Command Palette
Search for a command to run...
Après Avoir Analysé 100 Millions De Points De Données Du Télescope Spatial Hubble En 3 Jours, l'Agence Spatiale Européenne a Proposé AnomalyMatch, Découvrant Ainsi Plus d'un Millier d'objets Célestes anormaux.

Actuellement, les relevés du ciel à grande échelle, multibandes, à large champ de vision et à haute profondeur propulsent l'astronomie dans une ère de traitement des données sans précédent. Grâce à la mise en service d'instruments de nouvelle génération tels que le télescope spatial Euclid, l'observatoire Rubin et le télescope spatial Roman, l'univers est cartographié systématiquement à une échelle et avec une précision inégalées. Ces observations devraient générer des milliards d'images célestes et de données spectroscopiques, ce qui constitue l'un de leurs principaux atouts scientifiques.Autrement dit, découvrir et identifier systématiquement ces corps célestes rares présentant une valeur astrophysique particulière.Parmi les exemples, citons les lentilles gravitationnelles fortes, les galaxies en fusion, les galaxies en forme de méduse et les disques protoplanétaires à orientation de bord.
Ces objets célestes rares, souvent qualifiés d’« anomalies astrophysiques », jouent un rôle crucial dans la validation des modèles d’évolution des galaxies, des théories de la gravitation et des paramètres cosmologiques. Cependant, leur découverte a longtemps reposé en grande partie sur l’identification visuelle fortuite par les chercheurs ou sur un tri manuel effectué par des projets de sciences participatives.Ces méthodes sont non seulement très subjectives et inefficaces, mais aussi difficiles à adapter à l'échelle massive de données qui va bientôt émerger.
en même temps,Les méthodes traditionnelles d'apprentissage automatique supervisé sont confrontées à des défis fondamentaux en raison du nombre extrêmement limité d'échantillons étiquetés d'objets célestes rares et du déséquilibre extrême des catégories de données.Pour pallier cette difficulté, la recherche s'est progressivement orientée vers des cadres de détection d'anomalies non supervisés ou faiblement supervisés. Ces méthodes ne prédéfinissent pas de catégories cibles spécifiques ; elles apprennent plutôt la structure ou la distribution globale des données grâce à des algorithmes, identifiant ainsi automatiquement les valeurs aberrantes qui s'écartent significativement du groupe « normal ». Par exemple, des outils basés sur des algorithmes tels que les forêts d'isolation et les facteurs d'anomalie locaux, ou des techniques qui construisent des espaces de représentation par apprentissage auto-supervisé puis effectuent des recherches de similarité, ont démontré leur efficacité dans des tâches telles que la détection de lentilles gravitationnelles fortes à partir de données de relevés du ciel à grande échelle.
Cependant, les méthodes purement non supervisées peuvent produire un grand nombre d'anomalies « parasites » sans intérêt pour l'astrophysique. Pour pallier cet inconvénient,Une équipe de recherche du Centre européen d'astronomie spatiale (ESAC), une division de l'Agence spatiale européenne (ESA), a proposé et appliqué une nouvelle méthode appelée AnomalyMatch.La détection d'objets célestes rares est définie comme un problème de classification binaire semi-supervisé extrêmement déséquilibré, intégrant des boucles d'apprentissage actif. Elle peut être initialisée avec un nombre très réduit d'échantillons anormaux étiquetés, moins de dix. Parallèlement, elle exploite pleinement le potentiel des données non étiquetées grâce à des techniques d'apprentissage semi-supervisé telles que les pseudo-étiquettes et la régularisation de cohérence. De plus, un mécanisme de vérification par des experts est intégré tout au long du processus, et les performances de détection sont progressivement améliorées grâce à l'utilisation optimale des données non étiquetées et des connaissances d'experts.
Les résultats de cette recherche, intitulée « Identification d'anomalies astrophysiques dans 99,6 millions de découpes de sources issues des archives de Hubble à l'aide d'AnomalyMatch », ont été publiés dans Astronomy & Astrophysics.
