Command Palette
Search for a command to run...
Avancée Majeure En Vision 3D : ByteSeed Lance DA3, Permettant La Reconstruction De L’espace Visuel Depuis N’importe Quel Point De Vue ; Plus De 70 000 Données D’environnements Industriels Réels ! CHIP Comble Le Manque De Données Industrielles Pour L’estimation De Pose 6D.

La capacité à percevoir et à comprendre les informations spatiales tridimensionnelles à partir d'entrées visuelles est la pierre angulaire de l'intelligence spatiale et une condition essentielle pour des applications telles que la robotique et la réalité mixte. Cette capacité fondamentale a donné naissance à diverses tâches de vision tridimensionnelle, comme l'estimation de profondeur monoculaire, la reconstruction 3D à partir du mouvement, la vision stéréoscopique multivue et la localisation et la cartographie simultanées.
Ces tâches ne diffèrent souvent que par quelques facteurs, comme le nombre de vues d'entrée, et présentent donc un fort chevauchement conceptuel. Cependant, le paradigme dominant actuel consiste encore à développer des modèles hautement spécialisés pour chaque tâche. La construction d'un modèle de compréhension 3D unifié, capable de gérer plusieurs tâches, est devenue une voie de recherche importante.Cependant, les solutions existantes reposent généralement sur des architectures de réseau complexes et personnalisées et nécessitent un apprentissage à partir de zéro par le biais d'une optimisation conjointe multitâche.Il est donc difficile d'assimiler et d'utiliser pleinement les connaissances et les avantages des modèles pré-entraînés à grande échelle.
Sur cette base,L'équipe Seed de ByteDance a lancé Depth Anything 3 (DA3).Un seul modèle Transformer, spécialement entraîné et basé sur des représentations de rayons spécifiques, peut estimer conjointement la profondeur et la pose depuis n'importe quel point de vue. Dans sa quête d'une simplification extrême des modèles, DA3 apporte deux conclusions majeures :
*Un seul transformateur standard (tel que l'encodeur DINO de base) peut être utilisé comme réseau principal.Aucune personnalisation de structure spécifique à la tâche n'est requise ;
*Prédiction des cibles à l'aide d'un seul rayon de profondeur.D'excellentes performances peuvent être obtenues sans avoir recours à un mécanisme d'apprentissage multitâche complexe.
L'équipe de recherche a également établi un nouveau banc d'essai de géométrie visuelle couvrant l'estimation de la pose de la caméra, la géométrie de point de vue arbitraire et le rendu visuel. Dans ce test,DA3 met à jour l'état dans toutes les missions.La précision de la pose de la caméra est en moyenne supérieure de 35,71 TP3T à celle de VGGT, la précision géométrique est améliorée de 23,61 TP3T et l'estimation de la profondeur monoculaire est supérieure à celle du modèle précédent DA2. Les expériences montrent que cette méthode minimaliste est suffisante pour reconstruire l'espace visuel à partir d'un nombre quelconque d'images (que la pose de la caméra soit connue ou non).
Le site web d'HyperAI propose désormais « Depth-Anything-3 : Recovering Visual Space from Any Viewpoint », alors essayez-le !
Utilisation en ligne :https://go.hyper.ai/MXyML
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 15 au 19 décembre :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en janvier : 11
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données d'évaluation du modèle de récompense vidéo VideoRewardBench
VideoRewardBench, développé conjointement par l'Université des sciences et technologies de Chine et le laboratoire Huawei Noah's Ark, est le premier banc d'essai d'évaluation complet couvrant quatre dimensions fondamentales de la compréhension vidéo : la perception, la connaissance, le raisonnement et la sécurité. Il vise à évaluer systématiquement la capacité des modèles à formuler des préférences et à évaluer la qualité des résultats générés dans des scénarios complexes de compréhension vidéo. L'ensemble de données contient 1 563 échantillons étiquetés, comprenant 1 482 vidéos différentes et 1 559 questions différentes. Chaque échantillon est composé d'une séquence vidéo-texte, d'une réponse souhaitée et d'une réponse de rejet.
