Command Palette
Search for a command to run...
En Générant 18 000 Ans De Données Climatiques, NVIDIA Et D’autres Ont Proposé Une Distillation À Longue Distance, Permettant Des Prévisions Météorologiques À Long Terme En Une Seule Étape De calcul.

La précision et le délai de prévision des données météorologiques ont un impact direct sur la prévention des catastrophes, la production agricole et la répartition des ressources mondiales. Des alertes à court terme aux prévisions climatiques saisonnières, voire à plus long terme, les défis technologiques croissent de façon exponentielle à chaque avancée. Après des années de développement dans le domaine de la prévision numérique du temps, l'intelligence artificielle (IA) a insufflé un nouvel élan à ce secteur. Ces dernières années, les modèles de prévision météorologique basés sur l'IA ont réalisé des progrès considérables en matière de prévisions à moyen terme, avec des performances comparables, voire supérieures, à celles des modèles dynamiques traditionnels les plus avancés.
La plupart des modèles météorologiques d'IA courants utilisent actuellement une architecture autorégressive, qui fonctionne en extrapolant et en apprenant de manière itérative à partir de données historiques sur les variations atmosphériques à court terme afin de prédire les conditions pour les prochaines heures. Ce type de modèle est performant pour les prévisions à moyen terme.Cependant, lors de l'extension à des échelles à long terme telles que les échelles sub-saisonnières à saisonnières (S2S), des goulots d'étranglement fondamentaux ont été rencontrés.
Les prévisions à long terme reposent sur des méthodes probabilistes, tandis que les modèles autorégressifs ne peuvent effectuer de prédictions que par itérations répétées, ce qui entraîne une accumulation continue d'erreurs et rend le calibrage difficile. La contradiction fondamentale réside dans :L'objectif de la formation est d'apprendre les tendances à court terme, tandis que les prévisions à long terme nécessitent la construction de modèles probabilistes capables de caractériser la lenteur de la variabilité climatique.
Pour pallier cette limitation, les chercheurs ont exploré de nouvelles pistes pour la prédiction en une seule étape. Cependant, de nouveaux problèmes sont apparus : lors de l’entraînement de modèles à long terme en une seule étape à partir de données de réanalyse existantes, un surapprentissage important peut se produire en raison de la rareté des échantillons, et la fiabilité du modèle ne peut être garantie.
Dans ce contexte,Une équipe de recherche de NVIDIA Research, en collaboration avec l'Université de Washington, a mis au point une nouvelle méthode de distillation à longue portée.L'idée principale consiste à utiliser un modèle autorégressif, particulièrement performant pour générer une variabilité atmosphérique réaliste, comme « modèle d'apprentissage » afin de produire une grande quantité de données météorologiques synthétiques par simulation rapide et peu coûteuse. Ces données servent ensuite à entraîner un modèle probabiliste « élève ». Ce dernier n'a besoin que d'un seul calcul pour générer des prévisions à long terme, évitant ainsi l'accumulation d'erreurs d'itération et contournant le problème complexe de la calibration des données.
Cette approche s'écarte du cadre de la modélisation autorégressive et compresse les données climatiques à grande échelle dans un modèle génératif conditionnel, surmontant ainsi les limitations liées à la rareté des données d'apprentissage dans les études précédentes. La recherche a utilisé un modèle autorégressif couplé capable de simuler de manière stable un siècle de climat comme modèle d'apprentissage, générant des échantillons d'apprentissage bien plus importants que les relevés climatiques réels. Des expériences préliminaires montrent que le modèle « élève », entraîné à partir de ce modèle, offre des performances comparables au système de prévision intégré du CEPMMT pour les prévisions S2S, et que ses performances s'améliorent continuellement avec l'augmentation du volume de données synthétiques. Ceci laisse entrevoir la possibilité d'obtenir des prévisions climatiques à l'échelle mondiale plus fiables et plus économiques à l'avenir.
Les résultats de recherche connexes, intitulés « Distillation à longue portée : distiller 10 000 ans de climat simulé dans des modèles météorologiques d'IA à long pas de temps », ont été publiés sur arXiv.
Points saillants de la recherche :
* Dépasser la limite temporelle des données d'observation réelles, en utilisant des modèles météorologiques d'IA pour générer des données climatiques synthétiques sur plus de 10 000 ans, permettant au modèle d'apprendre des modes climatiques à variation lente qui n'ont pas été pleinement présentés dans les observations réelles ;
* Nous proposons une méthode de distillation à longue distance qui peut produire un modèle de prévision de probabilité à long terme avec un seul calcul en une seule étape, surmontant ainsi les problèmes d'accumulation d'erreurs et d'instabilité causés par des centaines d'itérations dans le cadre autorégressif traditionnel ;
* Après avoir été adapté aux données du monde réel, le modèle a atteint un niveau de performance comparable à celui du système opérationnel du Centre européen pour les prévisions météorologiques à moyen terme en matière de prévisions sub-saisonnières et saisonnières.
Adresse du document :https://arxiv.org/abs/2512.22814 Suivez notre compte WeChat officiel et répondez « distillation à distance » en arrière-plan pour obtenir le PDF complet.
Autres articles sur les frontières de l'IA : https://hyper.ai/papers
Ensembles de données : un cadre pour la génération, la classification et l'évaluation des données climatiques synthétiques
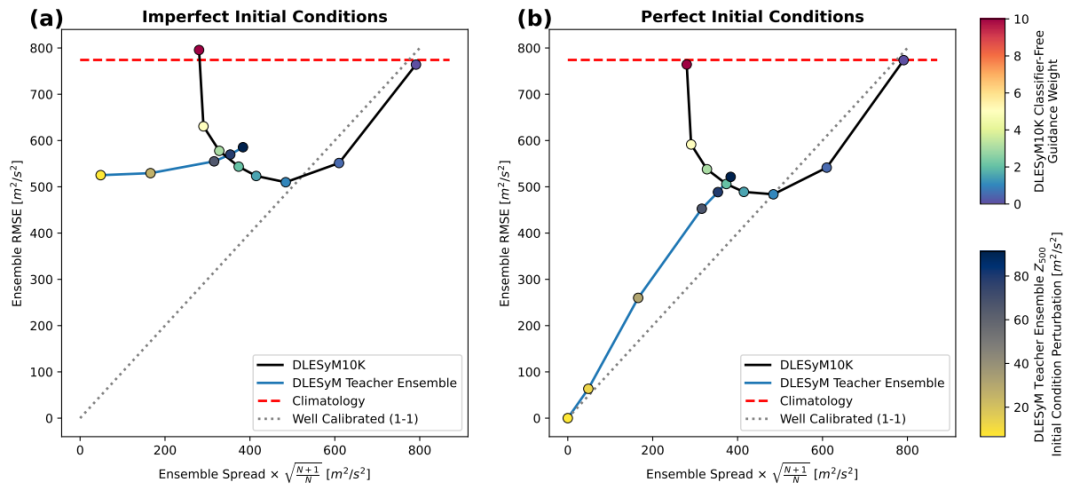
Pour évaluer la capacité de prévision intégrée et dépendante du temps du modèle de distillation à longue distance, cette étude l'a d'abord validée dans des expériences de modèle idéal contrôlées.Toutes les données d'évaluation ont été extraites des données de simulation réservées par le modèle d'enseignant autorégressif DLESyM (Deep Learning Earth System Model).De plus, cette configuration n'a jamais été utilisée lors de l'entraînement du modèle de distillation. Son objectif principal était d'examiner les performances du modèle de distillation à long pas et du modèle enseignant DLESyM pour la prévision de conditions météorologiques simulées inédites, lorsque les conditions initiales n'étaient pas entièrement déterminées, garantissant ainsi l'objectivité de l'évaluation.
L'évaluation a non seulement utilisé des métriques déterministes telles que l'erreur quadratique moyenne (RMSE) de l'ensemble, mais a également introduit le score de probabilité de classement continu (CRPS), un outil d'évaluation probabiliste des prévisions, afin de mesurer plus complètement la performance des prévisions. Les chercheurs ont sélectionné trois prévisions initiales avec différents mécanismes de prévisibilité pour les tests :
* Horizon temporel à moyen terme :
Pour la prévision moyenne quotidienne sur 7 jours (paramètres N=28, M=4), les données réservées du 1er janvier 2017 au 10 mars 2019 (année simulée) ont été utilisées, avec une date initiale sélectionnée tous les 2 jours, ce qui a donné lieu à plus de 400 échantillons.
