Command Palette
Search for a command to run...
革新的な入出力技術!テンセント・ハンユアンがハンユアンワールドミラーを発表、3D再構成技術を刷新し最先端へ。Netflixコンテンツの全体像を解読!Netflixの映画・テレビ番組カタログデータセットがエンターテインメントのトレンドを洞察

視覚幾何学学習はコンピュータビジョンの中核を成すテーマであり、拡張現実(AR)、ロボット操作、自律航法などに広く応用されています。運動構造(SfM)や多視点ステレオ法といった従来の手法は、一般的に反復最適化に依存しており、その結果、計算コストが高くなります。近年、この分野は徐々に、フィードフォワードニューラルネットワークに基づくエンドツーエンドのジオメトリ再構築モデルへと移行しています。
大きな成果にもかかわらず、既存の方法には入力と出力の両方の側面において依然として明らかな限界があります。入力側では、現在のモデルは生の画像のみを処理するため、カメラの内部特性、初期ポーズ、センサーの深度などのすぐに利用できる事前情報を利用することができません。その結果、スケールの曖昧さ、複数の視点間の不一致、テクスチャのない領域といった問題への対応において、性能が低下します。出力面では、既存の手法は主に単一または少数の幾何学的タスク(深度推定や姿勢推定など)に限定されており、高度に専門化され、統合性に欠けています。VGGTなどの研究はタスクの統合を促進してきましたが、法線推定や新規視点の合成といった基本的なタスクは、まだ統一されたフレームワークに組み込まれていません。
前述の制限から、重要な疑問が生じます。多様な事前情報を効果的に組み込むことで、一般的な 3D 再構築フレームワーク内で入力と出力の両方の課題に同時に対処できるでしょうか。
これに基づいて、Tencent の Hunyuan チームは、汎用的な 3D ジオメトリ予測タスク用の完全に統合されたフィードフォワード モデルである HunyuanWorld-Mirror をリリースしました。このモデルは、利用可能なあらゆるジオメトリの事前知識を活用して、一般的な 3D 再構築タスクを実行するように設計されています。このモデルの核となるのは、カメラの姿勢、内部パラメータ、深度マップといった複数の幾何学的事前情報を柔軟に統合し、同時に複数の3D表現(高密度点群、多視点深度マップ、カメラパラメータ、表面法線、3Dガウス分布)を生成する、革新的なマルチモーダル事前キューイング機構です。この統合アーキテクチャは、利用可能な事前情報を活用して構造的な曖昧さを解消し、単一のフィードフォワードプロセスで幾何学的に一貫性のある3D出力を提供します。