Utilisation directe :https://go.hyper.ai/JIB1B
2. Ensemble de données d'évaluation de la génération d'écriture Arena-Write
Arena-Write est un jeu de données de tâches d'écriture publié par l'Université de technologie et de design de Singapour (SUDT) en collaboration avec le Laboratoire d'ingénierie des connaissances de l'Université Tsinghua. Il est conçu pour évaluer les modèles de génération de textes longs et analyser systématiquement les capacités globales des grands modèles de langage à générer du contenu long et des tâches d'écriture complexes dans des scénarios d'utilisation réalistes. Le jeu de données contient 100 tâches d'écriture utilisateur, chacune composée d'une consigne d'écriture issue du monde réel et étiquetée avec le type de scénario d'écriture correspondant.
Utilisation directe :https://go.hyper.ai/4NQdD
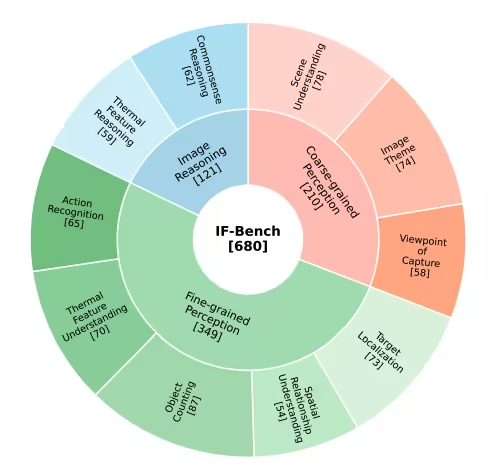
3. Ensemble de données de référence pour la compréhension d'images infrarouges IF-Bench
IF-Bench est un banc d'essai de haute qualité pour la compréhension multimodale d'images infrarouges, développé conjointement par l'Institut d'automatisation de l'Académie chinoise des sciences et l'École d'intelligence artificielle de l'Université de l'Académie chinoise des sciences. Il vise à évaluer systématiquement les capacités de compréhension sémantique des grands modèles de langage multimodaux (MLLM) pour les images infrarouges. L'ensemble de données comprend 499 images infrarouges et 680 paires question-réponse visuelles (VQA). Les images proviennent de 23 ensembles de données d'images infrarouges différents, assurant une distribution globale relativement équilibrée.
Utilisation directe :https://go.hyper.ai/hty3u
4. Ensemble de données d'estimation de pose 6D de la chaise industrielle CHIP
CHIP est un jeu de données d'estimation de pose 6D destiné à la manipulation robotique dans des contextes industriels réels. Développé par FBK-TeV en collaboration avec Ikerlan et Andreu World, il vise à combler le manque de données dans les benchmarks existants, qui se concentrent principalement sur les objets du quotidien et les configurations de laboratoire, et ne prennent pas en compte les conditions industrielles réelles. Le jeu de données contient 77 811 images RGB-D, représentant des modèles de chaises de sept structures et matériaux différents.
Utilisation directe :https://go.hyper.ai/AR5Xm
5. Ensemble de données semi-structurées SSRB pour les requêtes en langage naturel
SSRB est un jeu de données de référence à grande échelle pour l'interrogation en langage naturel de données semi-structurées. Publié conjointement par l'Institut de technologie de Harbin (Shenzhen), l'Université polytechnique de Hong Kong, l'Université Tsinghua et d'autres institutions, il a été sélectionné pour les jeux de données et les benchmarks NeurIPS 2025, dans le but d'évaluer et d'améliorer la capacité des modèles à extraire des données semi-structurées dans des conditions d'interrogation complexes en langage naturel.
