Command Palette
Search for a command to run...
LightOnOCR-2-1B: RLVR トレーニングに基づく高精度のエンドツーエンド OCR。Google ストリートビューの全国ストリートビュー画像: 世界クラスの地理マッピング技術に基づくオープンソースのパノラマ画像ライブラリ。

現在、OCR テクノロジーは、最初にテキスト領域が検出され、次に認識が実行され、最後に後処理が実行されるという、複雑な順次パイプラインに依存しています。このモデルは、複雑なレイアウトや多様なフォーマットを持つドキュメントを扱う際には、扱いにくく脆弱です。どのステップでもエラーが発生すると、全体的な結果が悪化する可能性があり、エンドツーエンドの最適化が困難であるため、メンテナンスと適応に多大なコストがかかります。
この文脈では、LightOn は LightOnOCR-2-1B モデルをオープンソースとしてリリースしました。わずか10億パラメータのこのエンドツーエンドのビジョン言語モデルは、権威あるベンチマークOlmOCR-Benchにおいて、90億パラメータの従来の最高モデルを凌駕するSOTA(最先端)性能を達成しました。同時に、サイズは9分の1に縮小し、推論速度は数倍向上しています。LightOnOCR-2-1Bは、統合モデルを用いて、ピクセルから構造化され順序付けられたテキストと画像の境界ボックスを直接生成します。事前学習済みのコンポーネント、高品質の抽出データ、RLVRなどの戦略を統合することで、プロセスを簡素化し、複雑なドキュメントの処理効率を大幅に向上させます。
「LightOnOCR-2-1B 軽量・高性能・エンドツーエンドOCRモデル」がHyperAIウェブサイトで公開されました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/8zlVw
2月2日から2月6日までのhyper.ai公式ウェブサイトの更新の概要は次のとおりです。
* 高品質の公開データセット: 6
* 厳選された高品質のチュートリアル:9
* 今週のおすすめ論文: 5
* コミュニティ記事の解釈:4件
* 人気のある百科事典のエントリ: 5
2月締め切りのトップカンファレンス:4
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. RubricHub マルチドメイン生成タスクデータセット