Points saillants de la recherche :
* AnomalyMatch a été utilisé pour effectuer le premier criblage systématique d'objets célestes anormaux dans l'ensemble des archives du patrimoine Hubble (environ 100 millions de coupes d'images).
* Le système a publié un catalogue d'anomalies astrophysiques nouvellement découvertes, élargissant considérablement la bibliothèque d'échantillons de phénomènes rares, comprenant 417 nouvelles fusions de galaxies, 138 candidats de lentilles gravitationnelles, 18 galaxies en forme de méduse et 2 galaxies à anneaux de collision.
* L'efficacité et la précision de traitement extrêmement élevées de la méthode ont été vérifiées avec succès, l'analyse complète des données ayant été réalisée en seulement 2 à 3 jours, démontrant ainsi son potentiel transformateur dans le traitement des futures données d'observations du ciel à très grande échelle provenant du télescope euclidien et d'autres sources.
Adresse du document :https://doi.org/10.1051/0004-6361/202555512
Suivez notre compte WeChat officiel et répondez « corps célestes rares » en arrière-plan pour obtenir le PDF complet.
Autres articles sur les frontières de l'IA :
https://hyper.ai/papers
Construit à partir d'un ensemble de données standardisé d'environ 100 millions de cartes de découpe de sources de Hubble
Les données utilisées dans cette étude proviennent d'extraits de sources générés par O'Ryan et al. Ce travail visait initialement à rechercher systématiquement des galaxies en interaction et en fusion dans les archives du Hubble Legacy Archive, en traitant la quasi-totalité des sources étendues de ces archives afin de constituer un ensemble d'images standardisé à grande échelle. Pour garantir la cohérence et l'opérabilité des données,Les chercheurs ont sélectionné uniquement les images mosaïques calibrées de niveau 3 acquises par le canal à grand champ de la caméra avancée pour les relevés du télescope spatial Hubble sous le filtre F814W.Cela fait référence aux données qui ont été traitées au point de pouvoir être directement utilisées pour l'analyse scientifique.
Ce processus de sélection a permis d'obtenir environ dix mille observations, couvrant des sources étendues du catalogue de sources Hubble publié par Whitmore et al. à l'aide du logiciel SourceExtractor.Cela a finalement abouti à une bibliothèque d'images contenant environ 99,6 millions d'images recadrées provenant d'une source unique.Chaque tranche, de taille fixe (150 × 150 pixels), correspond à une région céleste d'environ 7,5 secondes d'arc de côté. Elle est améliorée par les méthodes d'étirement linéaire et d'intervalle Z d'Astropy, puis enregistrée au format JPEG en niveaux de gris. Bien que le catalogue de sources de Hubble intègre MatchID pour la déduplication, Orion et al. ont choisi de l'effectuer uniquement après la classification afin de préserver les informations structurelles des systèmes en interaction ou des galaxies à plusieurs noyaux en fusion. Les chercheurs ont appliqué la même stratégie pour s'assurer que l'ensemble d'entraînement ne contienne pas de tranches différentes provenant d'une même source.
De plus, lors d'observations approfondies de certains champs d'étoiles compacts, tels que la galaxie d'Andromède, le Nuage de Magellan ou les amas globulaires, des sources ponctuelles denses peuvent être fusionnées en une seule « source étendue » par logiciel, formant ainsi un type particulier d'artefact d'image.Les chercheurs ont identifié de tels cas lors d'un apprentissage actif ultérieur et ont utilisé des modèles guidés par annotation pour les classer comme des objets anormaux à faible score.Pour améliorer l'efficacité de l'accès aux données, les quelque 99,6 millions de tranches sont stockées dans des blocs répartis sur environ mille fichiers HDF5.
Pour constituer l'ensemble d'entraînement, les chercheurs ont initialement ciblé les disques protoplanétaires alignés sur les bords. Ainsi, comme illustré dans la figure ci-dessous, les données d'entraînement initiales ne contenaient que 3 échantillons anormaux de ce type, 128 échantillons normaux étiquetés et un grand nombre d'images non étiquetées. Les échantillons normaux ont été obtenus par échantillonnage aléatoire dans l'ensemble de la base de données et par vérification manuelle, incluant les galaxies isolées, les champs d'étoiles et les artefacts courants.