HunyuanWorld-Mirror は、利用可能な事前確率を活用して困難なシナリオでも堅牢な再構築を可能にし、そのマルチタスク設計により、さまざまな出力間での幾何学的一貫性を保証します。カメラ、ポイント マップ、深度および表面法線推定から新しい遠近法の合成まで、幅広いベンチマークにわたって最先端のパフォーマンスが達成されました。
HyperAIのウェブサイトに「HunyuanWorld-Mirror:3Dワールド生成モデル」が掲載されましたので、ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/Ptv69
11月24日から11月28日までのhyper.ai公式ウェブサイトの更新の概要は次のとおりです。
* 高品質の公開データセット: 7
*厳選された高品質なチュートリアル: 6
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
12月締め切りのトップカンファレンス:2
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
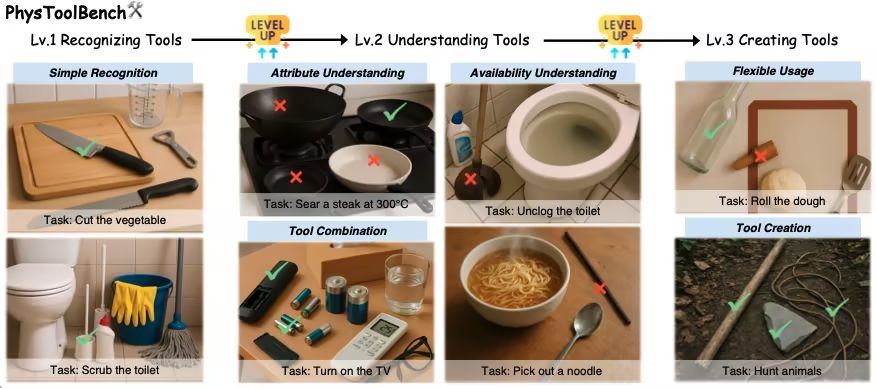
1. PhysToolBench 物理ツールタスクデータセット
PhysToolBenchは、香港科技大学(広州)が香港科技大学、北京航空航天大学、その他の研究機関と共同で公開した視覚言語質問応答(VQA)データセットです。このデータセットは、マルチモーダル大規模言語モデル(MLLM)による物理的な道具の認識、理解、作成能力を評価することを目的としています。このデータセットには1,000以上の画像とテキストのペアが含まれており、日常生活、産業、野外活動、専門環境など、様々なシナリオを網羅しています。
直接使用します:https://go.hyper.ai/bP9Ad
2. CytoData 血球画像データセット
CytoData血球画像データセットは、英国ケンブリッジ大学の研究チームによってNature誌に発表された匿名化された血球データセットです。このデータセットには、ケンブリッジのアデンブルック病院で採取された2,904枚の血液塗抹標本が含まれており、合計559,808枚の単一細胞画像が含まれています。このうち4,996枚の画像は、赤芽球や好酸球を含む10種類の血球でラベル付けされています。
