Command Palette
Search for a command to run...
À quoi ressemblent les courbes de taux d'apprentissage quasi optimales ?
À quoi ressemblent les courbes de taux d'apprentissage quasi optimales ?
Hiroki Naganuma Atish Agarwala Priya Kasimbeg George E. Dahl
Résumé
Une question fondamentale sans réponse dans l'entraînement des réseaux de neurones est : quelle est la meilleure forme de courbe de taux d'apprentissage pour une charge de travail donnée ? Le choix de la courbe de taux d'apprentissage est un facteur clé dans le succès ou l'échec du processus d'entraînement, mais au-delà de la présence d'une phase d'échauffement et de décroissance, il n'y a pas de consensus sur ce qui constitue une bonne forme de courbe. Pour répondre à cette question, nous avons conçu une procédure de recherche visant à trouver les meilleures formes au sein d'une famille paramétrée de courbes. Notre approche isole la forme de la courbe du taux d'apprentissage de base, qui autrement dominerait les comparaisons entre courbes. Nous avons appliqué notre procédure de recherche à diverses familles de courbes sur trois charges de travail : la régression linéaire, la classification d'images sur CIFAR-10 et la modélisation du langage à petite échelle sur Wikitext103. Nous avons montré que notre procédure de recherche trouvait effectivement, en général, des courbes quasi optimales. Nous avons constaté que l'échauffement et la décroissance sont des caractéristiques robustes des bonnes courbes, et que les familles de courbes couramment utilisées ne sont pas optimales sur ces charges de travail. Enfin, nous avons exploré comment les résultats de notre recherche de forme dépendent d'autres hyperparamètres d'optimisation, et avons découvert que la décroissance des poids peut avoir un effet important sur la forme optimale de la courbe. À notre connaissance, nos résultats représentent les résultats les plus complets à ce jour sur les formes de courbes quasi optimales pour l'entraînement des réseaux de neurones profonds.
One-sentence Summary
By proposing a shape search procedure that decouples learning rate schedule shape from base learning rate, researchers from Mila, Université de Montréal, and Google DeepMind demonstrate on linear regression, CIFAR-10 image classification, and Wikitext103 language modeling that warmup and decay are robust near-optimal features, commonly used schedule families are suboptimal, and weight decay strongly influences the optimal schedule shape.
Key Contributions
- A search procedure is proposed that factors out the base learning rate to isolate schedule shape, enabling fair comparisons across schedule families.
- Applied to linear regression, CIFAR-10, and WikiText-103, the search finds near-optimal schedules, revealing that warmup and decay are robust features while common schedule families are suboptimal.
- Optimal schedule shape strongly depends on weight decay, indicating that learning rate schedule optimization cannot be decoupled from regularization hyperparameter choices.
Introduction
The learning rate schedule profoundly influences neural network training speed and final performance, yet practitioners usually pick a fixed functional form, such as linear or cosine decay, and tune only a few parameters like peak value and phase durations. There is little systematic understanding of how the schedule’s shape should adapt to a given workload. The authors address this gap by defining several parameterized schedule families, including flexible spline-based curves that can mimic and extend standard shapes, and by developing a search methodology on computationally lightweight proxy tasks to discover near-optimal schedules. Their experiments show that the best schedules naturally incorporate warmup and gradual decay even when the family does not enforce them, and that hyperparameters like weight decay significantly alter the ideal shape, offering a concrete step toward workload-aware schedule design.
Method
The authorsdefine a learning rate schedule as a function s(t)=α⋅ϕ(t/T), where α is the base learning rate, T is the training horizon, and ϕ is the schedule shape. To constrain the search space, they parameterize various schedule shape families, including CONSTANT, COSINE, GENERALIZED COSINE, SQUARE-ROOT DECAY, GENERALIZED REX, TWO-POINT SPLINE, TWO-POINT LINEAR, and SMOOTH NON-MONOTONIC. Most of these families incorporate linear warmup, while the SMOOTH NON-MONOTONIC family allows for completely general two-control-point splines without guaranteed monotonic decay.