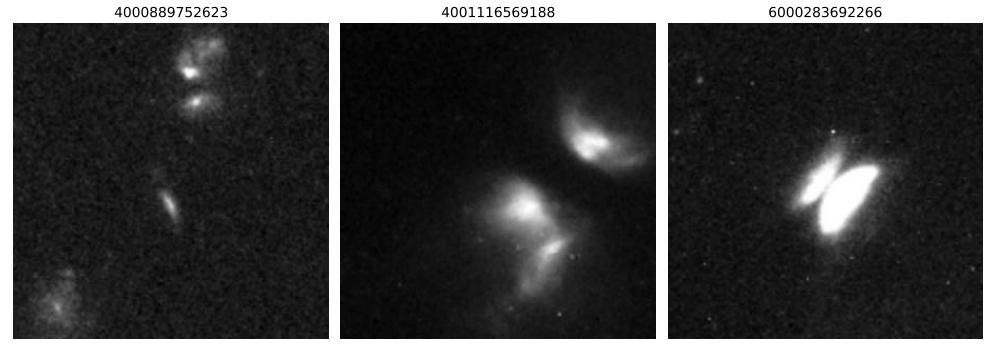
Cependant, avec l'introduction de l'apprentissage actif,Les objets candidats à haute fiabilité fournis par le modèle ont rapidement été étendus à d'autres corps célestes aux formes particulières et présentant un intérêt pour la recherche.À partir de là, les chercheurs ont progressivement constitué et enrichi un ensemble d'entraînement plus général, qui comprenait finalement 1 400 images étiquetées, dont 375 anormales et 1 025 normales. Les échantillons anormaux comprenaient principalement des galaxies en fusion (178) et des systèmes de lentilles gravitationnelles (63).

Malgré la diversité et la taille croissantes de l'ensemble d'entraînement, les chercheurs n'ont pas réussi à découvrir de nouveaux disques protoplanétaires alignés sur les bords dans les données F814W. Ceci s'explique principalement par deux raisons : d'une part, ces objets sont extrêmement rares dans cette bande d'observation ; d'autre part, l'intégration progressive d'autres types d'anomalies à l'ensemble d'entraînement a fait que les quelques échantillons de disques protoplanétaires connus sont devenus des données d'entraînement, réduisant ainsi la probabilité qu'ils soient considérés comme des anomalies « inconnues » et donc redétectés. Ce processus illustre également l'évolution de cette méthode, d'un outil de recherche de cibles spécifiques à un cadre général de détection d'anomalies.
AnomalyMatch : un cadre de détection d’anomalies interactif et efficace combinant apprentissage semi-supervisé et apprentissage actif.
AnomalyMatch est un cadre d'apprentissage automatique développé par des chercheurs pour relever le défi de la détection d'objets célestes rares dans de vastes ensembles de données astronomiques. L'innovation fondamentale de cette méthode réside dans…Elle définit explicitement la détection d'anomalies comme un problème de classification binaire extrêmement déséquilibré et combine de manière créative l'apprentissage semi-supervisé avec une boucle d'apprentissage active.Cela permet la découverte efficace de cibles rares potentielles dans des quantités massives de données non étiquetées, en ne s'appuyant que sur un très petit nombre d'échantillons anormaux connus.