直接使用します:https://go.hyper.ai/uLXKt
3. MeshCoder: 構造化3Dオブジェクトコードデータセット
MeshCoderは、上海人工知能研究所が清華大学、ハルビン理工大学(深圳)などの研究機関と共同で公開した、3Dポイントクラウドから編集可能なコードを生成するためのマルチモーダルデータセットです。3Dシーン解析、構造理解、プログラム可能な幾何学的再構成における大規模言語モデルの開発を促進することを目的としています。
直接使用します:https://go.hyper.ai/x3zvv
4. Netflix 映画とテレビ番組カタログデータセット
Netflix映画・テレビ番組カタログデータセットは、世界中の複数の国から集められた様々な種類の映画やテレビ番組コンテンツを網羅した包括的なカタログデータセットです。Netflixプラットフォームにおけるコンテンツ配信の全体像を示すとともに、エンターテインメントのトレンド、視聴者の嗜好、コンテンツ戦略に関する調査のためのデータサポートを提供することを目的としています。このデータセットには、Netflixで既に配信中の映画やテレビ番組のエントリが含まれています。各エントリはタイトルを表し、タイトル、コンテンツの種類(映画またはテレビ番組)、監督などの重要な情報が含まれています。
直接使用します:https://go.hyper.ai/8gzcZ
5. InteractMove 3Dシーン ヒューマン・オブジェクト・インタラクション・データセット
InteractMoveは、北京大学コンピュータ科学技術研究所と北京電子科学技術研究所が共同で公開した、3Dシーンにおける人間と物体のインタラクションを生成するためのデータセットです。テキストベースの制御に基づく可動物体のインタラクティブモデリングに関する研究を支援・促進することを目的としています。このデータセットは、複数種類の可動物体と様々な実世界のスキャンシーンをカバーし、シーンに厳密に整合した人間と物体のインタラクション動作シーケンスを提供します。
直接使用します:https://go.hyper.ai/uFrPd
6. GroundCUAインターフェース操作訓練データセット
GroundCUAは、ミラ・ケベック人工知能研究所がマギル大学、モントリオール大学、その他の機関と共同で公開した実世界のユーザーインターフェース(UI)データセットです。コンピュータとインタラクション可能なマルチモーダル知能エージェントの研究を支援することを目的としています。このデータセットは、専門家レベルの人間によるデモンストレーションに基づいて構築されており、356万件を超える要素レベルの注釈が手動で検証されています。
直接使用します:https://go.hyper.ai/5bDrX
7. カメラクローンマルチビューデータセット
香港大学が浙江大学、快手科技などの研究機関と共同で公開した「カメラクローン」は、Unreal Engine 5レンダリングをベースとした大規模な合成動画データセットです。シーンの内容を変えずに参照動画のカメラモーションを再現するカメラクローン学習を支援することで、「コンテンツ再現+カメラモーションマッチング」を実現します。
直接使用します:https://go.hyper.ai/US4nY
選択された公開チュートリアル
1. PyTorch公式チュートリアル: PyTorchでディープラーニングを実装する
このチュートリアルの目的は、PyTorch でテンソルを使用してニューラル ネットワークを構築する方法を理解し、小さなニューラル ネットワークをトレーニングして画像を分類することです。
オンラインで実行:https://go.hyper.ai/Fb2c6
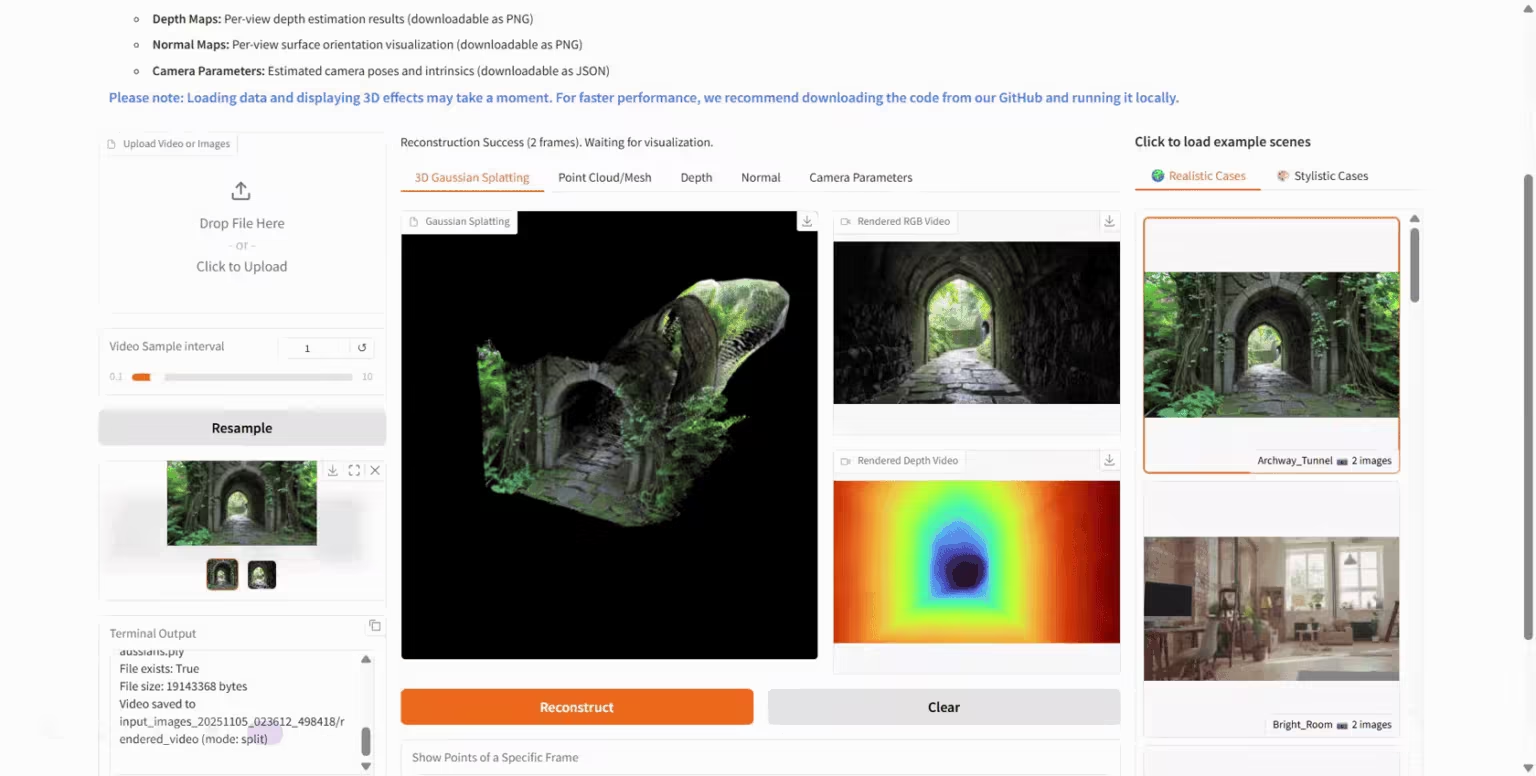
2. HunyuanWorld-Mirror:3D世界生成モデル
HunyuanWorld-Mirrorは、テンセントのHunyuanチームがリリースしたオープンソースの3D世界生成モデルです。マルチビュー画像や動画を含む複数の入力方法をサポートし、点群、深度マップ、カメラパラメータなど、様々な3D幾何学的予測結果を出力できます。このモデルは純粋なフィードフォワードアーキテクチャを採用し、単一のグラフィックカードに展開可能で、8~32ビューの入力をわずか1秒でローカル処理し、第2レベルの推論を実現します。
オンラインで実行:https://go.hyper.ai/Ptv69
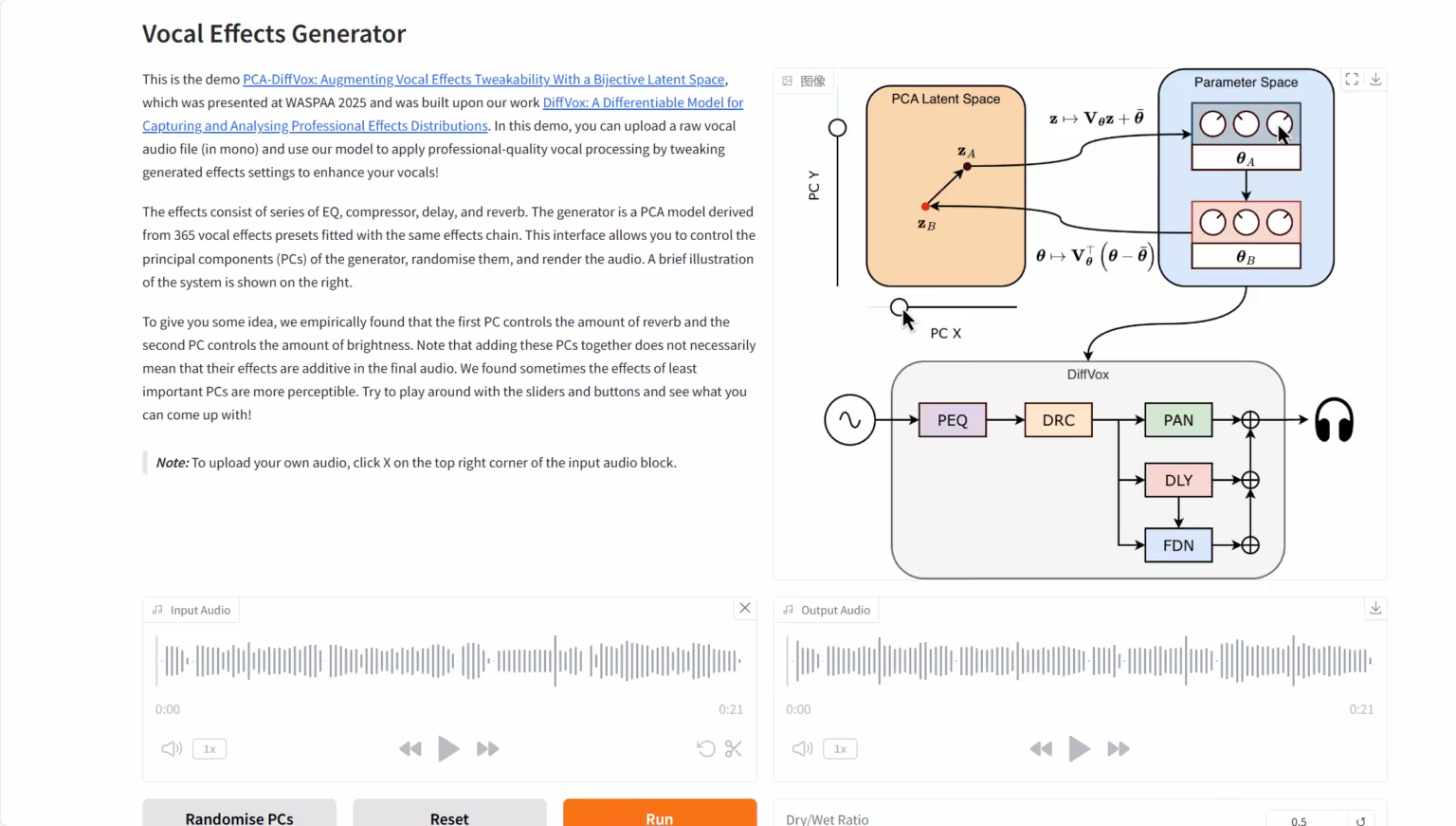
3. DiffVox: 音の差別化モデル
DiffVoxプロジェクトは、ソニーAI、ソニーグループ、そしてロンドン大学クイーン・メアリー校の研究チームによって共同で立ち上げられました。このモデルの核となる機能は、高度な推論時間最適化手法と革新的なガウス事前制約の導入にあります。これにより、生の人間の音声録音を、ターゲットリファレンスに聴感上近い高品質なオーディオへとインテリジェントに変換し、パラメータに関してはプロフェッショナルなミキシング基準を満たすことが可能になります。
オンラインで実行:https://go.hyper.ai/Y19Wv
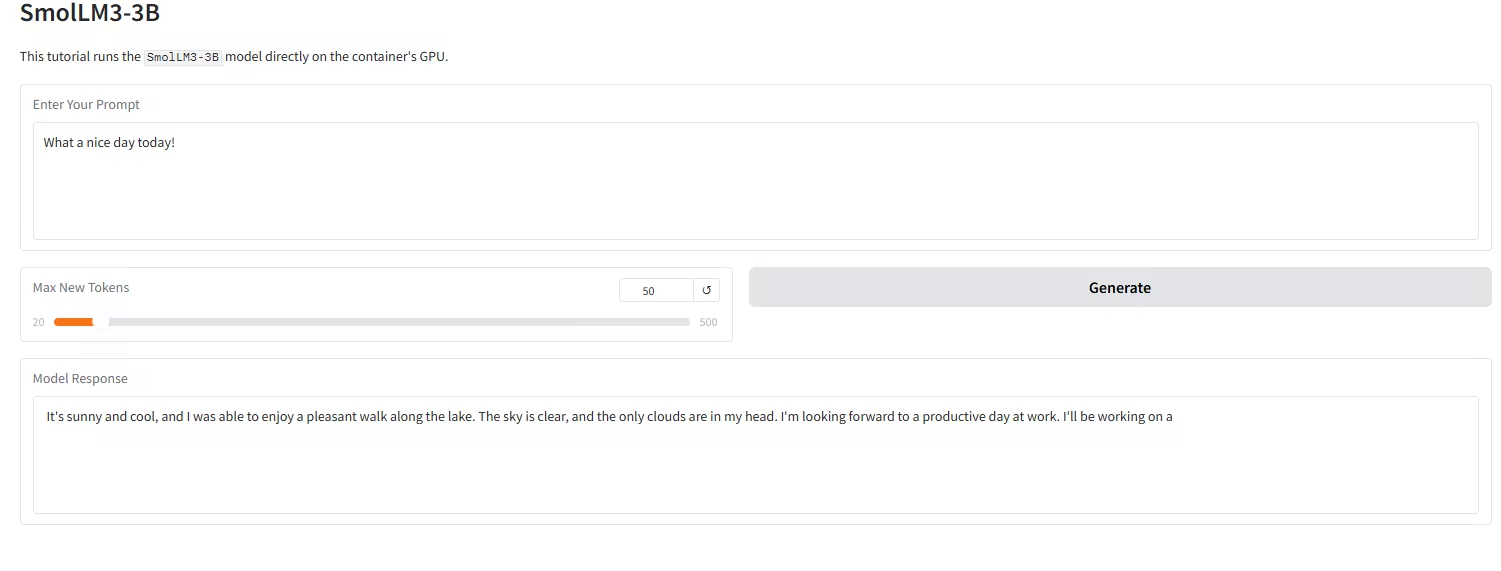
4. SmolLM3-3Bモデルのワンクリック展開
Hugging Face TB(Transformer Big)チームがリリースしたSmolLM3-3Bは、「エッジ性能の限界」と位置付けられています。30億のパラメータを持つ革新的なオープンソース言語モデルであり、コンパクトな3Bサイズで小型モデルの性能限界を突破することを目指しています。
オンラインで実行:https://go.hyper.ai/wZ48d
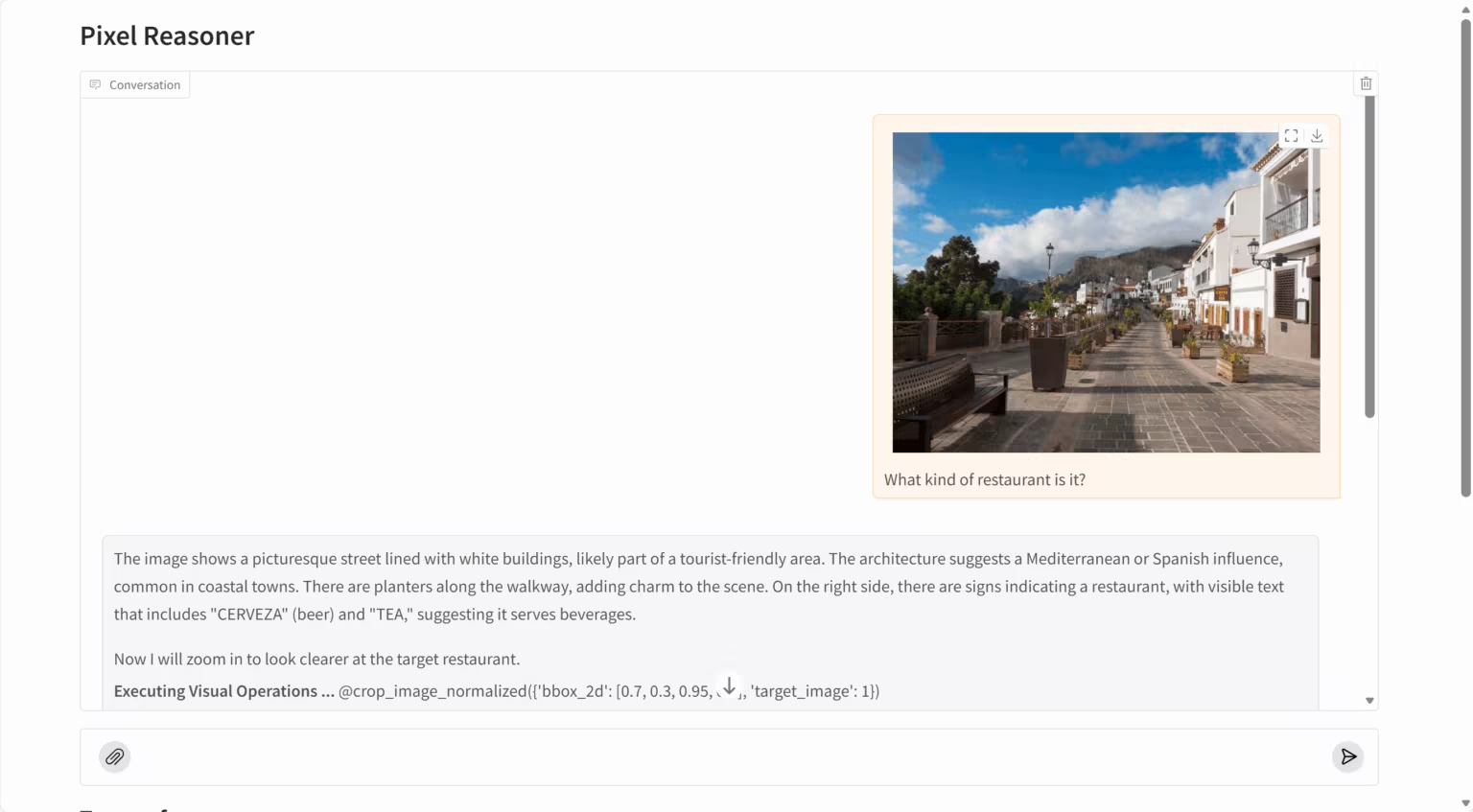
5. PixelReasoner-RL: ピクセルレベルの視覚推論モデル
PixelReasoner-RL-v1は、TIGER AI Labが発表した画期的な視覚言語モデルです。Qwen2.5-VLアーキテクチャをベースとするこのプロジェクトは、革新的な好奇心主導型強化学習トレーニング手法を用いることで、テキストベースの推論のみに依存する従来の視覚言語モデルの限界を克服します。このモデルはピクセル空間内で直接推論を実行できるため、スケーリングやフレーム選択などの視覚操作をサポートし、画像の詳細、空間関係、動画コンテンツの理解能力を大幅に向上させます。
オンラインで実行:https://go.hyper.ai/t1rdr
6. Krea-realtime-video: リアルタイムビデオ生成モデル
Krea Realtime 14Bは、Kreaチームがリリースした140億パラメータのリアルタイム動画生成モデルです。リアルタイムの長編動画生成を可能にし、公開されているリアルタイム動画生成モデルの中でも最大級の規模を誇ります。Wan 2.1 14Bテキスト動画変換モデルをベースにしたこのモデルは、自己強制蒸留学習を用いて従来の動画拡散モデルを自己回帰構造に変換することで、真にリアルタイムな動画生成体験を実現します。
オンラインで実行:https://go.hyper.ai/GS7oW

今週のおすすめ紙
1. 深い研究による一般的なエージェント記憶
本論文では、General Agentic Memory(GAM)と呼ばれる新しいフレームワークを提案します。このフレームワークは「Just-In-Time」(JIT)原則に基づき、オフラインでは単純だが実用的なメモリのみを保持し、実行時にはクライアント向けに最適化されたコンテキストの構築に重点を置きます。実験的研究により、GAMは既存のメモリシステムと比較して、様々なメモリベースのタスク完了シナリオにおいて大幅なパフォーマンス向上を実現することが実証されています。
