Command Palette
Search for a command to run...
Orca : Le monde est dans votre esprit
Orca : Le monde est dans votre esprit
Résumé
Nous présentons Orca, une première instanciation d'un modèle de fondation général du monde. Orca apprend un espace latent unifié du monde à partir de signaux mondiaux multimodaux et l'expose via des interfaces de lecture multimodales. Plutôt que d'optimiser des prédictions isolées de type prochain token, prochaine image ou prochaine action, nous nous concentrons sur la modélisation de la Prédiction du Prochain État, offrant une voie unifiée de modélisation de transition d'état pour comprendre, prédire et agir sur le monde. Orca apprend à travers deux paradigmes complémentaires : l'apprentissage inconscient capture des transitions d'état naturelles denses à partir de vidéos continues, et l'apprentissage conscient modélise des transitions d'état significatives clairsemées par des événements décrits en langage et une supervision VQA. Pour le pré-entraînement, nous construisons un inventaire de données d'apprentissage du monde à grande échelle, comprenant 125 000 heures de données vidéo et 160 millions d'annotations d'événements. Après le pré-entraînement, Orca apprend un espace latent unifié du monde. Pour examiner si l'espace latent appris soutient les tâches en aval, nous l'évaluons via trois lectures représentatives : génération de texte, prédiction d'image et génération d'actions incarnées. Le squelette d'Orca est gelé, et seuls les décodeurs légers spécifiques à chaque modalité sont entraînables. Les expériences montrent la scalabilité du paradigme proposé et vérifient qu'un espace latent du monde plus fort permet de meilleures lectures en aval. Orca surpasse les modèles spécialisés de taille similaire. Ces résultats montrent qu'Orca, en tant que modèle de fondation général du monde, présente une approche prometteuse pour comprendre, prédire et agir sur le monde. Enfin, nous discutons des limitations actuelles, dans le but de fournir des perspectives et une inspiration utiles à la communauté.
One-sentence Summary
Researchers at the Beijing Academy of Artificial Intelligence introduce Orca, a general world foundation model that learns a unified world latent space from multimodal signals via Next-State-Prediction and dual learning paradigms (unconscious learning on dense video transitions and conscious learning on language-described events with VQA supervision); using a frozen backbone with trainable lightweight modality-specific decoders, Orca demonstrates scalable performance that surpasses similar-sized specialized baselines on text generation, image prediction, and embodied action generation tasks.
Key Contributions
- The paper presents Orca, a general world foundation model that learns a unified latent space from multimodal signals via Next-State-Prediction modeling, moving from isolated next-token, next-frame, or next-action objectives to a unified state-transition paradigm.
- Orca employs two complementary learning strategies: unconscious learning on continuous videos for dense natural state transitions and conscious learning on language-described events and VQA supervision for sparse meaningful transitions, using a pre-training inventory of 125K hours of video and 160M event annotations.
- Experiments demonstrate that the frozen Orca backbone supports text generation, image prediction, and embodied action generation through only lightweight trainable decoders, outperforming similar-sized specialized baselines and confirming that stronger world latents yield stronger downstream readouts.
Introduction
The authors argue that true progress toward general intelligence demands models that construct internal representations of world states, going beyond narrow next-token, next-frame, or next-action prediction. Prior work largely targets isolated prediction tasks and lacks a unified latent space for modeling state transitions from multimodal signals, which hinders transfer to diverse downstream capabilities. To address this, the authors propose Orca, a world learner that builds a world latent space from video and language through two complementary paradigms: unconscious learning of natural dense state transitions from continuous video, and conscious learning of instruction-guided sparse event transitions. They further assemble a large-scale video dataset with event annotations and demonstrate that the learned latent space scales with data and model size, yielding stronger downstream performance in text generation, interactive image prediction, and embodied action generation at comparable model scales.