RubricHubは、Li Autoと浙江大学が共同で公開した、大規模かつマルチドメインの生成タスクデータセットです。このデータセットは、オープンエンドの生成タスクに対するスコアリング基準に基づいた高品質な監督を提供します。このデータセットは、粗いスコアリング基準から細かいスコアリング基準までを自動化するフレームワークを用いて構築されており、原理に基づく統合、マルチモデル集約、難易度進化といった戦略を統合することで、包括的かつ高度な識別力を持つ評価基準を生成します。
直接使用します:https://go.hyper.ai/g3Htm
2. Nemotron-Personas-Brazil ブラジル合成文字データセット
Nemotron-Personas-Brazilは、NVIDIAがWideLabsと共同で公開したブラジルの合成キャラクターデータセットです。ブラジルの人口の多様性と豊かさを示すことで、地域的多様性、民族的背景、教育水準、職業分布など、多次元的な潜在的な人口分布をより包括的に反映することを目的としています。
直接使用します:https://go.hyper.ai/7xKKH
3. CL-benchコンテキスト学習評価ベンチマーク
CL-benchは、テンセント・ハンユアン・チームと復旦大学が共同で公開した、大規模言語モデルのコンテキスト学習能力を評価するためのベンチマークデータセットです。このデータセットは、モデルが事前学習済みの知識に依存せずに、与えられたコンテキストから新しい規則、概念、またはドメイン知識を学習し、後続のタスクに適用できるかどうかをテストすることを目的としています。
直接使用します:https://go.hyper.ai/w2MG3
4. RoVid-X ロボットビデオ生成データセット
RoVid-X は、北京大学が ByteDance Seed と共同でリリースしたロボット ビデオ生成データセットであり、ロボット ビデオを生成する際にビデオ生成モデルが直面する物理的な課題に対処することを目的としています。
直接使用します:https://go.hyper.ai/4P9hI
5. Google ストリートビュー 全国ストリートビュー画像データセット
Googleストリートビューは、複数の国を網羅したストリートビュー画像のデータセットです。画像ファイル名には作成日と地図名が含まれ、各国の画像はそれぞれのフォルダに保存されています。
直接使用します:https://go.hyper.ai/tZRlI

6. DeepPlanning長期計画能力評価データセット
DeepPlanning は、インテリジェント エージェントの計画能力を評価するために Qwen チームによってリリースされたデータセットであり、複雑で長期的な計画タスクにおける推論および意思決定能力を評価することを目的としています。