論文リンク:https://go.hyper.ai/sA1RN
2. ROOT: ニューラルネットワークトレーニングのための堅牢な直交化最適化器
本論文では、二重のロバスト性メカニズムによって訓練の安定性を大幅に向上させるロバストな直交化最適化器ROOTを提案する。広範な実験結果により、ROOTはノイズの多い環境や非凸最適化シナリオにおいて、大幅に向上したロバスト性を示すことが実証されている。MuonベースやAdamベースの最適化器と比較して、ROOTは収束が速いだけでなく、最終的な性能も優れている。
論文リンク:https://go.hyper.ai/gv0x2
3. GigaEvo: LLMと進化アルゴリズムを搭載したオープンソースの最適化フレームワーク
本論文では、AlphaEvolveに着想を得たハイブリッドLLM進化計算手法に関する研究と実験を支援するために設計された、スケーラブルなオープンソースフレームワークであるGigaEvoを提案します。GigaEvoシステムは、MAP-Elites品質多様性アルゴリズム、有向非巡回グラフ(DAG)に基づく非同期評価パイプライン、洞察力に富んだ生成機能を備えたLLM駆動型突然変異演算子、双方向系統追跡メカニズムといった複数のコアコンポーネントをモジュール形式で実装し、柔軟なマルチアイランド進化戦略もサポートします。
論文リンク:https://go.hyper.ai/jN3Q1
4. SAM 3: あらゆるものを概念でセグメント化する
本論文では、概念プロンプトに基づいて画像や動画内のオブジェクトを検出、セグメント化、追跡できる統合モデルであるSegment Anything Model (SAM) 3を提案します。SAM 3は、画像および動画のPCSタスクにおいて既存システムの2倍の精度を達成し、視覚セグメンテーションタスクにおいては前世代のSAMのパフォーマンスを向上させます。SAM 3は現在オープンソース化されており、プロンプトに基づく概念セグメンテーションの新しいベンチマークであるSegment Anything with Concepts (SA-Co)もリリースされています。
論文リンク:https://go.hyper.ai/KN3g7
5. OpenMMReasoner: オープンで汎用的なレシピでマルチモーダル推論の限界を押し広げる