Comme illustré dans la figure ci-dessous, la conception de ce modèle repose sur des paradigmes d'apprentissage semi-supervisé avancés tels que FixMatch. Son architecture utilise des données étiquetées et non étiquetées issues de l'ensemble de données utilisateur pour entraîner l'architecture EfficientNet, afin d'optimiser l'efficacité de calcul et la capacité d'extraction de caractéristiques.Le cadre global comprend deux composantes d'apprentissage collaboratif : la partie apprentissage supervisé utilise une perte focale combinée à une stratégie de pondération dynamique.Il met également en œuvre un suréchantillonnage intelligent pour les catégories d'anomalies rares afin d'atténuer efficacement le biais d'entraînement causé par un déséquilibre extrême des classes ;La partie non supervisée génère des pseudo-étiquettes à haute confiance à partir d'images faiblement améliorées.De plus, une contrainte de régularisation de cohérence est imposée à la version fortement améliorée, forçant le modèle à apprendre des représentations morphologiques robustes dans les données, plutôt que de s'appuyer sur des artefacts de surface.
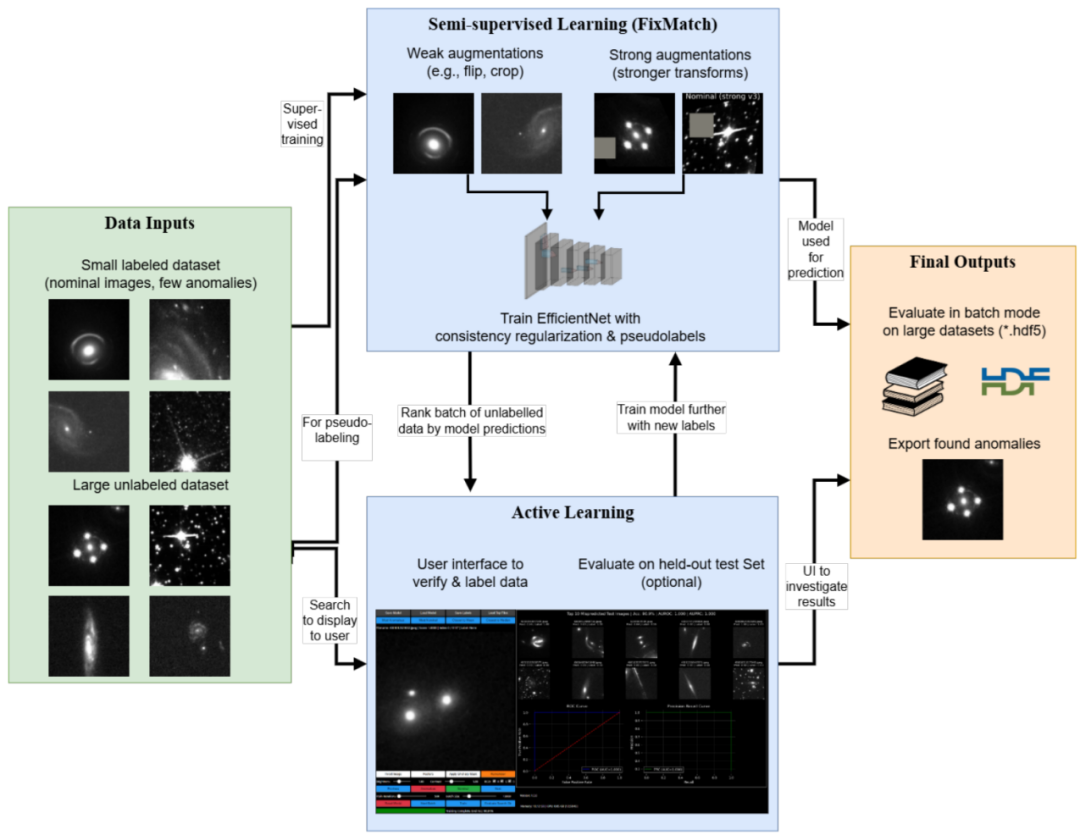
En termes de mécanisme d'entraînement, le modèle adopte une stratégie d'optimisation par étapes.Dans la phase initiale, un petit nombre d'échantillons étiquetés sont utilisés pour l'échauffement supervisé, puis des données non étiquetées et leurs pseudo-étiquettes sont progressivement introduites pour l'entraînement semi-supervisé.Après chaque cycle d'entraînement, le modèle analyse l'ensemble des données non étiquetées et attribue un « score d'anomalie » à chaque échantillon. Ce score repose sur la confiance du modèle dans la prédiction de la catégorie d'anomalie, et sa fiabilité est améliorée par une stratégie de calibration.
