HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generation

The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding























QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generation
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
Med-Banana-50K: A Cross-modality Large-Scale Dataset for Text-guided Medical Image Editing
Kascade: A Practical Sparse Attention Method for Long-Context LLM Inference
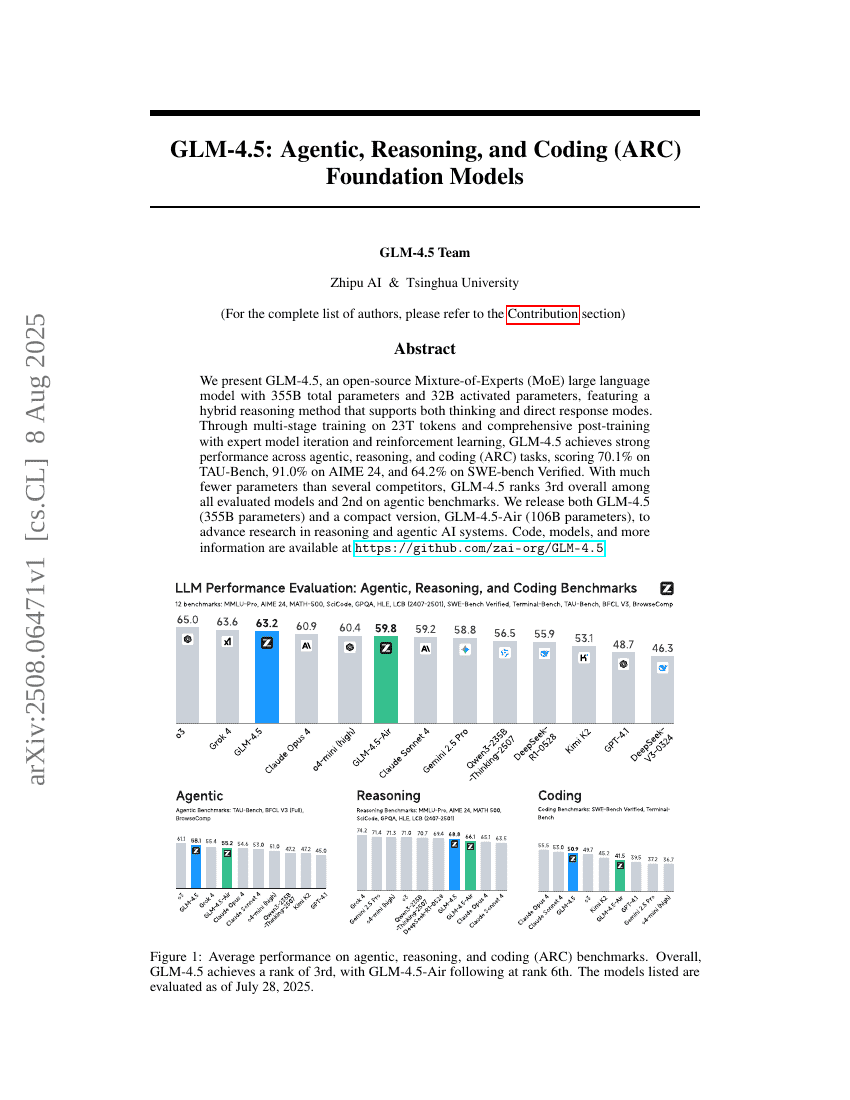
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
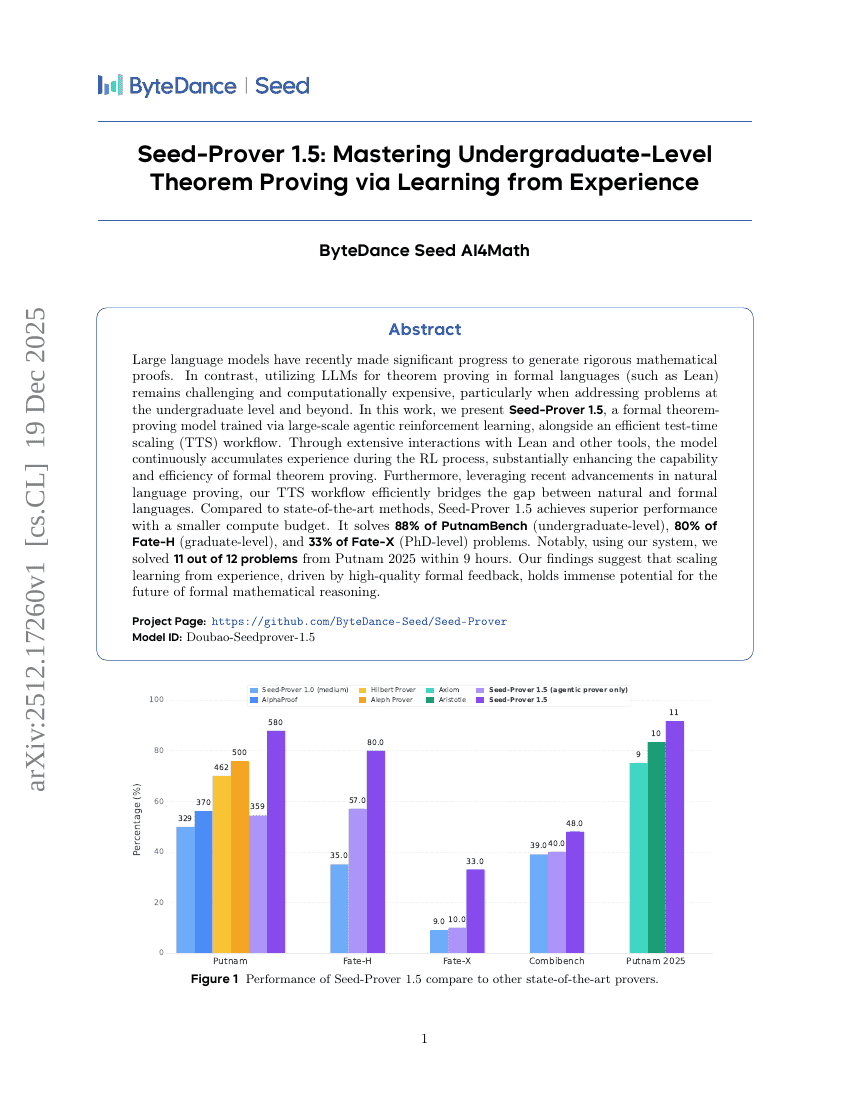
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
When Reasoning Meets Its Laws
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