本論文では、教師ありファインチューニング(SFT)と強化学習(RL)を組み合わせた、完全に透過的な2段階マルチモーダル推論学習スキームであるOpenMMReasonerを紹介します。SFT段階では、研究者らは874,000サンプルを含むコールドスタートデータセットを構築し、段階的な厳密な検証メカニズムを用いて推論能力の強固な基盤を構築しました。続くRL段階では、複数のドメインをカバーする74,000サンプルのデータセットを用いてこれらの能力をさらに強化・安定化し、より堅牢で効率的な学習プロセスを実現します。
論文リンク:https://go.hyper.ai/OfXKY
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. 初のマルチモーダル天文学基盤モデル「AION-1」誕生!カリフォルニア大学バークレー校をはじめとする研究機関が、2億個の天文ターゲットを用いた事前学習に基づく汎用マルチモーダル天文学AIフレームワークの構築に成功しました。
カリフォルニア大学バークレー校、ケンブリッジ大学、オックスフォード大学など、世界中の10以上の研究機関のチームが協力し、天文学における初の大規模マルチモーダル基礎モデルファミリーであるAION-1を打ち上げました。統合された初期核融合バックボーンネットワークを通じて、画像、スペクトル、星カタログデータといった異種の観測情報を統合・モデル化します。ゼロショットシナリオにおいて優れた性能を発揮するだけでなく、線形検出精度は特定のタスク向けに特別に訓練されたモデルに匹敵、あるいは凌駕することもあります。
レポート全体を表示します。https://go.hyper.ai/2zA0f
2. Meituan のオープンソース ビデオ生成モデル LongCat-Video は、テキストベースのビデオ生成、画像ベースのビデオ生成、ビデオ継続という 3 つの主要機能を備えており、トップレベルのオープンソース モデルやクローズドソース モデルに匹敵します。
Meituanは最新の動画生成モデル「LongCat-Video」をオープンソース化しました。このモデルは、テキストから動画への変換、画像から動画への変換、動画の連続再生など、様々な動画生成タスクを統一されたアーキテクチャで処理することを目指しています。一般的な動画生成タスクにおける卓越したパフォーマンスに基づき、研究チームはLongCat-Videoが真の「世界モデル」構築に向けた確かな一歩であると考えています。
レポート全体を表示します。https://go.hyper.ai/b6pzF