To find near-optimal schedules within these families, the authors employ a two-step search procedure. They define the optimal training loss for a parameterized shape ϕθ and base learning rate α as: J(θ,α):=r∼Rmedian[min0≤t≤TLtrain(r)(θ,α,t)] where the median is taken over the distribution of randomness R (e.g., weight initializations). The optimal shape parameters θ⋆ are found by minimizing this objective over both θ and α.
The search step decouples the schedule parameters from the base learning rate. Schedule parameters are randomly sampled, and for each setting, the authors sweep over 16 base learning rates on a logarithmically spaced grid. Thousands of shapes are generated and scored using multiple PRNG seeds. Following the initial search, an evaluation step retrains the top k schedules with 100 seeds to compute robust median scores and confidence intervals.
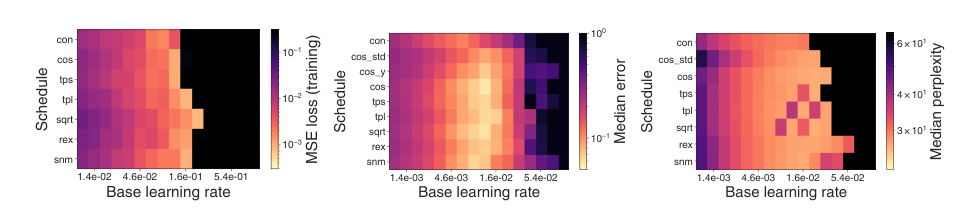
The experimental results demonstrate that the base learning rate is the most critical factor for achieving good performance. Once a schedule incorporates both warmup and decay, tuning the base learning rate yields significantly larger gains than refining the specific schedule shape hyperparameters. Furthermore, the search consistently reveals that warmup and monotonic decay are fundamental features of effective learning rate schedules in deep learning, even when using flexible families like SMOOTH NON-MONOTONIC that do not enforce these properties by design.
Experiment
The evaluation compares learning rate schedule families across three small, optimization-limited workloads: synthetic linear regression, CIFAR-10 image classification, and WikiText-103 language modeling, using random search to find near-optimal shapes. The linear regression test validates the search methodology against a ground-truth optimum that has no warmup and a flat profile with a sharp late decay, while the deep learning workloads consistently require warmup followed by monotonic decay, with the base learning rate being the most critical hyperparameter. More flexible schedule families yield modest but meaningful improvements over standard cosine decay, though the Smooth Non-Monotonic family proves hard to optimize. Workload variation experiments show that weight decay strength meaningfully shifts optimal decay timing, while varying training horizon leads to gentler decay. Overall, the study confirms warmup and decay as fundamentally useful, demonstrates that task-optimal schedules differ sharply between convex and non-convex settings, and provides guidance for practical schedule tuning and search.
The study evaluated families of learning rate schedules, finding that on neural network workloads (CIFAR-10, WIKITEXT-103), schedules with warmup and flexible decay shapes yielded small but significant improvements over constant or standard cosine decay. The optimal schedule shape varied with the workload, and principles from convex optimization (linear regression) did not transfer to deep learning, where warmup proved beneficial. Among flexible options, generalized cosine captured notable gains, while two-point spline and linear families offered sufficient flexibility to approximate near-optimal schedules. On CIFAR-10 and WIKITEXT-103, learning rate warmup was beneficial across families and workload variations, contrasting with linear regression where warmup was not useful. Generalized cosine decay, with a tunable exponent, achieved significant gains over standard cosine on CIFAR-10 and outperformed a cosine variant with a non-zero final learning rate. Flexible families like two-point linear and two-point spline can capture schedules very close to optimal, but differences between top members of even more flexible families were small, suggesting diminishing returns from further complexity. The ability to change the decay shape gave small but significant improvements in both train and test metrics, encouraging consideration of schedules beyond the popular cosine decay when tuning resources are available.

When searching for learning rate schedules with AdamW on CIFAR-10, a higher momentum (β₁) during the search phase generally leads to better schedules. However, using a lower momentum at evaluation time after the schedule is found can further reduce training error, indicating that a post-search drop in momentum improves performance. Larger β₁ in the schedule selection phase consistently reduces training error when evaluated at the same β₁. For a fixed selection β₁, lowering β₁ at evaluation typically yields lower error, with the best combination being the schedule found at β₁=0.95 and evaluated at β₁=0.8.
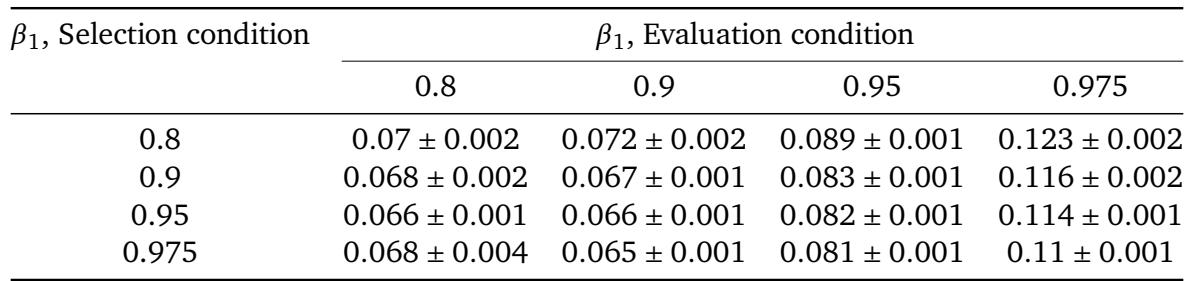
The choice of the momentum parameter β1 during both schedule search and evaluation significantly impacts WIKITEXT-103 perplexity. Schedules discovered with higher β1 values tend to perform well when the training run also uses a similarly high β1, but performance deteriorates sharply for low-momentum evaluation, particularly at β1=0.8. The lowest perplexity is achieved when the schedule is searched and evaluated at β1=0.95. Schedules selected with higher β1 values generally yield lower perplexity when evaluated at β1 of 0.9, 0.95, or 0.975, but this trend reverses at evaluation β1=0.8, where higher selection β1 leads to worse performance. Evaluating schedules at β1=0.8 produces the widest range of perplexities and the largest standard deviations, pointing to high uncertainty in low-momentum training runs.
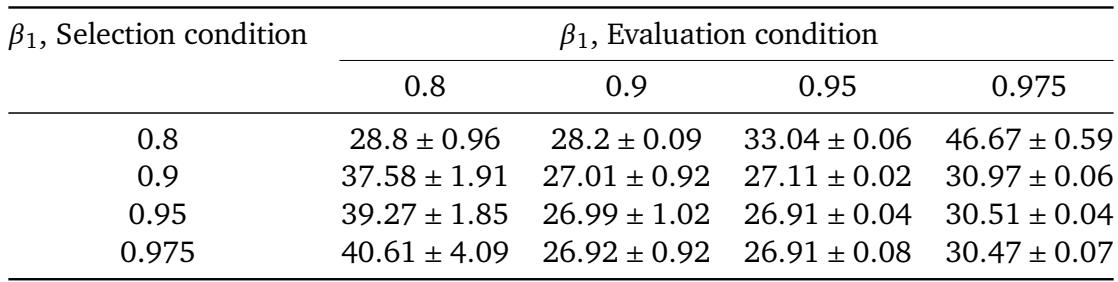
When choosing learning rate schedules, the momentum parameter β2 used during schedule selection strongly influences final performance. Selecting schedules with a high β2 (0.9995) and evaluating them with a low β2 (0.9) yields the lowest median training error on CIFAR-10, outperforming all matched selection–evaluation pairs. Across all evaluation β2 values, higher selection β2 consistently reduces error, indicating that tuning schedules with more momentum can uncover schedules that generalize well even with less momentum at deployment. The best combination uses selection β2=0.9995 and evaluation β2=0.9, achieving lower error than any setting where selection and evaluation β2 match. For every fixed evaluation β2, increasing the selection β2 reduces the median training error, with the largest drop occurring when moving from β2=0.9 to β2=0.9995. When schedules are selected with a low β2, error rises sharply as evaluation β2 increases, while selection with a high β2 keeps error relatively low across all evaluation conditions.