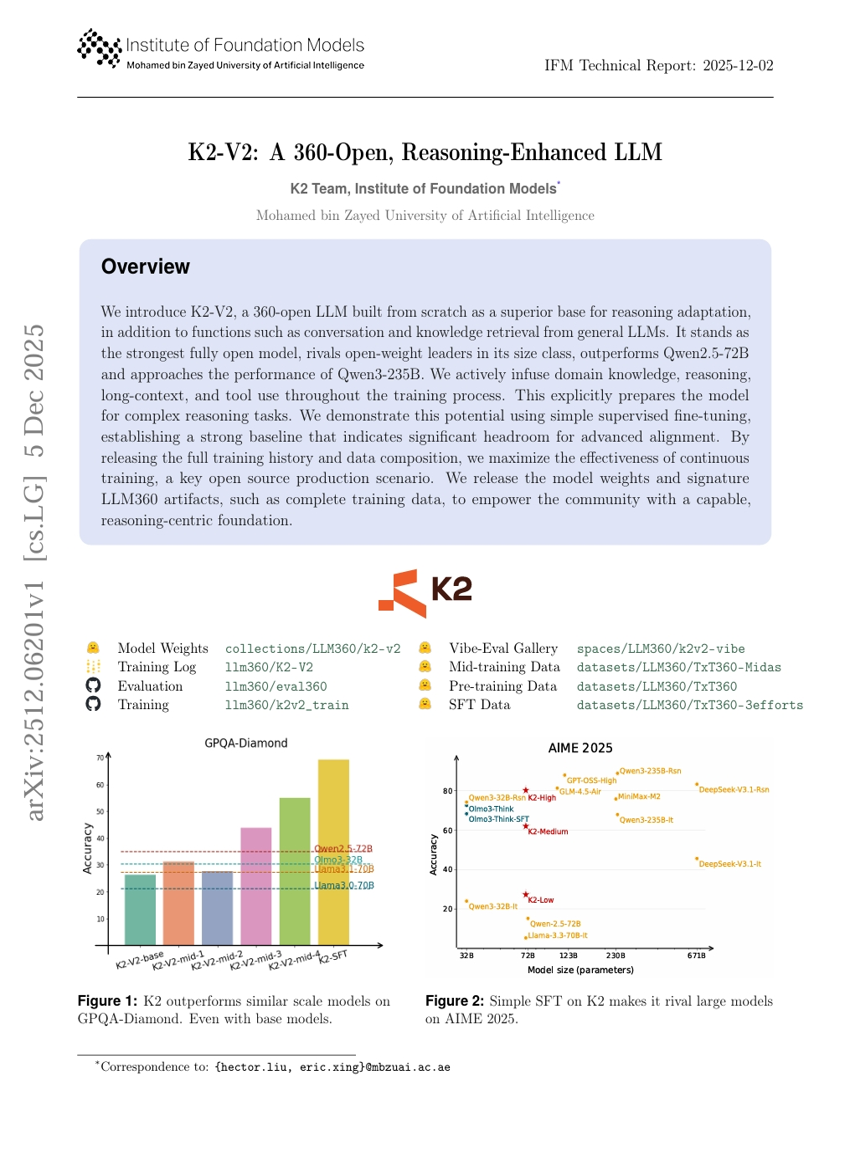
K2-V2: A 360-Open, Reasoning-Enhanced LLM
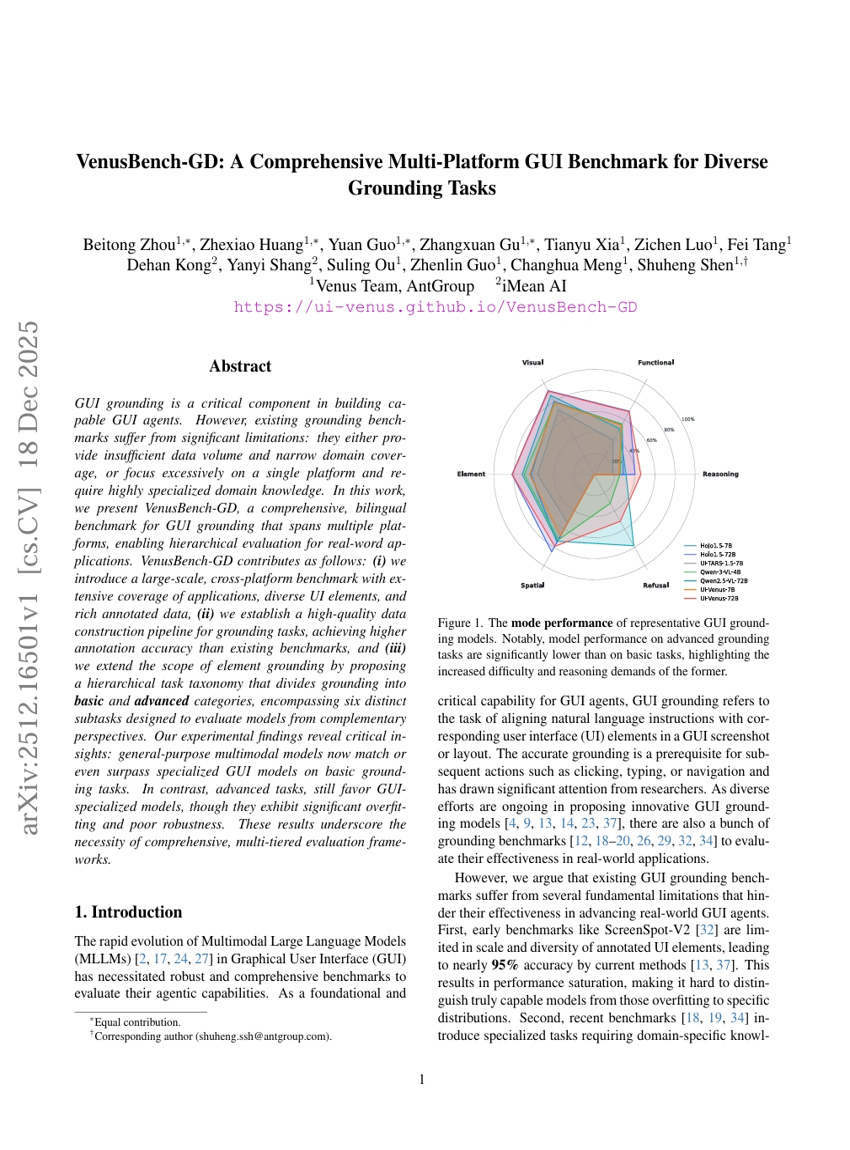
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
MCIF: Multimodal Crosslingual Instruction-Following Benchmark from Scientific Talks
NitroGen: An Open Foundation Model for Generalist Gaming Agents
H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
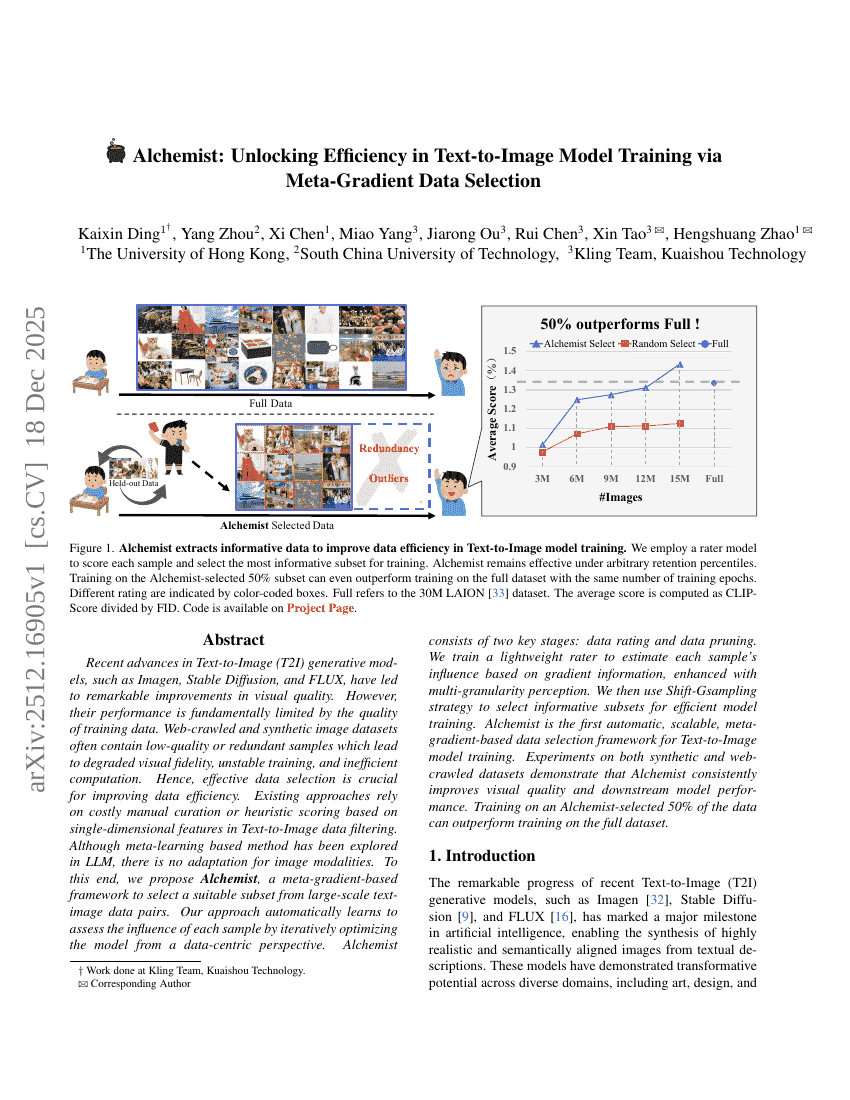
Alchemist: Unlocking Efficiency in Text-to-Image Model Training via Meta-Gradient Data Selection
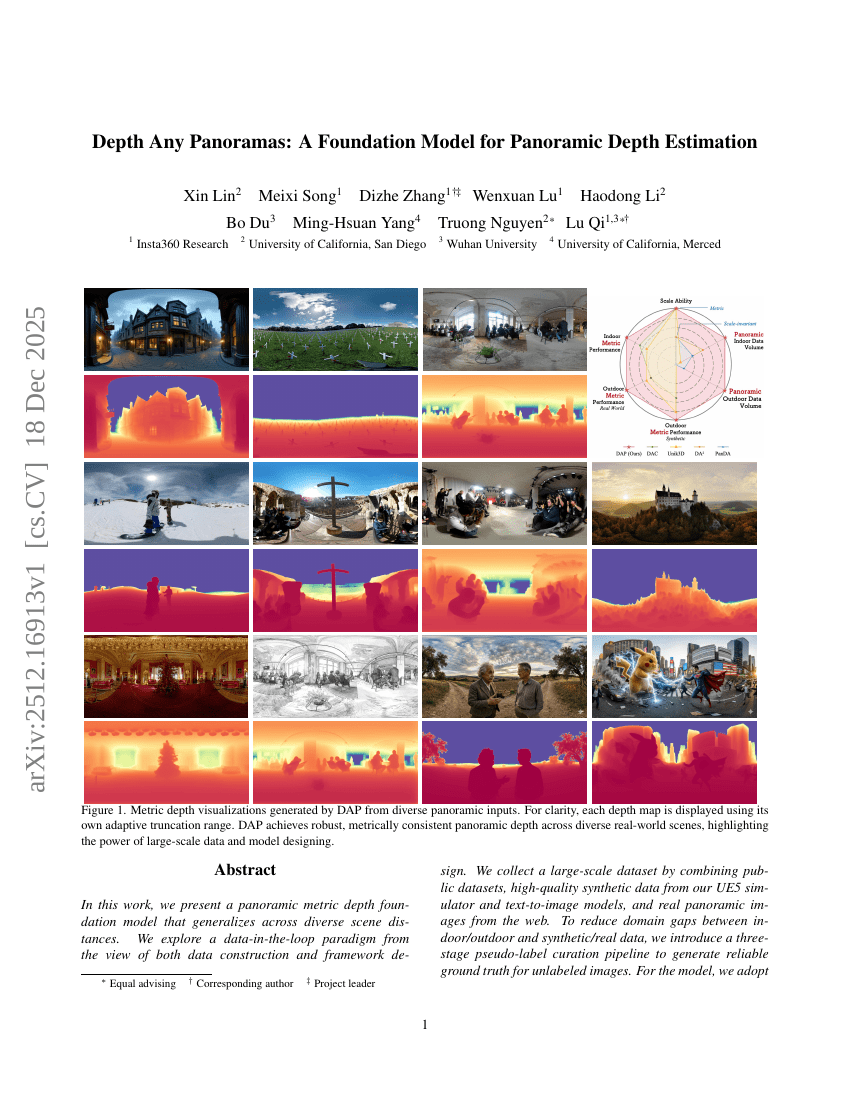
Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Generative Refocusing: Flexible Defocus Control from a Single Image