Dataset
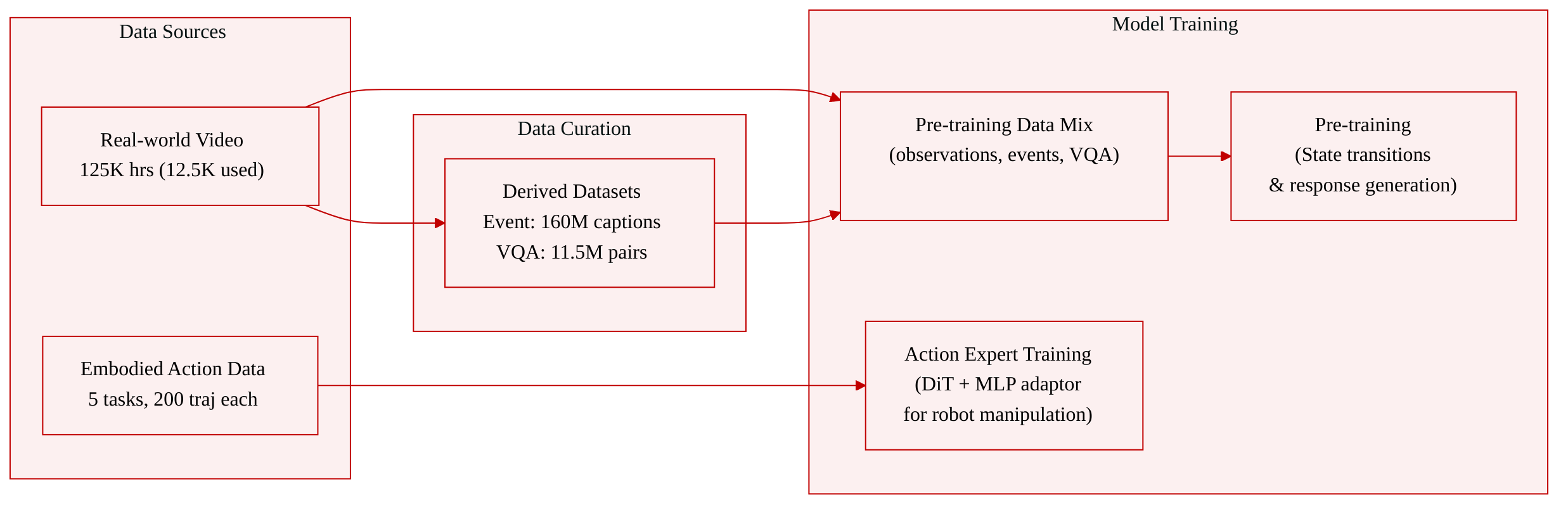
The authors construct their training data from three complementary collections, all grounded in real-world observations. The pre-training data comprises Video Data, Event Data, and VQA Data. For the downstream action module, they use a small embodied action dataset collected by a robot.
Pre-training data composition
- Video Data: Built from visual signals of four real-world observation types:
- Egocentric interaction (first‑person physical interaction)
- Exo‑centric manipulation (third‑person object‑centered changes)
- Action‑free robot execution (embodied action recordings in robotic settings)
- Natural dynamics (scenes that evolve without direct intervention)
The full repository contains 125K hours of general video; in this version only one‑tenth (12.5K hours) is used. The remaining data is reserved for future iterations.
-
Event Data: Derived from the Video Data through multi‑level temporal segmentation and language annotation.
-
Coarse events describe the main steps of a process.
-
Fine‑grained events capture the shorter state transitions within each step.
-
Each segmented event is paired with a caption that specifies the transition. A total of 160M event annotations are available, all supporting event‑conditioned state transition learning.
-
VQA Data: Constructed from language signals paired with video observations to teach description and interpretation of world states. 11.5M general VQA items are included, supporting response generation for visual question answering.
Event and VQA data are both derived from or built on top of the real‑world video observations. No explicit filtering rules or cropping strategies are mentioned; the construction relies on the segmentation, captioning, and pairing processes described above.
How the data is used
During pre‑training, the three collections provide different types of supervision:
- Video Data is used for observation‑only state transition and event‑conditioned state transition.
- Event Data explicitly teaches event‑conditioned state transitions via its captioned segments.
- VQA Data trains the model to generate responses that interpret observed world states.
The paper does not specify exact mixture ratios or training splits, only that the three collections work together to learn world states and their transitions.
Embodied action data (downstream readout training)
For the action‑generation module, the authors use a separate, small‑scale dataset:
- Collected by a dual‑arm wheeled humanoid robot performing 5 manipulation tasks.
- For each task, 200 trajectories are provided, each containing instructions, visual information, and proprioceptive signals.
- This dataset is used exclusively to train the Action Expert head (a DiT‑based model) and the adaptor layers that map from the model’s latent space to action chunks.
No additional filtering or processing details are given beyond the robot collection setup and the pairing of instructions with visual‑proprioception streams.