* Période S2S :
Pour la prévision moyenne hebdomadaire sur 4 semaines (paramètres N=112, M=28), les données du 1er janvier 2017 au 16 mai 2021 (année simulée) ont été utilisées, avec une date initiale tous les 4 jours, et la taille de l'échantillon a également dépassé 400.
* Validité saisonnière :
Pour la prévision moyenne mensuelle sur 12 semaines (paramètres N=336, M=112), les données du 1er janvier 2017 au 28 septembre 2025 (année simulée) ont été utilisées, avec une date initiale sélectionnée tous les 8 jours, ce qui donne une taille d'échantillon d'environ 400.
Afin de garantir l'indépendance des modèles, les chercheurs ont divisé environ 15 000 ans de données de simulation climatique synthétique générées par DLESYM en un ensemble d'entraînement (751 TP3T, soit environ 11 000 ans) et un ensemble de validation (251 TP3T), en fonction de leur appartenance à l'ensemble. Ils ont ensuite entraîné des modèles de distillation indépendants pour chaque échéance de prévision. La génération de ces données synthétiques a fait appel à une stratégie parallèle : 200 dates initiales ont été sélectionnées de manière homogène entre le 1er janvier 2008 et le 31 décembre 2016, chaque date correspondant à une simulation de 90 ans.Cela a permis d'obtenir des données climatiques couvrant une période totale de 18 000 ans.
L'objectif ultime de cette recherche est d'appliquer le modèle entraîné à des prévisions réelles à long terme. Il est important de noter que le « climat du modèle » généré par le fonctionnement à long terme de DLESyM diffère du climat réel. Par conséquent, lors du transfert du modèle vers des applications concrètes, ce problème de « transfert de domaine » doit être abordé comme un axe prioritaire.
Distillation à longue distance : une double innovation entre « distillation de données » et « étalonnage probabiliste »
L'idée novatrice qui sous-tend les méthodes de distillation à longue distance réside dans...Il utilise un modèle autorégressif à pas court qui peut fonctionner de manière stable pendant longtemps comme « professeur » pour entraîner un modèle « élève » capable de produire des prévisions à long terme en une seule étape de calcul.Cela permet d'éviter fondamentalement le problème d'accumulation d'erreurs causé par des centaines d'itérations dans le cadre autorégressif traditionnel.
Plus précisément, les chercheurs définissent une cible de prévision à long terme – l'état moyen sur une période future – à partir de la séquence glissante à long terme du modèle enseignant. Le modèle élève apprend ensuite directement la distribution de probabilité conditionnelle de l'état initial vers cette cible à long terme. L'atout majeur du modèle enseignant réside dans sa capacité à générer efficacement des quantités massives de données synthétiques, bien supérieures à l'échelle des données de réanalyse originales, résolvant ainsi le problème de la rareté des échantillons d'entraînement pour les prévisions à long terme.
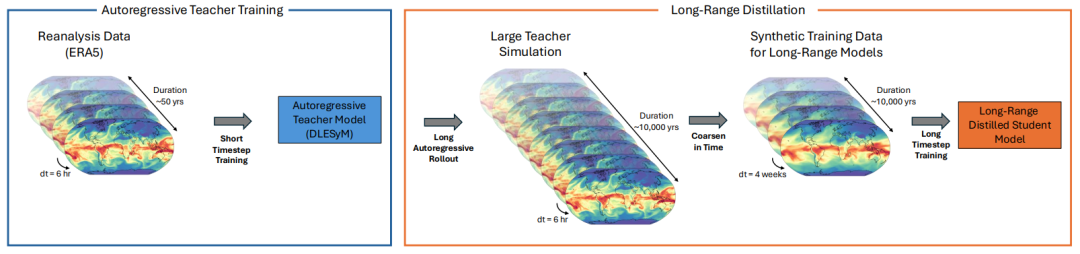
Pour atteindre cet objectif,Cette étude utilise le modèle DLESYM comme « enseignant ».Le modèle est initialisé à partir des données de réanalyse ERA5 et prévoit des variables clés telles que la température de surface de la mer, la température de l'air et la hauteur géopotentielle. Les chercheurs ont conçu une stratégie de génération de données efficace : 200 dates initiales ont été sélectionnées de manière homogène entre 2008 et 2016, et des simulations ont été menées en parallèle sur une période de 90 ans, ce qui a permis d'obtenir un total de 18 000 ans de données climatiques synthétiques. Grâce à la puissance de calcul des ordinateurs, le processus de génération des données n'a pris que quelques heures, démontrant ainsi pleinement les avantages de l'intelligence artificielle en matière de simulation climatique. Après un contrôle qualité, environ 15 000 ans de données valides ont été utilisés pour l'entraînement et la validation du modèle.
Le modèle « Student » utilise une architecture de modèle de diffusion conditionnelle et est spécifiquement conçu pour la prévision probabiliste.L'objectif est de modéliser la relation complexe entre les conditions météorologiques futures à long terme et les conditions d'entrée (telles que les conditions moyennes journalières des quatre jours précédents). L'architecture du modèle repose sur un réseau UNet amélioré, adapté à la grille HEALPix, qui capture efficacement les dépendances spatio-temporelles du champ météorologique global grâce à l'introduction d'embeddings spatiaux et temporels périodiques apprenables. Lors de l'entraînement, les chercheurs ont utilisé une stratégie spécifique de gestion du bruit afin de garantir que le modèle apprenne les caractéristiques des données à toutes les échelles.
Pour calibrer avec précision l'incertitude des prédictions de probabilité, cette étude introduit de manière novatrice un « guidage sans classificateur ».Il permet un contrôle flexible de la dispersion de l'ensemble des prévisions en ajustant un simple paramètre de pondération pendant la phase d'inférence du modèle.Cela permet un équilibre optimal entre l'erreur de prévision et la précision des prédictions, facilitant ainsi la génération de prévisions de probabilité bien calibrées.
Pour permettre au modèle d'effectuer des prévisions réalistes, cette étude a mis en œuvre une double stratégie afin de résoudre le problème du « décalage de domaine ». Premièrement, des corrections des biais climatiques ont été appliquées pour rectifier les différences systématiques entre les données simulées et les observations réelles à l'état moyen. Deuxièmement, le modèle a été affiné à l'aide de données de réanalyse ERA5 limitées, en mettant à jour uniquement certains paramètres clés du réseau. Cela a permis au modèle de conserver les tendances apprises à partir d'un volume important de données synthétiques tout en s'adaptant mieux aux caractéristiques de l'atmosphère réelle. Enfin, la compétitivité du modèle dans des scénarios réels a été évaluée par comparaison avec des systèmes opérationnels de référence tels que le Centre européen pour les prévisions météorologiques à moyen terme (CEPMMT).
Des avancées majeures à plusieurs niveaux : des données évolutives, des prévisions calibrables et des compétences comparables à celles des systèmes d’information des entreprises de premier plan.
À travers une série d'expériences, cette étude a systématiquement vérifié les performances et le potentiel du modèle de distillation à longue distance dans quatre domaines : l'impact de l'échelle des données d'entraînement, l'étalonnage de l'incertitude des prévisions, les capacités de prévision multi-temporelle et la comparaison avec les systèmes opérationnels.
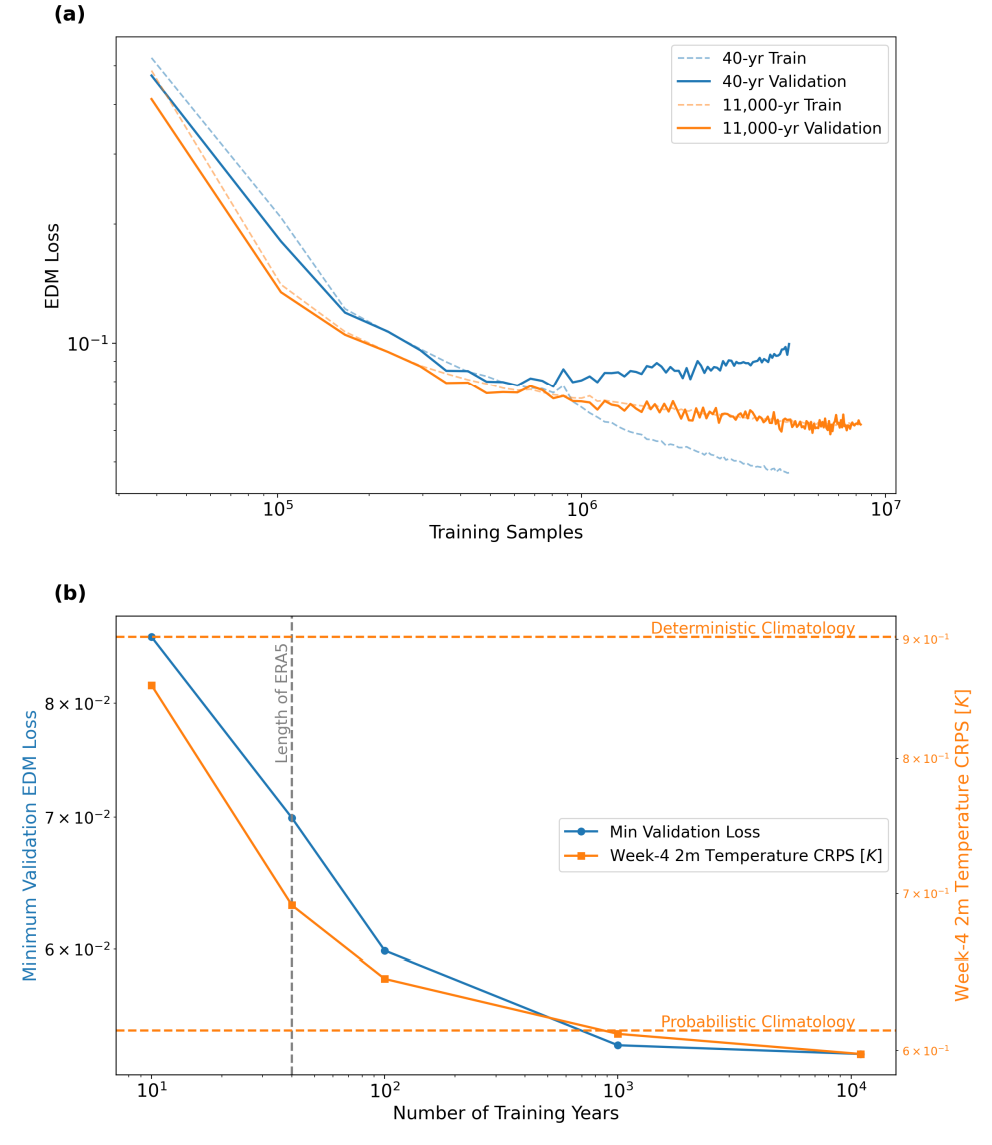
Premièrement, cette étude a validé l'hypothèse principale : l'augmentation de la quantité de données d'entraînement synthétiques peut améliorer significativement la capacité prédictive du modèle. Comme le montre la figure ci-dessous, le modèle entraîné avec seulement 40 ans de données simulées a rapidement surajusté, tandis que le modèle entraîné sur environ 11 000 ans de données synthétiques (DLESyM10K) a présenté une courbe d'apprentissage stable. Plus important encore,L'augmentation du volume de données se traduit directement par une amélioration des capacités de prévision :Dans les prévisions de température sur 4 semaines, le score CRPS a diminué de 14%. Ceci démontre pour la première fois que l'utilisation de modèles autorégressifs pour générer des données synthétiques à grande échelle permet de construire efficacement des modèles de prévision à long terme plus robustes.
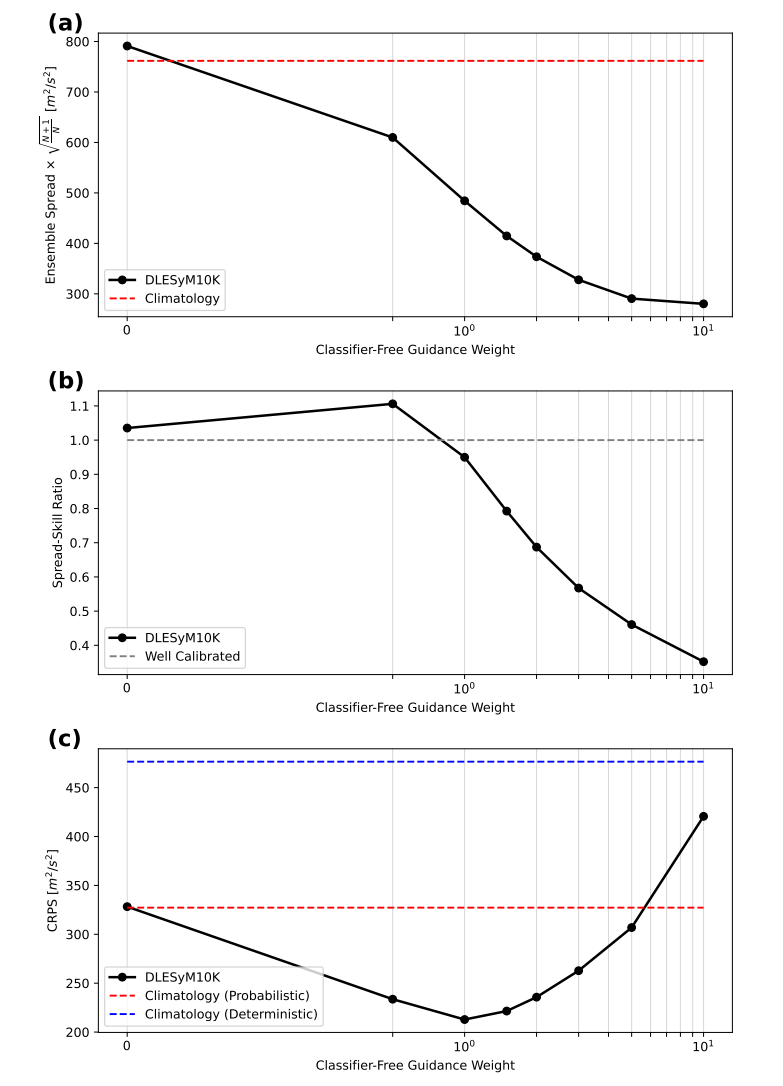
Cette étude utilise une technique de « guidage sans classificateur » pour calibrer la dispersion des prévisions probabilistes. En ajustant l'intensité du guidage, la dispersion de l'ensemble des prévisions peut être contrôlée, permettant d'atteindre un équilibre optimal avec les erreurs de prévision. Les expériences montrent que…Lorsque la force de guidage est réglée sur 1, le modèle peut automatiquement obtenir un bon étalonnage ;Si des ajustements s'avèrent nécessaires, le paramètre peut être facilement modifié lors de la phase d'inférence. Ceci offre une méthode d'étalonnage efficace et flexible pour la prévision probabiliste.
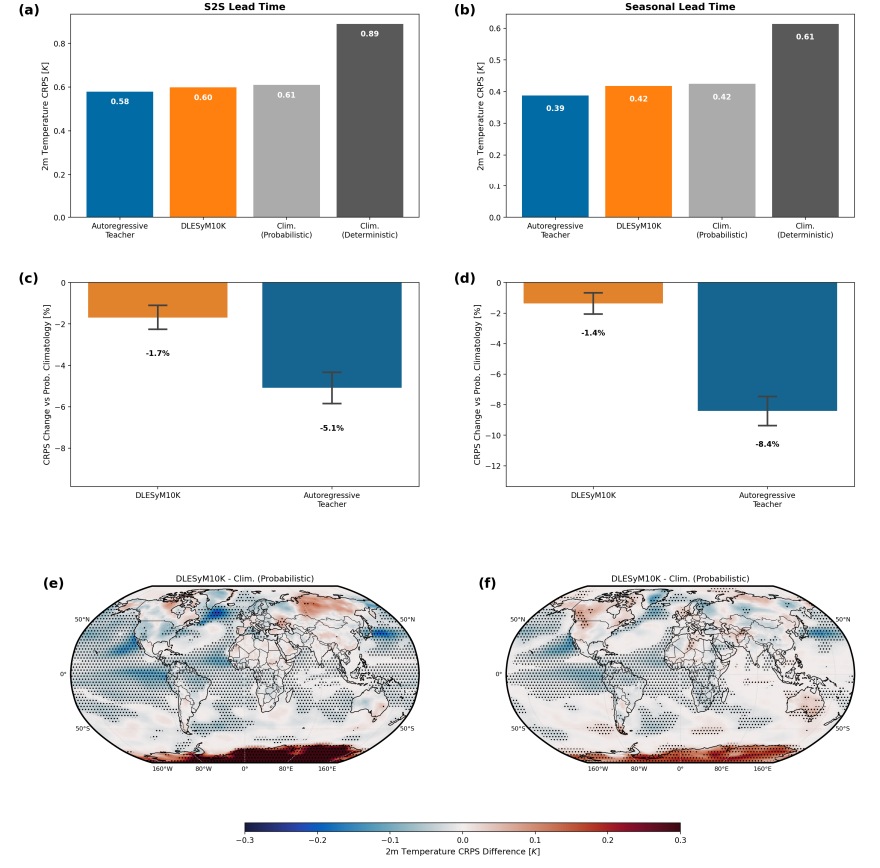
Le modèle démontre des performances robustes dans les prévisions à moyen terme, sub-saisonnières à saisonnières (S2S) et saisonnières.Dans les prévisions à moyen terme, le modèle fait preuve d'une grande robustesse face aux erreurs initiales, et ses caractéristiques de modélisation probabiliste contribuent à atténuer les incertitudes liées aux conditions initiales. Pour les prévisions S2S et saisonnières plus complexes, DLESyM10K surpasse nettement les modèles climatologiques de référence, notamment dans les régions très prévisibles comme les tropiques et les océans. Notamment,Il atteint un niveau de compétence comparable à celui d'un modèle d'enseignant autorégressif avec des centaines d'itérations grâce à un calcul en une seule étape.Cela démontre l'efficacité du cadre.
Lors du transfert du modèle aux prévisions réelles, un ajustement fin et une correction des biais ont permis de corriger l'écart entre le « climat du modèle » et le climat réel. Une comparaison avec le système opérationnel du Centre européen pour les prévisions météorologiques à moyen terme (CEPMMT) montre :Après quelques ajustements, les performances de prévision de température à 4 semaines du système DLESyM10K sont très proches de celles du système ECMWF, et les deux sont nettement supérieures à la référence climatologique.L'analyse régionale révèle que chaque modèle présente des atouts spécifiques selon les régions géographiques ; par exemple, DLESyM10K est plus performant dans certaines parties des Amériques et de l'Afrique centrale. Ceci démontre le potentiel du modèle d'IA à rivaliser avec les systèmes d'information d'entreprise les plus avancés, tout en soulignant sa valeur ajoutée.
En résumé, la méthode de distillation à long terme, grâce à une combinaison de mise à l'échelle des données et de modélisation probabiliste en une seule étape, entraîne un modèle de diffusion conditionnelle capable de fournir en une seule étape des prévisions probabilistes à long terme et réalise un étalonnage flexible de l'incertitude en intégrant des techniques de guidage sans classificateur. Les expériences montrent que…Cette méthode a permis d'obtenir des performances comparables à celles du système opérationnel du Centre européen pour les prévisions météorologiques à moyen terme (CEPMMT) pour les prévisions sub-saisonnières à saisonnières.Ce paradigme offre non seulement une nouvelle approche des prévisions météorologiques à long terme, mais jette également les bases de la construction d'un modèle génératif général au service de l'exploration des sciences du climat.
La collaboration mondiale entre l'industrie, le monde universitaire et la recherche accélère la transformation des technologies météorologiques
L'utilisation de l'IA pour générer des données synthétiques et pallier le manque de données dans les prévisions à long terme représente une voie importante pour la collaboration entre les milieux universitaires et industriels, favorisant ainsi l'innovation dans le domaine de la prévision météorologique. De nombreuses pratiques de recherche et d'ingénierie de pointe ont émergé, contribuant à faire progresser la prévision météorologique à long terme, de la phase théorique à l'application opérationnelle.
Dans le milieu universitaire, la collaboration interdisciplinaire devient essentielle pour surmonter les principaux défis technologiques. Par exemple,L'« Initiative climatique pour l'IA (AICE) » de l'Université de ChicagoCette organisation, qui réunit des experts en climatologie, en informatique et en statistiques, se consacre à la réduction significative des coûts de calcul des prévisions climatiques. Sa technologie a permis de générer des prévisions de haute qualité à l'aide d'ordinateurs portables classiques et devrait contribuer à réduire les disparités en matière de prévisions météorologiques entre les différentes régions.
L'Université de Cambridge, en collaboration avec l'Institut Turing, le Centre européen pour les prévisions météorologiques à moyen terme et d'autres institutions, a développé conjointement Aardvark Weather, un système de prévision de bout en bout basé sur les données.Ce système peut intégrer de multiples données d'observation et produire simultanément des prévisions globales et des prévisions locales, affichant des performances comparables à celles des modèles numériques opérationnels optimisés pour des prévisions à 10 jours. Son approche de modélisation intégrée est en parfaite adéquation avec l'objectif initial de simplifier le processus de prévision par distillation à long terme, fournissant ainsi un modèle technique pour améliorer la précision des prévisions à long terme.
* Cliquez pour afficher Météo Aardvark Analyse approfondie :Nature, l'Université de Cambridge et d'autres ont publié le premier système de prévision météorologique de bout en bout basé sur les données, qui augmente la vitesse de prévision de dizaines de fois
Titre de l'article : Prévisions météorologiques de bout en bout basées sur les données
* Adresse du papier :
https://www.nature.com/articles/s41586-025-08897-0
Dans l'industrie, les pratiques innovantes privilégient la mise en œuvre technique et l'application des technologies à des scénarios précis. Les entreprises technologiques repoussent sans cesse les limites technologiques de la météorologie par IA grâce à une implication forte dans les collaborations entre l'industrie, le monde universitaire et la recherche, ainsi que dans la recherche et le développement indépendants. Par exemple,Microsoft, Google DeepMind et d'autres organisations ont été fortement impliquées dans le développement du système météorologique Aardvark.Les atouts de Google DeepMind en matière de traitement de données à grande échelle et d'architecture d'apprentissage profond permettent d'améliorer l'efficacité et la précision des modèles météorologiques. De plus, son expertise dans les modèles génératifs et le calibrage des prévisions probabilistes apporte des informations précieuses pour la résolution de problèmes tels que le contrôle de la dispersion d'ensemble dans la distillation à longue distance.
Parallèlement, les entreprises encouragent activement l'application de l'intelligence artificielle en météorologie à des situations spécifiques. Par exemple, en collaborant avec les gestionnaires de parcs et les services d'urgence, elles intègrent des technologies de prévision précises à long terme dans des systèmes intelligents de prévention des catastrophes. Grâce à une simulation complète de l'évolution d'une catastrophe, elles proposent des services de prévision personnalisés pour des domaines tels que la sécurité des parcs, la gestion de l'eau et la production agricole, garantissant ainsi que les utilisateurs finaux bénéficient réellement des prévisions météorologiques à long terme.
Ces recherches menées par le monde universitaire et l'industrie ont non seulement vérifié la faisabilité des approches techniques que sont la distillation des données et la modélisation en une seule étape, mais ont aussi progressivement formé un cercle vertueux où les « percées académiques orientent la recherche et l'innovation technique stimule la mise en œuvre », favorisant ainsi le développement continu des prévisions météorologiques mondiales par IA vers une direction plus précise, plus efficace et plus inclusive.
Liens de référence :
1.https://climate.uchicago.edu/entities/aice-ai-for-climate/