Surtout, AnomalyMatch intègre de manière transparente un flux de travail d'apprentissage actif et interactif. Ce flux de travail présente aux experts du domaine, via une interface web dédiée à l'analyse d'images astronomiques, les échantillons candidats ayant obtenu les meilleurs scores de prédiction. Les experts peuvent ainsi classer, étiqueter ou éliminer rapidement les échantillons, et les résultats de validation sont réinjectés en temps réel dans la boucle d'entraînement. Les échantillons nouvellement validés enrichissent non seulement l'ensemble des étiquettes, mais leurs annotations permettent également d'ajuster dynamiquement les pondérations des classes et les seuils des pseudo-étiquettes, formant ainsi une boucle d'auto-amélioration : « recommandation du modèle – validation par les experts – itération du modèle ».
Pour les archives du patrimoine de Hubble, qui contiennent environ 100 millions de coupes de sources, le modèle effectue un cycle complet d'inférence de données en seulement 2,5 jours environ, et prend en charge la reprise après interruption et les mises à jour incrémentales.En pratique, ce cadre a permis de découvrir un grand nombre de nouveaux objets célestes rares, tels que des galaxies en fusion, des lentilles gravitationnelles et des galaxies en forme de méduse, et d'identifier plusieurs systèmes uniques encore inédits. Sa grande efficacité et sa forte capacité de généralisation démontrent pleinement l'intérêt majeur de tels cadres hybrides intelligents pour le traitement des données issues des relevés du ciel à très grande échelle de nouvelle génération.
1 339 objets célestes inhabituels découverts dans les archives du patrimoine Hubble
Après avoir achevé l'entraînement du modèle, l'étude l'a appliqué à l'ensemble des données des archives du patrimoine de Hubble afin de rechercher et de classer systématiquement les objets célestes anormaux.
Dans un premier temps, les chercheurs ont rigoureusement dédupliqué les 5 000 échantillons candidats présentant les scores d'anomalie les plus élevés dans les résultats du modèle. Plus précisément, ils ont croisé les identifiants des échantillons avec ceux du catalogue de sources de Hubble, extrait leurs coordonnées, puis effectué un appariement radial précis sur un rayon de 10 secondes d'arc. La probabilité que deux objets anormaux indépendants coexistent à une distance angulaire aussi faible étant extrêmement faible, cette méthode élimine efficacement les coupures d'images dupliquées dues à la fragmentation des données. Le résultat obtenu est présenté dans la figure ci-dessous.Les chercheurs ont obtenu 1 339 candidats anormaux uniques, ce qui reflète intuitivement le problème du taux de répétition élevé présent dans l'ensemble de données original.