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Next-Embedding Prediction Makes Strong Vision Learners
Agent AI: Surveying the Horizons of Multimodal Interaction
AI Mathematician as a Partner in Advancing Mathematical Discovery -- A Case Study in Homogenization Theory
GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation
PrivateXR: Defending Privacy Attacks in Extended Reality Through Explainable AI-Guided Differential Privacy
Temporal Frictions and Judicial Outcomes: Analyzing the Impact of Time Delays on Criminal Sentencing in Cook County (2020-2024)
Meta-RL Induces Exploration in Language Agents
LLMCache: Layer-Wise Caching Strategies for Accelerated Reuse in Transformer Inference
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
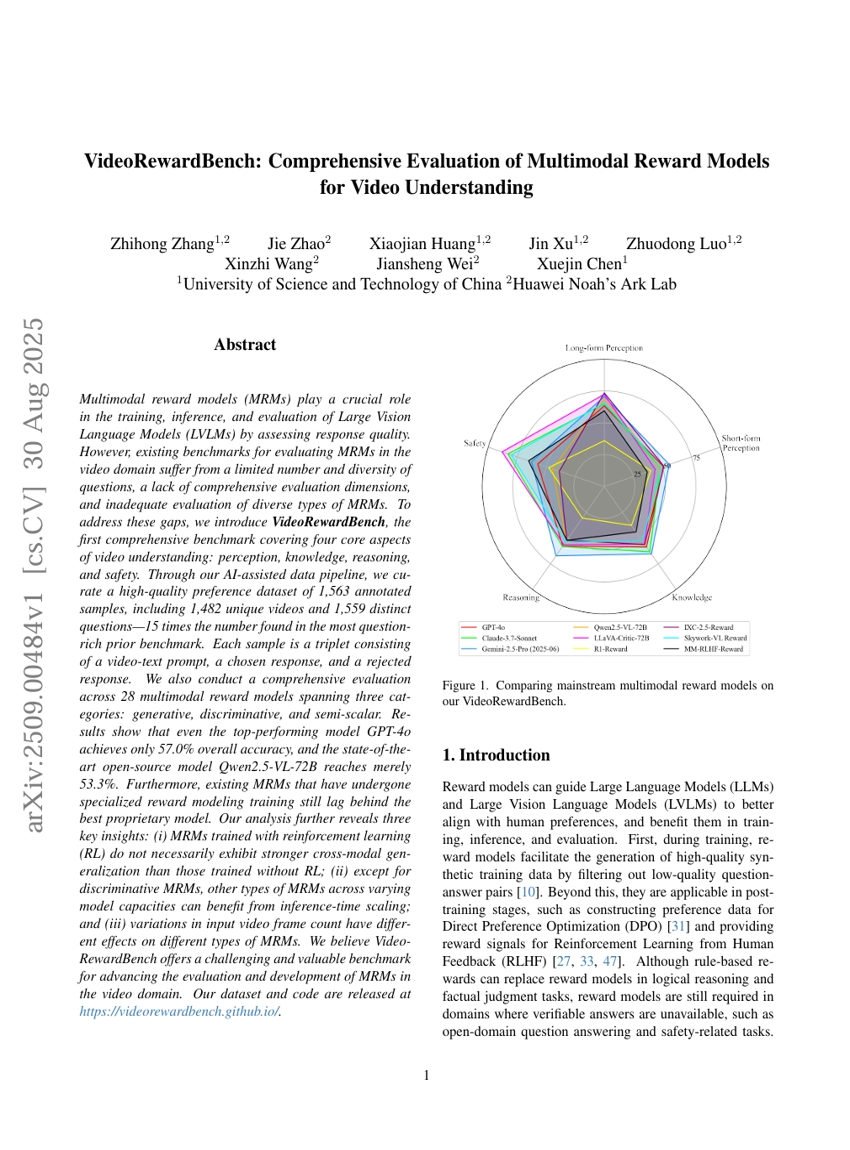
VideoRewardBench: Comprehensive Evaluation of Multimodal Reward Models for Video Understanding
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Med-Banana-50K: A Cross-modality Large-Scale Dataset for Text-guided Medical Image Editing
Kascade: A Practical Sparse Attention Method for Long-Context LLM Inference
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
When Reasoning Meets Its Laws
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
K2-V2: A 360-Open, Reasoning-Enhanced LLM
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
MCIF: Multimodal Crosslingual Instruction-Following Benchmark from Scientific Talks
NitroGen: An Open Foundation Model for Generalist Gaming Agents
H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs
The World is Your Canvas: Painting Promptable Events with Reference Images, Trajectories, and Text
Alchemist: Unlocking Efficiency in Text-to-Image Model Training via Meta-Gradient Data Selection
Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Generative Refocusing: Flexible Defocus Control from a Single Image
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Next-Embedding Prediction Makes Strong Vision Learners
Agent AI: Surveying the Horizons of Multimodal Interaction
AI Mathematician as a Partner in Advancing Mathematical Discovery -- A Case Study in Homogenization Theory
GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation
PrivateXR: Defending Privacy Attacks in Extended Reality Through Explainable AI-Guided Differential Privacy
Temporal Frictions and Judicial Outcomes: Analyzing the Impact of Time Delays on Criminal Sentencing in Cook County (2020-2024)
Meta-RL Induces Exploration in Language Agents
LLMCache: Layer-Wise Caching Strategies for Accelerated Reuse in Transformer Inference
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
VideoRewardBench: Comprehensive Evaluation of Multimodal Reward Models for Video Understanding
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation