Command Palette
Search for a command to run...
CUDA の初期チーム メンバーは、cuTile が Triton を「特にターゲットにしている」ことを厳しく批判しました。Tile パラダイムは、GPU プログラミング エコシステムの競争環境を再形成できるでしょうか?

CUDAのリリースから約20年が経った2025年12月、NVIDIAは最新バージョンのCUDA 13.1をリリースしました。その主な変更点は、新しいCUDAタイル(cuTile)プログラミングモデルにあります。GPU カーネル構造は「タイルベース」プログラミング モデルを通じて再編成され、開発者は基盤となる CUDA C++ を直接操作することなく、高性能カーネルを記述できるようになりました。これは間違いなく GPU プログラミング エコシステムにとって注目すべきマイルストーンです。これは、AI 時代のカスタム オペレーターの需要の高まりに対応し、ソフトウェア エコシステムの粘着性をさらに高めるために NVIDIA が立ち上げた新しいレベルの製品である可能性があります。
cuTileは注目を集めるようになってから、カスタム演算子の開発サイクル、Tritonとの直接的な競合、そしてPythonのデフォルトのエントリポイントとなる可能性などについて、開発者コミュニティで急速に議論を巻き起こしました。cuTileはまだ非常に初期段階ですが、現在の開発者からのフィードバックは、既に新たなパラダイムとなる可能性を秘めていることを示唆しています。
関連するエコシステムが徐々に形成されていくにつれ、cuTileの位置付けと可能性はより明確になりつつあります。GitHub、フォーラム、そして社内プロジェクトにおいて、多くのエンジニアがcuTileのコード構成と可読性の向上を肯定し、コミュニティユーザーの中には既存のCUDAコードをcuTileに移行しようとする者もいます。Pythonエコシステムのサポートにより、cuTileはGPUプログラミングの主流のエントリーポイントとなるのでしょうか、それともCUDAとTritonの間に新たな技術的分業を生み出すのでしょうか。今後、より多くの実世界のワークロードが登場するにつれて、これらの答えは徐々に明らかになるかもしれません。
cuTile: 「コード重視」の GPU プログラミング時代の到来
CUDA は長年にわたり、開発者にシングル命令マルチスレッディング (SIMT) のハードウェアおよびプログラミング モデルを提供し、開発者が GPU の並列コンピューティング ロジックを「スレッド」の粒度で記述できるようにしてきました。カーネルは数千のスレッドに分割され、各スレッドは小さな計算セグメントを実行し、スレッドのグループはブロックを形成し、その後ハードウェアがそれらをストリーミング マルチプロセッサ (SM) にマッピングして実行します。
しかし、過去 3 ~ 5 年間のコンピューティング需要、特に AI トレーニングの規模が急激に増加したことにより、このスレッド中心のプログラミングでは、ますます多くのボトルネックが発生するようになりました。研究者やエンジニアは、スレッドスケジューリングを理解するだけでなく、メモリコアレッシング、ワープダイバージェンス、さらにはTensorコアの実行形式まで深く考慮する必要があります。つまり、高性能なCUDAカーネルを作成するには、グラフィックスカードアーキテクチャのあらゆる側面を深く理解する必要があります。そうでなければ、ハードウェアの能力を最大限に活用することは困難です。
cuTile の登場は、このトレンドに対する NVIDIA の回答であり、開発者がアルゴリズムに戻りながら、ハードウェア パフォーマンスの向上をフレームワークに任せることを可能にします。
具体的には、cuTileは、NVIDIA GPU向けの並列プログラミングモデルであり、Pythonベースのドメイン固有言語(DSL)でもあります。高度なハードウェア機能を自動的に活用できます。たとえば、Tensor コアと Tensor メモリ アクセラレータがあり、さまざまな NVIDIA GPU アーキテクチャ間で優れた移植性を維持します。

技術的な観点から言えば、CUDAタイルの基盤はCUDAタイルIR(中間表現)です。これは、ハードウェアをタイルベースでネイティブにプログラミングすることを可能にする仮想命令セットを導入します。開発者は、最小限の変更で複数世代のGPUにわたって効率的に実行できる高レベルコードを記述できます。
NVIDIAの並列スレッド実行(PTX)はSIMTプログラムの移植性を保証しますが、ただし、CUDA Tile IR は CUDA プラットフォームを拡張して、タイルベースのアプリケーションをネイティブにサポートします。開発者は、データ並列プログラムをタイルとタイルブロックに分割することに集中できます。CUDA Tile IRは、これらのタイルをスレッド、メモリ階層、テンソルコアなどのハードウェアリソースにマッピングします。つまり、タイルベースプログラミングでは、開発者はタイルを指定し、それらのタイル上で実行される計算操作を定義するだけでアルゴリズムを記述できます。アルゴリズムの各要素の実行方法を個別に設定する必要はなく、それらの詳細はコンパイラに任せることができます。
NVIDIA は、CUDA 実装から 20 年を経て、なぜプログラミング パラダイムを更新することを選択したのでしょうか?
