Command Palette
Search for a command to run...
最先端のリアルタイム物体検出!YOLOv13 はグローバル認識機能を拡張します。NeurIPS 2025 に選ばれた UltraHR-100K は、超高解像度のテクスチャ画像を実現します。

リアルタイム物体検出は、コンピュータビジョンにおける最先端研究分野として長年にわたり発展してきました。産業用検出から自動運転に至るまで、科学界と産業界による「速度」と「精度」の追求は、決して止まることはありません。この分野において、YOLOシリーズのモデルは、推論速度と精度の優れたバランスにより、主流の地位を占めています。
しかし、YOLO の初期バージョンから最近の YOLOv11、さらには領域自己注意メカニズムを使用する YOLOv12 に至るまで、複雑なシナリオの処理には制限があります。畳み込み演算は、固定された局所的な受容野内の情報しか集約できず、そのモデリング能力は畳み込みカーネルのサイズとネットワークの深さによって制限されます。自己注意機構は受容野を拡張しますが、それでもグローバルモデリングと知覚の高い計算コストとのバランスを取る必要があります。さらに重要なのは、自己注意は基本的にピクセル間の2値相関しかモデル化できないことです。
これらの課題に対処するために、YOLO シリーズは最新バージョンの YOLOv13 に更新されました。新バージョンでは、潜在的な高次関連性を適応的に活用するハイパーグラフベースの適応型関連性強化(HyperACE)メカニズムが導入されています。これにより、ハイパーグラフ計算に基づくペアワイズ関連性モデリングに限定されていた従来の手法の限界を克服し、効率的なグローバルなクロスロケーションおよびクロススケールの特徴量融合と強化を実現します。YOLOシリーズのリアルタイム検出の利点を基に、新バージョンでは、高次セマンティックモデリングや軽量構造再構築といった一連の新しいメカニズムも導入されています。これにより、従来の領域ベースのペアワイズ相互作用モデリングがグローバルな高次関連モデリングに拡張されます。
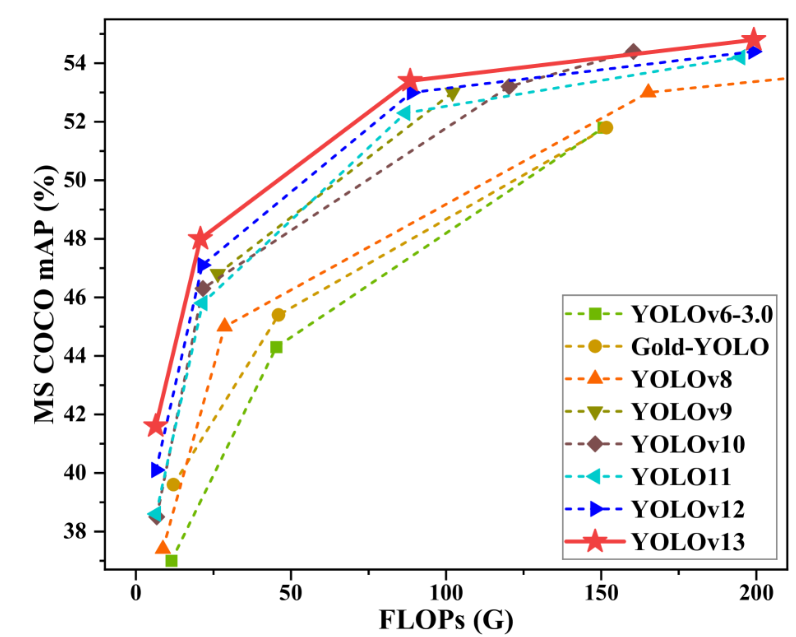
YOLOv13 は、MS COCO や Pascal VOC などの主要なデータセットで包括的なリーダーシップを獲得しました。より強力な一般化機能と展開の実用性を示し、複雑なシナリオにおけるアプリケーションにさらに高度なパフォーマンス オプションを提供します。