直接使用します:https://go.hyper.ai/yywsb
選択された公開チュートリアル
1. vLLM-Omniを使用してQwen-Image-Editをデプロイする
Qwen-Image-Editは、アリババのTongyi Qianwenチームがリリースした多機能画像編集モデルです。セマンティック編集機能とビジュアル編集機能の両方を備え、要素の追加、削除、変更といった低レベルのビジュアルアピアランス編集から、IP作成、オブジェクトの回転、スタイル転送といった高レベルのビジュアルセマンティック編集まで、幅広い編集が可能です。中国語と英語のテキストを正確に編集できるため、画像内のテキストコンテンツを直接変更しながらも、元のフォント、サイズ、スタイルを維持することができます。
オンラインで実行:https://go.hyper.ai/DowYs
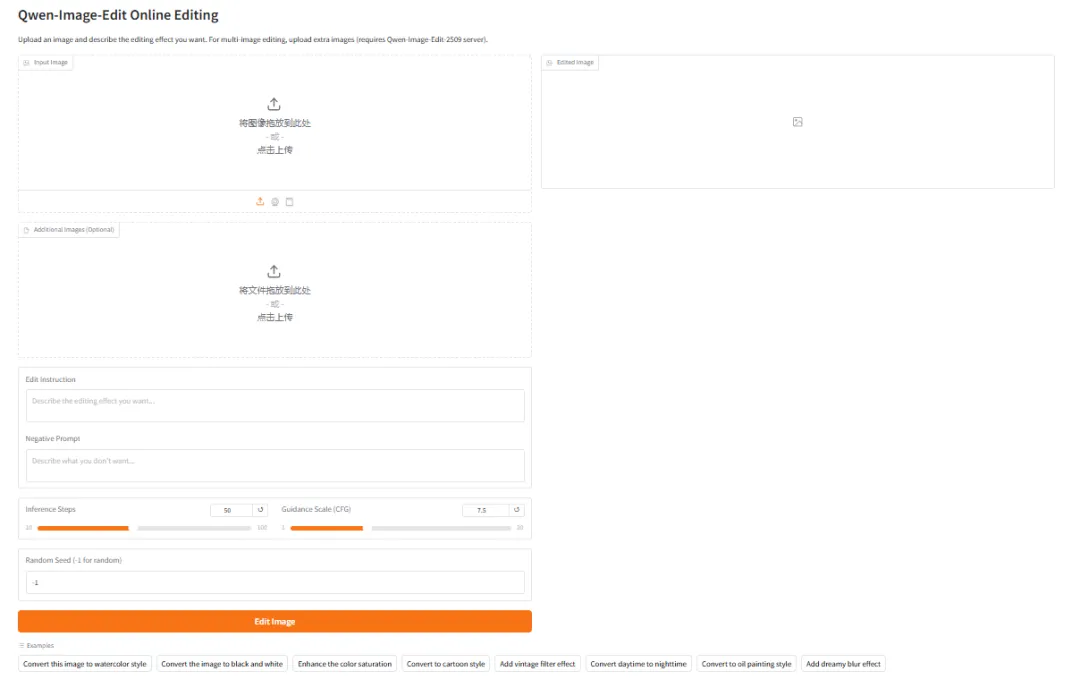
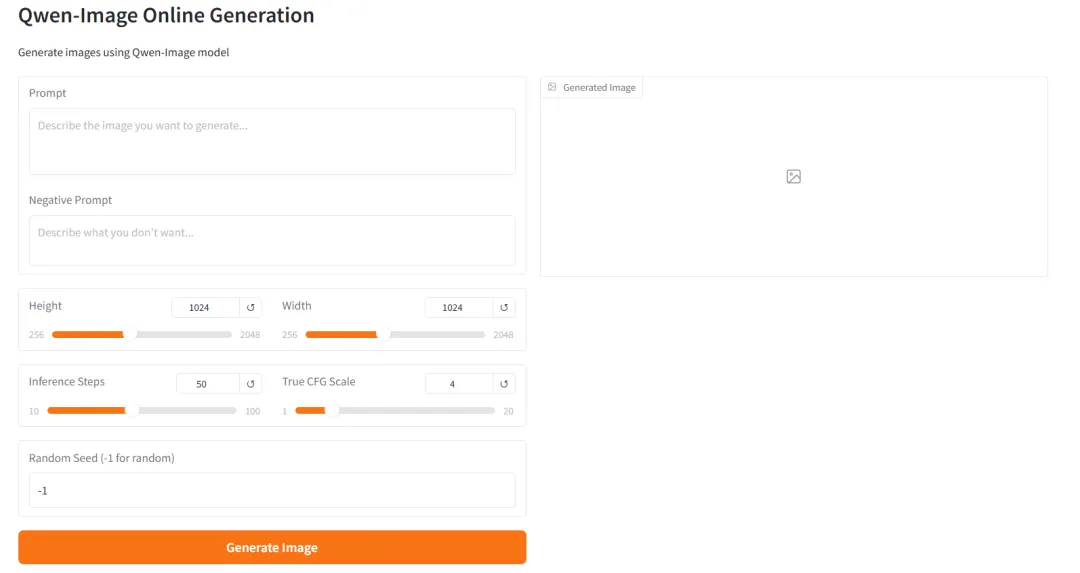
2. vLLM-Omniを使用してQwen-Image-2512をデプロイする
Qwen-Image-2512は、Qwen-Imageシリーズの基盤となるテキスト画像変換モデルです。以前のバージョンと比較して、Qwen-Image-2512はいくつかの主要な側面において体系的な最適化が行われ、生成される画像の全体的なリアリティと使いやすさの向上に重点が置かれています。ポートレート生成の自然さが大幅に向上し、顔の構造、肌の質感、照明の関係が、よりリアルな写真効果に近づきました。自然風景において、このモデルはより詳細な地形テクスチャ、植生の詳細、動物の毛皮などの高頻度情報を生成できます。同時に、テキスト生成とタイポグラフィ機能も向上し、読みやすいテキストと複雑なレイアウトをより安定して表示できるようになりました。
オンラインで実行:https://go.hyper.ai/Xk93p
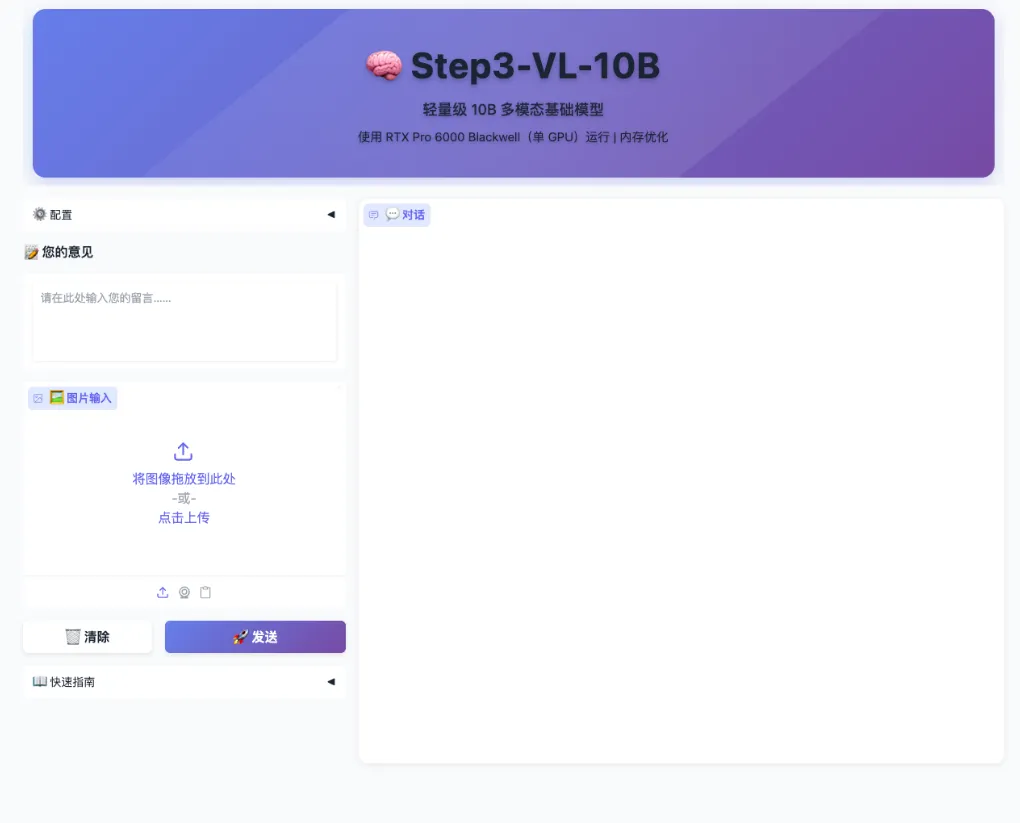
3. ステップ3-VL-10B: マルチモーダル視覚理解とグラフィカル対話
STEP3-VL-10Bは、Stepping Starチームによって開発されたオープンソースの視覚言語モデルであり、マルチモーダル理解と複雑推論タスク向けに特別に設計されています。このモデルは、100億(10B)という限られたパラメータスケール内で、効率性、推論能力、視覚理解の質のバランスを再定義することを目的としています。視覚知覚、複雑推論、そして人間の指示の整合において優れた性能を示し、複数のベンチマークテストにおいて同規模のモデルを一貫して上回り、一部のタスクでは10~20倍のパラメータスケールを持つモデルに匹敵する性能を示しました。