cuTile のリリースは、CUDA の最初のリリースから約 20 年後に行われました。CUDAは2006年のリリース以来、GPUプログラミングインターフェースから、フレームワーク、コンパイラ、ライブラリ、ツールチェーンを網羅する包括的なエコシステムへと徐々に進化し、現在もNVIDIAのソフトウェアシステムの中核インフラストラクチャとして機能し続けています。NVIDIAが2025年にCUDAを基盤とした新たなプログラミングパラダイムを導入するという決定は、単なる技術進化ではなく、業界環境の変化への直接的な対応です。
一方で、AIワークロードの変化はカスタム演算子の需要を極めて高めており、従来のCUDA C++では開発速度、デバッグコスト、そして人材不足が制約となっています。多くのチームはアルゴリズムを迅速に設計できるものの、短期間で高性能かつ保守性の高いCUDAカーネルを開発することは困難です。cuTileのリリースはまさにこの矛盾を解決するためのものです。パフォーマンスを犠牲にすることなく、Pythonフレンドリーなエントリーポイントを提供することで、より多くの開発者が制御可能なコストでカスタム演算子を構築できるようにすることで、GPUプログラミングの敷居を全体的に下げ、イテレーションサイクルを短縮します。
言い換えると、cuTile は、本格的なオペレータ DSL 戦争が始まる前にプログラミング パラダイムの制御を取り戻すための NVIDIA の初期の戦略的動きです。
