Command Palette
Search for a command to run...
Dévoiler l'inférence En IA : Le Modèle Parcimonieux d'OpenAI Rend Les Réseaux Neuronaux Transparents Pour La Première Fois ; Prédiction Des Calories Brûlées : Injection De Données Énergétiques Précises Dans Les Modèles De Fitness

Article original de Lin Jiamin HyperIA14 janvier 2026, 17h06Pékin
Ces dernières années, les grands modèles de langage ont connu des progrès fulgurants, mais leurs processus de décision internes demeurent une « boîte noire » complexe, difficile à suivre et à comprendre. Ce problème fondamental entrave sérieusement l'application fiable de l'IA dans des secteurs à haut risque comme la santé et la finance.La question de savoir comment rendre transparent et traçable le processus de réflexion d'un modèle reste un problème clé non résolu.
Sur cette base,OpenAI a publié Circuit Sparsity, un modèle de langage de grande taille comportant 0,4 milliard de paramètres, en décembre 2025. Il utilise la technologie de parcimonie des circuits pour réinitialiser 99,9% poids à zéro, construisant une architecture de calcul parcimonieuse interprétable.Dépassant les limites de la prise de décision « boîte noire » des Transformers traditionnels, ce modèle permet d'analyser le processus d'inférence de l'IA couche par couche. Fondamentalement, il transforme les réseaux neuronaux denses classiques en « circuits » clairsemés structurés grâce à une méthode d'apprentissage unique.
*parcimonie forcée dynamiqueContrairement aux méthodes traditionnelles, elle effectue un « élagage dynamique » à chaque étape de l'entraînement, ne conservant qu'un très petit nombre de poids avec la plus grande valeur absolue (comme 0,1%) à chaque tour, et forçant le reste à zéro, forçant ainsi le modèle à apprendre à fonctionner avec une connectivité minimale dès le début.
*Activer la parcimonieEn introduisant des fonctions d'activation à des endroits clés tels que les mécanismes d'attention, la sortie des neurones tend vers un état discret de « soit/soit », formant ainsi des canaux d'information clairs dans les réseaux clairsemés.
*Composants personnalisésLa norme RMSnorm est utilisée à la place de LayerNorm pour éviter la destruction de la sparsité ; et une table de consultation de bigrammes est introduite pour gérer la prédiction de mots simples, permettant au réseau principal de se concentrer davantage sur la logique complexe.
Le modèle entraîné selon la méthode décrite ci-dessus forme spontanément des « circuits » fonctionnellement définis et résolubles. Chaque circuit est responsable d'une sous-tâche spécifique. Les chercheurs peuvent clairement identifier que certains neurones sont spécifiquement utilisés pour détecter les guillemets simples, tandis que d'autres agissent comme des compteurs logiques. Comparé aux modèles denses traditionnels, le nombre de nœuds actifs nécessaires pour accomplir la même tâche est considérablement réduit.Sa technologie de « réseau de pont » associée tente de transposer les interprétations obtenues à partir de circuits épars en modèles denses haute performance tels que GPT-4, et fournit également un outil potentiel pour l'analyse de grands modèles existants.
Le site web d'HyperAI propose désormais « Circuit Sparsity : le nouveau modèle parcimonieux open source d'OpenAI », alors venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/WgLQc
Aperçu rapide des mises à jour du site web hyper.ai du 5 au 9 janvier :
* Ensembles de données publiques de haute qualité : 8
* Une sélection de tutoriels de haute qualité : 4
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec dates limites en janvier : 9
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données MCIF pour le suivi d'instructions multimodales et interlingue
MCIF est un jeu de données d'évaluation multilingue, multimodal et annoté manuellement, basé sur des discours scientifiques. Publié en 2025 par la Fondazione Bruno Kessler en collaboration avec l'Institut de technologie de Karlsruhe et Translated, il vise à évaluer la capacité des grands modèles de langage multimodaux à comprendre et à exécuter des instructions dans des contextes interlinguistiques, ainsi que leur aptitude à intégrer des informations vocales, visuelles et textuelles pour le raisonnement.