HyperAIウェブサイトでは、ワンクリックでYolov13をデプロイできる機能を提供しています。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/PAcy1
11月3日から11月7日までのhyper.ai公式ウェブサイトの更新の概要は次のとおりです。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
11月締め切りのトップカンファレンス:5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. 糖尿病健康指標データセット
Diabetes Health Indicatorsは、糖尿病リスク予測、公衆衛生研究、機械学習モデリングを支援するために設計された包括的な健康・医療分析データセットです。このデータセットには31の糖尿病特徴フィールドが含まれており、人口統計学的特性、ライフスタイル、病歴、臨床指標という4つの主要な変数カテゴリをカバーしています。
直接使用します:https://go.hyper.ai/nVnPo
2. Nemotron Personas USA: アメリカのペルソナデータセット。
Nemotron-Personas-USA は、NVIDIA がリリースした大規模な合成ユーザー プロファイル データセットであり、対話生成、ロール シミュレーション、ユーザー モデリング、多様な行動分析などのタスクにおける大規模言語モデル (LLM) とインテリジェント エージェント システムのトレーニングと評価をサポートするように設計されています。
直接使用します:https://go.hyper.ai/lMA6r
3. UltraHR-100K 超高解像度画像データセット
UltraHR-100Kは、超高解像度(UHR)テキスト画像変換(T2I)タスクのための大規模かつ高品質なデータセットです。拡散モデルのきめ細かな詳細合成、コンテンツの多様性表現、視覚的忠実度を向上させるために設計されています。このデータセットには、人物や建築物など幅広いテーマを網羅した約10万枚の超高解像度画像が含まれています。各画像は3Kを超える解像度で、高品質のリッチテキストによる説明が付与されています。
直接使用します:https://go.hyper.ai/I3Fwl

4. ライフスタイルデータ
ライフスタイルデータは、パーソナライズされた健康推奨システム、運動分析、ライフスタイル予測モデリングのための高品質なデータ基盤を提供するために設計された、包括的な健康とフィットネス行動データセットです。このデータセットは、日々の食事、運動、生理学的指標、体組成など、複数の側面から個人に関する情報を統合し、個人特性、運動パフォーマンス、食生活、フィットネス行動といった多階層変数をカバーする完全なフィールドを備えた構造化テーブル(CSV)形式で提供されます。