一方、「脱NVIDIA化」の潮流の下、GPUソフトウェアエコシステムにおける競争はますます激化しています。AMDはオープンソースのアクセラレーションコンピューティングプラットフォームROCmを立ち上げ、オープンアーキテクチャを通じてより多くのサードパーティライブラリやツールの参加を促し、エコシステムカバレッジを拡大しています。IntelはOneAPIを立ち上げ、アーキテクチャ間で統一されたプログラミングモデルの構築を試み、DPC++などの言語サポートを提供することで、異機種システム開発の複雑さを軽減しています。これらはすべて、CUDAの独占的地位を弱めています。
さらに、AI大規模モデル企業やチップ企業も独自の演算子DSLの開発を競い合っています。OpenAIは2022年10月という早い時期にTritonをリリースしました。このGPU向けのオープンソースのディープラーニングプログラミング言語コンパイラは、開発者がCUDA C++の低レベルの詳細に立ち入ることなく、簡潔なPythonスタイルのコードで高性能なGPUカーネルを記述することを可能にします。その結果、Tritonはコミュニティ内で急速に注目を集めました。多くの研究者やエンジニアは、TritonがGPU演算子開発の参入障壁を下げると考えています。一方、Meta/FAIR関連のTC/テンソル言語や、TVM/Relay/DeepSpeedを中心にコミュニティが構築した演算子コンパイルおよび最適化フレームワークも、ソフトウェアエコシステムの特定領域における競争に多様な選択肢を提供しています。
これが直接的に cuTile の出現につながりました。NVIDIA は、商業的優位性を強固にするために、ソフトウェア システムのパッケージングとユーザー エクスペリエンスをさらに改善し、より多くの開発者が CUDA エコシステムに留まるようにする必要がありました。 