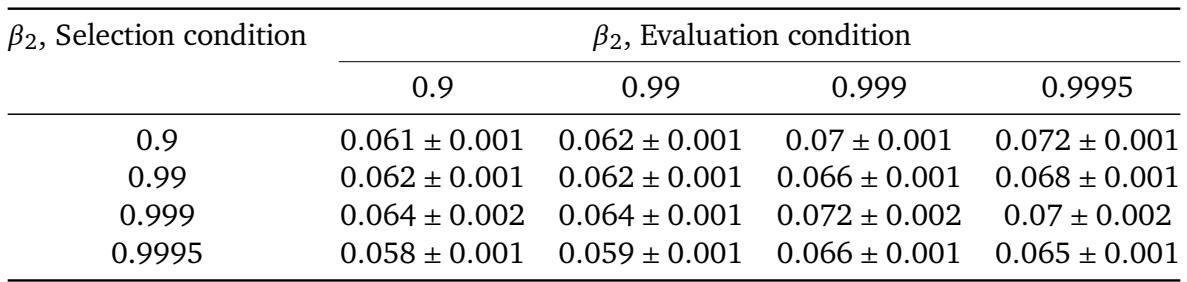
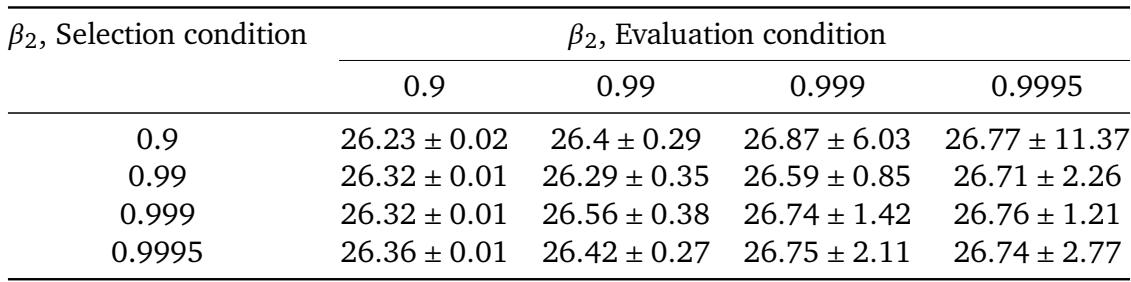
When tuning learning rate schedules, the choice of Adam's β₂ during schedule selection affects both the quality and stability of the resulting perplexity. Selecting schedules with a higher β₂ lowers the median perplexity, but the best overall performance is achieved by taking a schedule optimized with β₂=0.9995 and evaluating it with β₂=0.9. Using a low β₂ during selection introduces substantial noise, as shown by the wide spread in perplexity values across evaluation β₂. Schedule selection with higher β₂ reduces the median perplexity, while selection at β₂=0.9 produces the widest variation and large standard deviations, confirming that low β₂ during tuning adds noise. The best perplexity result emerges when a schedule selected using β₂=0.9995 is evaluated with β₂=0.9, highlighting the benefit of mismatched selection and evaluation settings.
Using AdamW on CIFAR-10 and WIKITEXT-103, the study evaluates learning rate schedule families and the impact of momentum parameters during schedule search. Flexible schedules incorporating warmup and tunable decay shapes (e.g., generalized cosine, two-point spline) yield small but significant improvements over constant or standard cosine, with the optimal shape varying by workload. Experiments on momentum reveal that selecting schedules with higher β1 and β2 values, and then evaluating at lower momenta (β1=0.8, β2=0.9), achieves the best performance, and high-β2 selection provides robustness against low-momentum noise. Overall, tuning schedule shape and exploiting momentum mismatch offers practical gains, encouraging exploration beyond standard cosine schedules when resources allow.