Command Palette
Search for a command to run...
オンラインチュートリアル | NVIDIA が小型モデルを推進: 小型でコンパクトな Nemotron-Nano-9B-v2 は Qwen3 より 6 倍高速

大規模言語モデルが初めて導入されたとき、いつかスマートウォッチに収まるほど小型になる日が来るなんて想像できたでしょうか?今日、この夢は徐々に現実になりつつあります。スマートウォッチなどのデバイスがクラウドからモデルにアクセスし、音声会話やインテリジェントアシスタントを実現しています。しかし、今後の課題は、小型デバイスへの実装だけでなく、軽量でありながらモデルの推論能力と効率性を維持することです。
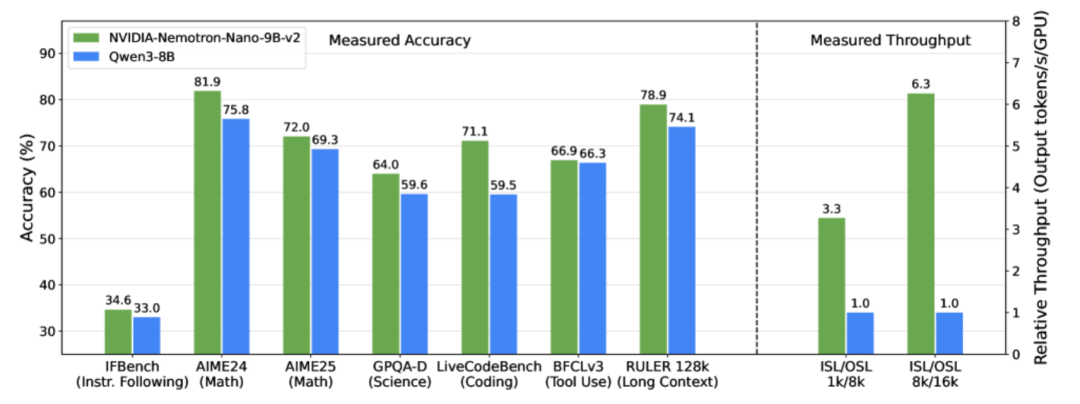
これに対処するため、NVIDIAチームは2025年8月19日に軽量大規模言語モデルNVIDIA-Nemotron-Nano-9B-v2をリリースしました。Nemotronシリーズのハイブリッドアーキテクチャに最適化されたバージョンとして、このモデルは、Mamba の効率的な長いシーケンス処理と Transformer の強力なセマンティック モデリング機能を革新的に組み合わせ、ほとんどの自己注意レイヤーを Mamba-2 状態空間レイヤーに置き換えて、長い推論軌跡を処理する際のモデルを高速化します。わずか90億のパラメータで、128Kという超長コンテキストのサポートを実現しています。複雑な推論ベンチマークでは、同規模の主要なオープンソースモデルであるQwen3-8Bと同等、あるいはそれ以上の精度を達成し、スループットは後者と比較して最大6倍向上しています。これは、大規模言語モデルの軽量展開と長文理解の分野における大きな進歩です。
言い換えれば、Nemotron-Nano-9B-v2 は単なる「小型デバイス内のモデル」以上のものを表しています。代わりに、強力な推論機能を本当に軽量にして、一般の人が利用できるようにすることを目的としています。おそらく将来的には、大規模な言語モデルが「小さく正確な」形で、いつでもどこでも人々にインテリジェントなサービスを提供できるようになるでしょう。
多言語のトレーニング後データセットをリリースして、モデルの機能を包括的に強化します。
研究チームは、単に小規模なモデルを構築するのではなく、12BパラメータのベースラインモデルであるNemotron-Nano-12B-v2-Baseから出発し、大量のキュレーションデータと合成データを用いて事前学習を行いました。さらに、推論能力を強化するために、複数のドメインをカバーするSFTスタイルのデータも追加しました。
その後、チームは、SFT(教師あり微調整)、IFeval RL(指示追跡評価)、DPO(直接選好最適化)、RLHF(人間によるフィードバック強化学習)などの多段階の事後トレーニングを実施し、数学、コード、ツール呼び出し、および長文コンテキストの対話に関してモデルの精度と堅牢性を高めました。関連するトレーニング後のデータセットが更新され、「Nemotron-Post-Training-Dataset-v2」としてリリースされました。SFT および RL データを 5 つのターゲット言語 (スペイン語、フランス語、ドイツ語、イタリア語、日本語) に拡張し、数学、コーディング、STEM (科学、技術、工学、数学)、対話などのシナリオをカバーして、モデルの推論機能とコマンド従属機能を向上させます。
データセットアドレス:
研究チームは、Minitronの圧縮・蒸留戦略に基づき、軽量なニューラルアーキテクチャ探索手法を用いてモデルコンポーネント(各層やフィードフォワードニューラルネットワークなど)の重要度を評価し、それらを枝刈りしました。この蒸留と再学習を通して、研究チームは元のモデルの機能を枝刈りされたモデルへと洗練させました。最終的に、12バイトのモデルを9バイトのNemotron-Nano-9B-v2へと圧縮し、推論精度を維持しながらリソース使用量を大幅に削減しました。
HyperAI Hyperneuron ウェブサイト (hyper.ai) の「チュートリアル」セクションで、「vLLM + Open WebUI を使用した NVIDIA-Nemotron-Nano-9B-v2 のデプロイ」が公開されました。この「小さくても精密」な大規模言語モデルとのコミュニケーションをぜひ体験してください!