Utilisation directe :https://go.hyper.ai/SyUiL
2. Jeu de données d'inférence multitâche TxT360-3efforts
TxT360-3efforts est un ensemble de données d'entraînement de modèle de langage à très grande échelle pour le réglage fin supervisé (SFT), publié par l'Université Mohamed bin Zayed d'intelligence artificielle en 2025. Il est conçu pour contrôler trois forces d'inférence du modèle à travers des modèles de chat.
Utilisation directe :https://go.hyper.ai/fMEbf
3. Ensemble de données de détection de contrebande par rayons X
Le jeu de données de détection de contrebande par rayons X est un ensemble de données publié en 2025 par l'Université normale de Chine du Sud, en collaboration avec l'Université polytechnique de Hong Kong et l'Université de la Saskatchewan. Il vise à améliorer les performances des modèles de détection dans les images de sécurité complexes et denses, en particulier pour résoudre des problèmes concrets tels que le déséquilibre des classes et la rareté des échantillons.
Utilisation directe :https://go.hyper.ai/ppXub
4. Ensemble de données de photopléthysmographie à distance multicaméra MCD-rPPG
MCD-rPPG est un ensemble de données vidéo multicaméras publié par Sber AI Lab en 2025. L'ensemble de données se compose de vidéos synchronisées et de données de biosignaux prises par 600 sujets dans différents états, et est conçu pour effectuer une photopléthysmographie à distance (rPPG) et une estimation des biomarqueurs de santé.
Utilisation directe :https://go.hyper.ai/6KY40
5. Ensemble de données d'évaluation complète en contexte long LongBench-Pro
LongBench-Pro est un ensemble de données destiné à l'évaluation des modèles de langage à contexte long, conçu pour évaluer systématiquement la capacité d'un modèle à comprendre et à traiter des textes longs dans différentes longueurs de contexte, types de tâches et conditions d'exécution.
Utilisation directe :https://go.hyper.ai/7esQI
6. Ensemble de données sur les visages humains
Human Faces est un jeu de données publié en 2025 pour les tâches de vision par ordinateur liées aux visages. Il vise à fournir des données d'images de haute qualité et bien structurées pour des applications telles que la reconnaissance faciale, la détection, l'analyse des expressions et la modélisation générative.
Utilisation directe :https://go.hyper.ai/9WlDl

7. Ensemble de données de prédiction des calories brûlées
Calories Burnt Prediction est un ensemble de données d'apprentissage supervisé permettant de prédire la dépense énergétique liée à l'exercice physique. Il vise à utiliser les caractéristiques physiologiques et les informations relatives à l'activité physique d'un individu pour prédire le nombre de calories brûlées pendant une séance d'entraînement.
Utilisation directe :https://go.hyper.ai/o6X59
8. Ensemble de données de traçage de chemin MapTrace
MapTrace est un vaste ensemble de données synthétiques de tracé de chemin, publié par Google en collaboration avec l'Université de Pennsylvanie en 2025. Cet ensemble de données vise à améliorer les capacités de raisonnement spatial précis et de planification de chemin des modèles de langage multimodaux (MLLM) appliqués aux scènes cartographiques. Son objectif principal est d'entraîner des modèles à générer des chemins continus, praticables et précis au pixel près, reliant l'origine à la destination.
Utilisation directe :https://go.hyper.ai/BGHUu
Tutoriels publics sélectionnés
1. Parcimonie des circuits : le nouveau modèle parcimonieux open source d’OpenAI
Circuit-sparsity est un modèle de langage à 400 millions de paramètres développé par OpenAI. Il utilise la technologie de parcimonie des circuits, réinitialisant à zéro 99,91 TP3T poids afin de construire une architecture de calcul parcimonieuse interprétable. Ceci permet de s'affranchir des limitations de prise de décision « boîte noire » des Transformers traditionnels, et d'analyser l'inférence de l'IA couche par couche. Le kit d'outils Streamlit, fourni avec le modèle, propose la technologie « pont d'activation », permettant aux chercheurs de retracer les chemins de signal internes, d'analyser les circuits correspondants et de comparer les performances des modèles parcimonieux et denses.
Exécutez en ligne :https://go.hyper.ai/zui8w
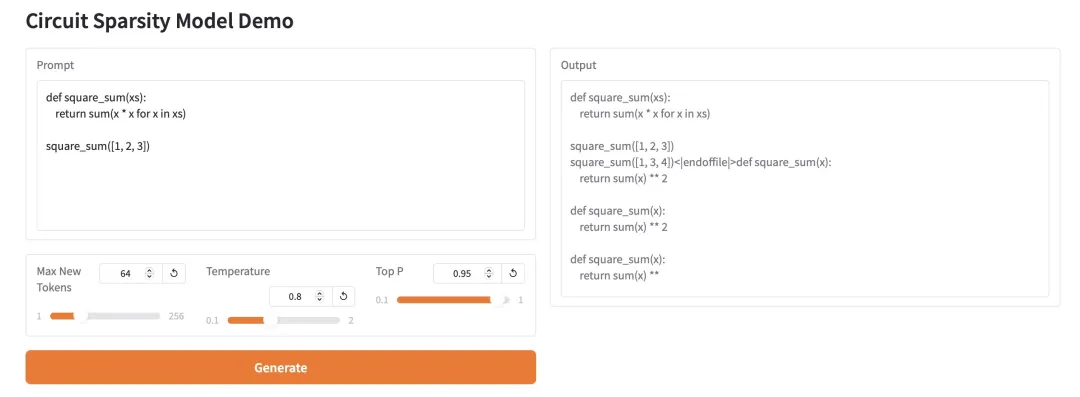
2. HY-MT1.5-1.8B : Modèle de traduction automatique neuronale multilingue
HY-MT1.5-1.8B est un modèle de traduction automatique multilingue doté de 1,8 milliard de paramètres, développé par l'équipe Hunyuan de Tencent. Basé sur l'architecture Transformer unifiée, il prend en charge la traduction automatique entre 33 langues et 5 langues/dialectes ethniques, et est optimisé pour les scénarios réels tels que les environnements multilingues et la gestion terminologique. Offrant une qualité de traduction proche de celle du modèle 7B, ce modèle ne comporte qu'un tiers du nombre de paramètres, permet un déploiement à grande échelle et une intégration aisée avec l'écosystème Hugging Face, et convient parfaitement aux services de traduction multilingue en ligne performants et économiques.
Exécutez en ligne :https://go.hyper.ai/I0pdR
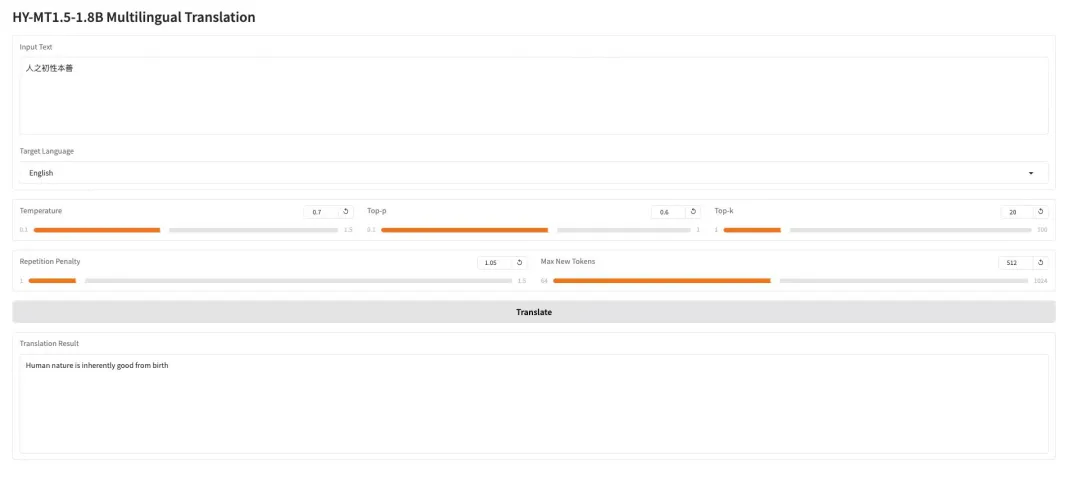
3. AWPortrait-Z Portrait Art LoRA
AWPortrait-Z est un modèle d'amélioration de portraits basé sur la technologie LoRa. Ce plugin s'intègre aux principaux modèles de diffusion d'images textuelles, améliorant considérablement le réalisme et la qualité photographique des portraits générés sans nécessiter de réentraînement du modèle de base. Ce modèle optimise spécifiquement le rendu de la structure faciale, du grain de peau et de l'éclairage, pour des effets plus naturels et raffinés, idéaux pour la création de portraits et la composition d'images exigeant un réalisme photographique.
Exécutez en ligne :https://go.hyper.ai/wRjIp
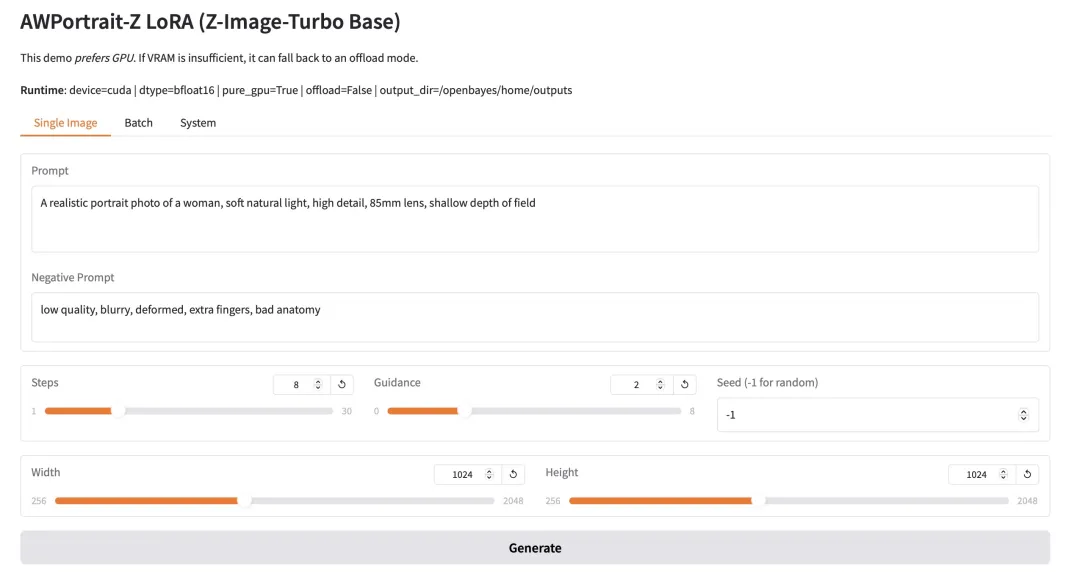
4. Granite-4.0-h-small : Une plateforme unique pour les tâches de dialogue et de codage multilingues.
Granite-4.0-h-small est un modèle d'optimisation fine des instructions à contexte long (3,2 milliards de paramètres) développé par IBM. Basé sur un modèle de base, il intègre des données open source et synthétiques et utilise des techniques d'optimisation fine supervisée, d'alignement par apprentissage par renforcement et de fusion de modèles. Ce modèle offre une excellente conformité aux instructions et des capacités d'appel d'outils optimales, utilise un format de dialogue structuré et est optimisé pour les applications d'entreprise à haute performance.
Exécutez en ligne :https://go.hyper.ai/1HhB9
Recommandation de papier de cette semaine
1. mHC : Hyperconnexion à contrainte de variété
Cet article propose les hyperconnexions à contrainte de variété (mHC), un cadre général qui restaure la propriété d'identité des hyperconnexions (HC) en projetant l'espace de connexions résiduelles de HC sur une variété spécifique, tout en garantissant une efficacité de calcul optimale grâce à une optimisation rigoureuse de l'infrastructure. Les résultats expérimentaux démontrent que mHC offre des performances exceptionnelles lors d'entraînements à grande échelle, avec des gains de performance tangibles et une remarquable scalabilité. Nous anticipons que, en tant qu'extension flexible et pratique des hyperconnexions, mHC contribuera à une meilleure compréhension de la conception de topologies et ouvrira de nouvelles perspectives prometteuses pour l'évolution des modèles de base.
Lien vers l'article :https://go.hyper.ai/ZePnH
2. Youtu-LLM : Exploiter le potentiel des agents intelligents natifs dans les modèles de langage légers et de grande taille
Les auteurs proposent Youtu-LLM, un modèle de langage léger de 1,96 milliard de paramètres développé par l'équipe Youtu-LLM. Grâce à un pré-entraînement à partir de zéro basé sur un programme d'apprentissage fondé sur le principe « bon sens-STEM-agent », il atteint des performances de pointe parmi les modèles de moins de 2 milliards de paramètres. Ce modèle intègre une architecture d'attention multi-latence compacte, un tokenizer orienté STEM et un pipeline évolutif pour générer des données de trajectoire d'agent de haute qualité dans des domaines tels que les mathématiques, la programmation, la recherche fondamentale et l'utilisation d'outils. Ceci permet au modèle d'internaliser des capacités natives de planification, de réflexion et d'action, surpassant significativement les modèles plus volumineux dans les benchmarks d'agents, tout en conservant de solides capacités de raisonnement général et de contextualisation étendue.
Lien vers l'article :https://go.hyper.ai/gitUc
3. Youtu-LLM : Exploiter le potentiel des agents intelligents natifs dans les modèles de langage légers et de grande taille
Cet article commence par définir et expliquer la fonction de la mémoire en retraçant son évolution, des neurosciences cognitives aux grands modèles de langage, puis aux agents intelligents. Il compare et analyse ensuite le système de classification, le mécanisme de stockage et le cycle de vie complet de la mémoire, d'un point de vue à la fois biologique et artificiel. Sur cette base, il passe en revue de manière systématique les principaux outils d'évaluation de la mémoire des agents intelligents. De plus, cet article explore les problématiques de sécurité des systèmes de mémoire, tant du point de vue de l'attaque que de la défense. Enfin, il présente les perspectives de recherche futures, en particulier la construction de systèmes de mémoire multimodaux et de mécanismes d'acquisition de compétences.
Lien vers l'article :https://go.hyper.ai/01H6H
4. Laissez libre cours à votre pensée : construire des agents intelligents dans le contexte de la musique rock et créer le modèle ROME au sein d'un écosystème d'apprentissage d'agents intelligents ouvert.
Les auteurs proposent ROME, un modèle d'agent open source basé sur l'écosystème d'apprentissage génétique (ALE). Ce framework intègre l'orchestration de bac à sable de ROCK, l'optimisation post-entraînement de ROLL et l'exécution d'agents contextuelle via l'interface de ligne de commande iFlow. Il atteint des performances de pointe sur les bancs d'essai Terminal-Bench 2.0 et SWE-bench Verified grâce à l'attribution de crédits aux blocs d'interaction sémantique via un nouvel algorithme d'optimisation de politiques (IPA), et prend en charge le déploiement en conditions réelles, permettant ainsi la création de flux de travail d'agents évolutifs, sécurisés et prêts pour la production.
Lien vers l'article :https://go.hyper.ai/UaAXZ
5. Rapport technique IQuest-Coder-V1
Cet article propose une nouvelle famille de modèles de langage de grande taille (LLM), la série IQuest-Coder-V1 (7B/14B/40B/40B-Loop). Contrairement aux représentations statiques de code traditionnelles, les auteurs proposent un paradigme d'apprentissage multi-étapes basé sur le flux de code, capturant dynamiquement l'évolution de la logique logicielle à différentes étapes du pipeline. Le modèle est construit grâce à un pipeline d'apprentissage évolutif. La publication de la série IQuest-Coder-V1 contribuera de manière significative aux progrès de la recherche en intelligence artificielle autonome et en systèmes d'agents intelligents pour le monde réel.
Lien vers l'article :https://go.hyper.ai/DBYN7
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. En générant 18 000 ans de données climatiques, NVIDIA et d’autres ont proposé une distillation à longue distance, permettant des prévisions météorologiques à long terme avec un seul calcul en une seule étape.
Une équipe de recherche de NVIDIA Research, en collaboration avec l'Université de Washington, a mis au point une nouvelle méthode de distillation à long terme. Le principe repose sur l'utilisation d'un modèle autorégressif, capable de générer une variabilité atmosphérique réaliste, comme « modèle d'apprentissage » pour produire d'importantes quantités de données météorologiques synthétiques grâce à une simulation rapide et peu coûteuse. Ces données servent ensuite à entraîner un modèle probabiliste « élève ». Ce dernier génère des prévisions à long terme en une seule étape de calcul, évitant ainsi l'accumulation d'erreurs itératives et les difficultés complexes liées à l'étalonnage des données. Les premiers résultats expérimentaux montrent que le modèle élève ainsi entraîné offre des performances comparables au système de prévision intégré du CEPMMT pour les prévisions S2S, et que ses performances continuent de s'améliorer avec l'augmentation du volume de données synthétiques, promettant des prévisions climatiques à l'échelle planétaire plus fiables et économiques.
Voir le rapport complet :https://go.hyper.ai/Ljebq
2. Dernier discours de Jensen Huang : 5 innovations, données de performance de Rubin révélées pour la première fois ; open source diversifié, couvrant les agents, les robots, la conduite autonome et l’IA4S
Au début de l'année, le CES 2026 (Consumer Electronics Show), souvent surnommé le « Gala du Printemps de la Technologie », a ouvert ses portes à Las Vegas, aux États-Unis. Bien que Jensen Huang ne figurât pas parmi les orateurs principaux du CES, il a multiplié les apparitions lors de divers événements. Sa présentation personnelle à NVIDIA LIVE a notamment été remarquée. Lors de cette présentation, Huang, vêtu de son emblématique veste en cuir noir, a présenté plus en détail la plateforme Rubin, qui intègre cinq innovations, et a mis en avant plusieurs réalisations open source. Plus précisément : la série NVIDIA Nemotron pour l'IA agentique ; la plateforme NVIDIA Cosmos pour l'IA physique ; la série NVIDIA Alpamayo pour la recherche sur la conduite autonome ; le NVIDIA Isaac GR00T pour la robotique ; et NVIDIA Clara pour le domaine biomédical.
Voir le rapport complet :https://go.hyper.ai/YMK1J
3. Bezos, Bill Gates, Nvidia, Intel et d'autres ont fait des paris ; des ingénieurs de la NASA dirigent une équipe pour créer un cerveau robotique à usage général, et l'entreprise est évaluée à 2 milliards de dollars.
Alors que les grands modèles peuvent se développer indéfiniment à partir d'Internet, de banques d'images et de vastes quantités de textes, les robots sont prisonniers d'un autre monde : les données du monde réel sont extrêmement rares, coûteuses et non réutilisables. Face à ces contraintes liées à l'insuffisance des données et à leur structure limitée dans le monde physique, FieldAI a opté pour une approche différente de la stratégie dominante axée sur la perception. L'entreprise conçoit un système d'intelligence robotique généraliste, centré sur les contraintes physiques, afin d'améliorer la capacité de généralisation et l'autonomie des robots dans des environnements réels.
Voir le rapport complet :https://go.hyper.ai/9T1rE
4. Rediffusion intégrale | Shanghai Chuangzhi/TileAI/Huawei/Advanced Compiler Lab/AI9Stars : Exploration approfondie des pratiques en matière de compilation IA
Face à l'évolution constante des technologies de compilation pour l'IA, de nombreuses recherches sont menées, permettant d'accumuler des connaissances et de converger. C'est dans ce contexte que s'est tenue la huitième session de Meet AI Compiler, le 27 décembre. Cinq experts de la Shanghai Innovation Academy, de TileAI Community, de Huawei HiSilicon, d'Advanced Compiler Lab et d'AI9Stars ont partagé leurs points de vue sur l'ensemble de la chaîne technologique, de la conception de la pile logicielle au développement des opérateurs, en passant par l'optimisation des performances. S'appuyant sur les travaux de recherche menés au cours de leurs missions respectives, les intervenants ont illustré les méthodes d'implémentation et les compromis des différentes approches techniques dans des cas concrets, donnant ainsi une dimension plus tangible aux concepts abstraits.
Voir le rapport complet :https://go.hyper.ai/8ytqF
5. Réaliser une conception de substrat hautement sélective : le MIT et Harvard découvrent de nouveaux modèles de clivage de protéases grâce à l'IA générative.
Le MIT et l'Université Harvard ont conjointement proposé CleaveNet, un processus de conception de bout en bout basé sur l'IA qui vise à révolutionner le paradigme existant de la conception de substrats de protéases en travaillant de concert avec des modèles prédictifs et génératifs, fournissant des solutions entièrement nouvelles pour la recherche fondamentale et le développement biomédical connexes.
Voir le rapport complet :https://go.hyper.ai/tcYYZ
Articles populaires de l'encyclopédie
1. Boucle homme-machine (HITL)
2. Fusion de tri super-réciproque RRF
3. Navigation incarnée
4. Perceptron multicouche
5. Ajustement précis du renforcement
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
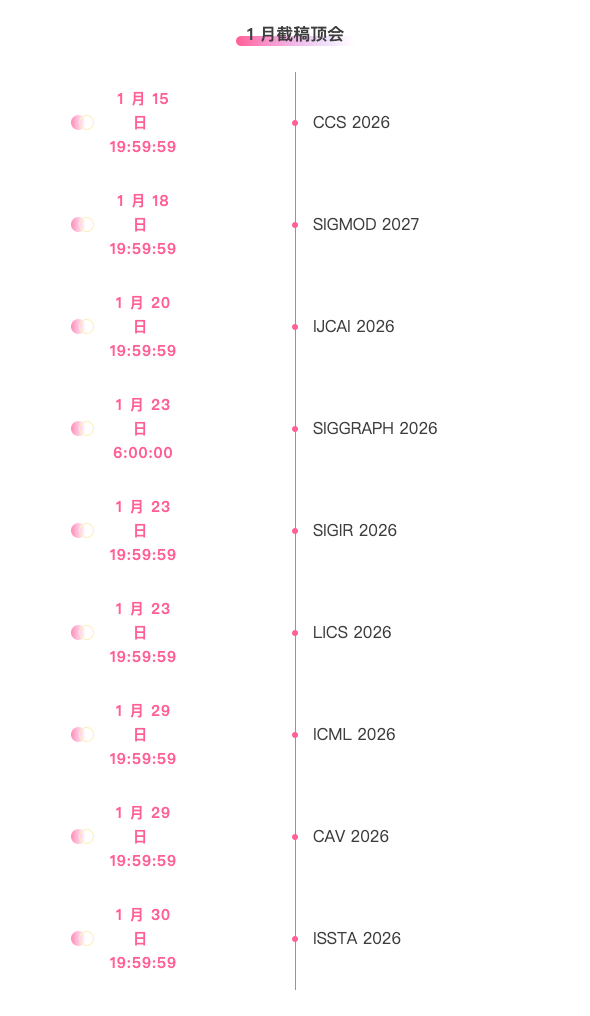
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