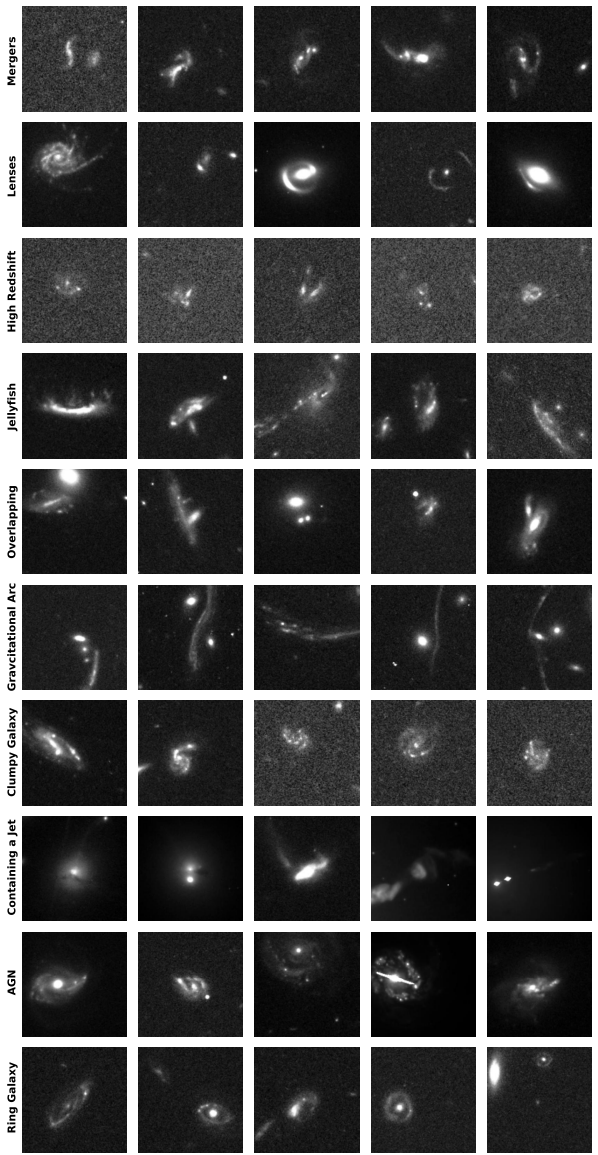
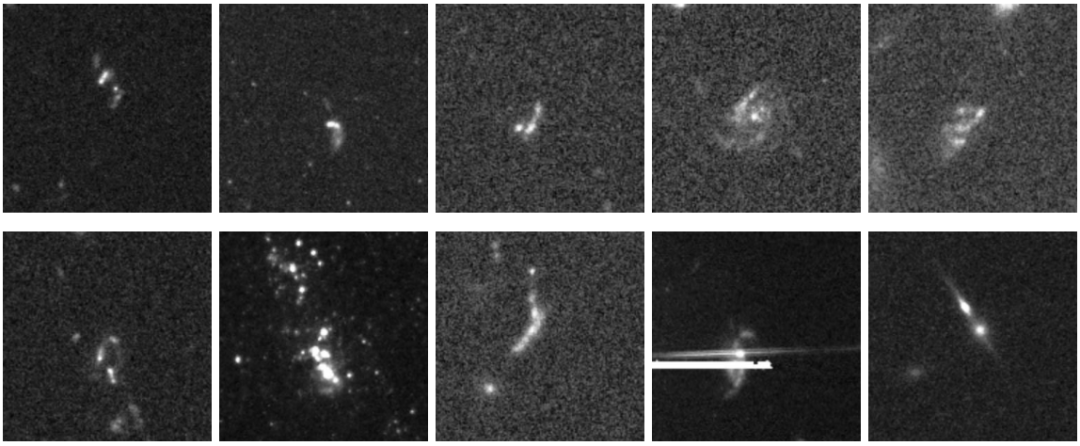
Par la suite, des experts du domaine, s'appuyant sur une analyse morphologique et des recherches bibliographiques dans des bases de données telles que SIMBAD et ESASky, ont minutieusement sous-classé chacun des 1 339 échantillons uniques. Les résultats de la classification ont montré que…Les galaxies en fusion ou en interaction sont la catégorie la plus fréquemment découverte, totalisant 629 systèmes indépendants, représentant environ 501 TP3T du total.
Cela s'explique en partie par le fait que ces corps célestes appartiennent à des catégories d'objets anormaux relativement courantes, et en partie par leurs fortes interactions de marée, qui leur confèrent une morphologie unique, facilement reproductible par les modèles. Il convient de noter que le champ de vision des chercheurs étant limité, certains systèmes de fusion en phase finale, fortement perturbateurs, peuvent apparaître comme des objets isolés sur les images. Leurs propriétés de fusion doivent alors être confirmées par un ajustement du champ de vision ou par la consultation de la littérature scientifique.