チュートリアルのリンク:
デモの実行
1. ブラウザにhyper.aiのURLを入力します。ホームページにアクセスしたら、「チュートリアル」ページをクリックし、「vLLM + Open WebUI」を選択してNVIDIA-Nemotron-Nano-9B-v2をデプロイし、「このチュートリアルをオンラインで実行」をクリックします。
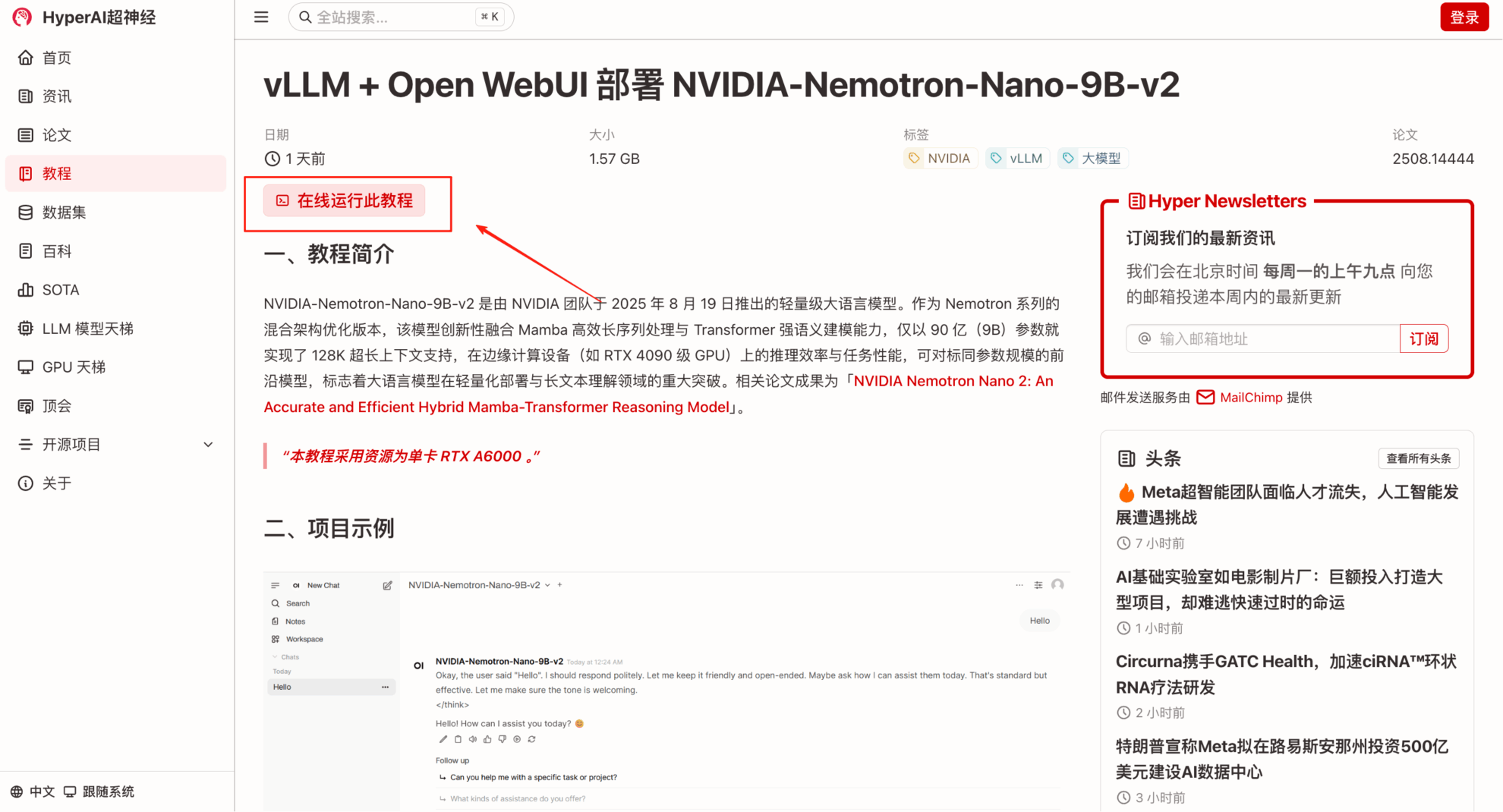