SemiAnalysis は、cuTile の導入は NVIDIA が CUDA の優位性を深めるための重要な動きであると述べた記事を公開しました。PyTorchコンパイラは、Tritonに加えてNVIDIA Python CuTeDSLをサポートするようになりました。これにより、FlexAttentionはTriton実装の2倍の速度になります。NVIDIAは、クローズドソースのPython CuTeDSL、cuTile、TileIRエコシステムを強力にサポートしてきました。Python CuTeDSL/cuTile/TileIRを通じて、NVIDIAはクローズドソースコンパイラの最適化へのアクセスを取り戻しました。
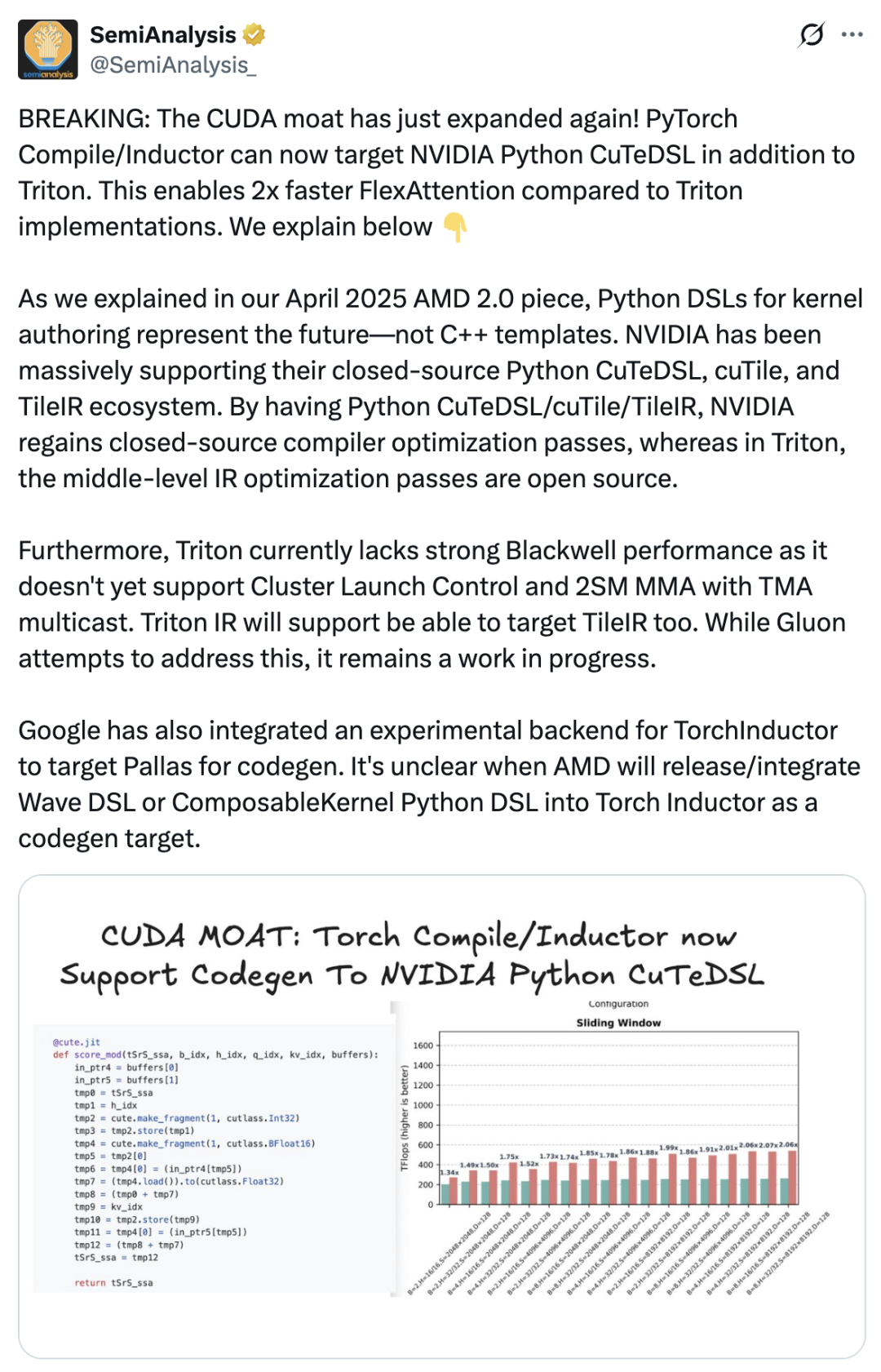
Triton をコピーしていますか? cuTile の「Tile Mindset」: 開発者のコメントは次のとおりです。
実際には、cuTile に対する市場の反応は賛否両論ある。cuTileを使用した開発者の中には、Tileの最適化は斬新な改善点である一方で、DSLの数が多すぎるため新たな学習曲線が生じたと報告する人もいました。RedditユーザーのPrevious-Raisin1434は、cuTileの新しいDSLのせいで移行期間中に圧倒されたとコメントしています。
「なぜ突然何千もの異なるものが存在するのか。以前はTritonを使用していたが、今ではNVIDIAは12を超える新しいDSLをリリースしている」と彼は不満を漏らした。
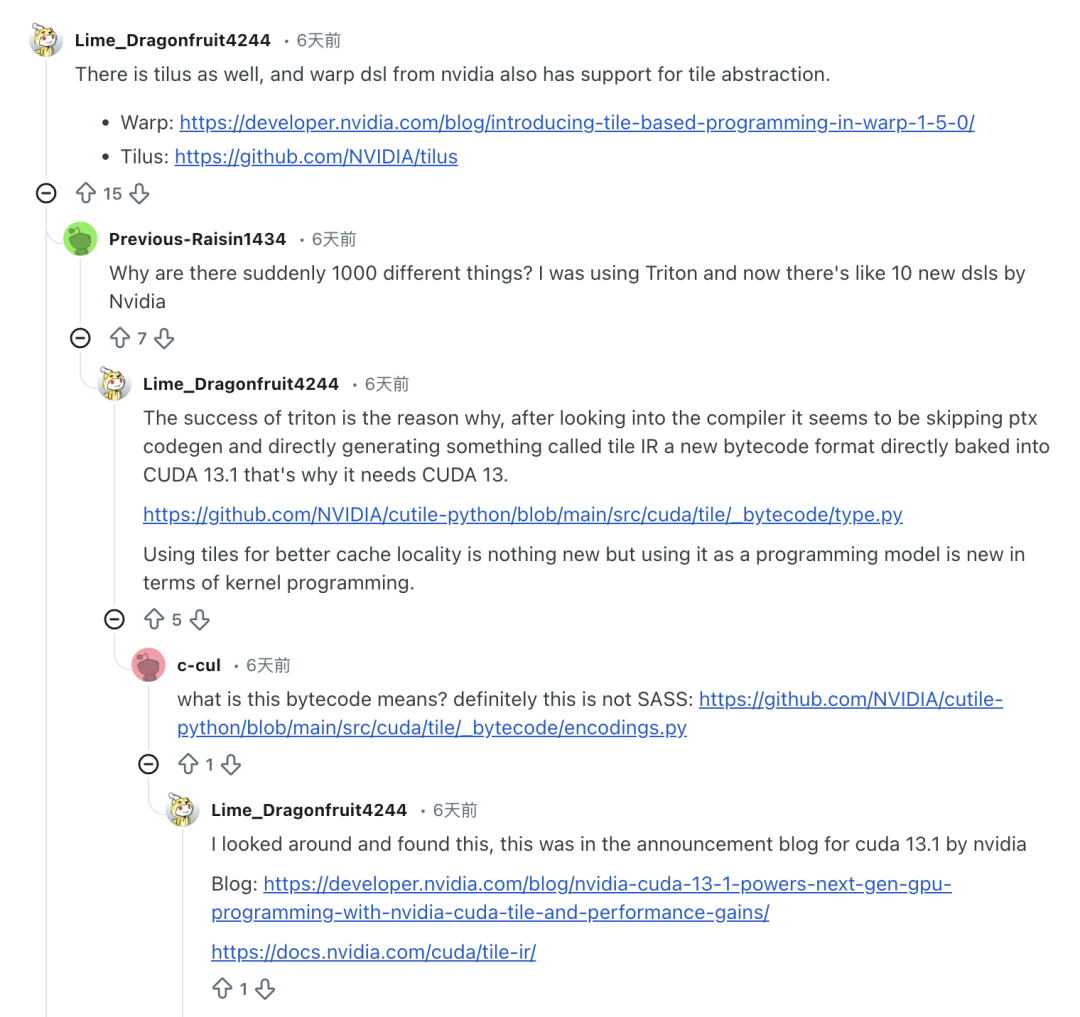