Method
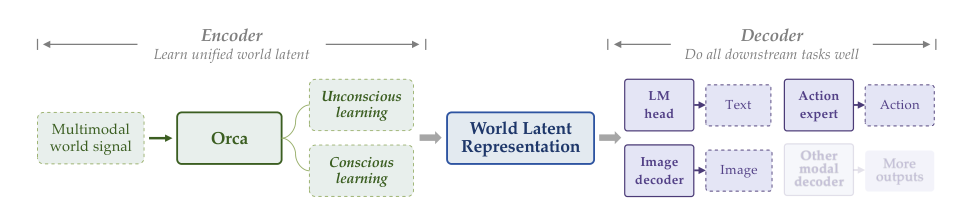
The authorsformulate world learning as latent world-state modeling, encompassing state abstraction from multimodal world signals and state transition. Given world signals χ, which can include language, vision, audio, and physical signals, the model maps them to a latent world state S, i.e., S=fθ(X). The state evolves under implicit dynamics zt and explicit conditions ct: St+Δ∼pΘ(St+Δ∣St,zt,ct),Δ∈Z=0 where Δ>0 predicts future states and Δ<0 backtracks to past states. To realize this state-transition modeling, the authors adopt two complementary learning paradigms: unconscious learning and conscious learning. Unconscious learning captures dense and natural state transitions from observation alone without explicit semantic conditions (ct=∅). Conscious learning captures sparse and meaningful state transitions under explicit semantic conditions, such as language instructions (ct=et+Δ).
The core of the architecture is the Encoder, which learns a unified world latent space for state abstraction and transition using a native pre-trained Vision-Language Model (VLM).
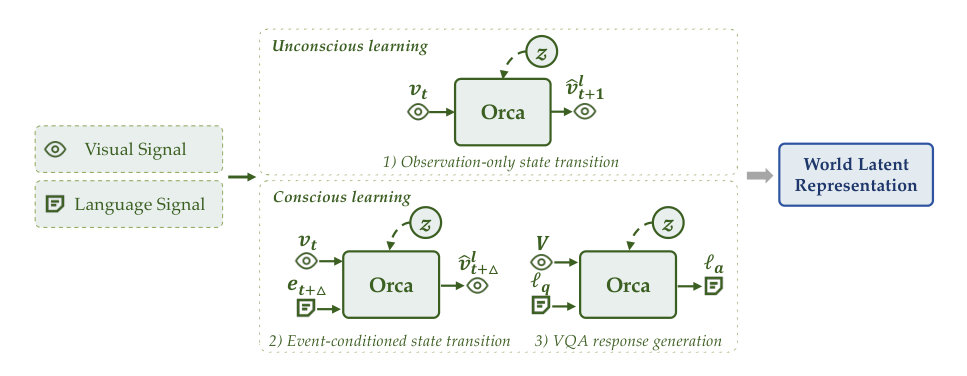
For unconscious learning, the input is a video frame vt, and the output is the predicted latent v^t+1l of the next adjacent frame. The frame passes through the VLM and two MLP layers to generate the prediction. The ground truth frame vt+1 passes through a frozen vision encoder to obtain a latent representation νt+1l, which is used to teacher-force the prediction. For conscious learning, the video is divided into segments based on meaningful events. The input includes a frame vt and an instruction description et+Δ of an adjacent event. The output is the predicted latent v^t+Δl associated with that event. Additionally, to foster world understanding, the model takes a video and related questions lq to output language answers la. The learned latent space is subsequently read out by modality-specific Decoders.
The training process consists of a pre-training stage and a downstream post-training stage. During pre-training, the authors instantiate world-state modeling with three objectives: observation-only state transition, event-conditioned state transition, and VQA response generation. The first two objectives are implemented through learnable query vectors in the VLM backbone input, while VQA generation is optimized via the language modeling head. The full pre-training loss combines these components: L=λobsLobs+λevtLevt+λvqaLvqa where Lobs corresponds to unconscious learning, and Levt and Lvqa correspond to conscious learning.
The pre-training data is organized into three complementary collections to provide supervision for learning world states and their transitions.