オンラインで実行:https://go.hyper.ai/ZvOV0
4.vLLM+GLM-4.7-Flash の Open WebUI 展開
GLM-4.7-Flashは、Zhipu AIがリリースした軽量MoE推論モデルで、高性能と高スループットのバランスを実現するように設計されています。思考連鎖、ツール呼び出し、エージェント機能をネイティブにサポートしています。ハイブリッドエキスパートアーキテクチャを採用し、スパースアクティベーションメカニズムを活用することで、大規模モデルのパフォーマンスを維持しながら、単一の推論における計算オーバーヘッドを大幅に削減します。
オンラインで実行:https://go.hyper.ai/bIopo

5. LightOnOCR-2-1B 軽量・高性能エンドツーエンドOCRモデル
LightOnOCR-2-1Bは、LightOn AIがリリースした最新世代のエンドツーエンド視覚言語認識(OCR)モデルです。LightOnOCRシリーズのフラッグシップモデルとして、文書理解とテキスト生成をコンパクトなアーキテクチャに統合し、10億個のパラメータを誇り、コンシューマーグレードのGPU(約6GBのVRAM必要)で動作可能です。このモデルは、視覚言語Transformerアーキテクチャを採用し、RLVR学習技術を組み込むことで、非常に高い認識精度と推論速度を実現しています。複雑な文書、手書きテキスト、LaTeX数式の処理を必要とするアプリケーション向けに特別に設計されています。
オンラインで実行:https://go.hyper.ai/8zlVw
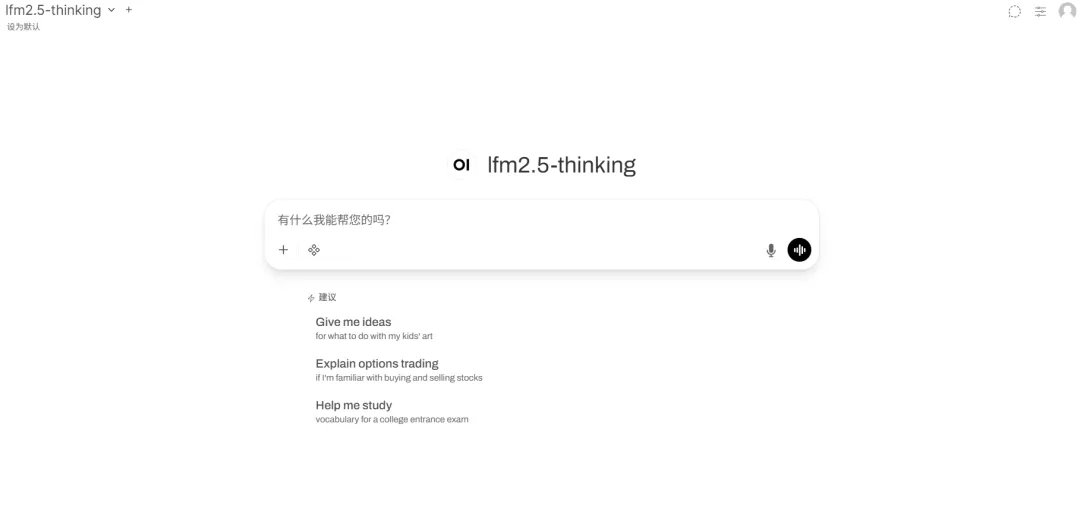
6.vLLM+Open WebUI LFM2.5-1.2B-Thinkingの展開
LFM2.5-1.2B-Thinkingは、Liquid AIがリリースした最新のエッジ最適化ハイブリッドアーキテクチャモデルです。論理推論に特化して最適化されたLFM2.5シリーズのバージョンとして、長シーケンス処理と効率的な推論機能をコンパクトなアーキテクチャに統合しています。このモデルは12億個のパラメータを備え、コンシューマーグレードのGPUだけでなく、エッジデバイスでもスムーズに動作します。革新的なハイブリッドアーキテクチャを採用し、極めて高いメモリ効率とスループットを実現し、インテリジェンスを犠牲にすることなく、デバイス上でリアルタイム推論を必要とするシナリオ向けに設計されています。
オンラインで実行:https://go.hyper.ai/PACIr
7. TurboDiffusion: 画像とテキスト駆動型ビデオ生成システム
TurboDiffusionは、清華大学のチームによって開発された高効率な動画拡散生成システムです。2.1アーキテクチャをベースとするこのプロジェクトは、高階蒸留法を用いることで、大規模動画モデルにおける推論速度の遅さと計算リソースの消費量の増加といった問題点を解決し、最小限のステップで高品質な動画生成を実現します。
オンラインで実行:https://go.hyper.ai/YjCht
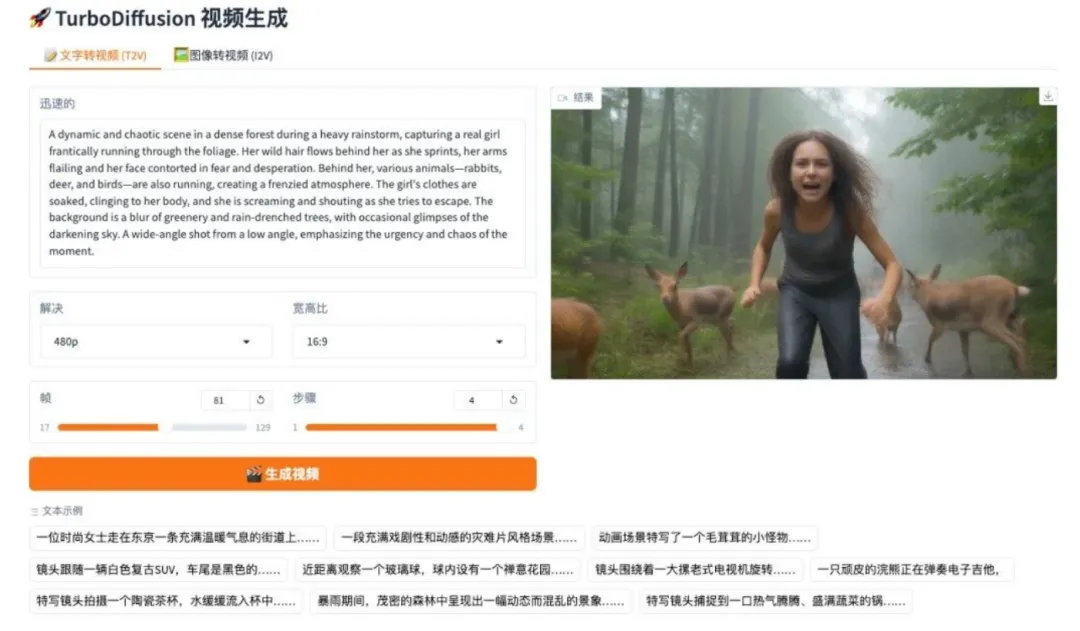
8. DeepSeek-OCR 2 ビジュアル因果フロー
DeepSeek-OCR 2は、DeepSeekチームがリリースした第2世代OCRモデルです。DeepEncoder V2アーキテクチャを導入することで、固定スキャンからセマンティック推論へのパラダイムシフトを実現しています。このモデルは、因果ストリームクエリとデュアルストリームアテンションメカニズムを採用し、視覚トークンを動的に並べ替えることで、複雑な文書の自然な読み取りロジックをより正確に再構築します。OmniDocBench v1.5評価では、このモデルは総合スコア91.09%を達成し、前モデルから大幅に向上しました。また、OCR結果の繰り返し率も大幅に低減し、将来のフルモーダルエンコーダー構築への新たな道筋を示しています。
オンラインで実行:https://go.hyper.ai/ITInm
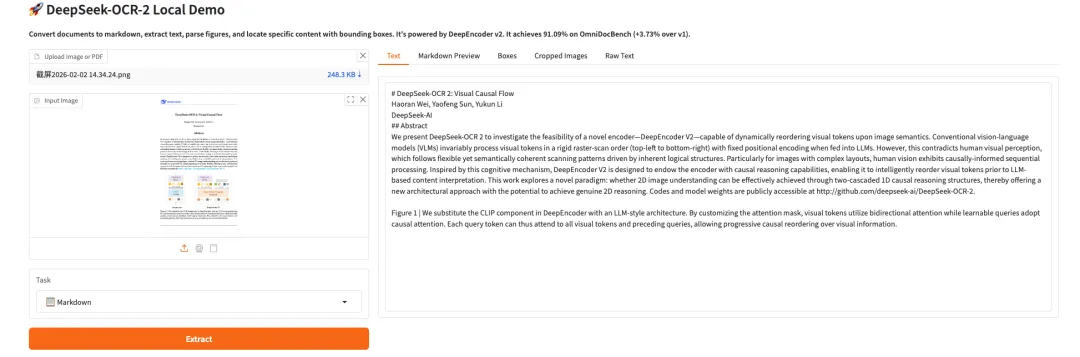
9. Personaplex-7B-v1: リアルタイム対話とキャラクターカスタマイズ音声インターフェース
PersonaPlex-7B-v1は、NVIDIAがリリースした70億パラメータのマルチモーダル・パーソナライズ対話モデルです。リアルタイムの音声/テキストインタラクション、長期的なペルソナ一貫性シミュレーション、マルチモーダル知覚タスク向けに設計されており、ミリ秒レベルの応答速度を備えた没入型ロールプレイングおよびマルチモーダルインタラクションのデモンストレーションシステムを提供することを目指しています。
オンラインで実行:https://go.hyper.ai/ndoj0
今週のおすすめ紙
1. 協調型マルチエージェントテスト時強化学習による推論
