Command Palette
Search for a command to run...
TRELLIS.2 : Utilise La Technologie O-Voxel Pour Une Génération Efficace De Géométries Et De Matériaux 3D Complexes ; Ensemble De Données De Prédiction Du Taux D’abandon Des Patients : Aide À Identifier Les Patients À Risque d’abandon.

Actuellement, la génération de modèles 3D utilisables à partir d'images reste longue et laborieuse, les processus traditionnels reposant largement sur l'intervention manuelle de modélisateurs professionnels. Même avec l'aide de l'IA,Lorsqu'il s'agit de formes complexes, de matériaux transparents ou de surfaces ouvertes, les modèles produisent souvent des résultats médiocres ou des structures anormales, et il est difficile de générer des produits finis avec des matériaux réalistes qui puissent être utilisés directement dans les jeux et le commerce électronique.
Dans ce contexte, l'équipe Microsoft a lancé TRELLIS.2, un projet open-source en décembre 2025, pour générer des ressources 3D de haute qualité et effectuer des tâches de texturage à partir d'images uniques.Le projet propose un processus complet, des images d'entrée aux formes et matériaux 3D, et comprend une démo web interactive pour une prise en main rapide et l'exportation des ressources. TRELLIS.2 se concentre sur l'amélioration des détails géométriques et de la cohérence des textures, prend en charge plusieurs résolutions et configurations d'inférence en cascade, et équilibre la vitesse et la qualité grâce à des paramètres d'inférence contrôlables, ce qui le rend adapté à des scénarios tels que la production de contenu 3D, le prototypage rapide et l'exploration créative.
Le site web d'HyperAI propose désormais la démo de génération 3D « TRELLIS.2 », alors venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/drI7I
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 19 au 23 janvier :
* Jeux de données publics de haute qualité : 5
* Une sélection de tutoriels de haute qualité : 9
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en janvier : 3
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de segmentation des patients
La segmentation des patients est un ensemble de données de classification des patients utilisé pour l'analyse et le marketing dans le secteur de la santé. Son objectif est de segmenter les patients en groupes pertinents en analysant leurs caractéristiques démographiques, leur état de santé, leur type d'assurance et leurs habitudes de consommation de soins afin d'améliorer l'efficacité des soins personnalisés et du marketing.
Utilisation directe :https://go.hyper.ai/Wp8LS
2. Ensemble de données de détection de chutes par caméra de vidéosurveillance
CCTV Incident est un jeu de données synthétiques ouvert, conçu spécifiquement pour la détection de chutes, l'estimation de la posture et la surveillance des accidents dans le cadre de tâches de vision par ordinateur. Il est conçu pour analyser les données issues d'une vue aérienne de vidéosurveillance, permettant ainsi aux modèles de comprendre les postures humaines et de distinguer avec précision les personnes debout de celles qui ont chuté.
Utilisation directe :https://go.hyper.ai/q60Dm

3. Ensemble de données de prédiction du taux de désabonnement des patients
L'ensemble de données de prédiction du taux d'abandon des patients est un ensemble de données catégorielles pour le domaine de la santé contenant 2 000 dossiers de patients conçus pour aider à identifier les patients à risque d'abandon afin que des mesures de fidélisation puissent être prises à l'avance.
Utilisation directe :https://go.hyper.ai/QAeYw
4. Ensemble de données RealTimeFaceSwap-10k pour l'usurpation d'identité lors d'appels vidéo
Le jeu de données RealTimeFaceSwap-10k, dédié à la détection des deepfakes lors des appels vidéo, est conçu pour détecter les vidéos truquées dans les contextes de visioconférence. Ce jeu de données comprend divers scénarios d'application et types de données, et vise à fournir un support de données fondamental pour la détection de la falsification vidéo.
Utilisation directe :https://go.hyper.ai/SGZRO
5. Ensemble de données vidéo de synthèse de réflexion transparente TransPhy3D
TransPhy3D est un ensemble de données vidéo synthétiques développé par l'Académie d'intelligence artificielle de Pékin en collaboration avec l'Université de Californie du Sud, l'Université Tsinghua et d'autres institutions. Il se concentre sur les scènes transparentes et réfléchissantes. Cet ensemble de données comprend 11 000 séquences rendues avec Blender/Cycles, fournissant des images RVB de haute qualité ainsi que des étiquettes de profondeur et de normales basées sur la physique.