一方、業界の専門家の中には、cuTile の差別化と独創性の欠如に疑問を呈し、「cuTile は、Triton、Mojo、ThunderKittens が統合されたかのように、NVIDIA の回答のように感じられる」と述べている人もいます。

この点について、初期の CUDA チームのメンバーである Nicholas Wilt 氏は、次のように投稿しました...「cuTile が Triton に対抗するために直接開発されたのではないかと疑わずにはいられません。cuTile は、Triton や Helion と同様に、カーネルを記述するための新しい eDSL です。」
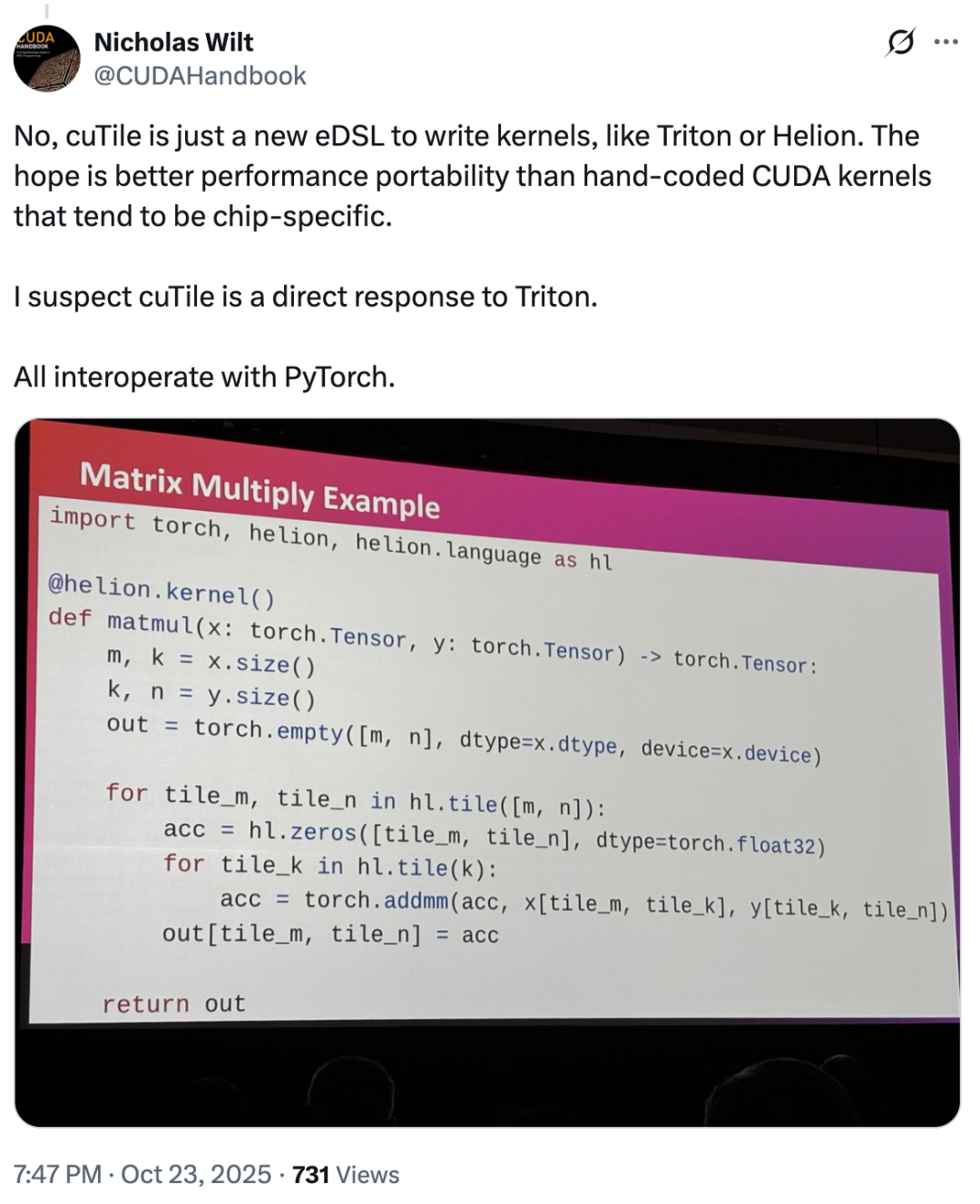
では、cuTileはTritonを模倣したのでしょうか?ほとんどのユーザーは「いいえ」と答えました。実際、cuTileに対する市場の反応は概ね好意的で、反対意見はごくわずかでした。ほとんどのユーザーはこのアップデートに不満を表明せず、cuTile を「革新的な製品」と称賛するユーザーもいました。「cuTile により、ユーザーはメモリスワッピング、ワープ spclz、メモリマージ、その他 100 を超える問題について心配する必要がなくなります。」
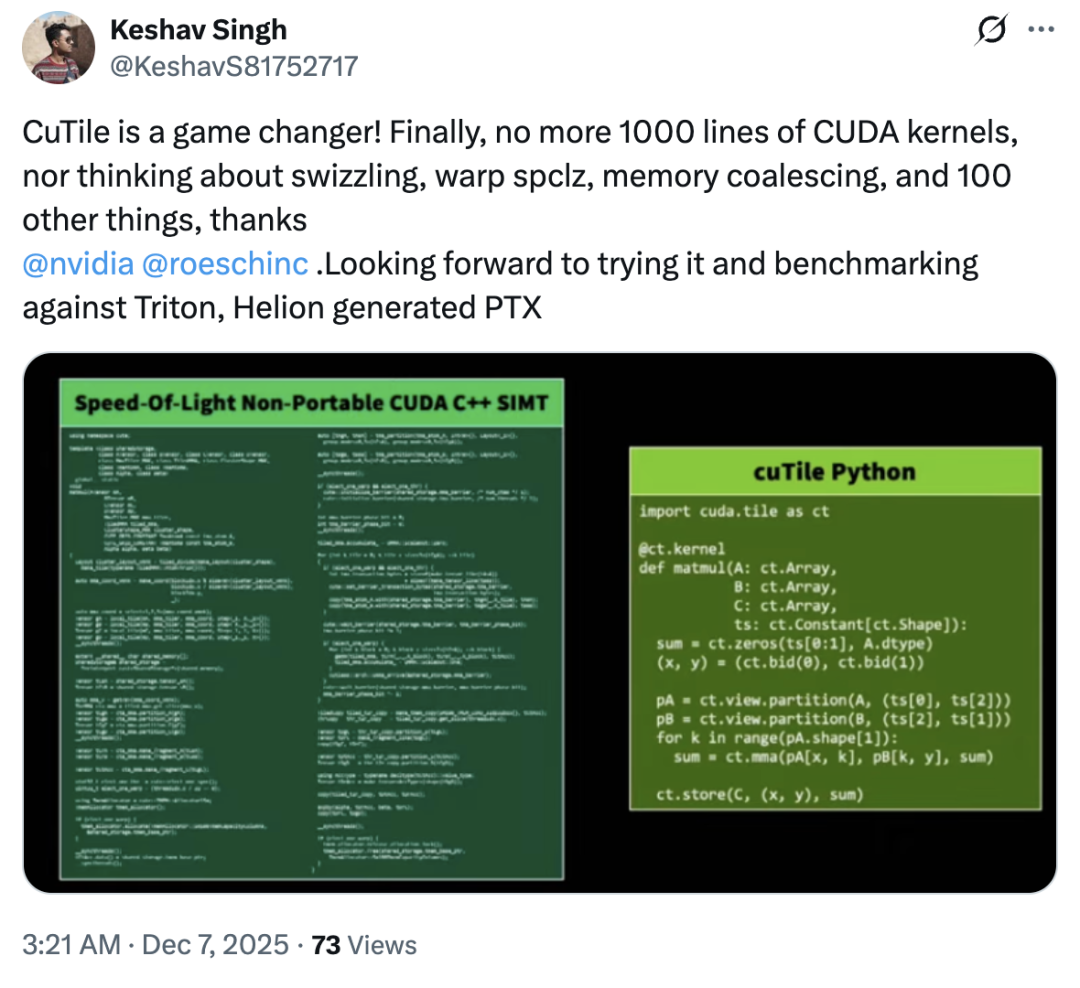
技術ブログによると、cuTile がユーザーを獲得する最大の魅力は、GPU コンピューティングをより高いレベルの抽象化に導入する「タイル」コンセプトにあるという。