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
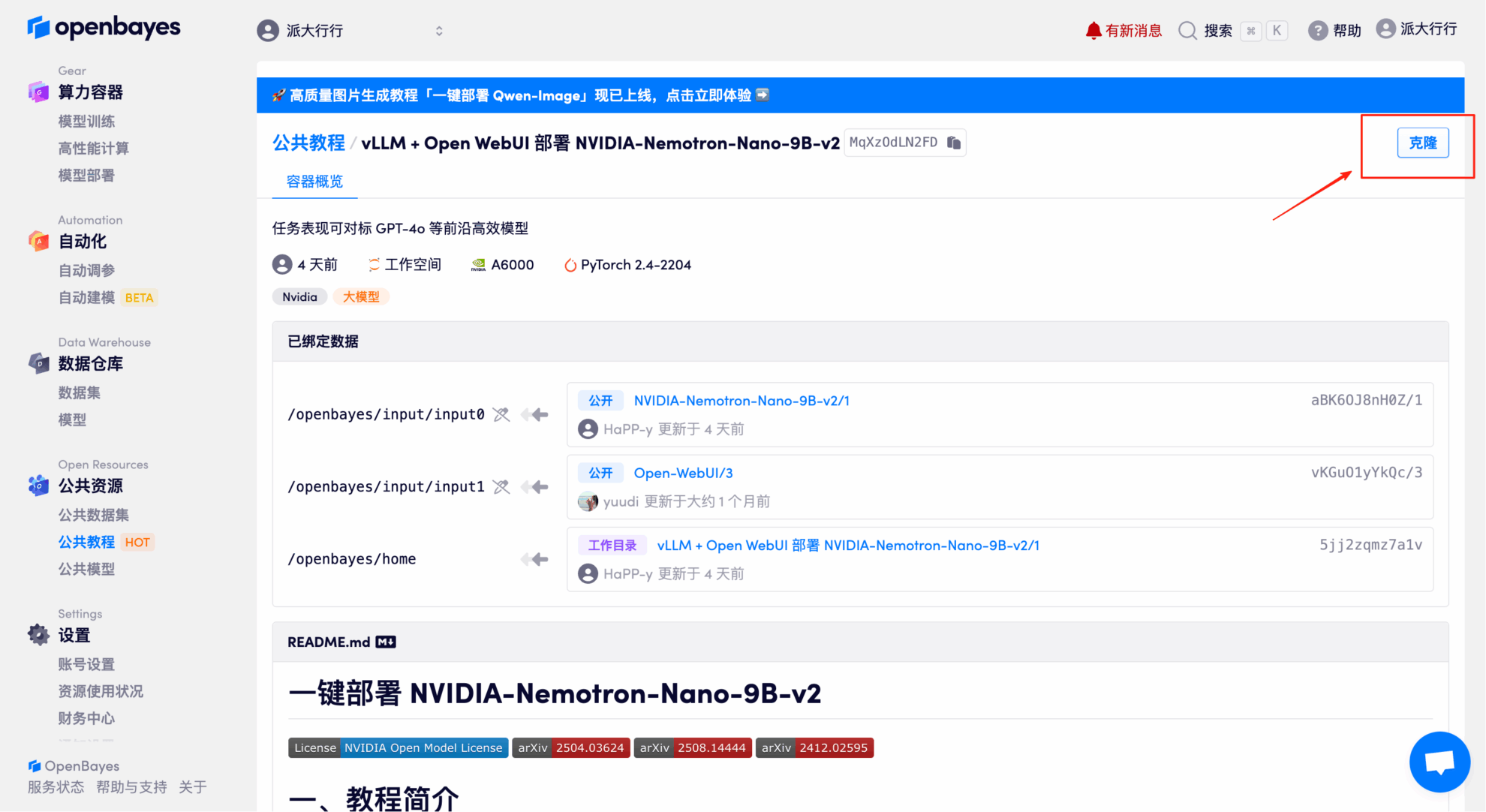
3. NVIDIA RTX A6000 48GBとPyTorchのイメージを選択し、「続行」をクリックします。OpenBayesプラットフォームでは、従量課金制、日単位/週単位/月単位の4つの課金オプションをご用意しています。