直接使用します:https://go.hyper.ai/SGK9K
5. 世界の地震・津波リスクデータセット
世界地震津波リスク評価は、地震と津波のリスク評価のための世界規模のデータセットであり、津波リスク予測、地震イベント分析、地震ハザード評価のための標準化された計算可能なデータ基盤を提供するように設計されています。
直接使用します:https://go.hyper.ai/a9Nrz
6. ShiftySpeech音声分布評価データセット
ShiftySpeechは、ジョンズ・ホプキンス大学が公開した大規模合成音声検出ベンチマークです。このベンチマークは、音声合成検出モデルが「分布ドリフト」(言語、話者、生成モデル、録音条件の変化を含む)に直面した際の、実世界における汎化能力を研究することを目的としています。
直接使用します:https://go.hyper.ai/YMKSP
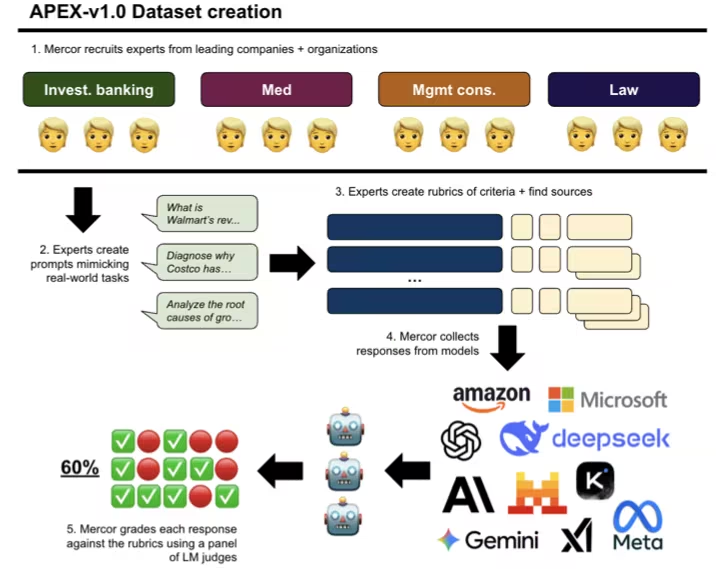
7. APEX AI生産性ベンチマークデータセット
APEXは、ハーバード大学ロースクールおよびスクリプス研究所と共同でMercorの研究チームが初めて公開した包括的なベンチマークデータセットです。経済的価値の高い知識労働における最先端の人工知能モデルの性能を評価するために使用されます。抽象的な推論レベルにとどまらず、実際の経済タスクにおける最先端の人工知能モデルの性能を測定することを目的としています。
直接使用します:https://go.hyper.ai/3E2on
8. マルチLエントリ多言語基本タスクベンチマークデータセット
Multi-LMentryは、多言語環境における低レベル言語理解および基本推論タスクのための大規模言語モデル(LLM)の言語横断的汎化能力を体系的に評価するために設計された多言語ベンチマークデータセットです。このデータセットは、英語とドイツ語を含む9つの言語をカバーしています。タスクはネイティブスピーカーによって手動で再設計されており、元のLMentryフレームワークに類似した形式ですが、自然さと文化的な適合性を確保するために直接翻訳されていません。
直接使用します:https://go.hyper.ai/o2uJC
9. Ditto-1M 命令駆動型ビデオ編集データセット