3. CPU 使用料無料 / GPU 使用クレジット 30 時間 / 70 GB の超大容量ストレージ、HyperAI Pro が正式にリリースされました!
HyperAIは、数百もの機械学習チュートリアルをJupyter Notebookにまとめ、初心者から経験豊富なエンジニアまで、高品質なオープンソースプロジェクトに簡単にアクセスしたり、全く新しいモデルを作成してデプロイしたりできるようにしています。HyperAIは、AIプロジェクトを初期の着想から迅速な導入まで支援する安定したコンピューティングパワーを提供します。ユーザーのニーズにさらに応え、より柔軟で手頃な価格のコンピューティングパワー課金オプションを提供するため、HyperAIはHyperAI Proメンバーシップシステムを正式に開始しました。
レポート全体を表示します。https://go.hyper.ai/Oi7d3
4. ケンブリッジ大学が血液細胞画像分類装置を開発。拡散モデルは白血病の検出に役立ち、臨床専門家の能力を超えています。
英国ケンブリッジ大学の研究チームは、拡散モデルに基づく血球画像分類手法「CytoDiffusion」を提案しました。この手法は、血球の形態分布を忠実にモデル化し、高精度な分類を実現するだけでなく、優れた異常検出能力、分布シフトへの耐性、解釈可能性、高いデータ効率、そして臨床専門家を凌駕する不確実性の定量化能力を備えています。
レポート全体を表示します。https://go.hyper.ai/QSCmq
5. 買収によって会社を築き上げたブロードコムの72歳のCEOは、同社のAI収益を1200億ドルに増やすことを目指し、契約を2030年まで延長した。
ホック・タン氏の経歴を見ると、「合併と買収」は避けて通れないテーマである。しかし、彼を事業投資の観点からのみ見るのは、あまりにも狭く単純すぎる。彼のあらゆる行動は、利益や売上高の計算にとどまらず、会社を徐々に中核的な地位へと押し上げており、その根底にあるトレンド予測はさらに重要だ。
レポート全体を表示します。https://go.hyper.ai/6lPG5
人気のある百科事典の項目を厳選
1. DALL-E
2. ハイパーネットワーク
3. パレートフロント
4. 双方向長短期記憶(Bi-LSTM)
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
12月締め切りのトップカンファレンス

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