Utilisation directe :https://go.hyper.ai/5ExjE
Tutoriels publics sélectionnés
1.vLLM+Open WebUI déploie Nemotron-3 Nano
Nemotron-3-Nano-30B-A3B-BF16 est un modèle de langage à grande échelle (LLM) entraîné de zéro par NVIDIA. Conçu comme un modèle unifié, il s'applique aussi bien aux tâches de raisonnement qu'aux tâches ne nécessitant pas de raisonnement. Ce modèle convient aux développeurs concevant des systèmes d'agents IA, des chatbots, des systèmes RAG et d'autres applications d'IA.
Exécutez en ligne :https://go.hyper.ai/VUuDA
2. MedGemma 1.5 Modèle médical d'IA multimodale
MedGemma 1.5 est un modèle performant pour les tâches médicales multimodales. Il offre des capacités exceptionnelles en classification d'images, en réponse à des questions visuelles et en raisonnement médical, ce qui le rend adapté à divers contextes cliniques et contribue efficacement à la recherche et à la pratique médicales. Ce modèle repose sur l'encodeur d'images SigLIP et un module de langage performant, et est pré-entraîné sur différents jeux de données, notamment des images médicales, des textes et des comptes rendus de laboratoire. Il permet ainsi un traitement efficace de tâches telles que les images médicales haute dimensionnelles, les images de pathologie en coupes complètes, l'analyse d'images longitudinales, la localisation anatomique, la compréhension de documents médicaux et l'analyse des dossiers médicaux électroniques.
Exécutez en ligne :https://go.hyper.ai/dZRn9
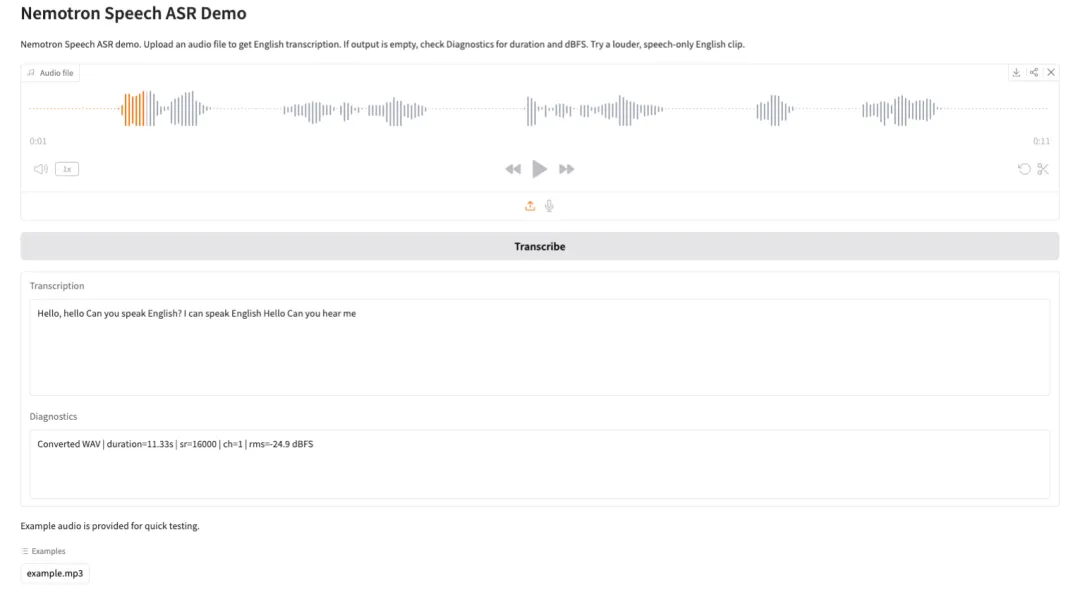
3. Nemotron-Speech-Streaming-ASR : Démonstration de reconnaissance vocale automatique
Nemotron Speech Streaming ASR est un modèle de reconnaissance vocale automatique en flux continu développé par l'équipe Nemotron Speech de NVIDIA. Conçu pour la transcription vocale en temps réel à faible latence, il offre également des capacités d'inférence par lots à haut débit, ce qui le rend idéal pour des applications telles que les assistants vocaux, le sous-titrage en temps réel, la transcription de conférences et l'IA conversationnelle. Le modèle utilise une architecture d'encodeur FastConformer avec gestion du cache et de décodeur RNN-T, permettant un traitement efficace des flux audio continus tout en réduisant considérablement la latence de bout en bout et en préservant la précision de la reconnaissance.