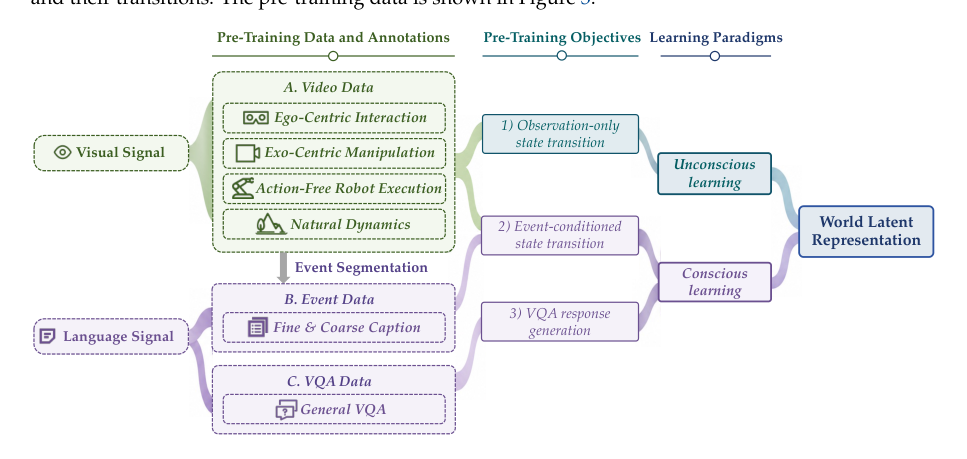
Video Data covers real-world observations like egocentric interaction, exo-centric manipulation, action-free robot execution, and natural dynamics, supporting observation-only and event-conditioned state transitions. Event Data is derived from video data through multi-level event segmentation and language annotation, supporting event-conditioned state transition. VQA Data is constructed from language signals and video data to teach the model to describe and interpret observed world states, supporting VQA response generation.
In the downstream post-training stage, the Orca backbone remains frozen, and only modality-specific readout modules are trained to extract language, vision, and action information.
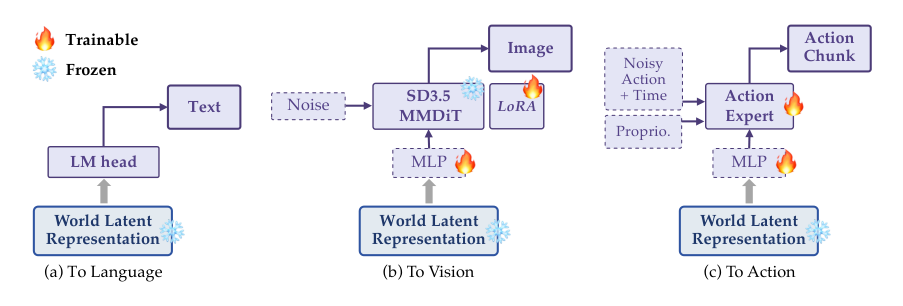
For text generation, the model reuses the LM head to produce responses from visual observations and instructions. For image prediction, the latent is passed through an MLP adaptor and used as a path input for a Stable Diffusion 3.5 model, where only the MLP adaptor and LoRA parameters are trainable. For action generation, a DiT-based Action Expert is trained from scratch using flow-matching loss. It receives the noisy action with time embedding, proprioception, and the latent processed by an MLP adaptor to generate action chunks for robot manipulation.
Experiment
Orca's next-state prediction paradigm scales effectively with model size and data, yielding a stronger world latent that improves downstream text generation, image prediction, and action generation, even without action labels. The model outperforms comparable VLMs and world models in reasoning and visual state prediction, and enables out-of-distribution robotic task success with better error recovery. Ablations show that jointly using observation-only, event-conditioned, and VQA losses achieves the most balanced performance, with each objective contributing distinct strengths.