Utilisation directe :https://go.hyper.ai/szsqF
6. INFINITY-CHAT Ensemble de données de questions-réponses ouvertes en situation réelle
INFINITY-CHAT, le premier jeu de données à grande échelle de questions ouvertes posées par des utilisateurs dans le monde réel, publié par l'Université de Washington en collaboration avec l'Université Carnegie Mellon et l'Institut Allen pour l'intelligence artificielle, a remporté le prix du meilleur article (catégorie bases de données) à NeurIPS 2025. Ce projet vise à étudier de manière systématique des questions clés telles que la diversité des modèles de langage dans la génération de questions ouvertes, les différences de préférences humaines et l'« effet d'essaim artificiel ».
Utilisation directe :https://go.hyper.ai/KmH1N
7. MUVR : Analyse comparative de la recherche vidéo multimodale non recadrée
MUVR est un jeu de données de référence pour la recherche de vidéos multimodales non montées, publié conjointement par l'Université d'aéronautique et d'astronautique de Nanjing, l'Université de Nanjing et l'Université polytechnique de Hong Kong. Sélectionné pour les jeux de données et les benchmarks de NeurIPS 2025, il vise à promouvoir la recherche sur la recherche vidéo sur les plateformes de vidéos longues. Ce jeu de données contient environ 53 000 vidéos non montées issues de Bilibili, 1 050 requêtes multimodales et 84 000 correspondances requête-vidéo, couvrant divers types de vidéos courants tels que l'actualité, les voyages et la danse.
Utilisation directe :https://go.hyper.ai/NRaSw

8. Ensemble de données d'évaluation complète de l'oubli de graphes OpenGU
OpenGU est un jeu de données d'évaluation complet pour le désapprentissage de graphes (GU), publié par l'Institut de technologie de Pékin. Sélectionné pour les jeux de données et les benchmarks de NeurIPS 2025, il vise à fournir un cadre d'évaluation unifié, des ressources de données multi-domaines et des paramètres expérimentaux standardisés pour les méthodes d'oubli dans les réseaux neuronaux de graphes.
Utilisation directe :https://go.hyper.ai/qqHct
9. Ensemble de données d'évaluation des tâches de recherche en inférence de FrontierScience
FrontierScience, publié par OpenAI, est un jeu de données destiné à l'évaluation des tâches d'inférence et de recherche scientifique. Il vise à évaluer systématiquement les capacités des grands modèles dans des sous-tâches de raisonnement scientifique et de recherche de niveau expert. Ce jeu de données repose sur un mécanisme de conception combinant « contenu original d'experts », une structure de tâches à deux niveaux et un système de notation automatique. Il est divisé en deux sous-ensembles : Olympiades et Recherche.
Utilisation directe :https://go.hyper.ai/fUUzF
10. Base de données de questions-réponses sur les premiers secours FirstAidQA
FirstAidQA est un ensemble de données de questions-réponses dédié aux premiers secours et aux interventions d'urgence, publié par l'Université islamique des sciences et technologies. Il vise à faciliter l'entraînement et l'application de modèles dans des contextes d'urgence aux ressources limitées. Cet ensemble de données contient 5 500 paires question-réponse de haute qualité, couvrant une variété de situations typiques de premiers secours et d'interventions d'urgence.