Exécutez en ligne :https://go.hyper.ai/SDEBI
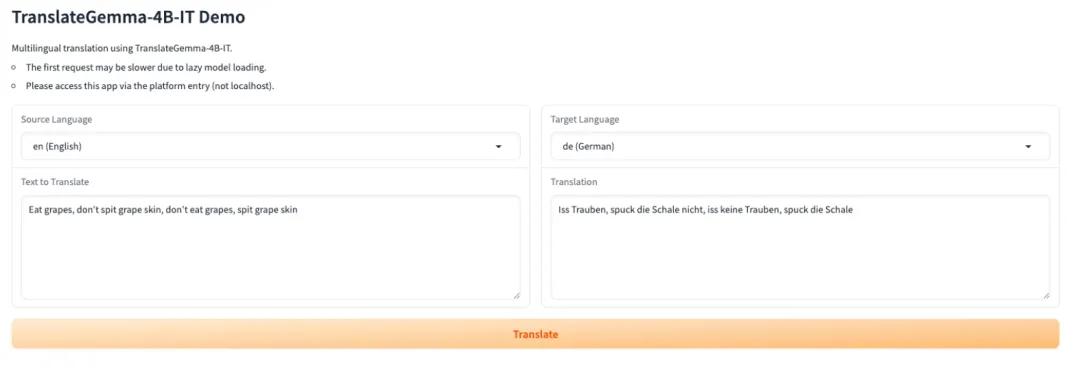
4. TranslateGemma-4B-IT : Une série de modèles de traduction open source de Google.
TranslateGemma est une famille de modèles de traduction légère et open source développée par l'équipe Google Translate. Basée sur la famille de modèles Gemma 3, elle est spécialement conçue pour la traduction de textes multilingues et les scénarios de déploiement concrets. Cette famille offre des capacités de traduction stables et performantes avec un nombre réduit de paramètres, ce qui la rend idéale pour le chargement et l'inférence dans des environnements disposant d'une mémoire GPU limitée ou nécessitant un déploiement rapide.
Exécutez en ligne :https://go.hyper.ai/FRy35
5. GLM-Image : un modèle de génération d’images haute fidélité avec une sémantique précise
GLM-Image est un modèle de génération d'images open source développé par Zhipu AI, qui intègre le décodage autorégressif et le décodage par diffusion. Ce modèle prend en charge la génération d'images à partir de texte et d'images à partir d'images, et repose sur une représentation visuelle et linguistique unifiée. Cela lui permet de comprendre aussi bien les instructions textuelles que les images d'entrée, et d'effectuer une génération d'images affinée grâce à un réseau de diffusion de type DiT (Diffusion Transformer).
