Command Palette
Search for a command to run...
Un Essai À Faible Barrière d'Open-AutoGLM : Une Expérience d'agent Intelligent Combinant La Compréhension De l'écran Et l'exécution Automatisée ; Spatial-SSRL-81k : Construction d'un Chemin d'amélioration Auto-supervisé Pour La Conscience spatiale.

Alors que « Doubao Mobile » était encore au cœur des discussions quant à son potentiel de tendance,Zhipu AI a annoncé avoir rendu open source son framework d'assistant intelligent mobile, Open-AutoGLM.Il permet une compréhension multimodale et une exploitation automatisée du contenu de l'écran.
Contrairement aux outils d'automatisation mobile traditionnels,L'agent téléphonique utilise un modèle de langage visuel pour parvenir à une compréhension sémantique approfondie du contenu de l'écran et combine des capacités de planification intelligentes pour générer et exécuter automatiquement des processus opérationnels.Le système contrôle l'appareil via ADB (Android Debug Bridge). Il suffit à l'utilisateur de décrire ses besoins en langage naturel, par exemple « ouvrir Xiaohongshu pour chercher à manger », et l'agent mobile interprète automatiquement l'intention, comprend l'interface actuelle, planifie l'action suivante et mène à bien l'ensemble du processus.
En matière de sécurité et de contrôle, le système est doté d'un mécanisme de confirmation d'opération sensible et permet la prise de contrôle par l'utilisateur dans les scénarios nécessitant une intervention manuelle, tels que la connexion, le paiement ou les codes de vérification, garantissant ainsi une expérience utilisateur sûre et fiable. De plus, l'Agent Téléphonique offre des capacités de débogage ADB à distance, prenant en charge les connexions d'appareils via Wi-Fi ou réseaux mobiles, offrant ainsi aux développeurs et aux utilisateurs avancés un contrôle à distance flexible et une assistance au débogage en temps réel.
à l'heure actuelle,Open-AutoGLM, implémenté sur la base de ce framework, a été appliqué à plus de 50 applications chinoises courantes, dont WeChat, Taobao et Xiaohongshu.Capable de gérer une variété de tâches quotidiennes, allant des interactions sociales et des achats en ligne à la navigation de contenu, il évolue progressivement vers un assistant intelligent couvrant tous les aspects de la vie des utilisateurs, y compris les vêtements, la nourriture, le logement et les transports.
Le site web d'HyperAI propose désormais « Open-AutoGLM : un assistant intelligent pour appareils mobiles », alors venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/QwvOU
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 8 au 12 décembre :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 5
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en janvier : 11
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données Envision pour la génération visuelle d'événements multi-étapes
Envision est un ensemble de données composé de paires image-texte, publié par le Laboratoire d'intelligence artificielle de Shanghai. Il a été conçu pour tester la capacité d'un modèle à comprendre les relations causales et à générer des récits à plusieurs étapes à partir d'événements réels. Cet ensemble contient 1 000 séquences d'événements et 4 000 amorces textuelles en quatre étapes, couvrant six grands domaines : les sciences naturelles et les sciences humaines/l'histoire. Les documents relatifs aux événements proviennent de manuels scolaires et de ressources en ligne, sont sélectionnés par des experts, puis générés et affinés par GPT-4o afin de former des amorces narratives présentant des chaînes causales claires et des étapes qui se déroulent progressivement.
Utilisation directe :https://go.hyper.ai/xD4j6
2. DetectiumFire - Ensemble de données multimodal pour la compréhension des incendies
DetectiumFire, un jeu de données développé par l'Université Tulane en collaboration avec l'Université Aalto, est conçu pour la détection de flammes, le raisonnement visuel et la génération multimodale. Il a été intégré à la piste « Jeux de données et benchmarks » de NeurIPS 2025, qui vise à fournir une ressource unifiée d'entraînement et d'évaluation pour les scènes d'incendie dans les modèles de vision par ordinateur et de langage visuel. Ce jeu de données contient plus de 145 000 images d'incendies réels de haute qualité et 25 000 vidéos liées aux incendies.
Utilisation directe :https://go.hyper.ai/7Z92Z

3. Ensemble de données d'évaluation de la marche en 3D pour la maladie de Parkinson (Care-PD)
CARE-PD, développé par l'Université de Toronto en collaboration avec le Vector Institute, le KITE Research Institute–UHN et d'autres institutions, est actuellement le plus grand ensemble de données 3D de maillage de la marche accessible au public pour la maladie de Parkinson. Sélectionné pour les ensembles de données et les benchmarks NeurIPS 2025, il vise à fournir une base de données de haute qualité pour la prédiction des scores cliniques, l'apprentissage de la représentation de la marche parkinsonienne et l'analyse interinstitutionnelle unifiée. L'ensemble de données contient des enregistrements de la marche de 362 sujets répartis dans 9 cohortes indépendantes issues de 8 institutions cliniques. Toutes les vidéos de la marche et les données de capture de mouvement ont été traitées de manière uniforme et converties en maillages 3D de la marche humaine SMPL anonymisés.
Utilisation directe :https://go.hyper.ai/CH7Oi
4. Ensemble de données de référence pour l'inférence mathématique multilingue PolyMath
PolyMath est un ensemble de données d'évaluation du raisonnement mathématique multilingue, développé par l'équipe Qianwen d'Alibaba en collaboration avec l'université Jiao Tong de Shanghai. Sélectionné pour les ensembles de données et les benchmarks NeurIPS 2025, il vise à évaluer systématiquement la compréhension mathématique, la profondeur du raisonnement et la cohérence interlinguistique des grands modèles de langage dans un contexte multilingue.
Utilisation directe :https://go.hyper.ai/VM5XK
5. Ensemble de données vidéo d'occlusion humaine 3D VOccl3D
VOccl3D est un vaste ensemble de données synthétiques, publié par l'Université de Californie, axé sur la compréhension du corps humain en 3D dans des scènes complexes avec occlusion. Il vise à fournir un référentiel plus réaliste pour l'estimation, la reconstruction et les tâches de perception multimodale de la pose humaine. Cet ensemble de données contient plus de 250 000 images et environ 400 séquences vidéo, construites à partir de scènes d'arrière-plan, d'actions humaines et de textures variées.
Utilisation directe :https://go.hyper.ai/vBFc2

6. Ensemble de données auto-supervisé et sensible à l'espace Spatial-SSRL-81k
Spatial-SSRL-81k est un jeu de données d'apprentissage auto-supervisé de la vision et du langage pour la compréhension et le raisonnement spatiaux. Développé par le Laboratoire d'intelligence artificielle de Shanghai en collaboration avec l'Université Jiao Tong de Shanghai, l'Université chinoise de Hong Kong et d'autres institutions, il vise à doter les grands modèles de capacités de perception spatiale sans annotation manuelle, améliorant ainsi leurs performances de raisonnement et de généralisation dans des environnements multimodaux.
Utilisation directe :https://go.hyper.ai/AfHSW

7. WenetSpeech-Chuan (Ensemble de données vocales du dialecte Sichuan-Chongqing)
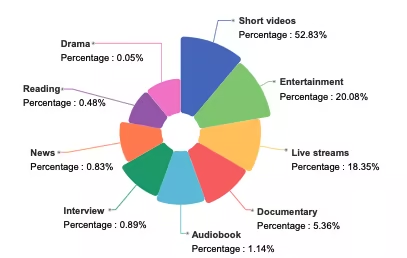
WenetSpeech-Chuan est un vaste ensemble de données vocales en dialectes du Sichuan et de Chongqing, publié par l'Université polytechnique du Nord-Ouest en collaboration avec Hillbeike, l'Institut de recherche en intelligence artificielle de China Telecom et d'autres institutions. Cet ensemble de données couvre neuf scénarios réels, dont 52 831 % sont des vidéos courtes. Le reste comprend des contenus de divertissement, des diffusions en direct, des livres audio, des documentaires, des interviews, des actualités, des lectures et des pièces de théâtre, offrant ainsi une distribution vocale très diversifiée et réaliste.
Utilisation directe :https://go.hyper.ai/dFlE2
8. Ensemble de données de tests physiologiques PhysDriver
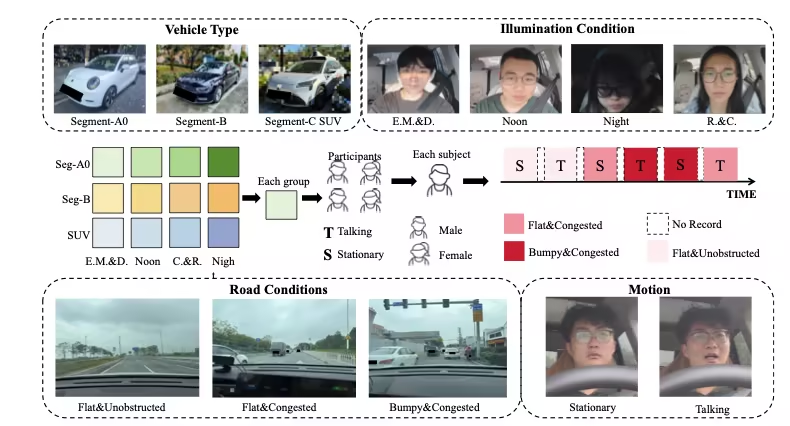
PhysDrive est le premier jeu de données multimodal à grande échelle pour la mesure physiologique sans contact en situation de conduite réelle, publié par des institutions telles que l'Université des sciences et technologies de Hong Kong (Guangzhou), l'Université des sciences et technologies de Hong Kong et l'Université Tsinghua. Sélectionné pour les jeux de données et les benchmarks NeurIPS 2025, il vise à soutenir la recherche et l'évaluation de la surveillance de l'état du conducteur, des systèmes de cockpit intelligents et des méthodes de perception physiologique multimodale.
Utilisation directe :https://go.hyper.ai/4qz9T
9. Jeu de données de référence MMSVGBench pour la génération de graphiques vectoriels multimodaux
MMSVG-Bench est un banc d'essai complet conçu pour les tâches de génération SVG multimodale. Développé conjointement par l'Université Fudan et StepFun, il a été sélectionné pour les jeux de données et les benchmarks de NeurIPS 2025 et vise à combler le manque actuel de jeux de tests unifiés, ouverts et standardisés dans le domaine de la génération de graphiques vectoriels.
Utilisation directe :https://go.hyper.ai/WiZCR
10. Ensemble de données PolypSense3D prenant en compte la taille des polypes
PolypSense3D est un jeu de données de référence multi-sources conçu spécifiquement pour les tâches de mesure de la taille des polypes par détection de profondeur. Développé par l'Université normale de Hangzhou en collaboration avec l'Université technique du Danemark, l'Université de Hohai et d'autres institutions, il a été sélectionné pour NeurIPS 2025 et vise à fournir des ressources d'entraînement et d'évaluation de haute qualité pour la détection des polypes, l'estimation de leur profondeur, la mesure de leur taille et l'apprentissage par transfert de la simulation au réel.
Utilisation directe :https://go.hyper.ai/SZnu6
Tutoriels publics sélectionnés
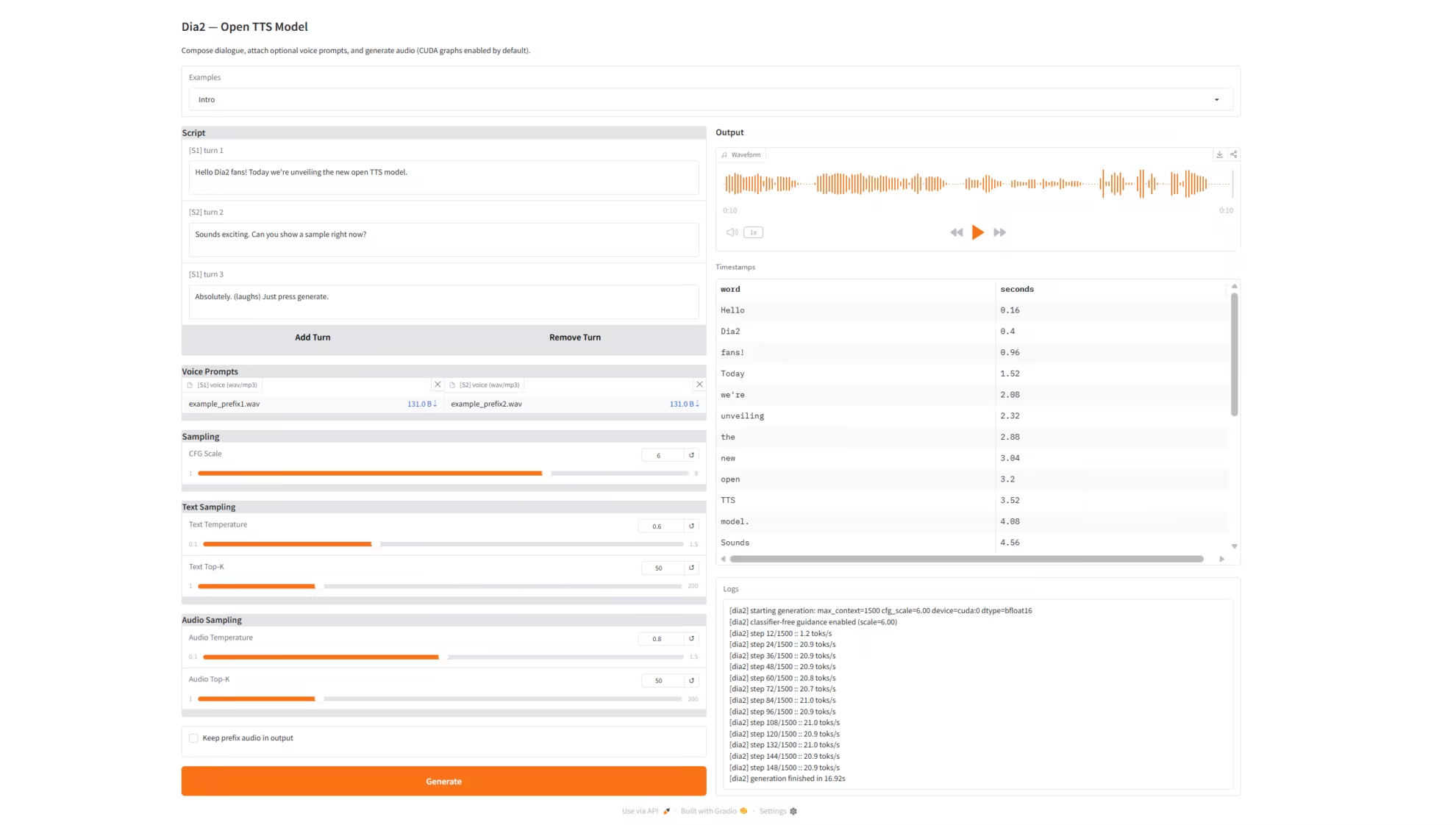
1. Dia2-TTS : Service de synthèse vocale en temps réel
Dia2-TTS est un service de synthèse vocale en temps réel basé sur le modèle de génération vocale à grande échelle Dia2 (Dia2-2B) développé par l'équipe de nari-labs. Il prend en charge la saisie de dialogues à plusieurs tours, les invites vocales à double rôle (voix préfixée) et l'échantillonnage multiparamétrique. Il offre une interface web interactive complète via Grado pour une synthèse vocale conversationnelle de haute qualité. Le modèle peut traiter directement des dialogues à plusieurs tours consécutifs afin de générer une parole naturelle, cohérente et de haute qualité, idéale pour des applications telles que le service client virtuel, les assistants vocaux, le doublage par IA et la génération de courts métrages.
Exécutez en ligne :https://go.hyper.ai/Qbfni
2. Open-AutoGLM : Assistant intelligent pour appareils mobiles
Open-AutoGLM est un framework d'assistant intelligent mobile développé par Zhipu AI et basé sur AutoGLM. Ce framework est capable de comprendre le contenu des écrans mobiles de manière multimodale et d'aider les utilisateurs à accomplir des tâches grâce à des opérations automatisées. Contrairement aux outils d'automatisation mobile traditionnels, Phone Agent utilise un modèle de langage visuel pour la perception de l'écran, combiné à des capacités de planification intelligente pour générer et exécuter automatiquement des processus opérationnels.
Exécutez en ligne :https://go.hyper.ai/QwvOU
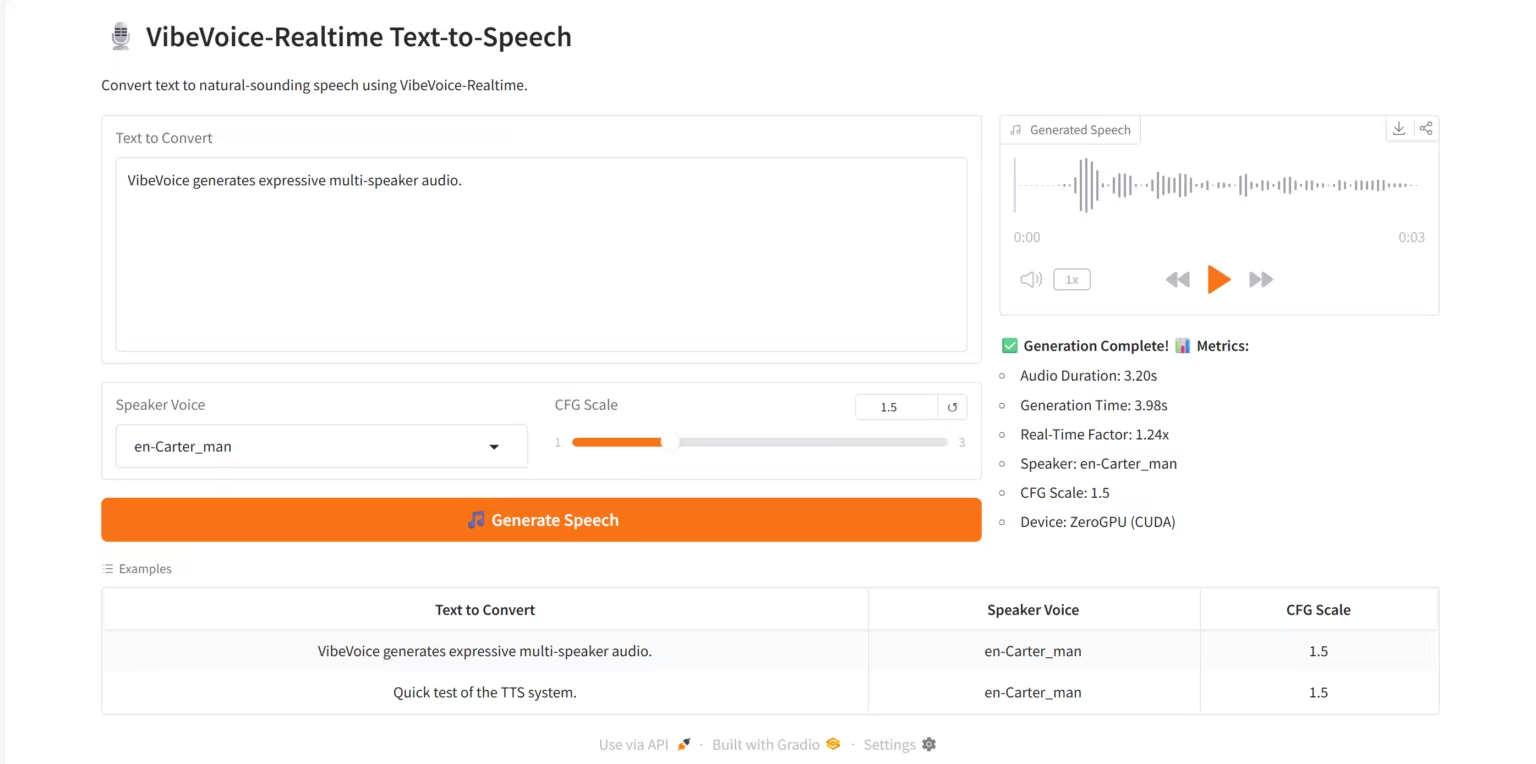
3. VibeVoice - Synthèse vocale en temps réel : Service de synthèse vocale en temps réel
VibeVoice-Realtime TTS est un système de synthèse vocale (TTS) temps réel de haute qualité, basé sur le modèle de synthèse vocale en flux continu VibeVoice-Realtime-0.5B développé par l'équipe de recherche de Microsoft. Ce système prend en charge la génération vocale multilocutrice, l'inférence temps réel à faible latence et les visualisations interactives sur la plateforme web Grado.
Exécutez en ligne :https://go.hyper.ai/RviLs
4. Z-Image-Turbo : un modèle de génération d’images à 6 paramètres haute efficacité
Z-Image-Turbo est un modèle de génération d'images haute performance de nouvelle génération, développé par l'équipe Tongyi Qianwen d'Alibaba. Avec seulement 6 octets de paramètres, ce modèle offre des performances comparables à celles des modèles propriétaires haut de gamme qui en utilisent plus de 20, et excelle particulièrement dans la génération de portraits photoréalistes de haute fidélité.
Exécutez en ligne :https://go.hyper.ai/R8BJF
5. Ovis-Image : un modèle de génération d’images de haute qualité
Ovis-Image est un système de génération d'images à partir de texte (T2I) de haute qualité, basé sur le modèle haute fidélité Ovis-Image-7B développé par l'équipe AIDC-AI. Ce système utilise un encodeur Transformer multi-échelle et une architecture générative autorégressive, offrant des performances exceptionnelles en matière de génération d'images haute résolution, de représentation des détails et d'adaptation à différents styles.
Exécutez en ligne :https://go.hyper.ai/NoaDw

Recommandation de papier de cette semaine
1. Wan-Move : Génération vidéo contrôlable par le mouvement via un guidage de trajectoire latente
Cet article propose Wan-Move, un cadre simple et évolutif qui intègre des capacités de contrôle de mouvement aux modèles de génération vidéo. Les méthodes existantes de contrôle de mouvement souffrent souvent d'un contrôle imprécis et d'une évolutivité limitée, ce qui engendre des résultats inadaptés aux applications pratiques. Pour pallier ce manque, Wan-Move assure un contrôle de mouvement de haute précision et de haute qualité. Son principe repose sur l'intégration directe de capacités de perception du mouvement aux caractéristiques conditionnelles initiales afin de guider la génération vidéo.
Lien vers l'article :https://go.hyper.ai/h3uaG
2. Visionnaire : Le transporteur de modèles mondiaux construit sur une plateforme de splatting gaussien alimentée par WebGPU
Cet article présente Visionary, une plateforme de rendu temps réel open source, nativement web, prenant en charge le rendu en temps réel de divers types de rasters et de maillages gaussiens. Reposant sur un moteur de rendu WebGPU haute performance et intégrant un mécanisme d'inférence ONNX exécuté à chaque image, la plateforme offre des capacités de traitement neuronal dynamique tout en conservant une conception légère et une expérience utilisateur intuitive de type « cliquer pour exécuter » dans un navigateur.
Lien vers l'article :https://go.hyper.ai/NaBv3
3. Natif du raisonnement parallèle : Raisonnement en parallélisme via l’apprentissage par renforcement auto-distillé
Cet article propose le Native Parallel Reasoner (NPR), un framework sans enseignant permettant aux grands modèles de langage (LLM) de développer de manière autonome de véritables capacités de raisonnement parallèle. Lors de huit tests de performance, le NPR, entraîné sur le modèle Qwen3-4B, atteint un gain de performance allant jusqu'à 24,51 TP3T et une augmentation maximale de la vitesse d'inférence de 4,6x.
Lien vers l'article :https://go.hyper.ai/KWiZQ
4. TwinFlow : Réaliser la génération en une seule étape sur de grands modèles avec des flux auto-adversariaux
Cet article propose TwinFlow, un cadre d'entraînement pour les modèles génératifs. Cette méthode ne repose pas sur un modèle enseignant pré-entraîné fixe et évite l'utilisation de réseaux antagonistes classiques lors de l'entraînement, ce qui la rend particulièrement adaptée à la construction de modèles génératifs à grande échelle et à haute efficacité. Dans les tâches de génération d'images à partir de texte, ce cadre atteint un score GenEval de 0,83 avec une évaluation de fonction d'ordre un (1-NFE), surpassant significativement des modèles de référence performants tels que SANA-Sprint (un cadre basé sur la perte GAN) et RCGM (un cadre basé sur des mécanismes de cohérence).
Lien vers l'article :https://go.hyper.ai/l1nUp
5. Au-delà du réel : extension imaginaire des plongements de position rotative pour les LLM à contexte long
L'encodage positionnel rotationnel (RoPE), qui consiste à faire pivoter les vecteurs de requête et de clé dans le plan complexe, est devenu une méthode standard pour encoder l'ordre des séquences dans les grands modèles de langage (LLM). Cependant, les implémentations standard existantes n'utilisent que la partie réelle du produit scalaire complexe pour calculer les scores d'attention, ignorant la partie imaginaire, qui contient des informations de phase importantes. Cela peut entraîner la perte de détails cruciaux sur les relations relatives lors de la modélisation des dépendances à longue portée. Cet article propose une méthode d'extension qui réintroduit les informations de la partie imaginaire précédemment négligées. Cette méthode exploite pleinement la représentation complexe complète pour construire un score d'attention à deux composantes.
Lien vers l'article :https://go.hyper.ai/iGTw6
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. Un pari à 20 milliards de dollars ! xAI mise les énormes capitaux de Musk sur OpenAI, dont la viabilité commerciale future reste la plus grande inconnue.
En 2025, xAI a bénéficié d'un essor financier sans précédent grâce à l'impulsion donnée par Musk, mais sa commercialisation est restée fortement dépendante des écosystèmes X et Tesla, tandis que les flux de trésorerie et la pression réglementaire augmentaient simultanément. L'approche de « faible alignement » de Grok est devenue de plus en plus risquée face à des réglementations mondiales de plus en plus strictes, et ses liens étroits avec X ont également limité son potentiel de croissance indépendante. Confronté à des déséquilibres de coûts, des modèles économiques limités et des frictions réglementaires, l'avenir de xAI reste incertain, tiraillé entre les ambitions des géants, les changements de politique et la volonté personnelle de Musk.
Voir le rapport complet :https://go.hyper.ai/NmLi4
2. Programme complet | Shanghai Innovation Lab, TileAI, Huawei, Advanced Compiler Lab et AI9Stars se réunissent à Shanghai pour une analyse approfondie de l'ensemble du processus d'optimisation des opérateurs.
Le 8e salon technique Meet AI Compiler se tiendra le 27 décembre à la Shanghai Innovation Academy. Cette session réunira des experts de la Shanghai Innovation Academy, de la communauté TileAI, de Huawei HiSilicon, de l'Advanced Compiler Lab et de la communauté AI9Stars. Ils partageront leurs connaissances sur l'ensemble de la chaîne technologique, de la conception de la pile logicielle et du développement des opérateurs à l'optimisation des performances. Les sujets abordés incluront l'interopérabilité inter-écosystèmes de TVM, l'optimisation des opérateurs de fusion de PyPTO, les systèmes à faible latence avec TileRT, les principales techniques d'optimisation pour Triton sur différentes architectures et l'optimisation des opérateurs pour AutoTriton, présentant ainsi un parcours technique complet, de la théorie à la mise en œuvre.
Voir le rapport complet :https://go.hyper.ai/xpwkk
3. Tutoriel en ligne | SAM 3 réalise une segmentation conceptuelle suggérée avec des performances doublées, traitant 100 objets de détection en 30 millisecondes
Bien que les modèles SAM et SAM 2 aient permis des progrès significatifs en segmentation d'images, ils ne parviennent toujours pas à identifier et segmenter automatiquement toutes les occurrences d'un concept au sein du contenu d'entrée. Pour pallier cette lacune, Meta a publié la dernière version, SAM 3. Cette nouvelle version surpasse largement les performances de ses prédécesseurs en segmentation visuelle indicible (PVS) et établit une nouvelle norme pour les tâches de segmentation de concepts indicibles (PCS).
Voir le rapport complet :https://go.hyper.ai/YfmLc
4. Une équipe interdisciplinaire de Carnegie a réussi à capturer des traces de vie datant de 3,3 milliards d'années en utilisant un modèle de forêt aléatoire basé sur 406 échantillons.
L'Institut Carnegie pour la science aux États-Unis, en collaboration avec de nombreuses universités du monde entier, a formé une équipe interdisciplinaire pour perfectionner une solution de « fusion technologique » associant la pyrolyse, la chromatographie en phase gazeuse, la spectrométrie de masse et l'apprentissage automatique supervisé, capable de capturer d'anciennes traces de vie dans des fragments moléculaires chaotiques.
Voir le rapport complet :https://go.hyper.ai/CNPMQ
5. Résumé de l'événement | L'Université de Pékin, l'Université Tsinghua, Zilliz et MoonBit discutent de l'open source et abordent la génération vidéo, la compréhension visuelle, les bases de données vectorielles et les langages de programmation natifs pour l'IA.
HyperAI, co-organisateur de COSCon'25, a accueilli le Forum de collaboration open source industrie-recherche le 7 décembre. Cet article résume les points clés des présentations approfondies de quatre intervenants. Les présentations complètes en vidéo seront également disponibles ultérieurement ; restez connectés !
Voir le rapport complet :https://go.hyper.ai/XrCEl
Articles populaires de l'encyclopédie
1. Mémoire à long terme bidirectionnelle (Bi-LSTM)
2. Vérité de base
3. Contrôle de la mise en page (Layout-to-Image)
4. Navigation incarnée
5. Images par seconde (IPS)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de janvier pour la conférence de haut niveau

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