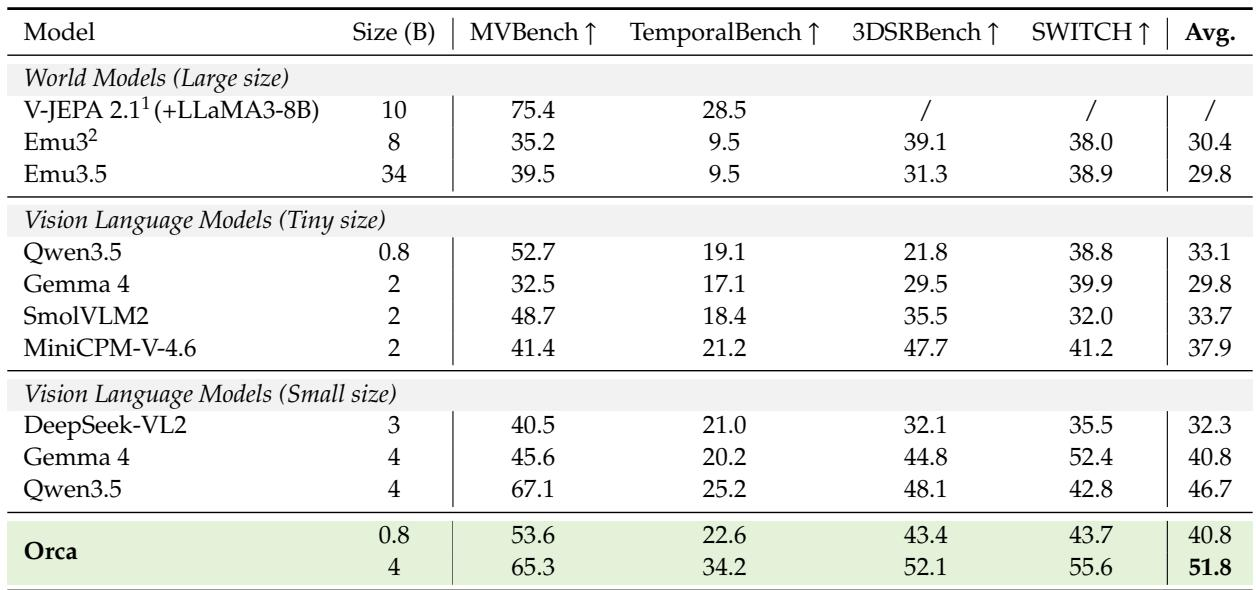
A tiny vision-language model (0.8B) achieves the highest average text generation score, surpassing much larger world models. Among world models, the V-JEPA plus language model pairing leads on MVBench and TemporalBench, while Emu3 dominates 3DSRBench, and all models perform similarly on the SWITCH benchmark. A 0.8B vision-language model obtains a higher average across all four benchmarks than 8B and 34B world models. The V-JEPA 2.1 plus LLaMA3 combination shows the strongest MVBench and TemporalBench results, with a 46.9-point MVBench advantage over the next best model. Emu3 excels on 3DSRBench with a score nearly 10 points above the nearest competitor. SWITCH performance is tightly clustered across all models, with scores within a 1.9-point range.
Orca-4B outperformed Qwen3.5-4B on all text generation benchmarks, with the largest gains in state transition and dynamic motion understanding. Commonsense reasoning also improved notably, while spatial relations showed only a marginal increase. These results suggest that Orca's state transition modeling particularly enhances capabilities tied to world-state changes and temporal dynamics. Orca-4B achieved a 12.27% relative improvement over Qwen3.5-4B on state transition benchmarks, the largest gain across all categories. Dynamic motion understanding improved by 8.52% and commonsense reasoning by 5.19%, demonstrating broad gains in temporal and abstract reasoning. Spatial relations saw only a 0.57% improvement, indicating that state transition modeling offers limited benefit for static spatial tasks.

On the PRICE-V0.1 real-world image prediction benchmark, the Orca model with a 4B language encoder and 2B vision decoder attains the highest average score across four automatic evaluators while also showing the lowest variance among all compared systems. The smaller Orca configuration trails behind dedicated image generation baselines, indicating that model scale substantially influences state transition prediction quality. Orca's larger variant (4B+2B) achieves the best overall average and the most consistent results, as measured by standard deviation. FLUX.2 [klein] posts the second-highest average but exhibits much larger evaluator disagreement, suggesting less stable predictions. The smallest Orca (0.8B+2B) records the lowest average, highlighting that greater capacity benefits visual state prediction. Model rankings vary per evaluator: FLUX.2 [klein] is preferred by Gemma 4-31B, whereas Orca leads under the other three judges. All evaluations use real-world interaction data judged by four different large language models, ensuring multi-faceted assessment.