Exécutez en ligne :https://go.hyper.ai/2bcfV

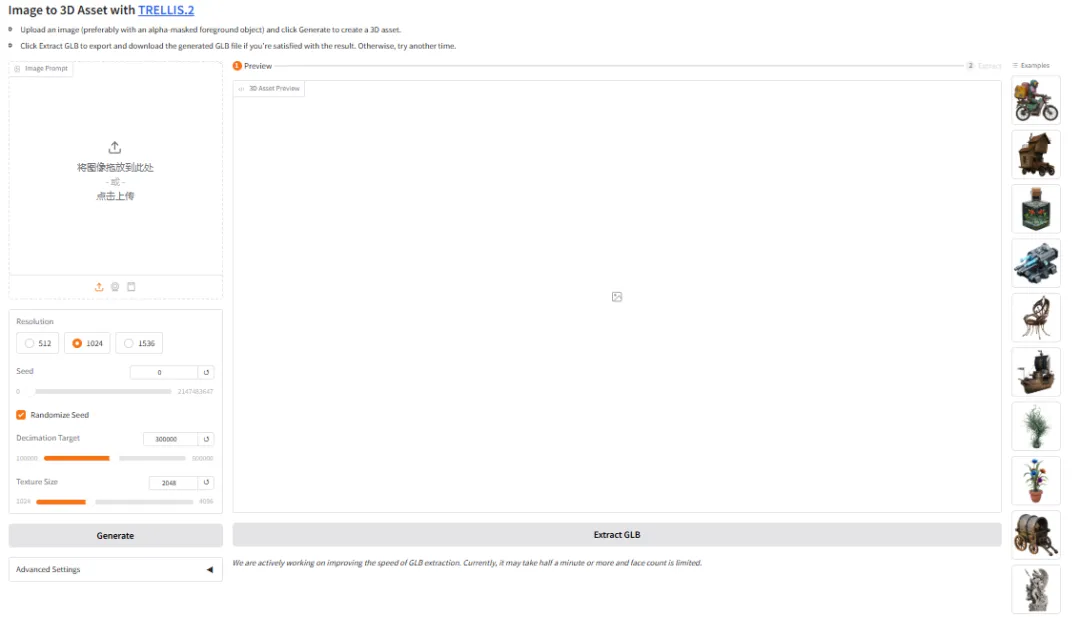
6. Génération de démo 3D TRELLIS.2
TRELLIS.2 est un projet open source de Microsoft, un modèle de grande envergure doté de 4 milliards de paramètres, conçu pour générer des ressources 3D texturées et prêtes à l'emploi directement à partir d'une seule image. Ce modèle unifie la génération de géométrie et de matériaux de haute qualité, réalisant une reconstruction géométrique haute fidélité et une synthèse de matériaux PBR en trois dimensions au sein d'un flux de travail unique.
Exécutez en ligne :https://go.hyper.ai/drI7I
7.vLLM + Fonction de déploiement WebUI ouverteGemma-270m-it
FunctionGemma-270m-it est un modèle léger et dédié aux appels de fonctions, développé par Google DeepMind et doté de 270 millions de paramètres. Basé sur l'architecture Gemma 3 270M, il est entraîné selon les mêmes techniques de recherche que la série Gemini. Spécialement conçu pour les scénarios d'appels de fonctions, ce modèle utilise 6 To de données d'entraînement jusqu'en août 2024, couvrant les définitions d'outils publics et les données d'interaction liées à leur utilisation. FunctionGemma prend en charge une longueur de contexte maximale de 32 Ko et a fait l'objet d'un filtrage rigoureux de la sécurité du contenu et d'un processus de développement d'IA responsable.
