Command Palette
Search for a command to run...
EdgeBench : Dévoiler les lois d'échelle de l'apprentissage à partir d'environnements réels
EdgeBench : Dévoiler les lois d'échelle de l'apprentissage à partir d'environnements réels
Résumé
Les lois d'échelle du pré-entraînement révèlent que la capacité des modèles s'améliore de manière prévisible avec les données et le calcul. Mais l'apprentissage à partir d'environnements réels après le déploiement reste bien moins compris. En analysant environ 38 000 heures d'interaction d'agents avec l'environnement sur 134 tâches du monde réel, nous trouvons, à notre connaissance, la première preuve que la performance globale durant l'apprentissage environnemental suit une loi d'échelle log-sigmoïde avec une précision remarquablement élevée, atteignant R2=0,998. À travers les générations de modèles, nous constatons également que la vitesse d'apprentissage des agents double environ tous les trois mois. Cette découverte provient d'EdgeBench, une suite de 134 tâches du monde réel avec des horizons ultra-longs, couvrant la découverte scientifique, l'ingénierie logicielle, l'optimisation combinatoire, le travail de connaissance professionnel, les mathématiques formelles et les jeux interactifs. Chaque tâche soutient au moins 12 heures de fonctionnement continu de l'agent sous un retour d'information riche et multi-niveaux, et est construite grâce à un effort expert substantiel. Nous publions publiquement 51 tâches et notre cadre d'évaluation complet pour accélérer l'étude de la manière dont les agents apprennent de l'expérience du monde réel.
One-sentence Summary
ByteDance Seed's EdgeBench, a 134-task real-world benchmark spanning scientific discovery, software engineering, and interactive games, reveals that agent performance during environment learning follows a log-sigmoid scaling law (R2=0.998) and that learning speed doubles every three months across model generations, providing the first empirical scaling laws for post-deployment agent learning.
Key Contributions
- The paper presents EdgeBench, a benchmark of 134 real-world tasks across scientific discovery, software engineering, combinatorial optimization, professional knowledge work, formal mathematics, and interactive games, designed to measure agent performance improvement over day-long horizons with rich, multilevel feedback.
- Aggregate agent performance across these diverse, long-horizon tasks follows a log-sigmoid scaling law with interaction time, achieving an R² of 0.998 and enabling later performance to be forecast from early trajectories.
- The learning speed of frontier agents doubles roughly every three months across recent model generations, indicating that environment learning is a measurable and systematic scaling object.
Introduction
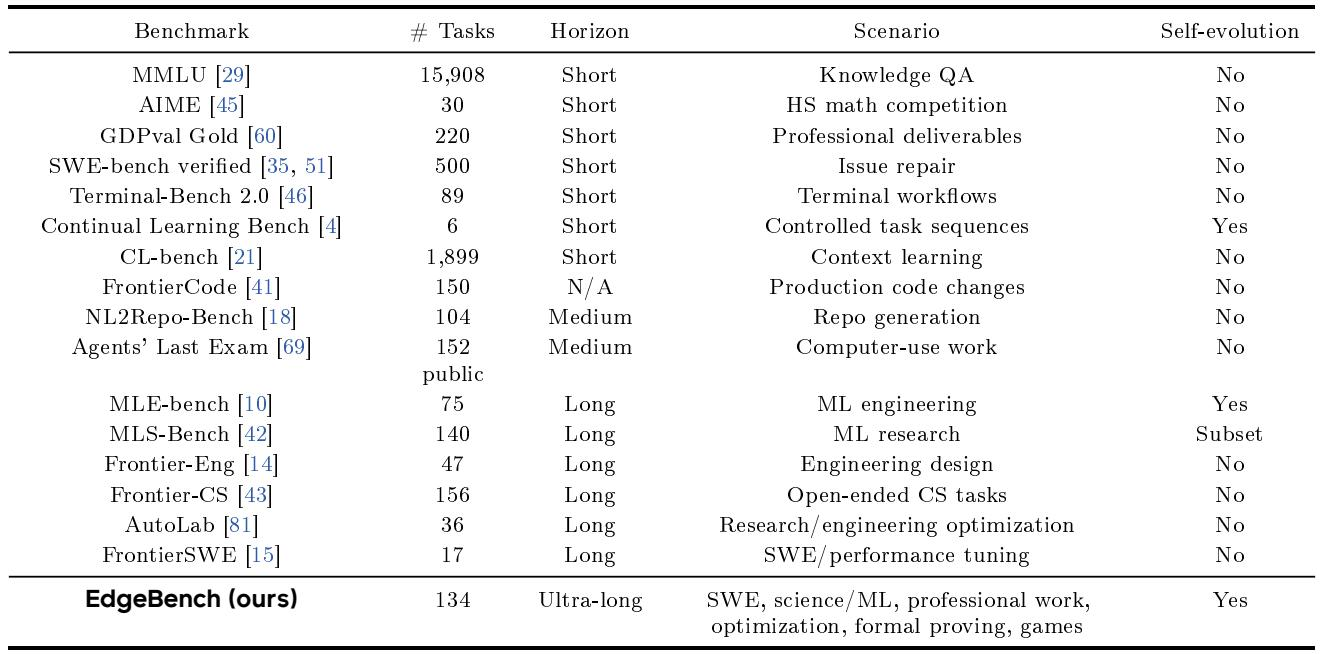
Large language models are increasingly deployed as agents that must adapt to real-world tasks through interaction, but prior benchmarks lack the long horizon and rich, multi-level feedback needed to study how agents actually learn from their environment. Existing evaluations either measure static endpoints on short tasks or provide only narrow feedback, making them unable to capture the trajectory of experience-driven improvement. The authors introduce EdgeBench, a benchmark of 134 day-scale tasks across six diverse domains (from scientific research to software engineering), where agents receive both local test results and submission-gated judge feedback over at least 12 hours. Using this benchmark and roughly 38,000 hours of agent interaction, they uncover the first evidence that environment learning follows a precise log-sigmoid scaling law with interaction time and that frontier agents’ learning speed has doubled roughly every three months.
Dataset
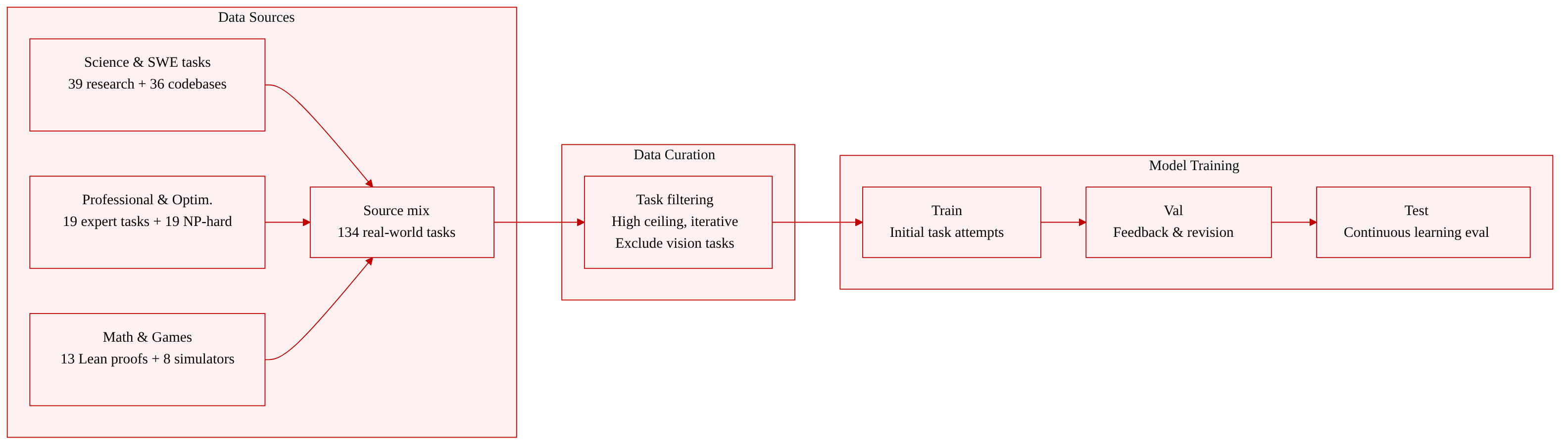
The authors curate 134 real-world tasks spanning six capability families, each selected for two properties: a high performance ceiling that current agents cannot saturate, and a workflow that rewards continuous learning rather than one-shot completion. Domain experts collaborated to source and filter the tasks, deliberately excluding those where success depends primarily on visual understanding (e.g., GUI operation) so that iterative reasoning and learning ability can be isolated.
Dataset composition and sources
- Total: 134 tasks across six families.
- Sources are real-world: research data from working scientists, production-grade codebases, professional white‑collar deliverables, formal mathematics in Lean, and human‑playable games.
- Filtering rules: tasks must have a high unsolved ceiling and support iterative improvement; vision‑heavy tasks are excluded.
Key details per family
- Scientific Problems & ML (39 tasks). Real research data and experimental settings; agents formulate hypotheses, choose models, validate against noisy observations, and refine iteratively. Many are open‑ended with no known optimal solution.
- Systems & Software Engineering (36 tasks). Production‑grade codebases; changes can exceed 100,000 lines of code. Agents must reason across interdependent modules while meeting correctness and performance targets.
- Combinatorial Optimization (19 tasks). Open‑ended, predominantly NP‑hard problems; exact methods are intractable, so agents design, tune, and iterate on heuristic search strategies.
- Professional Knowledge Work (19 tasks). Deliverables from finance, education, healthcare, and legal domains equivalent to a professional with 3+ years of experience working for about three days. Many tasks include structured rubrics and multi‑round feedback simulating client review cycles, enabling iterative revision.
- Formal Math & Theorem Proving (13 tasks). Frontier‑difficulty proofs requiring large‑scale Lean proofs; most are newly created for the benchmark. Agents receive structured intermediate guidance and can incrementally extend partial proofs.
- Interactive Games & Simulators (8 tasks). Real human games with enormous state spaces and procedural variation. Proficient humans spend tens of hours mastering them; agents must develop strategies through high‑frequency interaction across many episodes.
How the data is used
- The tasks are designed for continuous learning evaluation: agents are expected to improve through repeated attempts, feedback, and iterative refinement rather than performing a single inference.
- In families like Professional Knowledge Work, multi‑round structured feedback mimics real review cycles, allowing agents to learn from critique.
- In Formal Math, incremental proof‑building lets agents receive intermediate guidance and extend partial results.
- The tasks serve as a diverse evaluation suite where the primary challenge is reasoning, planning, and learning from experience, not perception.
Processing and curation choices
- Cropping strategy / metadata: Not explicitly detailed, but tasks are constructed to expose raw, real‑world inputs (research data, full codebases, Lean environments, game states) with minimal simplification.
- Filtering: The search explicitly excluded tasks where vision is the bottleneck, so the dataset minimizes contamination of reasoning evaluation by perceptual capability.
- Expert collaboration: Each task was sourced and vetted with domain experts to ensure authenticity and the presence of a high performance ceiling.
Method
The authors design EdgeBench as a benchmark suite that specifically measures whether an autonomous agent can learn from experience in an unfamiliar real-world environment. The core design rests on two methodological commitments: ultra-long-horizon diverse tasks and realistic multi-level feedback. The first principle is operationalized through a task taxonomy comprising 134 tasks across six capability families, each crafted as a day-scale challenge that allows frontier models to interact for at least 12 hours. These extended interaction windows are necessary because learning behaviors such as exploration, strategy revision, and experience accumulation require substantial temporal scope to emerge; short-horizon tasks tend to be solved from memorized priors rather than from genuine adaptation to novelty.
The second principle is realized through a structured evaluation protocol that simulates, for each task, an isolated slice of the real world. Every task environment is split into a private work environment and a separate judge environment. The agent interacts with the work environment, receiving local, agent-driven feedback that corresponds to the real-world signals of test failures, experimental results, and unexpected phenomena. To access the richer, authoritative feedback from the judge, the agent must submit a solution, gating that higher-quality signal behind an active decision. Meanwhile, the host infrastructure captures full trajectory measurements, enabling precise study of how agent performance evolves over the interaction horizon. This architecture ensures that the feedback approximates the complexity of real-world learning while maintaining experimental control.
The collected trajectory data across five frontier agents and roughly 38,000 hours of environment interaction reveals that learning from the environment obeys a remarkably simple scaling form. When task scores are aggregated over the benchmark and plotted against log interaction time, the performance growth closely follows a log-sigmoid curve. To explain this empirical regularity, the authors propose a theoretical model in which environment learning is viewed as a frontier expansion process on a latent task graph.
In this model, each task is represented by a graph whose nodes are score units with weights wi and normalized weights μi=wi/∑iwi. A binary variable ni(u)∈{0,1} indicates whether unit i is unlocked at effective time coordinate u, so the normalized score obtained at that moment is
x(u)=∑iμini(u).
Edges carry non-negative weights Kij that quantify how much an unlocked source unit j facilitates the unlocking of a target unit i. A locked unit i therefore experiences an influence field
hi(u)=∑jKijnj(u).
Assuming that locked units unlock stochastically at a rate proportional to this field, the expected rate of score growth conditioned on the current state is
dudE[x(u)∣n(u)]=η∑i∈L(u)∑j∈U(u)μiKij,(2)
which is exactly the weighted frontier cut from the set of unlocked units U(u) to the set of locked units L(u). Thus, progress is driven by the size of the boundary across which unlocked knowledge can propagate.
A mean-field approximation is then applied, assuming that at the macroscopic level every unlocked-locked cut behaves approximately as a product measure:
∑i∈L∑j∈UμiKij≈κμ(L)μ(U).
With μ(A)=∑i∈Aμi, this yields a simple differential equation for the expected score:
dudx=βx(1−x),β=ηκ.(3)
The factor x represents the unlocked score mass, which provides reusable capability, and 1−x represents the locked mass, measuring the remaining opportunity for improvement.
To connect the graph coordinate u to real time, the authors argue that u grows as logt under self-similar graph structure: if each additive increase in task difficulty exposes a multiplicatively larger portion of the graph, then the search volume required to traverse the graph expands exponentially with difficulty, so that the difficulty scale reached by time t scales logarithmically. Substituting u∼logt into (3) gives the dynamics in observable time,
dlogtdx=βx(1−x).(4)
Separating variables and integrating yields a logistic function of logt:
x(t)=1+(tmid/t)β1,⟹S(t)=1+(tmid/t)βSmax.
The fitted rate β captures the effective frontier-propagation speed in log time: larger β produces a steeper transition from low to high performance, while smaller β spreads progress over more multiplicative time. The ceiling Smax represents the attainable score support over the observed regime rather than an absolute performance upper bound.
Individual tasks can exhibit plateaus and sudden jumps due to finite score units, but the benchmark-level aggregate curve smooths these fluctuations. Under mild assumptions of blockwise cut-mixing, vanishing average jump noise, midpoint alignment, and speed concentration, the task-averaged score xM(u) converges in probability to a single log-sigmoid. This framework provides a mechanistic interpretation of the scaling law as a macroscopic signature of frontier expansion on structured task graphs, linking environment learning to the same mathematical form observed in pretraining performance scaling.
Experiment
EdgeBench evaluates five frontier models on 134 diverse real-world tasks using a dual-loop protocol where agents iterate locally and submit to a hidden judge, enabling measurement of learning over 12-hour horizons. The key finding is that agent performance improvement from environment interaction follows a precise log-sigmoid scaling law, emergent across many tasks and mirroring pretraining trends. Learning speed doubles approximately every three months, accumulated experience adds value beyond repeated sampling, and longer context windows yield consistent gains. A case study reveals that agents improve through sparse but structured diagnose-edit-evaluate loops, first making the problem measurable, then decomposing failures and targeting bottlenecks.
The log-sigmoid form achieves the lowest RMSE (0.390) among three-parameter S-curve families and a log-linear baseline, though other sigmoid curves (log-probit, log-Gompertz, Weibull CDF) are nearly identical (0.398–0.404). All S-curves substantially outperform the log-linear baseline (0.717), indicating that learning trajectories are robustly sigmoidal. Log-sigmoid yields the best fit with RMSE 0.390, marginally ahead of the other sigmoid families. Log-probit, log-Gompertz, and Weibull CDF produce nearly indistinguishable RMSE values (0.398–0.404). All S-curves reduce error by roughly 45% compared to the log-linear baseline (RMSE 0.717).

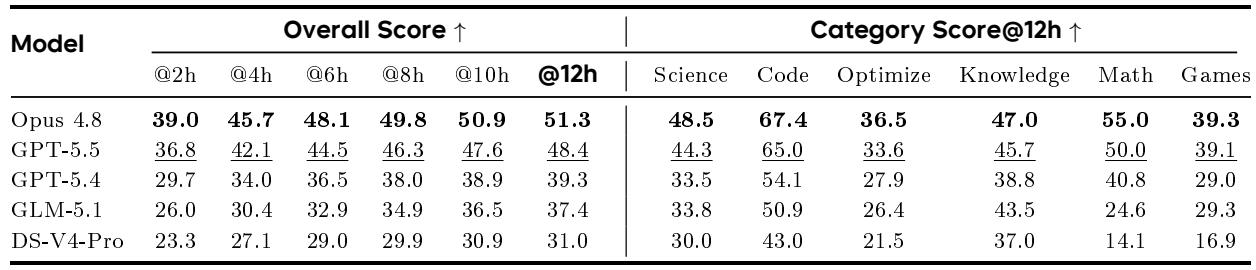
The aggregate results show a clear hierarchy: one model leads at every time budget and across all 12‑hour category averages, with a close runner‑up and a large gap to the remaining contestants. Analysis of submission efficiency indicates that higher performance is associated with more effective submissions, but the top model achieves its lead despite submitting less often than the second‑best, pointing to the importance of deliberate, feedback‑guided improvement over sheer submission volume. The leading model holds a consistent advantage throughout the 2‑to‑12‑hour window, and its lead widens slightly by the final checkpoint. At 12 hours, the second‑best model is competitive only in Games, where the gap is negligible; in other categories the top model maintains a comfortable margin. Models with higher effective‑submission rates generally perform better, but the highest effective‑submission rate does not translate into the best final score, revealing that submission quality and the size of improvements matter more than submission frequency. Weaker models often over‑trust local proxies or continue broad exploration after feedback has ruled out a direction, reducing sample efficiency, while stronger models preserve a working baseline, make focused changes, and use feedback to retain gains or roll back failures.
An agent that can accumulate experience across runs gains increasingly more over a same-budget baseline as time progresses. The advantage is small early on but becomes substantial by the 12‑hour mark, reflecting how a structured, failure‑driven search process converts many exploratory probes into a handful of high‑impact improvements. The performance gap between the experienced agent and the baseline grows from a negligible margin at 2 hours to a clear advantage of over 6 points by 12 hours. Only 27 of 224 submissions improve the best score, yet this sparse diagnose–edit–evaluate loop produces cumulative gains when the agent identifies and attacks the main bottleneck.

Most representative benchmarks evaluate static task completion and do not measure self-evolution over time or samples, with only one exception explicitly tracking performance against a resource axis. In contrast, an agent given iterative diagnose-edit-evaluate loops on a continual task shows structured, uneven improvement, demonstrating distinct problem-solving phases that turn many failed probes into a small number of cumulative gains. Only one of seven surveyed benchmarks tracks self-evolution by plotting performance against a resource axis, while others assess single-instance task solving without such continual metrics. During a 12-hour run, the agent improved from 42.8 to 67.0 through sparse, structured submissions: only 27 of 224 agent submissions increased the best score, and progress occurred in phases like making the task measurable, decomposing errors, focusing on a main bottleneck, and repairing residual issues.
The evaluation across experiments reveals that learning trajectories are robustly sigmoidal, with a log-sigmoid fit outperforming linear baselines and underscoring the nonlinear nature of improvement. A model competition further shows that sustained leadership arises from deliberate, feedback-guided refinements rather than submission frequency, as the best agent converts sparse, high-impact edits into cumulative gains. Analysis of iterative agent behavior and benchmark design indicates that most static benchmarks fail to capture self-evolution, while structured diagnose-edit-evaluate loops drive phased, bottleneck-focused progress that accumulates advantage over time.