本論文では、MATTRL(テスト時強化学習フレームワーク)を提案する。MATTRLは、構造化されたテキスト経験を推論プロセスに注入することで、マルチエージェント推論を強化する。MATTRLは、複数の専門家によるチームコラボレーションとラウンドごとのクレジット割り当てを通じて合意形成を実現し、再学習を必要とせずに、医療、数学、教育のベンチマークにおいて堅牢なパフォーマンス向上を実現する。
論文リンク:https://go.hyper.ai/ENmkT
2. A^3-Bench: アンカーとアトラクターの活性化による記憶駆動型科学的推論のベンチマーク
本論文では、メモリ駆動型科学的推論ベンチマークであるA³-Benchを提案する。これは、SAPMアノテーションフレームワークとAAUIメトリクスを用いてアンカーとアトラクターの活性化を評価し、メモリの利用が標準的な一貫性や回答精度を超えて推論の一貫性をどのように向上させるかを明らかにする。
論文リンク:https://go.hyper.ai/Ao5t9
3. PaCoRe: 並列協調推論によるテスト時間計算のスケーリング学習
本論文では、複数ラウンドの並列推論軌跡間のメッセージパッシングを通じてテスト時間計算(TTC)の大幅なスケーリングを実現する並列協調推論フレームワーク、PaCoReを提案する。HMMT 2025において、GPT-5(93.2%)を上回る94.5%の精度を達成した。PaCoReは、固定されたコンテキスト制約内で数百万トークンの推論プロセスを効率的に統合するとともに、モデルとデータをオープンソース化することで、スケーラブルな推論システムの開発を促進する。
論文リンク:https://go.hyper.ai/fQrnt
4. ビデオ生成のためのモーションアトリビューション
本論文では、動きを重視した勾配ベースのデータ属性フレームワークであるMotiveを提案する。これは、動き重み付け損失マスクを用いて、時間的なダイナミクスと静的な外観を分離する。これにより、微調整に影響を与えるセグメントをスケーラブルに認識することが可能になり、テキストから動画への変換における動きの滑らかさと物理的な妥当性が向上する。VPenchにおいて、人間の嗜好勝率は74.11 TP3Tを達成した。
論文リンク:https://go.hyper.ai/2pU21
5. VIBE: ビジュアル指示ベースエディタ