Exécutez en ligne :https://go.hyper.ai/pdN7q

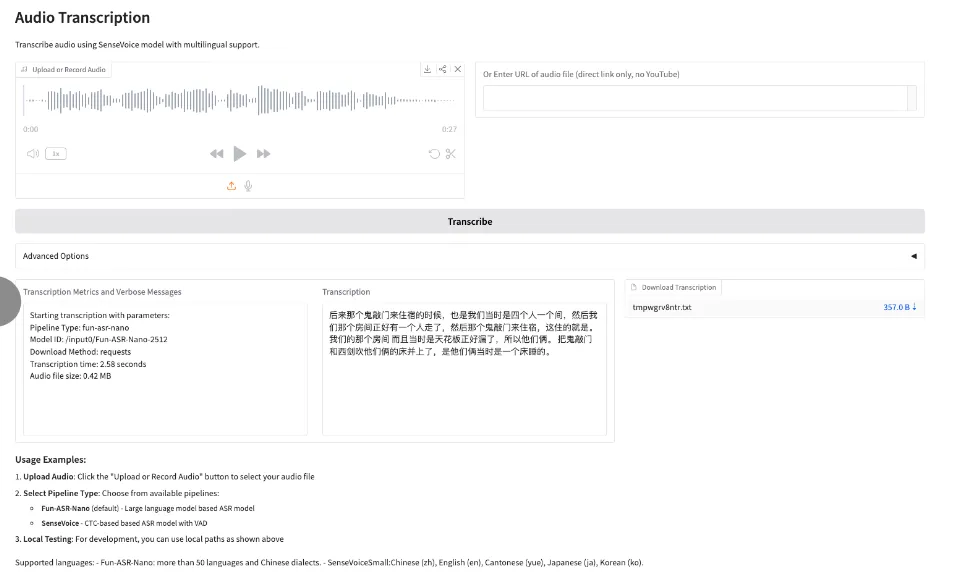
8. Fun-ASR-Nano : un modèle de reconnaissance vocale de bout en bout à grande échelle
Fun-ASR-Nano est une solution de reconnaissance vocale complète pour grands modèles, développée par Alibaba Tongyi Labs et faisant partie de la gamme Fun-ASR. Conçue pour les environnements à faible puissance de calcul, elle vise une transcription vocale en texte à faible latence et se concentre sur les performances sur des jeux de données d'évaluation réels. Ses fonctionnalités incluent la reconnaissance vocale multilingue (avec commutation de code libre), la personnalisation des mots clés et la suppression des hallucinations.
Exécutez en ligne :https://go.hyper.ai/j7OdD
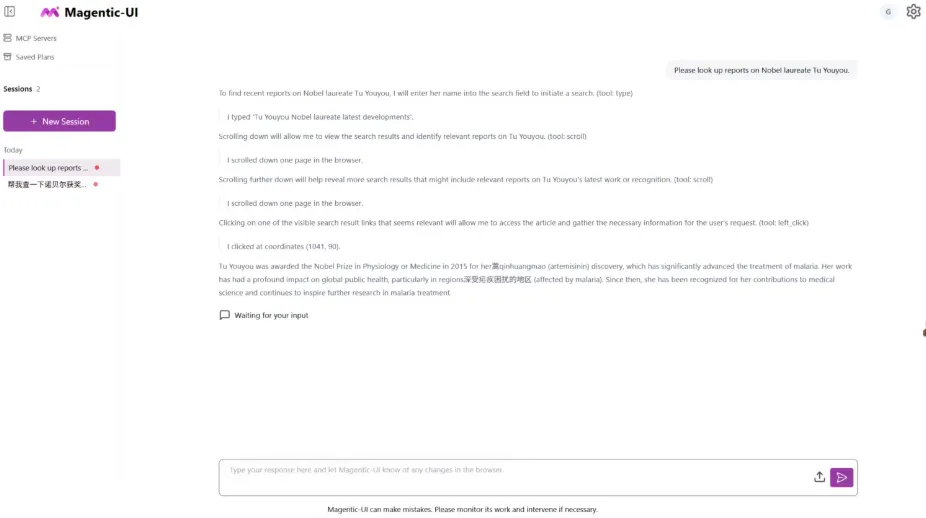
9. Fara-7B : un modèle d’agent intelligent efficace basé sur le Web
Fara-7B est le premier SLM (Small Language Model) agentique destiné à un usage informatique, développé par Microsoft Research. Avec seulement 7 milliards de paramètres, il offre des performances exceptionnelles pour la manipulation de pages web en conditions réelles, atteignant des performances de pointe dans de nombreux benchmarks d'agents web et approchant, voire surpassant, des modèles de plus grande envergure sur certaines tâches.
Exécutez en ligne :https://go.hyper.ai/2e5rp
Recommandation de papier de cette semaine
1. Regarder, raisonner et rechercher : une étude comparative de recherche approfondie sur la vidéo sur le Web ouvert pour le raisonnement vidéo agentiel
Cet article présente VideoDR, le premier banc d'essai d'apprentissage profond pour la vidéo. VideoDR exige des modèles qu'ils extraient des ancres visuelles des vidéos, effectuent une recherche interactive et réalisent une inférence multi-sauts à partir de sources multiples. L'évaluation de différents modèles de grande taille révèle que le paradigme agent n'est pas toujours supérieur au paradigme workflow ; son efficacité dépend de la capacité du modèle à maintenir les ancres visuelles initiales dans de longues chaînes de recherche. L'étude identifie la dérive de la cible et la cohérence à long terme comme des goulots d'étranglement majeurs.
Lien vers l'article :https://go.hyper.ai/uB9jE
2. BabyVision : Le raisonnement visuel au-delà du langage
Cette étude a révélé que les modèles de langage artificiels (MLLM) existants s'appuient excessivement sur des connaissances linguistiques préalables et ne possèdent pas les capacités visuelles fondamentales des jeunes enfants. Le test de référence BabyVision, réalisé par l'équipe de recherche, a montré que les modèles les plus performants (comme Gemini, avec un score de 49,7) obtenaient des scores significativement inférieurs à ceux des adultes (94,1), et même à ceux des enfants de 6 ans, ce qui démontre une déficience fondamentale en compréhension visuelle de base. Cette recherche vise à faire progresser les MLLM vers une perception et un raisonnement visuels comparables à ceux de l'être humain.
Lien vers l'article :https://go.hyper.ai/cjtcE
3. Rapport technique STEP3-VL-10B
Cet article propose STEP3-VL-10B comme modèle de base multimodal open source haute performance. Grâce à un pré-entraînement unifié, un apprentissage par renforcement et un mécanisme innovant d'inférence parallèle coordonnée, il atteint des performances exceptionnelles avec seulement 10 milliards de paramètres. Il rivalise, voire surpasse, des modèles géants 10 à 20 fois plus volumineux et des modèles propriétaires de pointe dans de nombreux tests de performance, offrant ainsi à la communauté un outil de référence puissant et efficace pour l'intelligence visuelle du langage.
Lien vers l'article :https://go.hyper.ai/q6kmv
4. Penser avec une carte : agent cartographique parallèle renforcé pour la géolocalisation
Cet article propose de doter le modèle de la capacité de « penser à l'aide d'une carte ». Grâce à des boucles agent-carte et une optimisation en deux étapes, l'apprentissage par renforcement et la mise à l'échelle parallèle du temps de test sont utilisés, améliorant significativement la précision de la géolocalisation des images. Sur le nouveau jeu de données d'images réelles MAPBench, cette méthode surpasse les modèles open source et propriétaires existants, augmentant considérablement la précision à moins de 500 mètres, passant de 8,01 TP3T à 22,11 TP3T.
Lien vers l'article :https://go.hyper.ai/Fn9XT
5. Segmentation socio-sémantique urbaine par raisonnement vision-langage
Cette étude propose le jeu de données SocioSeg et le cadre SocioReasoner, qui utilisent un modèle de langage visuel pour le raisonnement afin de relever le défi de la segmentation des entités sémantiques sociales dans les images satellitaires. Cette méthode simule le processus d'annotation humaine par la reconnaissance intermodale et le raisonnement multi-étapes, et est optimisée par l'apprentissage par renforcement. Expérimentalement, elle surpasse les modèles de pointe existants, démontrant de fortes capacités de généralisation sans exemple.
Lien vers l'article :https://go.hyper.ai/PW7g4
Interprétation des articles communautaires
1. En intégrant les données de séquence protéique, de structure 3D et de caractéristiques fonctionnelles, une équipe allemande a construit une « vue panoramique » de la ligase d'ubiquitine E3 humaine basée sur l'apprentissage métrique.
Chez les organismes, la dégradation et le renouvellement opportuns des protéines cellulaires sont essentiels au maintien de l'homéostasie protéique. Le système ubiquitine-protéasome (UPS) est un mécanisme fondamental régulant la transduction du signal et la dégradation des protéines. Au sein de ce système, les ligases d'ubiquitine E3 constituent des unités catalytiques clés, et jusqu'à présent, les ligases E3 étudiées ont présenté une forte hétérogénéité. Dans ce contexte, une équipe de recherche de l'Université Goethe en Allemagne a classifié le « ligome E3 humain ». Leur méthode de classification repose sur un paradigme d'apprentissage métrique, utilisant un cadre hiérarchique faiblement supervisé pour appréhender les relations réelles entre la famille E3 et ses sous-familles.