「当初、これは単なる CUDA 用の Python バインディングまたは簡略化されたラッパーだと思っていましたが、ドキュメントや例を詳しく調べてみると、はるかに大きな野望があることがわかりました。」 cuTile の核となるアイデアは、並列コンピューティングとハードウェア アクセラレーションに関連する Tile です。タイリングは、大規模なデータセットを小さなチャンクに分割することで、キャッシュや共有メモリをより有効に活用する古典的な最適化手法です。cuTileは、この概念をプログラミングモデルのレベルにまで高めます。ブログ記事には、「これにより、開発者はタイルという単位で直接計算を考え、記述できるようになります。スレッドブロック内の各スレッドがどのように連携するか、グローバルメモリから共有メモリにデータがどのようにロードされるか、同期がどのように実行されるかなどを明示的に管理する必要がなくなります。代わりに、データのタイルを定義し、それらのタイルに対して実行される操作を定義すると、cuTileコンパイラがこれらの面倒な低レベルの詳細を処理する効率的なカーネルコードを自動的に生成します」と記されています。
cuTile はまだ初期段階ですが、業界内で移行パスを積極的に模索している事例があります。一部のアルゴリズム専門家は、CUDA C++ から cuTile への自動変換ツールの構築を試み始めています。既存のエンジニアリングコードと新しいパラダイムの間に実用的な橋を架けることが目標です。こうした取り組みの一環として、Redditコミュニティの開発者たちは、コミュニティの潜在的な移行ニーズを満たすために、CUDAカーネルの一部をタイルベースのフォーマットに変換できるオープンソースプロジェクトを立ち上げました。
しかし、NVIDIAの「Tile」パラダイムがどこまで発展していくのかについては明確な答えがありません。cuTileは新製品として、まだ検証段階に入ったばかりです。CUDAからcuTileへの移行ツールチェーンがさらに成熟し、コミュニティがcuTileをめぐる新たな実験と議論の場を形成すれば、cuTileは将来のGPUソフトウェアエコシステムにおいて前例のない地位を占めることになるかもしれません。しかし、これらのしきい値を超えることができなかったことの結果は非常に明白です。cuTile は、CUDA の長い歴史の中で、短い実験で終わってしまったのかもしれません。結論として、現在の競争環境において、cuTile が今後も魅力的であり続けるかどうかは、開発エクスペリエンスを継続的に最適化し、移行コストを削減し、複雑なオペレーターにとってかけがえのないパフォーマンス上の利点を提供できるかどうかにかかっています。
参考リンク:
1.https://byteiota.com/nvidia-cutile-python-gpu-kernel-programming-without-cuda-complexity/
2.https://veyvin.com/archives/github-trending-2025-12-08-nvidia-cutile-python
3.https://cloud.tencent.com/developer/article/2512674
4.https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware