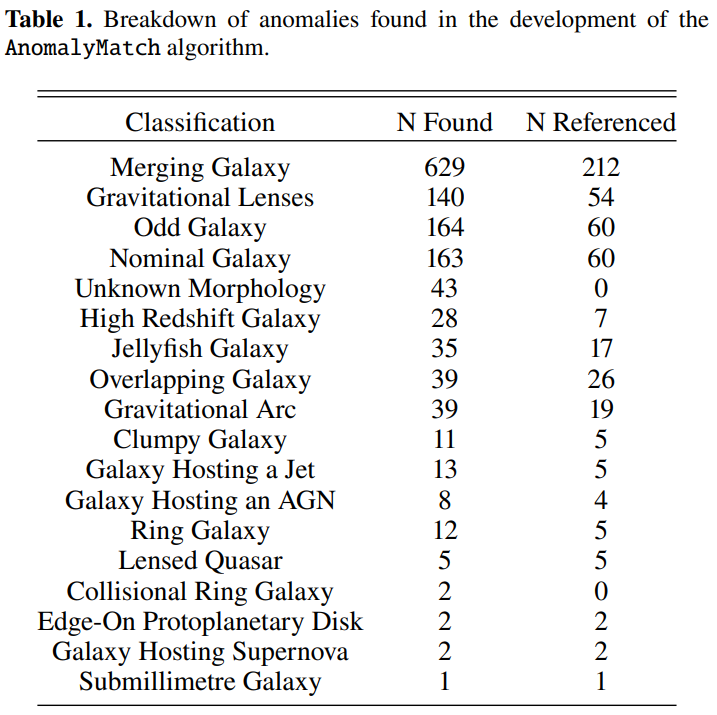
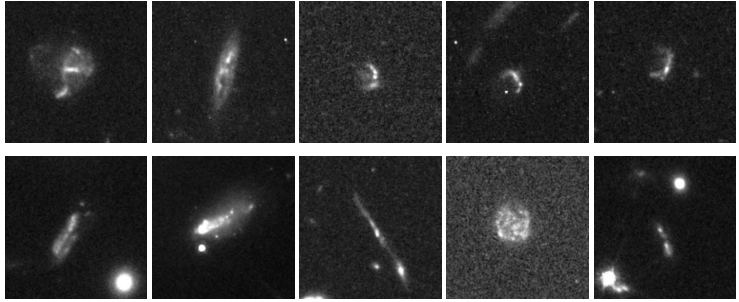
Les lentilles gravitationnelles et les phénomènes associés constituent la deuxième grande catégorie de découvertes d'anomalies. Les chercheurs ont identifié un nombre important de candidats à des lentilles gravitationnelles fortes, dont plusieurs systèmes connus et de nombreux nouveaux candidats potentiels. Ils ont également distingué 39 arcs gravitationnels, généralement générés par des amas de galaxies au premier plan, dont l'échelle dépasse souvent celle d'un simple tilde et n'apparaît dans les données que comme un fragment d'un arc lumineux géant. Le modèle a aussi permis de détecter un groupe de galaxies à haut décalage vers le rouge, qui apparaissent sur les images comme des taches denses, légèrement désordonnées et présentant un faible rapport signal/bruit, ce qui correspond aux caractéristiques observationnelles de tels objets.
Dans d'autres catégories, les chercheurs ont découvert 35 galaxies en forme de méduse répondant à des critères stricts (toutes situées dans des amas de galaxies et présentant des ondes de choc en bordure d'onde et des traînées de décapage), 11 galaxies en grumeaux et un nombre similaire de galaxies se chevauchant. Il est à noter que le modèle, sans aucun apprentissage spécifique, a démontré une remarquable capacité de généralisation dans la reconnaissance des caractéristiques morphologiques.Plusieurs lentilles de quasars (caractérisées par des structures telles que la « croix d'Einstein ») et 13 galaxies hôtes de jets relativistes, assez rares dans la bande optique, ont été découvertes avec succès.Cela démontre qu'AnomalyMatch peut transférer les connaissances acquises et détecter des sous-types anormaux qui n'apparaissent pas dans l'ensemble d'entraînement.
En plus des membres clairement catégorisés mentionnés ci-dessus, le catalogue final comprend également trois catégories générales : « Galaxies spéciales » désigne les objets célestes aux formes très irrégulières qui ne correspondent à aucune sous-catégorie existante ; « Galaxies normales » représente les faux positifs (environ 10%) où le jugement du modèle est incorrect, incluant principalement des galaxies isolées avec de légères perturbations structurelles, des champs d’étoiles denses ou des artefacts instrumentaux ; et « Galaxies inconnues » couvre 43 cibles particulières qui ne peuvent pas être classées actuellement sur la base des connaissances existantes, laissant la porte ouverte à de futures recherches.
L'IA remodèle l'astronomie moderne
Face au tsunami de données engendré par la nouvelle génération de relevés astronomiques à grande échelle, la recherche astronomique mondiale connaît un profond changement de paradigme.
Dans le milieu universitaire, l'un des axes de recherche consiste à développer des machines capables de mieux comprendre les variations temporelles et d'état complexes des données astronomiques. Par exemple, une équipe de recherche de l'Université de Toronto, de l'Imperial College de Londres et du Centre d'astrophysique Harvard-Smithsonian a mis au point une nouvelle méthode, basée sur des modèles de Markov cachés à espace continu, permettant d'identifier et de distinguer automatiquement les différents états physiques des sources astronomiques.
En termes simples, cette méthode modélise l'activité stellaire comme une série d'états cachés et en perpétuelle évolution.je En analysant les courbes de variation de la lumière multibande capturées par le télescope, il est possible de déduire intelligemment l'état physique d'un corps céleste à chaque instant.L'équipe de recherche a appliqué cet algorithme à une étoile éruptive active appelée EV Lac. L'IA a réussi à distinguer différents états, tels que « calme » et « éruptif », à partir de ses données de rayons X et a quantifié avec précision les caractéristiques des événements éruptifs.
Titre de l'article :
Séparation des états dans les sources astronomiques à l'aide de modèles de Markov cachés : étude de cas des phases d'éruption et de quiescence sur EV Lac
Lien vers l'article :https://doi.org/10.1093/mnras/stae2082
Dans le même temps, le monde des affaires participe à cette révolution des données astronomiques de manière inédite, non plus seulement en tant que fournisseur de technologies, mais aussi en tant que concepteur, constructeur et exploitant de missions scientifiques. Open Cosmos, entreprise européenne leader dans le domaine des technologies spatiales, en est un parfait exemple. En 2024, elle a noué un partenariat avec l'Institut spatial catalan…La société a officiellement conçu et construit sa première plateforme satellitaire dédiée à la recherche astrophysique, « PhotSat ».Ce CubeSat, petit mais puissant, embarquera deux télescopes et est conçu pour scruter l'ensemble du ciel dans les bandes visible et ultraviolette tous les deux jours, surveillant en continu les variations de dizaines de millions d'étoiles parmi les plus brillantes. Ses objectifs scientifiques sont très clairs : fournir un flux de données précieux pour des recherches essentielles telles que la recherche d'exoplanètes, la caractérisation des propriétés stellaires et la détection des explosions de supernovae.
Qu'il s'agisse des modèles de Markov cachés développés dans les laboratoires universitaires pour mieux comprendre les données en profondeur, ou des satellites astrophysiques construits par des entreprises spatiales commerciales pour atteindre des objectifs scientifiques précis, leur principal moteur est de gérer la croissance exponentielle du volume et de la complexité des données. Avec la mise en service d'installations de nouvelle génération comme l'Observatoire Rubin et le télescope spatial Roman, il est probable que ce modèle à double moteur – « algorithmes intelligents + plateformes innovantes » – se généralise, propulsant l'astronomie d'une approche fondée sur les hypothèses vers une nouvelle ère pilotée à la fois par les données et les algorithmes. Cette ère permettra une découverte plus efficace des mystères cosmiques rares et précieux de l'immensité de l'univers.
Liens de référence :
1.https://www.electronicsweekly.com/news/business/open-cosmos-to-develop-astrophysical-satellite-2024-10/