Voir le rapport complet :https://go.hyper.ai/zyM1F
2. L'université de Yale a proposé MOSAIC, qui constitue une équipe de plus de 2 000 experts en chimie IA, permettant une spécialisation efficace et l'identification des voies de synthèse optimales.
La chimie de synthèse moderne est confrontée à une contradiction majeure entre l'accumulation rapide des connaissances et l'efficacité de leur application et de leur transformation. Actuellement, le développement de ce domaine est principalement limité par deux facteurs : d'une part, l'expertise peine à couvrir l'espace réactionnel en constante expansion, ce qui entraîne souvent des coûts élevés liés aux essais et erreurs dans les tâches de synthèse interdisciplinaires ; d'autre part, malgré le développement rapide de l'intelligence artificielle, la fiabilité des modèles généraux en chimie demeure insuffisante. Dans ce contexte, une équipe de recherche de l'Université de Yale a récemment proposé le modèle MOSAIC, transformant un modèle généraliste à langage étendu en un système collaboratif composé de nombreux experts chimistes spécialisés.
Voir le rapport complet :https://go.hyper.ai/oatBT
3. Tutoriel en ligne | GLM-Image : Comprendre avec précision les instructions et rédiger un texte correct grâce à une architecture hybride de décodeur autorégressif et de diffusion
Dans le domaine de la génération d'images, les modèles de diffusion se sont progressivement imposés grâce à leur stabilité d'apprentissage et à leurs fortes capacités de généralisation. Cependant, face à des scénarios exigeant une grande quantité de connaissances, les modèles traditionnels peinent à gérer simultanément la compréhension des instructions et la caractérisation détaillée. Pour pallier ce problème, Zhipu, en collaboration avec Huawei, a mis à disposition en open source un modèle de génération d'images de nouvelle génération : GLM-Image. Ce modèle est entièrement entraîné sur le supercalculateur Ascend Atlas 800T A2 et le framework d'IA MindSpore. Sa principale caractéristique réside dans l'adoption d'une architecture hybride innovante « autorégressive + décodeur de diffusion » (modèle autorégressif 9B + décodeur DiT 7B), combinant la profondeur de compréhension des modèles de langage avec la haute qualité de génération des modèles de diffusion.
Voir le rapport complet :https://go.hyper.ai/LTojo
4. Dernières découvertes publiées dans Nature par l'Université Tsinghua et l'Université de Chicago ! L'IA permet aux scientifiques d'être promus 1,37 an plus tôt et réduit le champ de la recherche scientifique de 4,631 TP3T
Récemment, une équipe de recherche de l'Université Tsinghua et de l'Université de Chicago a publié dans la revue Nature ses dernières conclusions, intitulées « Les outils d'intelligence artificielle étendent l'impact des scientifiques mais réduisent le champ d'application de la science », fournissant ainsi des preuves systématiques sans précédent permettant à l'industrie de comprendre l'impact fondamental de l'IA sur la science.
Voir le rapport complet :https://go.hyper.ai/0NhLI
Articles populaires de l'encyclopédie
1. Images par seconde (IPS)
2. Fusion par tri inversé RRF
3. Modèle de langage visuel (VLM)
4. Hyperréseaux
5. Attention contrôlée
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
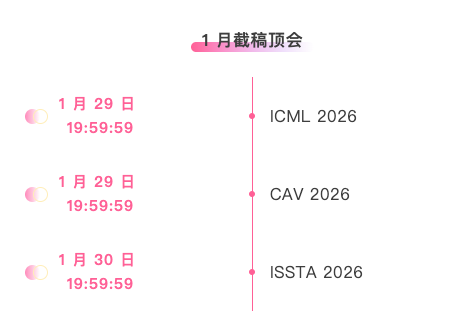
Une plateforme unique pour suivre les principales conférences universitaires en IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








