Command Palette
Search for a command to run...
Une Compilation De Ressources Sur l'intelligence Incarnée : Ensembles De Données d'apprentissage Robotique, Expérience En Ligne De Modèles De Modélisation Du Monde Et Les Derniers Articles De Recherche De NVIDIA, ByteDance, Xiaomi Et autres.

Si le principal champ de bataille de l'intelligence artificielle au cours de la dernière décennie a été « la compréhension du monde » et la « génération de contenu », alors l'enjeu central de la prochaine étape se déplace vers une proposition plus complexe :Comment l'IA peut-elle véritablement pénétrer le monde physique et y agir, apprendre et évoluer ?Le terme « intelligence incarnée » apparaît fréquemment dans les recherches et les discussions connexes.
Comme son nom l'indique, l'intelligence incarnée n'est pas un robot traditionnel.Elle souligne plutôt que l'intelligence se forme par l'interaction entre l'agent et son environnement dans une boucle fermée de perception, de prise de décision et d'action.Dans cette perspective, l'intelligence ne se limite plus aux paramètres des modèles ou aux capacités de raisonnement, mais est profondément ancrée dans les capteurs, les actionneurs, le retour d'information de l'environnement et l'apprentissage à long terme. Les discussions sur la robotique, la conduite autonome, les agents et même l'intelligence artificielle générale (IAG) s'inscrivent pleinement dans ce cadre.
C’est pourquoi l’intelligence incarnée est devenue un axe de recherche majeur pour les géants technologiques mondiaux et les plus grands instituts de recherche ces deux dernières années. Elon Musk, PDG de Tesla, a maintes fois souligné que le robot humanoïde Optimus est tout aussi important que la conduite autonome ; Jensen Huang, fondateur de Nvidia, considère l’IA physique comme la prochaine étape après l’IA générative et continue d’investir massivement dans la simulation et les plateformes d’entraînement des robots ; Fei-Fei Li, Yann LeCun et d’autres continuent de produire des analyses et des résultats de pointe de grande qualité dans des sous-domaines tels que l’intelligence spatiale et les modèles du monde ; OpenAI, Google DeepMind et Meta explorent également les capacités d’apprentissage des agents intelligents dans des environnements réels ou quasi réels, en s’appuyant sur des technologies telles que les modèles multimodaux et l’apprentissage par renforcement.
Dans ce contexte, l'intelligence incarnée ne se limite plus à des modèles ou algorithmes isolés, mais s'est progressivement muée en un écosystème de recherche composé d'ensembles de données, d'environnements de simulation, de tâches de référence et de méthodes systématiques. Afin d'aider un plus grand nombre de lecteurs à saisir rapidement les enjeux clés de ce domaine,Cet article organisera et recommandera de manière systématique un ensemble de jeux de données de haute qualité, de tutoriels en ligne et d'articles relatifs à l'intelligence incarnée, fournissant ainsi une référence pour l'apprentissage et la recherche ultérieurs.
Recommandation de jeu de données
1. Ensemble de données d'apprentissage du robot BC-Z
Taille estimée :32,28 Go
Adresse de téléchargement :https://go.hyper.ai/vkRel

Il s'agit d'un vaste ensemble de données d'apprentissage robotique développé conjointement par Google, Everyday Robots, l'Université de Californie à Berkeley et l'Université de Stanford. Il contient plus de 25 877 scénarios de tâches opérationnelles différents, couvrant 100 tâches diverses. Ces tâches ont été collectées grâce à des opérations à distance réalisées par des experts et des processus autonomes partagés, impliquant 12 robots et 7 opérateurs différents, pour un total de 125 heures de fonctionnement. L'ensemble de données permet d'entraîner une politique multitâche à 7 degrés de liberté, adaptable en fonction de la description verbale de la tâche ou de vidéos d'opérations humaines, afin de réaliser des tâches opérationnelles spécifiques.
2.Ensemble de données de préhension de robot DexGraspVLA
Taille estimée :7,29 Go
Adresse de téléchargement :https://go.hyper.ai/G37zQ

Ce jeu de données, créé par l'équipe Psi-Robot, contient 51 exemples de données de démonstration humaine permettant de comprendre les données et leur format, d'exécuter le code et d'expérimenter le processus d'entraînement. Ses recherches sont motivées par le besoin d'obtenir des taux de réussite élevés pour la préhension agile dans des environnements complexes, notamment un taux de réussite supérieur à 90 % (TP3T) avec différentes combinaisons d'objets invisibles, d'éclairage et d'arrière-plans. Ce cadre utilise un modèle visuel-langage pré-entraîné comme planificateur de tâches de haut niveau et apprend une politique basée sur la diffusion comme contrôleur d'actions de bas niveau. Son innovation réside dans l'exploitation du modèle de base pour obtenir de puissantes capacités de généralisation et dans l'utilisation de l'apprentissage par imitation basé sur la diffusion pour acquérir des actions agiles.
3.EgoThink : un ensemble de données de référence de réponses visuelles à des questions à la première personne
Taille estimée :865,29 Mo
Adresse de téléchargement :https://go.hyper.ai/5PsDP

Ce jeu de données, proposé par l'Université Tsinghua, est un jeu de données de référence pour la réponse visuelle à des questions en perspective subjective. Il contient 700 images couvrant 6 capacités fondamentales, subdivisées en 12 dimensions. Les images sont extraites du jeu de données vidéo Ego4D en perspective subjective ; afin de garantir la diversité des données, deux images au maximum ont été extraites de chaque vidéo. Lors de la construction du jeu de données, seules des images de haute qualité illustrant clairement la pensée en perspective subjective ont été sélectionnées. EgoThink trouve de nombreuses applications, notamment pour l'évaluation et l'amélioration des performances des modèles d'apprentissage visuel (MAV) dans les tâches en perspective subjective, et constitue une ressource précieuse pour les futures recherches en intelligence artificielle incarnée et en robotique.
4.Ensemble de données de réponses aux questions de l'EQA
Taille estimée :839,6 Ko
Adresse de téléchargement :https://go.hyper.ai/8Uv1o
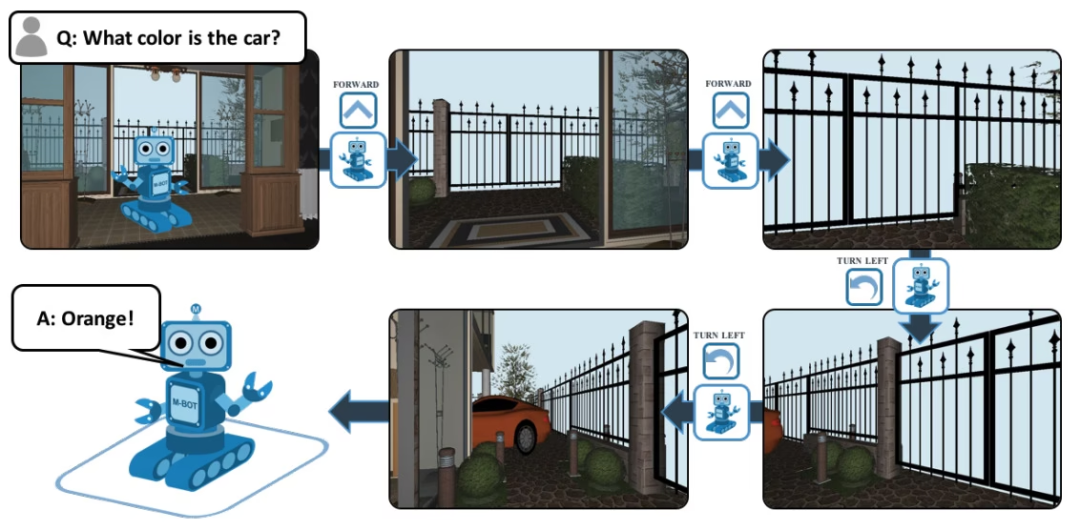
EQA, dont le nom complet est Embodied Question Answering, est un ensemble de données de réponses visuelles aux questions basé sur House3D. Après avoir reçu une question, un agent situé à n’importe quel endroit de l’environnement peut trouver des informations utiles dans l’environnement et répondre à la question. Par exemple : Q : De quelle couleur est la voiture ? Pour répondre à cette question, l'agent doit d'abord explorer l'environnement grâce à une navigation intelligente, collecter les informations visuelles nécessaires à la première personne, puis répondre à la question : orange.
5. Robot global OmniRetarget
ensemble de données de remappage de mouvement
Taille estimée :349,61 Mo
Adresse de téléchargement :https://go.hyper.ai/IloBI

Il s'agit d'un jeu de données de trajectoires de haute qualité pour la modélisation complète des mouvements de robots humanoïdes, publié par Amazon en collaboration avec le MIT, l'UC Berkeley et d'autres institutions. Il contient les trajectoires du robot humanoïde G1 interagissant avec des objets et des terrains complexes, couvrant trois scénarios : transport d'objets par le robot, marche sur différents terrains et interaction hybride objet-terrain. En raison de restrictions de licence, le jeu de données accessible au public n'inclut pas de version modélisée de LAFAN1. Il est divisé en trois sous-ensembles, totalisant environ 4 heures de données de trajectoires, comme suit :
* robot-object : La trajectoire de l'objet transporté par le robot, dérivée des données OMOMO 3.0 ;
* terrain du robot : Trajectoire de déplacement du robot sur un terrain complexe, générée par la collecte de données MoCap interne, d'une durée d'environ 0,5 heure ;
* robot-objet-terrain : Cela implique la trajectoire de mouvement d'un objet interagissant avec le terrain et dure environ 0,5 heure.
De plus, l'ensemble de données contient également un répertoire de modèles, qui fournit des fichiers de modèles visuels aux formats URDF, SDF et OBJ pour l'affichage plutôt que pour la formation.
Consultez d'autres ensembles de données de haute qualité :https://hyper.ai/datasets
Recommandations de tutoriels
La recherche en intelligence artificielle incarnée repose souvent sur la combinaison de plusieurs modèles et modules pour parvenir à la perception, la compréhension, la planification et l'action dans le monde physique. Parmi ceux-ci figurent les modèles du monde et les modèles de raisonnement. Cet article recommande principalement les deux modèles open source les plus récents suivants.
Consultez d'autres tutoriels de haute qualité :https://hyper.ai/notebooks
1.HY-World 1.5 : Cadre pour un système de modélisation du monde interactif
HY-World 1.5 (WorldPlay) est le premier modèle de monde interactif en temps réel open source à cohérence géométrique à long terme, développé par l'équipe Hunyuan de Tencent. Ce modèle permet la modélisation d'un monde interactif en temps réel grâce à la technologie de diffusion vidéo en continu, résolvant ainsi le compromis entre vitesse et mémoire des méthodes actuelles.
Exécutez en ligne :https://go.hyper.ai/qsJVe
2.Déploiement vLLM+Open WebUI Nemotron-3 Nano
Le Nemotron-3-Nano-30B-A3B-BF16 est un modèle de langage à grande échelle (LLM) entraîné de zéro par NVIDIA. Conçu comme un modèle unifié applicable aux tâches de raisonnement et aux tâches ne nécessitant pas de raisonnement, il est principalement utilisé pour construire des systèmes d'agents IA, des chatbots, des systèmes RAG (génération augmentée par récupération) et diverses autres applications d'IA.
Exécutez en ligne :https://go.hyper.ai/6SK6n
Recommandation de papier
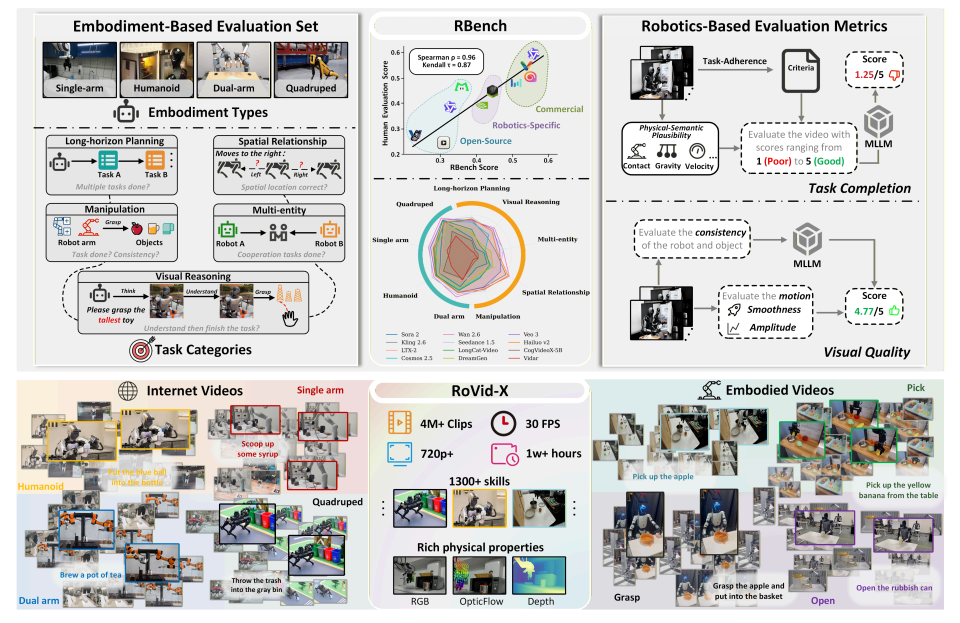
- RBench
Titre de la thèse:Repenser le modèle de génération vidéo pour le monde incarné
Équipe de recherche :Université de Pékin, Graine ByteDance
Voir le document :https://go.hyper.ai/k1oMT
Résumé de la recherche :
L'équipe a proposé RBench, un banc d'essai complet pour la génération de vidéos robotiques, couvrant cinq domaines de tâches et quatre formes de robots différentes. Il évalue la génération de vidéos robotiques selon deux dimensions : la justesse au niveau de la tâche et la fidélité visuelle, à l'aide d'une série de sous-indicateurs reproductibles, notamment la cohérence structurelle, la plausibilité physique et l'intégralité des mouvements. Les résultats d'évaluation sur 25 modèles de génération vidéo représentatifs montrent que les méthodes actuelles présentent encore des lacunes importantes pour générer des comportements robotiques physiquement réalistes. De plus, le coefficient de corrélation de Spearman entre RBench et l'évaluation humaine atteint 0,96, validant ainsi l'efficacité du banc d'essai pour mesurer la qualité des modèles.
En outre, l'étude a également permis de créer RoVid-X, le plus grand ensemble de données open source de génération de vidéos robotiques à ce jour, contenant 4 millions de clips vidéo annotés couvrant des milliers de tâches, complétés par des annotations complètes des attributs physiques.
2. Être-H0.5
Titre de l'article :Being-H0.5 : Mise à l’échelle de l’apprentissage robotique centré sur l’humain pour la généralisation inter-incarnation
Équipe de recherche :Être au-delà
Voir le document :https://go.hyper.ai/pW24B
Résumé de la recherche :
L'équipe a proposé un modèle Vision-Langage-Action (VLA) fondamental, Being-H0.5, conçu pour offrir de solides capacités de généralisation et d'incarnation sur de multiples plateformes robotiques. Les modèles VLA existants sont souvent limités par des problèmes tels que les différences importantes de morphologie entre les robots et la rareté des données disponibles. Pour relever ce défi, ils ont proposé un paradigme d'apprentissage centré sur l'humain qui considère les trajectoires d'interaction humaine comme un « langage mère » universel dans le domaine de l'interaction physique.
Parallèlement, l'équipe a également lancé UniHand-2.0, l'une des solutions de pré-entraînement incarné les plus vastes à ce jour, intégrant plus de 35 000 heures de données multimodales réparties sur 30 robots différents. Sur le plan méthodologique, elle a proposé un espace d'actions unifié, associant les méthodes de contrôle hétérogènes des différents robots à des séquences d'actions sémantiquement alignées. Ceci permet aux robots à faibles ressources de transférer et d'apprendre rapidement des compétences à partir de données humaines et de plateformes à ressources élevées.

3. Réfléchir vite
Titre de l'article :Réflexion rapide et action : Raisonnement efficace vision-langage-action via la planification latente verbalisable
Équipe de recherche :Nvidia
Voir le document :https://go.hyper.ai/q1h7j
Résumé de la recherche :
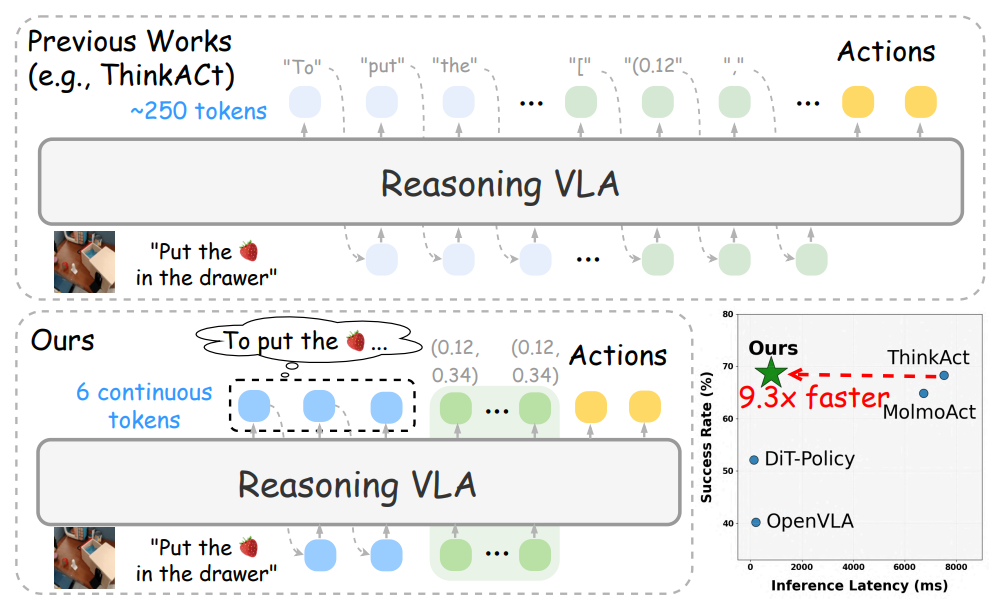
L'équipe a proposé Fast-ThinkAct, un cadre de raisonnement efficace qui permet un processus de planification plus compact tout en maintenant les performances grâce à un mécanisme de raisonnement latent linguistique. Fast-ThinkAct acquiert des capacités de raisonnement efficaces en extrayant des concepts latents de processus (CoT) à partir de modèles d'apprentissage et aligne les trajectoires d'opérations selon une fonction objectif basée sur les préférences, transférant ainsi les capacités de planification linguistique et visuelle au contrôle incarné.
Des résultats expérimentaux approfondis couvrant diverses opérations incarnées et tâches d'inférence démontrent que Fast-ThinkAct, tout en maintenant des capacités de planification à long terme, une adaptabilité à peu d'échantillons et des capacités de récupération des pannes, réalise une amélioration significative des performances en réduisant la latence d'inférence jusqu'à 89,31 TP3T par rapport aux modèles VLA basés sur l'inférence de pointe actuels.
4. JugeRLVR
Titre de l'article :JudgeRLVR : Juger d’abord, générer ensuite pour un raisonnement efficace
Équipe de recherche :Université de Pékin, Xiaomi
Voir le document :https://go.hyper.ai/2yCxp
Résumé de la recherche :
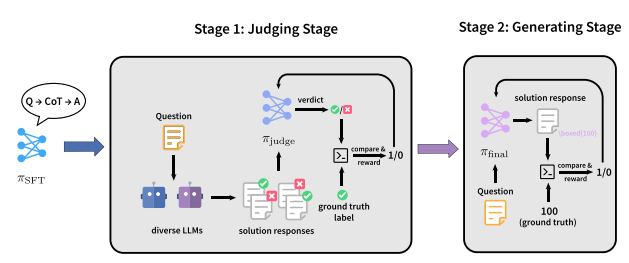
L'équipe a proposé un paradigme d'entraînement en deux étapes, JudgeRLVR, qui consiste à « discriminer d'abord, puis générer ». Dans un premier temps, un modèle est entraîné à discriminer et à évaluer les réponses de résolution de problèmes à l'aide de solutions vérifiables. Dans un second temps, ce même modèle est affiné grâce à l'algorithme RLVR génératif standard, en utilisant le modèle discriminatif comme initialisation.
Comparé à Vanilla RLVR, utilisé sur des données d'entraînement du même domaine mathématique, JudgeRLVR atteint un meilleur compromis qualité-efficacité sur Qwen3-30B-A3B : sur les tâches mathématiques du domaine, la précision moyenne est améliorée d'environ 3,7 points de pourcentage tandis que la longueur moyenne de génération est réduite de 42% ; sur les benchmarks hors domaine, la précision moyenne est améliorée d'environ 4,5 points de pourcentage, démontrant une capacité de généralisation plus forte.
5. ACoT-VLA
Titre de l'article :ACoT-VLA : Chaîne de pensée d’action pour les modèles vision-langage-action
Équipe de recherche :Université d'aéronautique et d'astronautique de Pékin, AgiBot
Voir le document :https://go.hyper.ai/2jMmY
Résumé de la recherche :
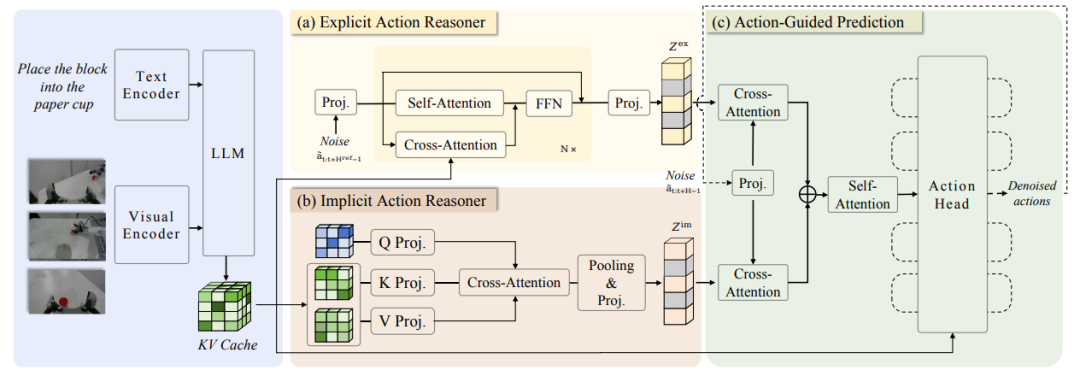
L'équipe a d'abord proposé Action Chain-of-Thought (ACoT), qui modélise le processus de raisonnement comme une série d'intentions d'action structurées et à gros grains, guidant la génération de la politique finale. Elle a ensuite proposé ACoT-VLA, une nouvelle architecture de modèle concrétisant le paradigme ACoT.
Dans sa conception spécifique, il introduit deux composants centraux complémentaires : le raisonneur d’actions explicites (EAR) et le raisonneur d’actions implicites (IAR). L’EAR propose une trajectoire de référence à gros grains sous la forme d’étapes de raisonnement explicites au niveau de l’action, tandis que l’IAR extrait des informations a priori latentes sur les actions à partir des représentations internes d’entrées multimodales. Ensemble, ils constituent l’ACoT et servent d’entrées conditionnelles au module d’action en aval, permettant ainsi un apprentissage de la politique avec des contraintes d’atterrissage.
De nombreux résultats expérimentaux, tant dans des environnements réels que simulés, démontrent les avantages significatifs de cette méthode, atteignant des scores de 98,51 TP3T, 84,11 TP3T et 47,41 TP3T sur les benchmarks LIBERO, LIBEROPlus et VLABench, respectivement.
Consultez les derniers articles :https://hyper.ai/papers