Ditto-1Mは、香港科技大学がAnt Group、浙江大学などの機関と共同で開発した、指示駆動型ビデオ編集データセットです。自然言語指示に基づくビデオ編集モデルの開発を促進し、大規模かつ高品質な合成サンプルを通じて、複雑な指示に対するモデルの理解とビデオ生成の精度を向上させることを目的としています。
直接使用します:https://go.hyper.ai/o2uJC

10. Reac-Discovery化学反応器の性能データセット
ジャウメ1世大学が公開したReac-Discoveryは、AIを活用したフローリアクター設計と反応性能の最適化のためのデータセットです。このデータセットは、チームが独自に開発したReac-Discoveryプラットフォームを用いた実験中に自動生成され、外部の公開データソースは一切使用されていません。データセットは、プラットフォームの機能モジュールReac-Gen、Reac-Fab、Reac-Evalに対応する、形状、印刷可能性、反応性能の3つのカテゴリーのデータをカバーしています。
直接使用します:https://go.hyper.ai/bMxVY
選択された公開チュートリアル
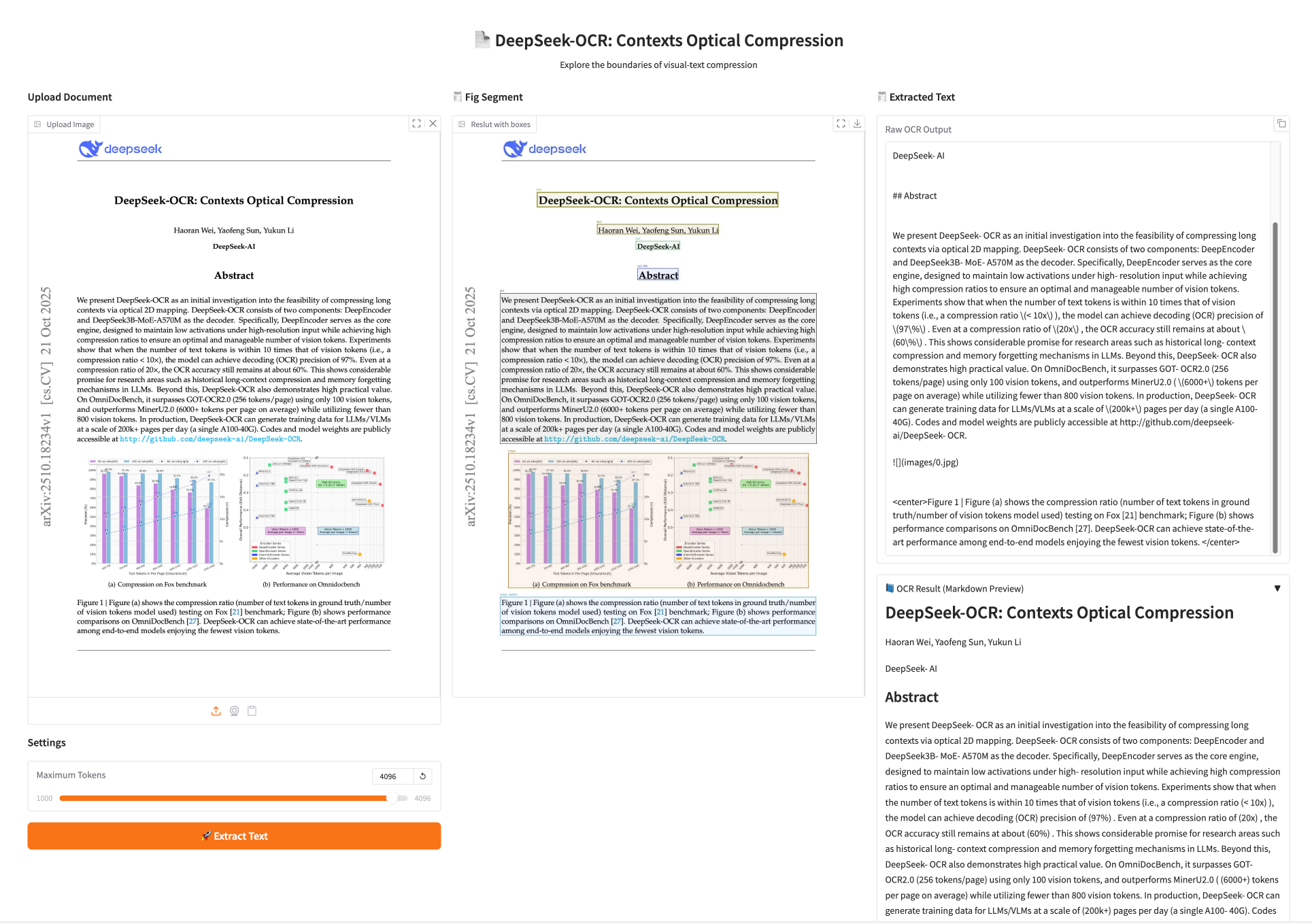
1. DeepSeek-OCR: 従来の文字認識に代わる「視覚的圧縮」
DeepSeek社がリリースしたDeepSeek-OCRは、画像から長いコンテキストを圧縮する可能性に関する予備的な研究です。実験では、テキストトークンの数が画像トークンの10倍を超えない場合(つまり、圧縮率が10倍未満の場合)、このモデルは971 TP3Tのデコード(OCR)精度を達成できることが示されています。圧縮率が20倍の場合でも、OCR精度は約601 TP3Tです。
オンラインで実行:https://go.hyper.ai/wmghV
2. Nanonets-OCR2-3B: 複雑な文書内の視覚要素をより正確に解釈
Nanonets-OCR2-3Bは、Nanonetsがリリースした画像からMarkdownへの変換モデルです。Nanonets-OCR2-3Bは、文書を構造化されたMarkdownに変換するだけでなく、インテリジェントなコンテンツ認識、セマンティックタグ付け、コンテキスト認識型のビジュアル質問応答を活用することで、複雑な文書をより深く理解し、より正確に解釈することができます。
オンラインで実行: https://go.hyper.ai/3DWbb
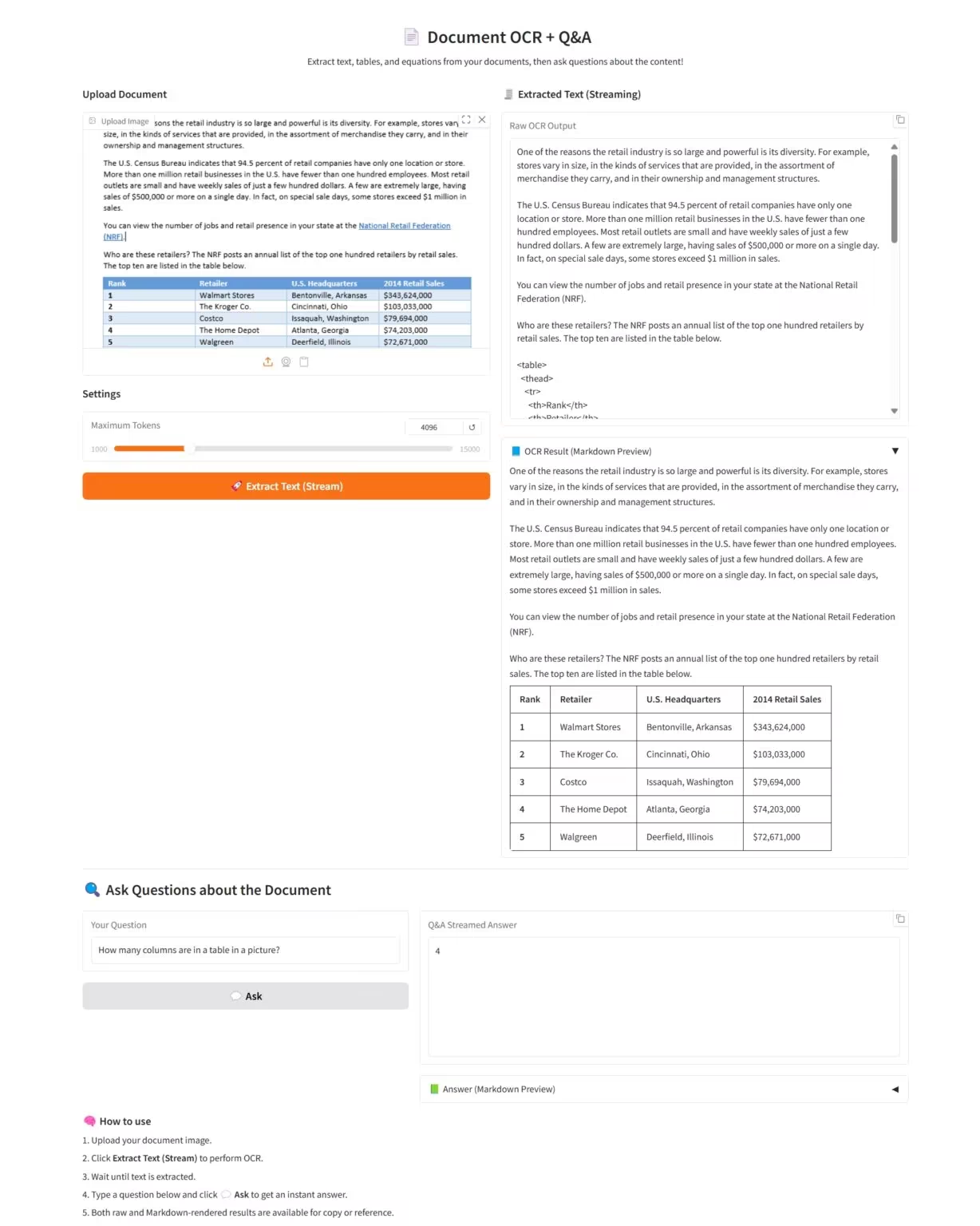
3. Yolov13のワンクリック展開