新規ユーザーは、以下の招待リンクから登録すると、RTX 4090を4時間分、CPU時間を5時間分無料でご利用いただけます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
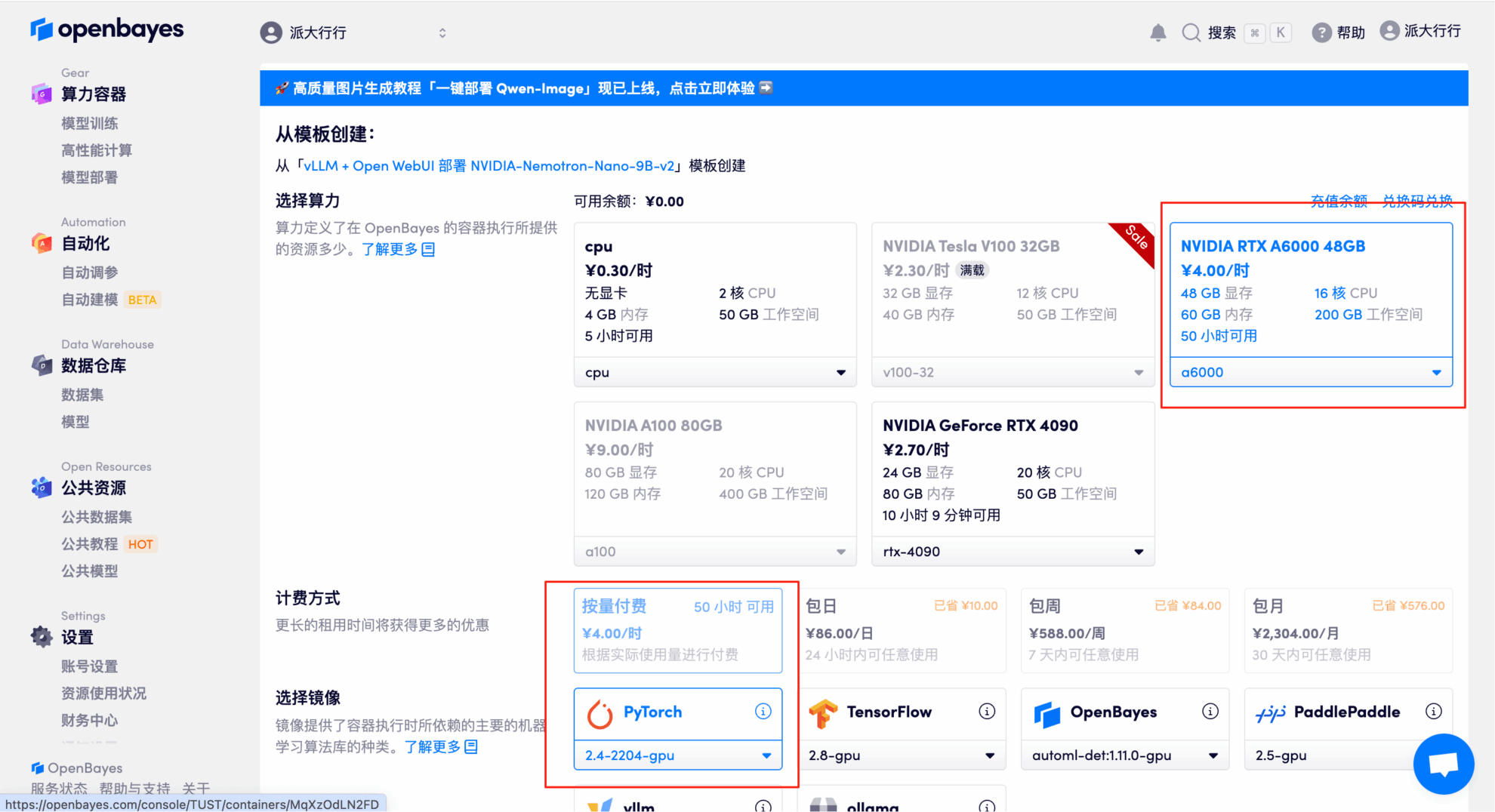
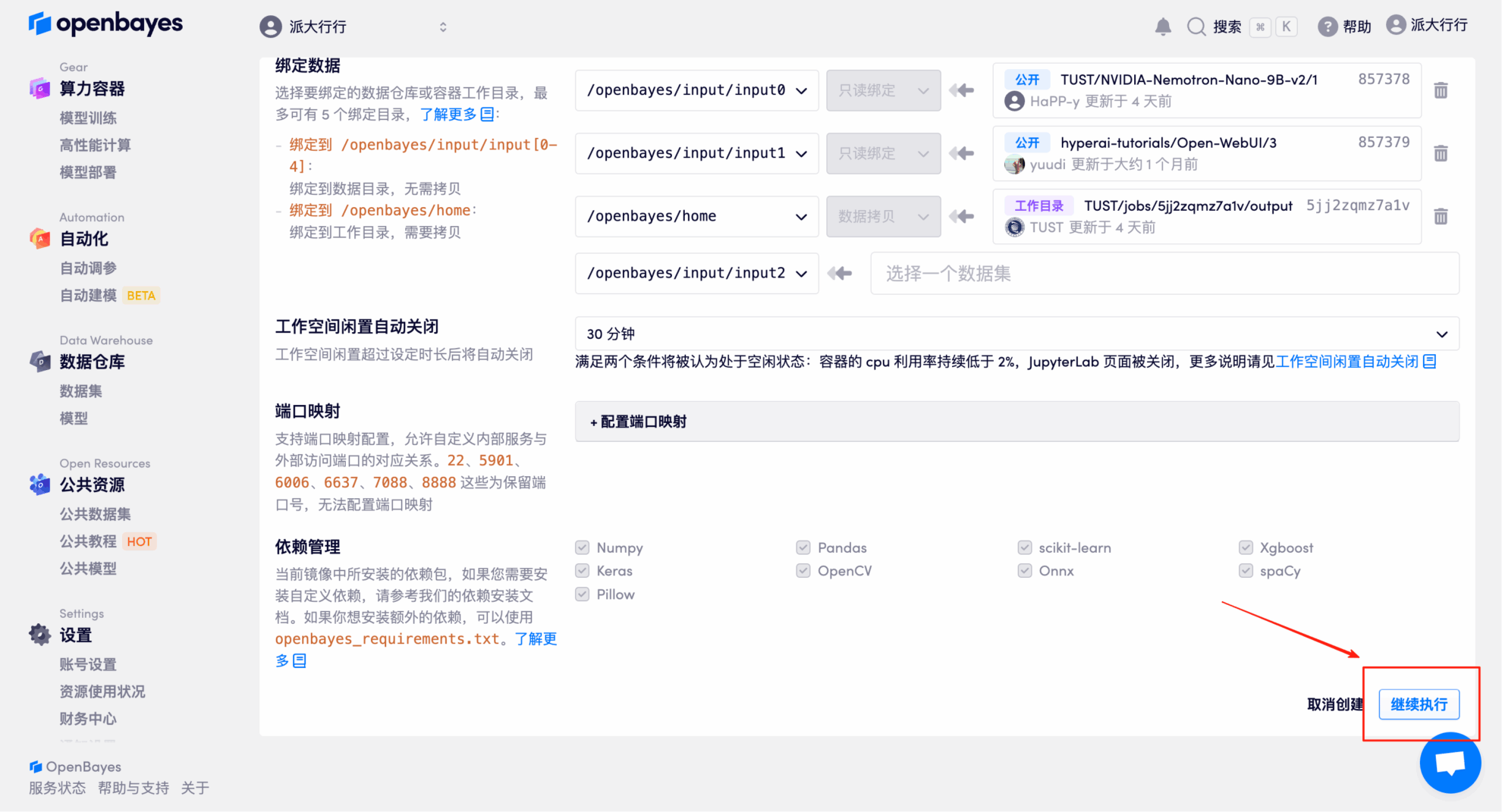
