HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow

On the Role of Discreteness in Diffusion LLMs

























Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow
On the Role of Discreteness in Diffusion LLMs
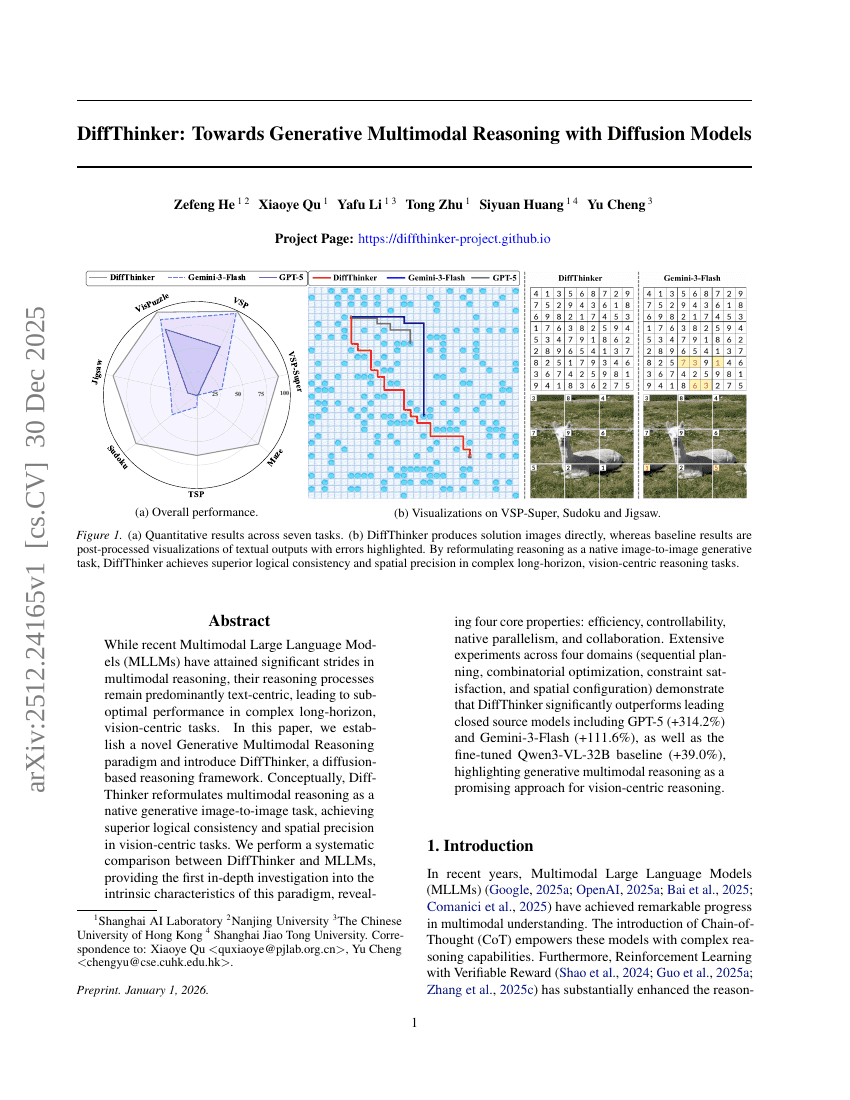
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Scaling Open-Ended Reasoning to Predict the Future
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
mHC: Manifold-Constrained Hyper-Connections
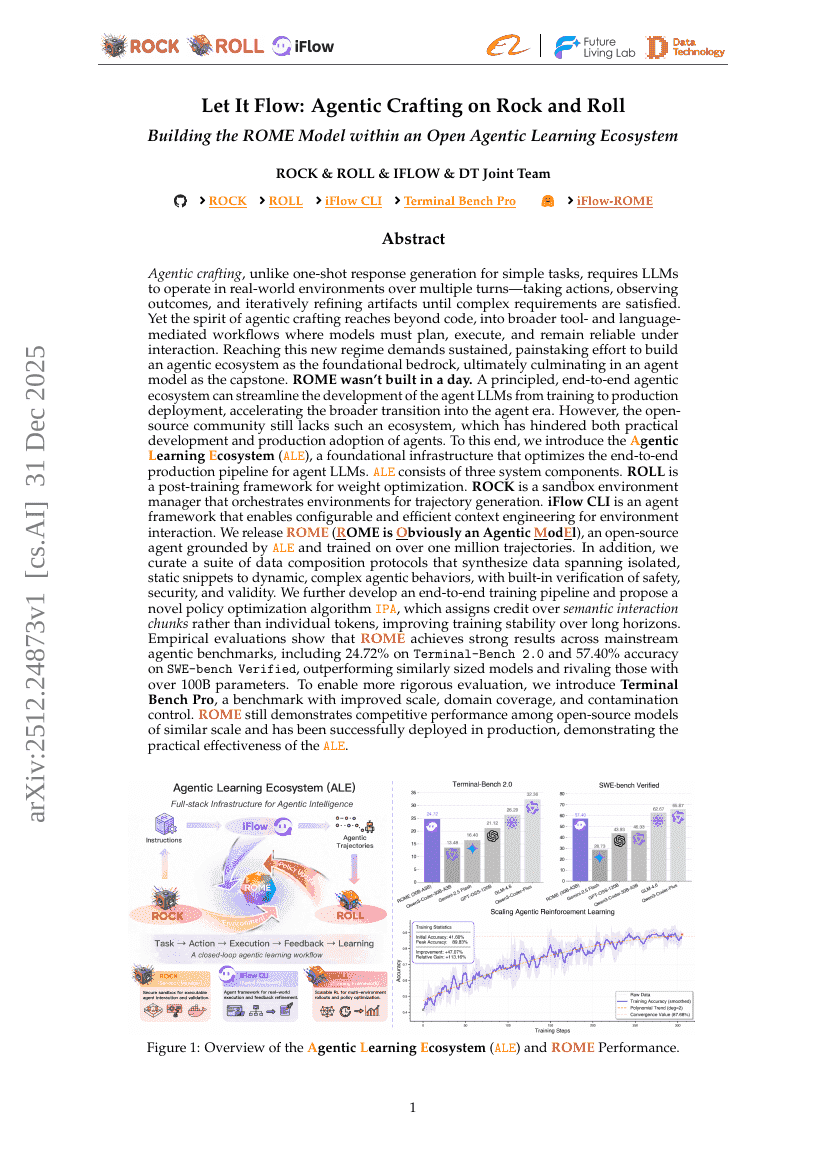
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
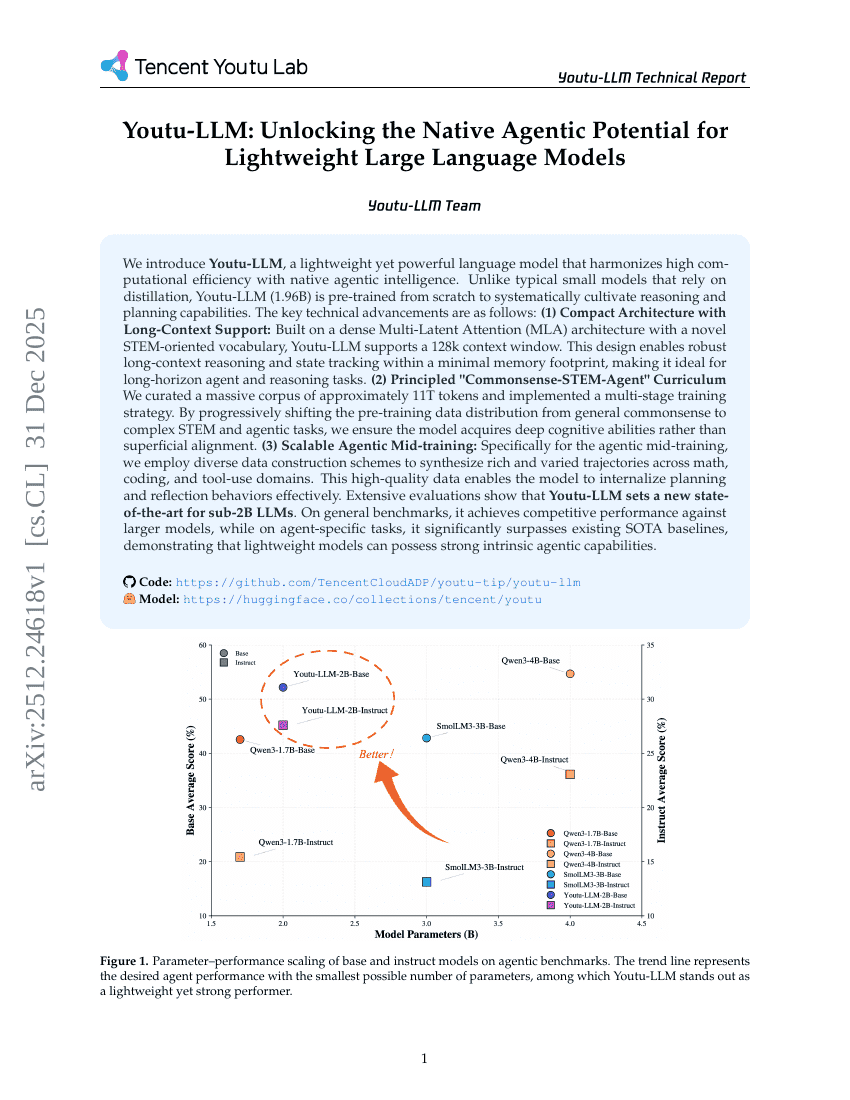
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
GateBreaker: Gate-Guided Attacks on Mixture-of-Expert LLMs
GraphLocator: Graph-guided Causal Reasoning for Issue Localization
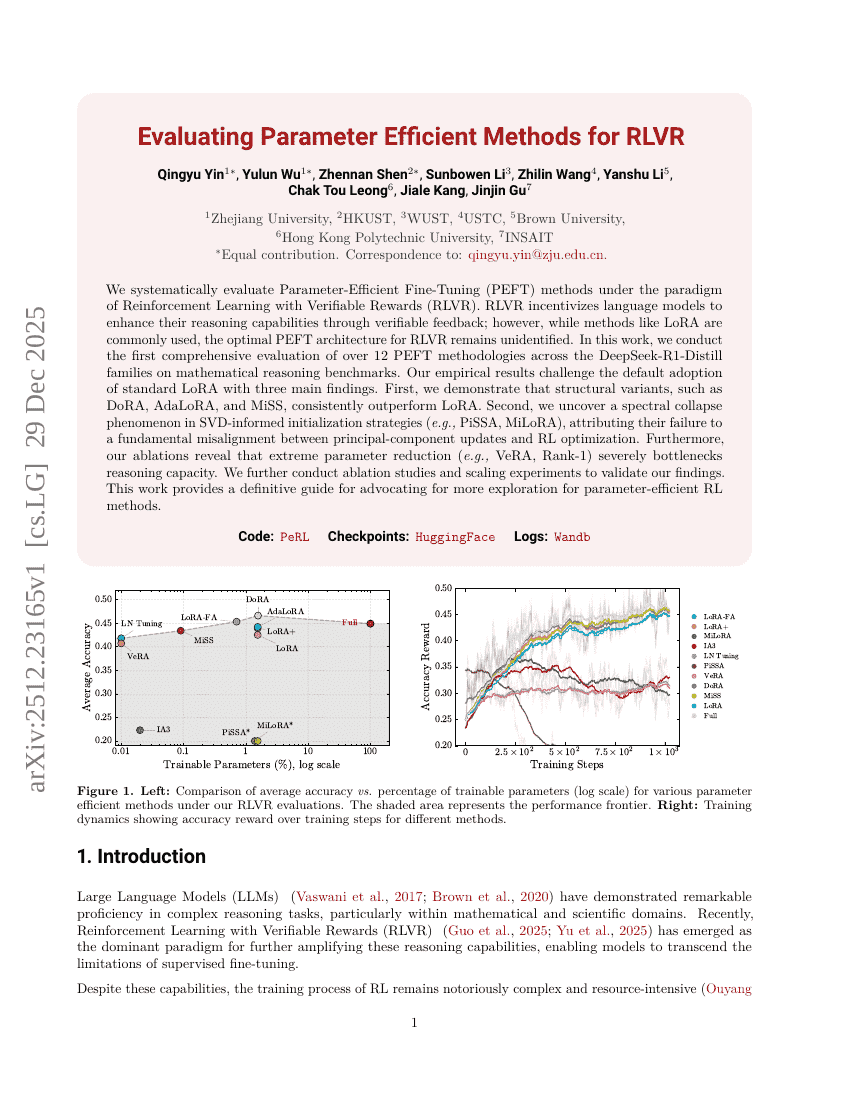
Evaluating Parameter Efficient Methods for RLVR
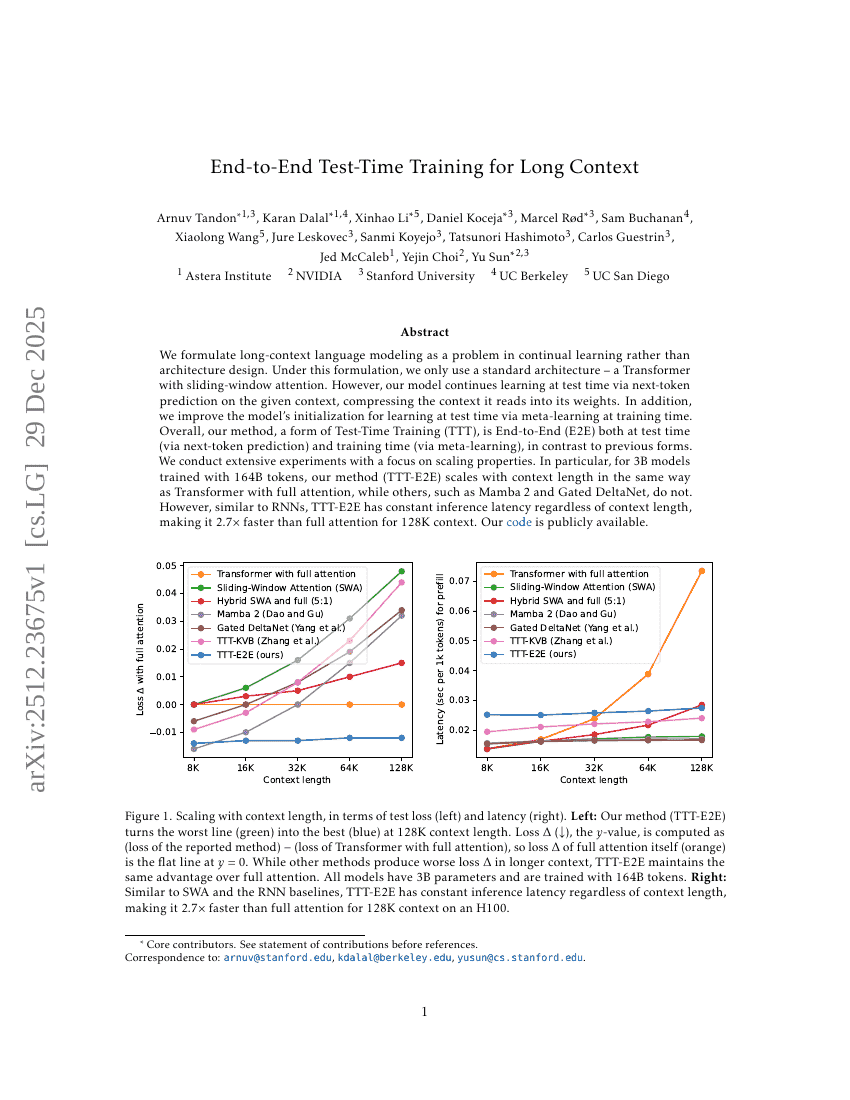
End-to-End Test-Time Training for Long Context
DreamOmni3: Scribble-based Editing and Generation
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling
SpotEdit: Selective Region Editing in Diffusion Transformers
Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Yume-1.5: A Text-Controlled Interactive World Generation Model
LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss
LongFly: Long-Horizon UAV Vision-and-Language Navigation with Spatiotemporal Context Integration
Attention Is Not What You Need
SlideTailor: Personalized Presentation Slide Generation for Scientific Papers
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
InsertAnywhere: Bridging 4D Scene Geometry and Diffusion Models for Realistic Video Object Insertion
Mindscape-Aware Retrieval Augmented Generation for Improved Long Context Understanding
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Scaling Open-Ended Reasoning to Predict the Future
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
mHC: Manifold-Constrained Hyper-Connections
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
GateBreaker: Gate-Guided Attacks on Mixture-of-Expert LLMs
GraphLocator: Graph-guided Causal Reasoning for Issue Localization
Evaluating Parameter Efficient Methods for RLVR
End-to-End Test-Time Training for Long Context
DreamOmni3: Scribble-based Editing and Generation
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling
SpotEdit: Selective Region Editing in Diffusion Transformers
Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Yume-1.5: A Text-Controlled Interactive World Generation Model
LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss
LongFly: Long-Horizon UAV Vision-and-Language Navigation with Spatiotemporal Context Integration
Attention Is Not What You Need
SlideTailor: Personalized Presentation Slide Generation for Scientific Papers
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
InsertAnywhere: Bridging 4D Scene Geometry and Diffusion Models for Realistic Video Object Insertion
Mindscape-Aware Retrieval Augmented Generation for Improved Long Context Understanding