本論文では、20億パラメータのQwen3-VLモデルをガイダンスとして、16億パラメータのSana1.5拡散モデルを生成に用いる、コンパクトな指示ベースの画像編集ワークフローVIBEを提案する。VIBEは、極めて低い計算コストで、ソース画像の一貫性を厳密に維持した高品質な編集を実現する。24GBのGPUメモリ上で効率的に動作し、H100上でわずか4秒程度で2K画像を生成し、より大規模なベースラインモデルと同等かそれ以上の性能を実現する。
論文リンク:https://go.hyper.ai/8YMEO
コミュニティ記事の解釈
1. 欧州宇宙機関は、ハッブル宇宙望遠鏡から3日間で1億のデータポイントを横断した後、AnomalyMatchを提案し、1000を超える異常な天体を発見しました。
現在、マルチバンド、広視野、高深度を特徴とする大規模な天体観測により、天文学はかつてないほどデータ集約的な時代へと突き進んでいます。その中核となる科学的可能性の一つは、特別な天体物理学的価値を持つ希少天体の体系的な発見と特定にあります。しかしながら、これらの発見は長年、研究者による偶然の目視による特定や、市民科学プロジェクトによる手作業によるスクリーニングに大きく依存してきました。これらの方法は、非常に主観的で非効率的であるだけでなく、今後発生する膨大なデータ量にも適していません。この欠陥に対処するため、欧州宇宙機関(ESA)傘下の欧州宇宙天文学センター(ESAC)の研究チームは、AnomalyMatchと呼ばれる新しい手法を提案し、適用しました。
レポート全体を表示します。https://go.hyper.ai/Jm3aq
2. データセットの概要 | 把握、質問応答、論理的推論、軌道推論などの分野をカバーする 16 の具体化されたインテリジェンス データセット。
過去10年間の人工知能の主戦場が「世界を理解する」ことと「コンテンツを生成する」ことであったとすれば、次の段階の核心課題はより挑戦的な命題へと移行しつつあります。それは、AIがいかにして真に物理世界に入り込み、その中で行動し、学習し、進化していくか、という問いです。関連する研究や議論では、「具現化された知能」という用語が頻繁に登場します。その名の通り、具現化された知能は従来のロボットではなく、知覚、意思決定、行動という閉ループの中で、エージェントと環境との相互作用によって形成される知能を重視しています。本稿では、具現化された知能に関連する現在利用可能なすべての高品質データセットを体系的に整理・推奨し、さらなる学習と研究のための参考資料を提供します。
レポート全体を表示します。https://go.hyper.ai/lsCyF
3. オンラインチュートリアル | DeepSeek-OCR 2 の数式/表解析の改善により、低いビジュアルトークンコストで約 4% のパフォーマンス向上を実現
視覚言語モデル(VLM)の開発において、文書OCRは常に複雑なレイアウト解析や意味論的論理の整合といった中核的な課題に直面してきました。モデルが人間のように視覚論理を「理解」できるようにする方法は、文書理解能力を向上させる上で重要なブレークスルーとなっています。最近、DeepSeek-AIのDeepSeek-OCR 2は新たな答えを提供します。その核心は、新しいDeepEncoder V2アーキテクチャの採用です。このモデルは従来のCLIP視覚エンコーダを放棄し、LLMスタイルの視覚エンコーディングパラダイムを導入しています。双方向アテンションと因果的アテンションを融合することで、視覚トークンの意味論的再配置を実現し、2D画像理解のための「2段階1D因果推論」という新たな道筋を構築します。
レポート全体を表示します。https://go.hyper.ai/nMH13
4. 天体物理学、地球科学、レオロジー、音響学など 19 のシナリオを網羅する Polymathic AI は、13 億のモデルを構築して、正確な連続媒体シミュレーションを実現します。
科学計算と工学シミュレーションの分野において、複雑な物理システムの進化をいかに効率的かつ正確に予測するかは、常に学界と産業界の両方にとって重要な課題でした。一方、自然言語処理とコンピュータービジョンにおけるディープラーニングのブレークスルーは、研究者たちが物理シミュレーションにおける「基礎モデル」の潜在的な応用を探求するきっかけとなりました。しかし、物理システムは複数の時間的・空間的スケールにわたって進化することが多いのに対し、多くの学習モデルは短期的なダイナミクスのみに基づいて学習されています。長期予測に使用すると、複雑なシステムでは誤差が蓄積され、モデルの不安定性につながります。この状況を踏まえ、Polymathic AI Collaborationの研究チームは、13億個のパラメータとTransformerベースのアーキテクチャを備え、主に流体のような連続体ダイナミクス向けに設計された基礎モデル「Walrus」を提案しました。
レポート全体を表示します。https://go.hyper.ai/MJrny
人気のある百科事典の項目を厳選
1. RRFと組み合わせた逆ソート
2. コルモゴロフ・アーノルド表現定理
3. 大規模マルチタスク言語理解MMLU
4. ブラックボックスオプティマイザー
5. クラス条件付き確率
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