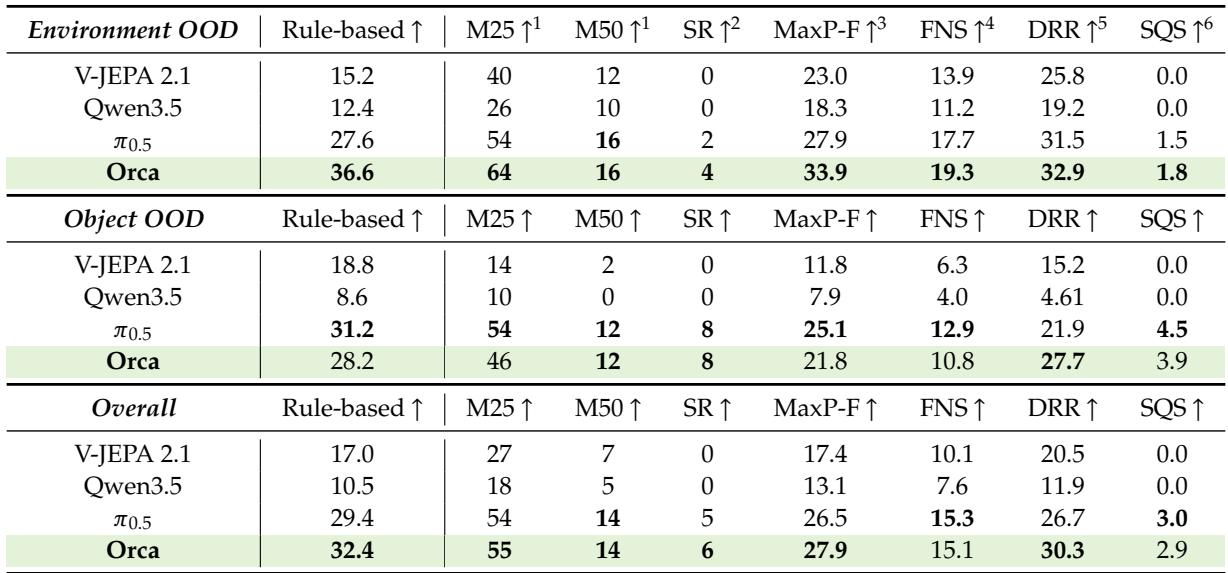
Orca’s learned world latent transfers effectively to action generation, substantially outperforming Qwen3.5 across environment and object OOD settings and breaking the zero success-rate barrier seen in other methods trained from scratch. It also shows stronger progression through task milestones and better recovery from execution errors, achieving the highest failure near-success and drawdown recovery ratios among compared models. Orca achieves the highest rule-based scores in both OOD settings and is the only from-scratch model to attain non-zero success rates, outperforming Qwen3.5 and V-JEPA 2.1 with the same Action Expert. Orca’s higher failure near-success score and drawdown recovery ratio indicate that even failed trajectories reach later task stages and the model more effectively corrects deviations and continues after progress drops.
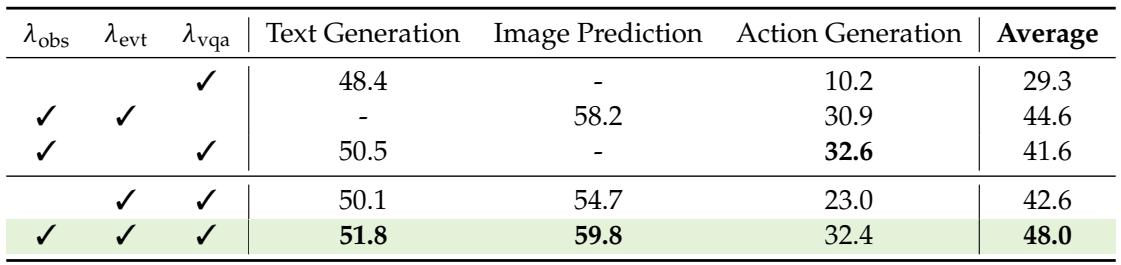
Combining observation-only state transition, event-conditioned state transition, and VQA response generation yields the most balanced performance across text, image, and action readouts. Removing the observation loss substantially weakens action generation, while the event loss is essential for image prediction. The VQA loss preserves language grounding and, together with the other two objectives, achieves the highest overall average. Using all three pre-training objectives attains the highest average score (48.0) and the most balanced downstream results. Adding the observation-only transition loss markedly boosts action generation, raising the action score from 23.0 to 32.4 when moving from event-plus-VQA to the full combination. Event-conditioned transition is critical for image prediction: image generation fails without it, and adding it lifts image performance to 54.7 with VQA and 59.8 with all three losses.
A tiny 0.8B vision-language model surprisingly outperforms much larger world models on text generation benchmarks, while world model combinations like V-JEPA with LLM lead on temporal understanding and Emu3 excels on 3D spatial reasoning. Orca-4B shows substantial gains over Qwen3.5 in state transition and dynamic motion comprehension but only marginal improvement on static spatial tasks. On real-world image prediction, Orca's larger variant achieves the most consistent quality, and its learned world latent transfers effectively to action generation, enabling non-zero out-of-distribution success rates and strong error recovery. Ablation reveals that combining observation-only, event-conditioned, and VQA training objectives yields the most balanced performance, with observation loss vital for action, event loss critical for image generation, and VQA loss maintaining language grounding.