対値のみに焦点を当てるのではなく、MOFの合成可能性を判断することがより重要な課題となります。研究チームは、ΔL_MFFL(自由エネルギー補正に基づく指標)を4.4 kJ/mol MOFatomの閾値に設定し、MOFの合成可能性について2値分類予測を行いました。実験結果を下の図に示します。
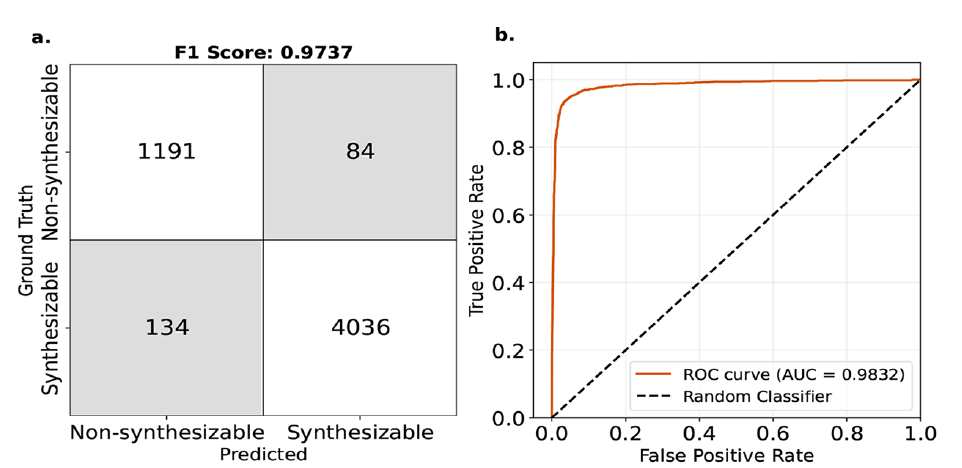
* F1 スコアは 97% に達し、モデルの優れた一般化能力が示されました。
* ROC 曲線の下の面積 (AUC) は 0.98 と高く、これは、モデルが特定の MOF が約 2% のみで合成できると判断した場合、最終的に誤った評価が行われる確率として理解できます。
多形性MOFのスクリーニング
多態性を持つMOFシステムの場合、この実験により、最も安定した多形を識別するモデルの能力がさらに検証されました。それぞれ 2 ~ 50 個の多形を含む 7,490 個の多形ファミリーの中で、このモデルは自由エネルギー差がわずか 0.16 kJ/mol MOFatom である最も安定した多形を正しく選択することができ、成功率はおよそ 63% です。自由エネルギー差が 0.49 kJ/mol MOFatom に増加すると、成功率は 89% に増加します。
全体として、このモデルは多型認識タスクで約 781 TP3T の平均成功率を達成します。下の図に示すように、実験スクリーニング前のハイスループット予測に大きな価値があります。

実用的観点から、LLMが熱力学的安定性と多形競合の評価に基づいて特定のMOF設計が合成可能であると判断した場合、その正しさの確率は約76%から98%の間となります。高い確率は、MOFに競合する多形がない場合に相当します。
AI は MOF と材料科学研究のパラダイムを再構築しています。
2025年10月8日スウェーデン王立科学アカデミーは、MOF分野における研究貢献を認められ、京都大学の北川進教授、メルボルン大学のリチャード・ロブソン教授、カリフォルニア大学バークレー校のオマール・ヤギ教授の3名に2025年のノーベル化学賞を授与することを決定しました。この歴史的な瞬間から振り返ると、MOF研究は30年以上の発展を遂げ、初期の構造構築と合成探索から、性能制御、用途拡大、そして産業化へと徐々に移行してきました。この節目を経て、材料科学は新たな変数を迎え入れています。人工知能の深い関与は、MOF、ひいては材料科学全体の研究パラダイムとイノベーションのリズムを再構築しつつあります。
標準化された命名規則のないMOFの広大で複雑な世界への挑戦に応えて、2025年10月に、トロント大学とカナダ国立研究会議クリーンエネルギーイノベーション研究センターの研究チームは、構造化され、スケーラブルで拡張可能な知識グラフである MOF-ChemUnity を提案しました。この手法は、LLMを利用して、文献中のMOF名とその同義語、およびCSDに登録されている結晶構造との間の信頼性の高い1対1のマッピングを確立し、MOF名とその同義語、そして結晶構造間の曖昧性を排除します。現在のバージョンでは、MOF-ChemUnityは約10,000件の科学論文と15,000件を超えるCSD結晶構造とその計算化学特性を統合し、機械操作可能な形式で提示しています。
論文タイトル: MOF-ChemUnity: 金属–有機構造体研究のための文献情報に基づく大規模言語モデル
用紙のアドレス:https://pubs.acs.org/doi/10.1021/jacs.5c11789
MOF材料の合理的設計において、合成前の構造予測は、そのような材料の効率的かつ標的を絞った合成を達成するための重要な課題であった。この課題に対処するために、上海交通大学の Cui Yong 教授と Gong Wei 教授が率いるチームは、MOF の金属ノードタイプを高速かつ正確に予測できるデータ駆動型の機械学習ワークフローを開発しました。この手法は、有機配位子の構造情報を入力として用い、機械学習モデルを用いて配位子の特徴と金属ノードの種類とのマッピング関係を確立することで、合成前に形成される可能性のある金属ノードの種類を効果的に予測します。学習および最適化された機械学習予測モデルは、テストセットにおいて91%の予測精度、89%の適合率、85%の再現率を達成しました。
論文タイトル: データ駆動型機械学習による金属有機構造体における金属ノードタイプの予測によるリンカー設計のガイドと逆C3H8/C3H6分離のターゲット化
用紙のアドレス:http://engine.scichina.com/doi/10.1007/s11426-025-2917-4
従来のMOF研究は、多くの場合、構造や特性から出発し、局所的な変数制御と広範な実験や計算を通じて、対象材料に徐々に近づいていきます。しかし、これらの新しい研究では、出発点自体が変化しています。研究者はまず、計算的に実現可能で合理的な材料表現システムを構築し、次にモデルに、物理的に妥当で、熱力学的に実現可能で、合成的に価値のある構造の組み合わせを学習させます。モデルが百万スケールの構造空間において信頼性の高い熱力学的および構造的判断を迅速に提供できるようになると、材料研究の焦点は「計算と測定の方法」から「問題の定義、表現の構築、そして判断の境界の設定方法」へと移行します。これは、30年以上にわたる構造的および化学的蓄積を経て、MOF研究が達成しようとしている次の方法論的飛躍となるかもしれません。
参考文献:
1.https://pubs.acs.org/doi/10.1021/jacs.5c13960
2.https://phys.org/news/2026-01-tool-narrows-ideal-metal-frameworks.html