Utilisation directe :https://go.hyper.ai/QQphC
Tutoriels publics sélectionnés
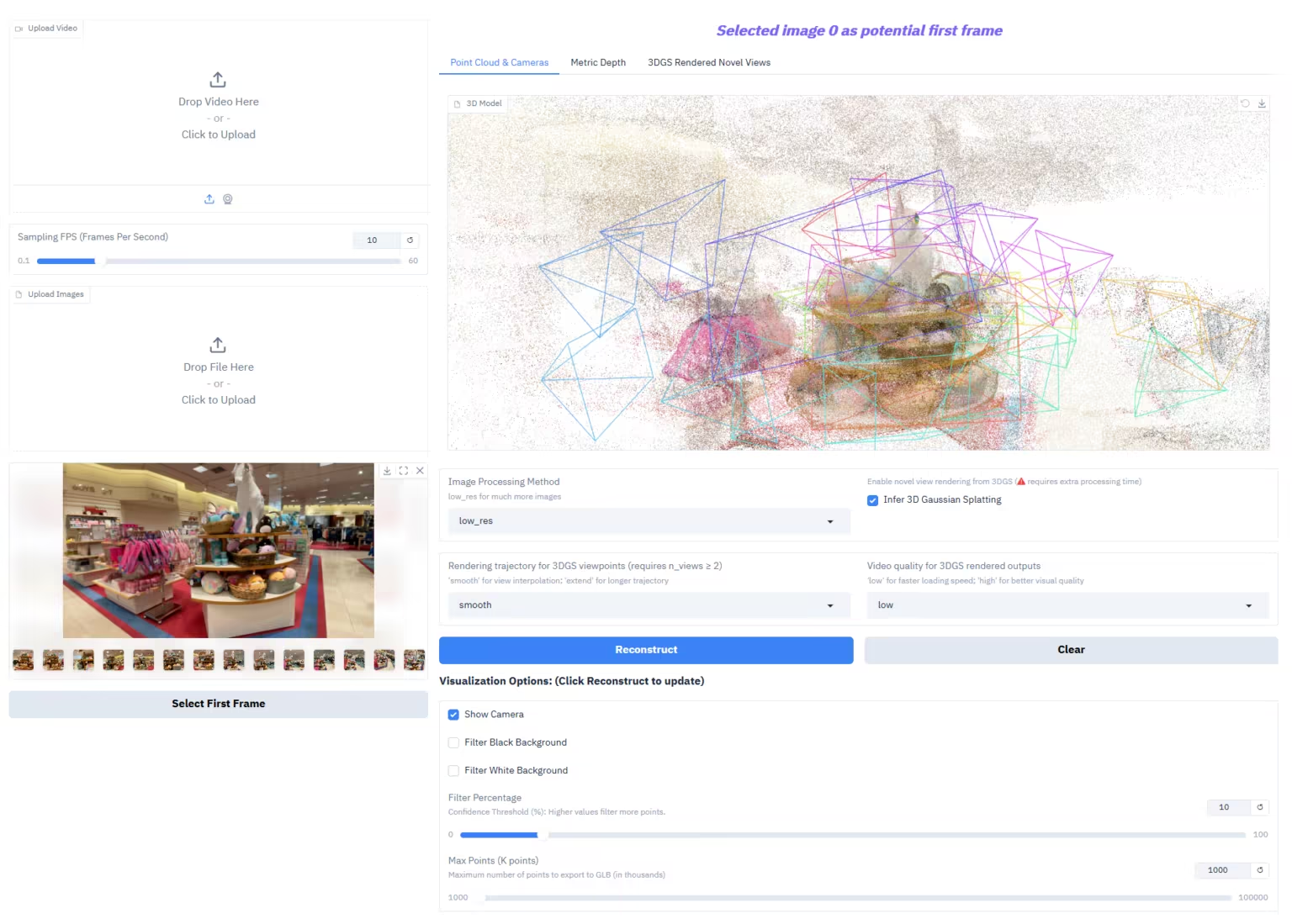
1. Profondeur-Tout-3 : Restaurer l’espace visuel depuis n’importe quelle perspective
Depth-Anything-3 (DA3) est un modèle de géométrie visuelle révolutionnaire développé par l'équipe ByteDance-Seed. Il révolutionne les tâches de géométrie visuelle grâce au concept de « modélisation minimaliste » : il utilise un seul Transformer ordinaire (tel que l'encodeur DINO standard) comme réseau de base et remplace l'apprentissage multitâche complexe par une « représentation par rayons de profondeur » pour prédire des structures géométriques spatialement cohérentes à partir de n'importe quelle entrée visuelle (poses de caméra connues et inconnues).
Exécutez en ligne :https://go.hyper.ai/MXyML
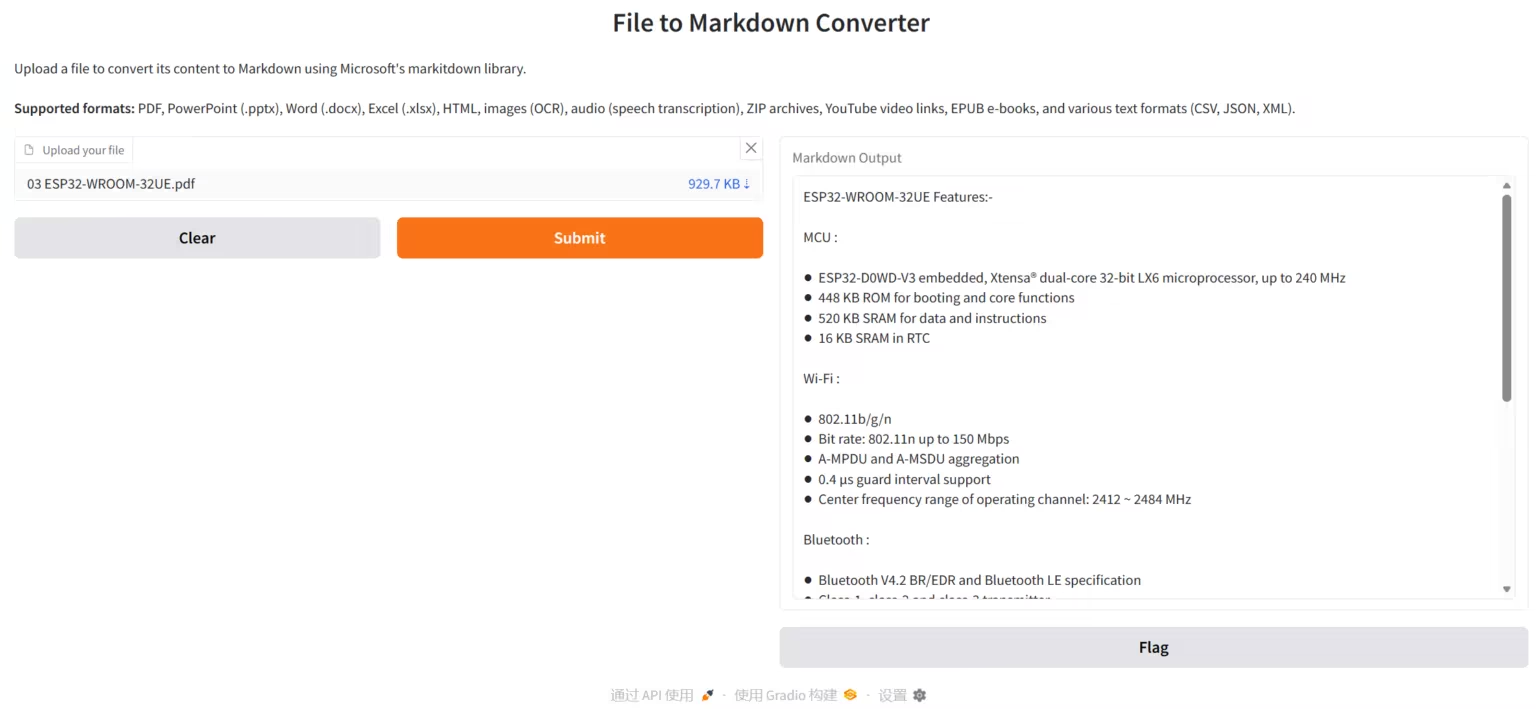
2. MarkItDown, l'outil de conversion de documents open source de Microsoft
MarkItDown est un outil de conversion de documents Python léger et prêt à l'emploi, développé par Microsoft. Il vise à convertir efficacement et de manière structurée divers formats de documents et de médias riches courants en Markdown, fournissant un format d'entrée optimisé spécifiquement pour les pipelines de compréhension et d'analyse de texte dans les grands modèles de langage (LLM).
Exécutez en ligne :https://go.hyper.ai/7WIGP
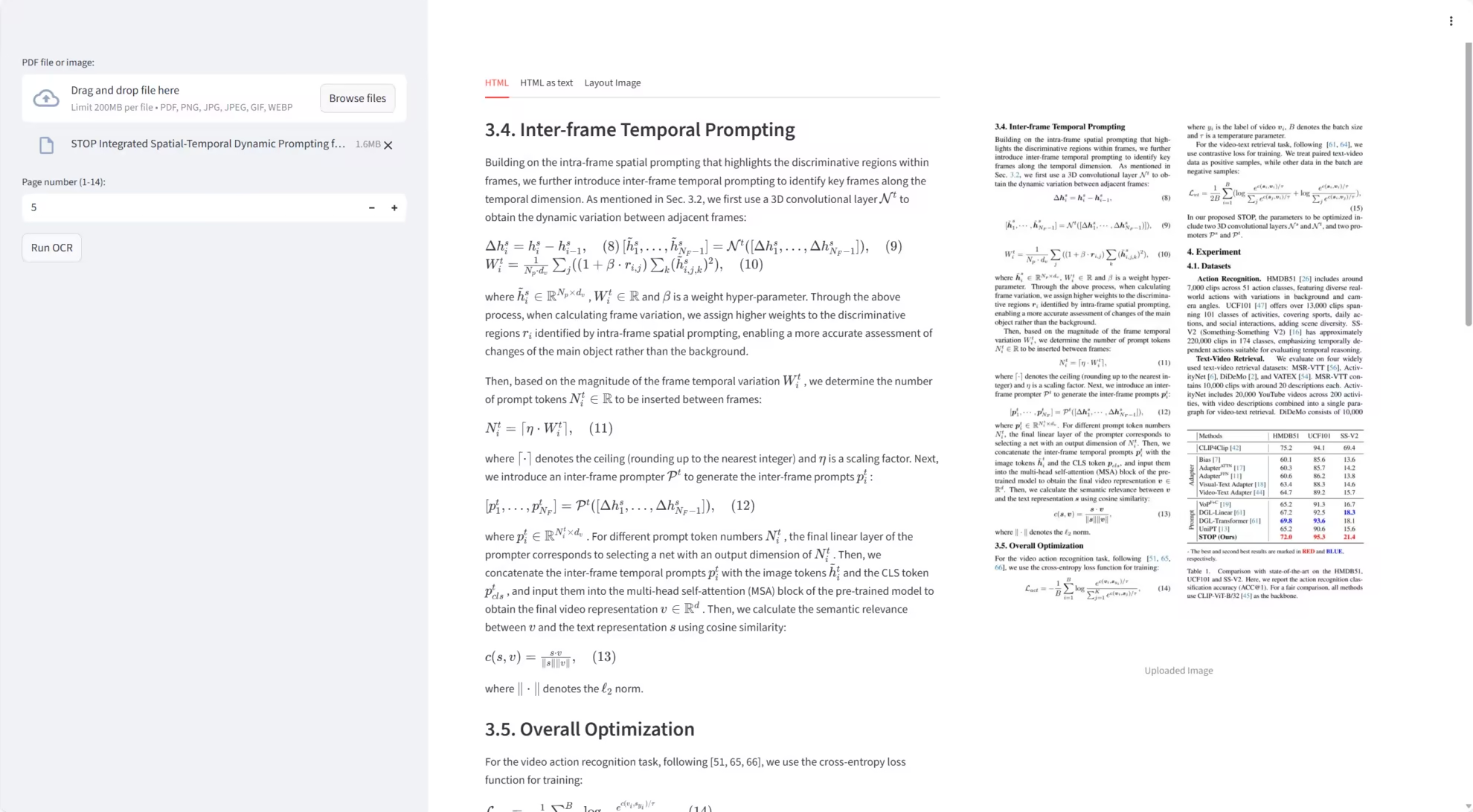
3. Chandra : OCR de documents de haute précision
Chandra est un système de reconnaissance optique de caractères (OCR) de haute précision développé par l'équipe Datalab-to. Axé sur la reconnaissance de la mise en page et l'extraction de texte, Chandra traite directement les fichiers PDF et image, générant des sorties en texte structuré, Markdown et HTML, et fournissant des schémas de mise en page pour une inspection aisée des résultats de l'OCR.
Exécutez en ligne :https://go.hyper.ai/nZhF5
Recommandation de papier de cette semaine
1. LongVie 2 : Modèle du monde vidéo ultra-long multimodal et contrôlable
Cet article propose LongVie 2, un cadre autorégressif de bout en bout qui atteint des performances de pointe en matière de contrôlabilité à longue portée, de cohérence temporelle et de fidélité visuelle, et prend en charge la génération de vidéos continues jusqu'à cinq minutes de long, marquant une étape clé vers la modélisation d'un monde vidéo unifié.
Lien vers l'article :https://go.hyper.ai/toK8K
2. MMGR : Raisonnement génératif multimodal
Cet article propose le cadre d'évaluation et de comparaison du raisonnement génératif multimodal (MMGR), un système d'évaluation systématique basé sur cinq capacités de raisonnement fondamentales : le raisonnement physique, le raisonnement logique, le raisonnement spatial 3D, le raisonnement spatial 2D et le raisonnement temporel. Le MMGR évalue les capacités de raisonnement des modèles génératifs dans trois domaines clés : le raisonnement abstrait (ARC-AGI, Sudoku), la navigation incarnée (navigation et positionnement 3D dans le monde réel) et la compréhension du sens commun physique (scénarios sportifs et comportements interactifs complexes).
Lien vers l'article :https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5 : Recette post-entraînement pour le raisonnement en contexte long et la gestion de la mémoire
Cet article présente QwenLong-L1.5, un modèle qui atteint des capacités de raisonnement à long contexte supérieures grâce à des innovations systématiques post-entraînement. Basé sur l'architecture Qwen3-30B-A3B-Thinking, QwenLong-L1.5 obtient des performances proches de celles de GPT-5 et Gemini-2.5-Pro dans les benchmarks de raisonnement à long contexte, avec une amélioration moyenne de 9,90 points par rapport à ses modèles de référence. Dans les tâches ultra-longues (de 1 à 4 millions de jetons), son cadre d'agent de mémoire permet une amélioration significative de 9,48 points par rapport à l'agent de référence.
Lien vers l'article :https://go.hyper.ai/DxYGd
4. La mémoire à l'ère des agents IA
Cet article vise à passer en revue de manière systématique les développements les plus récents en matière de recherche sur la mémoire des agents. Il précise d'abord le champ d'application de la mémoire des agents, en la distinguant clairement de concepts connexes tels que la mémoire des grands modèles de langage (LLM), la génération augmentée par récupération (RAG) et l'ingénierie du contexte. Ensuite, il analyse la mémoire des agents selon trois perspectives unifiées : la forme, la fonction et la dynamique.
Lien vers l'article :https://go.hyper.ai/zfHTr
5. ReFusion : un modèle de langage à grande échelle de diffusion avec décodage autorégressif parallèle
Cet article propose ReFusion, un nouveau modèle de diffusion de masques qui offre des performances et une efficacité supérieures en élevant le décodage parallèle du niveau du jeton à un niveau supérieur, celui des « slots ». Chaque slot est une sous-séquence continue de longueur fixe. ReFusion améliore les performances de 341 TP3T en moyenne par rapport aux modèles de diffusion de masques précédents et multiplie par plus de 18 la vitesse d'inférence moyenne. De plus, il réduit considérablement l'écart de performances avec les modèles autorégressifs robustes tout en conservant un gain de vitesse moyen de 2,33.
Lien vers l'article :https://go.hyper.ai/YosaF
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. En utilisant moins de 100 000 points de données structurés pour l'entraînement, l'École polytechnique fédérale de Lausanne (EPFL) a proposé PET-MAD, atteignant une précision de simulation atomique comparable aux modèles professionnels.
Le modèle PET-MAD proposé par l'École polytechnique fédérale de Lausanne (EPFL) atteint une précision comparable à celle des modèles dédiés grâce à un ensemble de données couvrant une large gamme de diversité atomique et utilisant beaucoup moins d'échantillons d'entraînement que les modèles traditionnels, fournissant ainsi une démonstration convaincante du développement de la simulation atomique vers une plus grande efficacité et universalité.
Voir le rapport complet :https://go.hyper.ai/cpeR5
2. Tutoriel en ligne | Microsoft ouvre VibeVoice, permettant 90 minutes de dialogue naturel entre 4 rôles
Microsoft a rendu VibeVoice open source. Ce logiciel permet la synthèse vocale multilocutrice longue et évolutive. Le modèle peut synthétiser jusqu'à 90 minutes de parole avec un maximum de quatre locuteurs dans une fenêtre contextuelle de 64 Ko, offrant un timbre plus riche, une intonation plus naturelle et une restitution réaliste de l'atmosphère d'une conversation. Il présente une meilleure transférabilité dans les applications multilingues et ses performances globales surpassent celles des modèles de dialogue open source et propriétaires existants.
Voir le rapport complet :https://go.hyper.ai/YfDjq
3. Les membres initiaux de l'équipe CUDA critiquent vivement cuTile pour avoir « spécifiquement ciblé » Triton ; le paradigme Tile peut-il remodeler le paysage concurrentiel de l'écosystème de programmation GPU ?
En décembre 2025, près de vingt ans après la sortie de CUDA, NVIDIA a lancé « cuTile », un nouveau point d'entrée pour la programmation GPU. Ce nouveau cuTile restructure le noyau GPU à l'aide d'un modèle de programmation par tuiles, permettant aux développeurs d'écrire efficacement des noyaux sans avoir besoin de connaissances approfondies en CUDA C++, ce qui a suscité de nombreux débats au sein de la communauté. Bien qu'encore à ses débuts, les avantages théoriques de l'approche par tuiles, l'exploration par la communauté des outils de migration et les essais pratiques suggèrent que cuTile a le potentiel de devenir un nouveau paradigme pour la programmation GPU. Son avenir dépendra de la maturité de l'écosystème, des coûts de migration et des performances.
Voir le rapport complet :https://go.hyper.ai/H1b0n
4. Dario Amodei, qui privilégie une surveillance proactive, a intégré la sécurité de l'IA dans la mission de l'entreprise après avoir quitté OpenAI.
Alors que la course mondiale à l'IA s'accélère, Dario Amodei, avec sa position minoritaire en faveur d'une « réglementation précoce », est devenu une figure incontournable de la Silicon Valley. De la promotion d'une IA constitutionnelle à son influence sur les cadres réglementaires en Europe et aux États-Unis, il s'efforce d'établir un « protocole de gouvernance » similaire à TCP/IP pour l'ère de l'IA. L'enjeu n'est pas seulement la sécurité, mais aussi la capacité de l'IA à passer d'une progression technologique rapide à des applications stables au cours de la prochaine décennie. La stratégie d'Amodei redéfinit la logique même de l'industrie mondiale de l'IA.
Voir le rapport complet :https://go.hyper.ai/SwyNW
5. Une équipe dirigée par Li Yong de l'Université Tsinghua a proposé une méthode de régression symbolique neuronale qui peut améliorer la précision de la prédiction par 60%, en dérivant automatiquement des formules de dynamique de réseau de haute précision.
Le professeur Yong Li et son équipe du département de génie électronique de l'université Tsinghua ont proposé ND², une méthode de régression symbolique neuronale qui caractérise la dynamique des systèmes en dérivant automatiquement des formules mathématiques à partir des données. Cette méthode simplifie le problème de recherche sur les réseaux multidimensionnels en un système unidimensionnel et utilise un réseau neuronal pré-entraîné pour guider la découverte de formules de haute précision.
Voir le rapport complet :https://go.hyper.ai/wVktJ
Articles populaires de l'encyclopédie
1. Norme nucléaire
2. Mémoire à long terme bidirectionnelle (Bi-LSTM)
3. Vérité de terrain
4. Navigation incarnée
5. Images par seconde (IPS)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de janvier pour la conférence de haut niveau

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