YOLOv13は、清華大学、太原理工大学、西安交通大学などの共同研究チームによって提案された物体検出モデルです。YOLOシリーズのリアルタイム検出の利点を基盤に、ハイパーグラフ拡張、高次セマンティックモデリング、軽量構造再構築といった一連の新メカニズムを導入しています。MS COCOやPascal VOCといった主流データセットにおいて包括的なリーダーシップを獲得し、より強力な汎化能力と実用的展開を実証しています。
オンラインで実行:https://go.hyper.ai/PAcy1
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. すべてのアクティベーションをブースト:汎用推論エンジンを1兆に拡張 Open Language Foundation
本稿では、「アクティベーションごとに推論能力を高める」という基本原則に基づいて構築された、シリアル推論タスク向けの言語基盤モデルであるLing 2.0を紹介します。統一されたMixture-of-Experts(MoE)アーキテクチャに基づき、このモデルは数十億から数兆のパラメータまで拡張可能で、高いスパース性、スケール間の一貫性、そして経験的スケーリング則に基づく効率性を重視しています。
論文リンク:https://go.hyper.ai/O4pRV
2. ThinkMorph: マルチモーダルインターリーブ思考連鎖推論における創発特性
この論文では、24,000 の高品質なインターリーブ推論軌跡に基づいて微調整された統合モデルである ThinkMorph を構築します。このモデルは、さまざまなレベルの視覚的関与を伴うさまざまなタスクをカバーし、段階的に前進するグラフテキスト推論ステップを生成し、視覚コンテンツを操作しながら一貫した意味論的ロジックを維持することができます。
論文リンク:https://go.hyper.ai/AGtSS
3. VLAを盲目にしない:OOD一般化のための視覚表現の調整
本研究では、視覚・言語・行動(VLA)モデルの微調整における表象の保持について体系的に検討し、直接的な行動の微調整が視覚表象パフォーマンスの低下につながることを明らかにした。この影響を特徴づけ、測定するために、研究者らはVLAモデルの隠れた表象を探索し、その注意マップを分析した。さらに、VLAモデルと対応するVLMモデルを比較するための一連の標的課題と手法を設計し、行動の微調整によって引き起こされる視覚言語能力の変化を分離した。
論文リンク:https://go.hyper.ai/xNU6P
4. OS-Sentinel: 現実的なワークフローにおけるハイブリッド検証による安全性強化モバイルGUIエージェントの実現
この論文では、形式検証器を通じて明示的なシステムレベルの違反を協調的に検出すると同時に、VLM ベースのコンテキスト ジャッジを使用してコンテキスト リスクとプロキシ動作を評価する、新しいハイブリッド セキュリティ検出フレームワーク OS-Sentinel を提案します。
論文リンク:https://go.hyper.ai/bG6b5
5. VCode: SVG を記号的視覚表現として用いたマルチモーダルコーディングベンチマーク
本論文では、マルチモーダル理解をコード生成タスクにリファクタリングするベンチマークフレームワークであるVCodeを提案します。画像が与えられた場合、モデルは下流の推論をサポートするために記号的意味を保持するSVGコードを生成する必要があります。このフレームワークは、一般常識理解(MM-Vet)、対象固有の知識(MMMU)、視覚知覚中心タスク(CV-Bench)の3つの領域をカバーします。
論文リンク:https://go.hyper.ai/UNmqK
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. デミス・ハサビスは、DeepMind を純粋科学研究の時代から脱却させます。AI4S が新たな物語になるにつれ、倫理的な課題は続きます。
2025年10月、Google DeepMindのCEOであるデミス・ハサビス氏が、タイム誌の「TIME 100」リストの表紙を飾りました。ハサビス氏はAlphaGoからAlphaFoldまで、AI4Sの科学的方向性を堅持していましたが、DeepMindがGoogleに統合されると、多くのメディアがDeepMindの商業的野心と倫理的な問題を批判しました。
レポート全体を表示します。https://go.hyper.ai/vSqZI
2. オンラインチュートリアル | デバイス向け最新最先端(SOTA)TTS!NeuTTS-Airは0.5Bモデルをベースに3秒の音声クローニングを実現
Neuphonic社の最新のオープンソース・エンドツーエンド音声合成モデルであるNeuTTS-Airは、特にハイパーリアリスティック合成とリアルタイム推論のベンチマークにおいて、オープンソースモデルの中で最先端(SOTA)のパフォーマンスを達成しています。また、組み込みエージェントやスタイル転送といった新しいシナリオへの汎用化が可能で、3秒間のオーディオクローニングをサポートし、自然な音声の対話コンテンツを生成します。
レポート全体を表示します。https://go.hyper.ai/5kAIi
3. 従来の方法より4200倍高速!ETHチューリッヒは、ヒト皮質データで検証された初のニューロンモデリングフレームワーク「NOBLE」を提案しています。
ETHチューリッヒ、カリフォルニア工科大学、アルバータ大学の共同チームが、NOBLEと呼ばれるディープラーニングフレームワークを提案しました。これは、ヒトの大脳皮質の実験データを用いて性能を検証した初の大規模ディープラーニングフレームワークであり、実験データからニューロンの非線形ダイナミクスを直接学習することで、従来の数値ソルバーと比較して4200倍のシミュレーション速度を実現しました。
レポート全体を表示します。https://go.hyper.ai/oQ74B
4. OpenAI、Meta、Googleなどに勤める22歳の大学中退者3人がAI採用業界に革命を起こしている。わずか2年前に設立されたMercorの評価額は数百億ドルに上る。
わずか22歳で大学を中退した3人によって設立されたMercorは、わずか3年足らずでシリーズCの資金調達で3億5,000万ドルを調達し、評価額は100億ドルに急上昇しました。同社はAIを活用した採用モデルによって、従来の採用業務の効率をわずか数秒にまで短縮し、AIの経済的価値を評価するための新たな基準となるAPEXベンチマークを立ち上げました。
レポート全体を表示します。https://go.hyper.ai/kBj1w
5. タンパク質構造の不均一性に関する原子レベルモデリングの課題を解決する!David BakerチームのPLACERフレームワーク解析
ワシントン大学のデイビッド・ベイカー教授率いる研究チームは、PLACERと呼ばれるグラフニューラルネットワークを開発した。このネットワークは、小分子の原子構成と結合情報に基づいて、さまざまな有機小分子の構造を正確に生成できる。また、タンパク質のマクロ構造が分かれば、タンパク質と小分子のドッキングタスクのために、小分子とタンパク質側鎖の詳細な構造を構築することができる。
レポート全体を表示します。https://go.hyper.ai/sisqO
人気のある百科事典の項目を厳選
1. DALL-E
2. ハイパーネットワーク
3. パレートフロント パレートフロント
4. 双方向長短期記憶(Bi-LSTM)
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
11月の締め切り会議
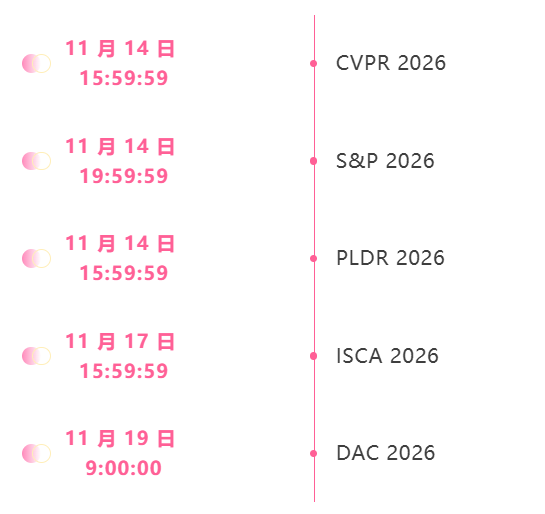
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