4. リソースが割り当てられるまでお待ちください。最初のクローン作成プロセスには約3分かかります。ステータスが「実行中」に変わったら、「APIアドレス」の横にある矢印をクリックしてデモページに移動します。APIアドレスを使用する前に、実名認証を完了する必要がありますのでご注意ください。
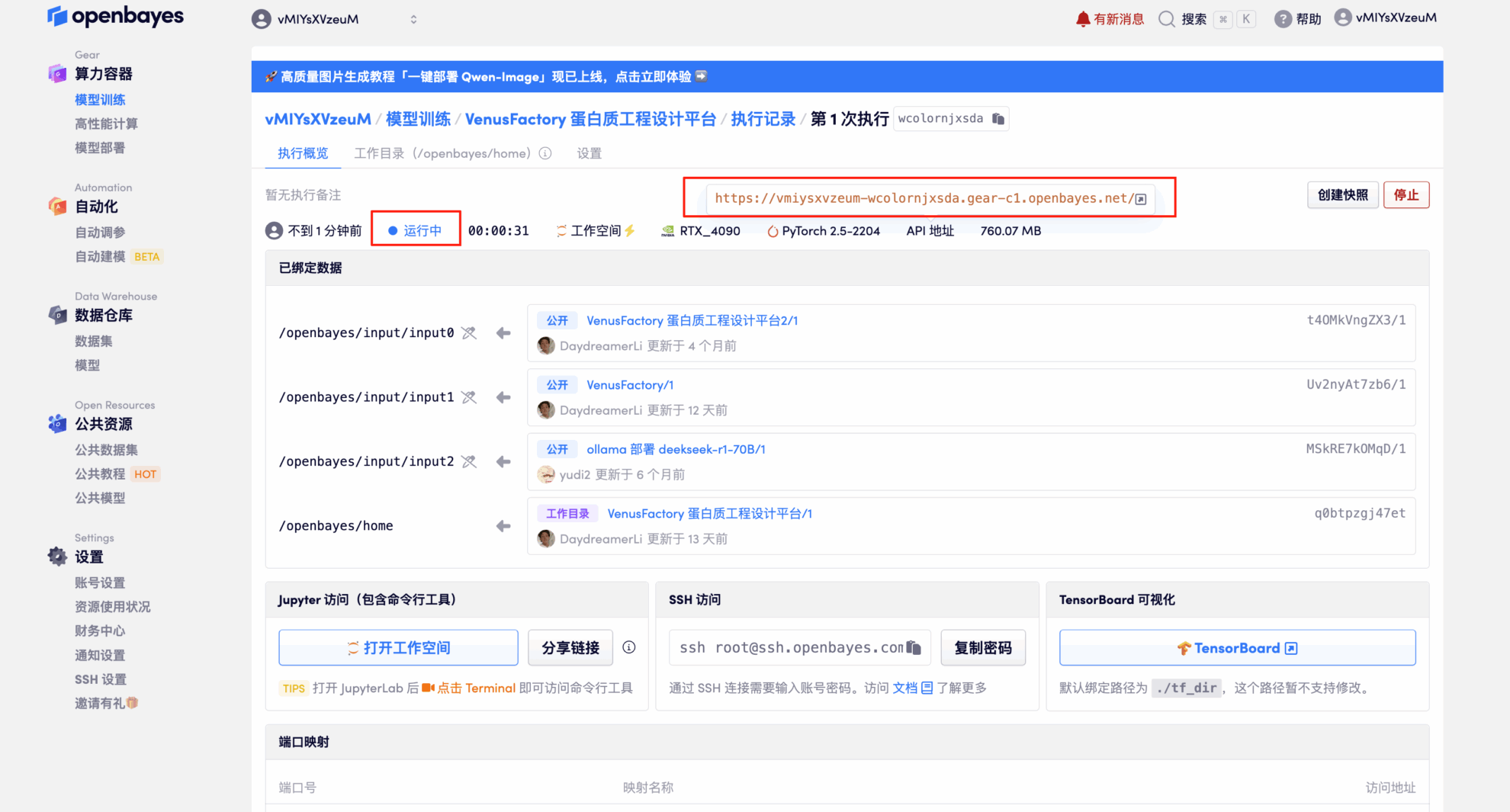
効果実証
デモ実行ページに入ったら、ダイアログ ボックスに「Prompt」と入力して、[実行] をクリックします。
秋が深まると、だんだんと涼しくなってきます。Nemotron-Nano-9B-v2が、初秋を暖かく過ごすためのヒントをご紹介します。



以上が今回HyperAIがおすすめするチュートリアルです。ぜひ皆さんも体験してみてください!
チュートリアルのリンク:
2023年から2024年にかけてのAI4S分野の高品質な論文と詳細な解釈記事をワンクリックで入手⬇️









