HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Reasoning Models Generate Societies of Thought

A Large-Scale Study on the Development and Issues of Multi-Agent AI Systems
























Reasoning Models Generate Societies of Thought
A Large-Scale Study on the Development and Issues of Multi-Agent AI Systems
ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents
Your Group-Relative Advantage Is Biased
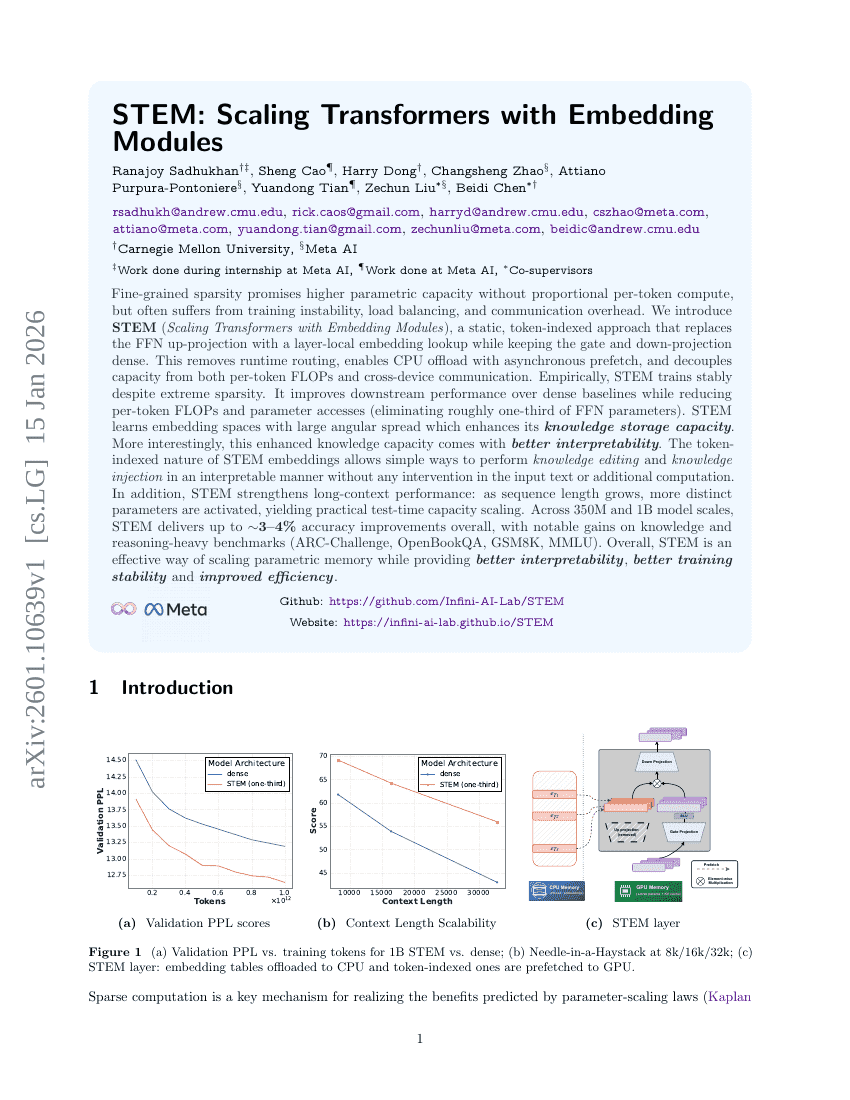
STEM: Scaling Transformers with Embedding Modules
Lost in the Noise: How Reasoning Models Fail with Contextual Distractors
Beyond Static Tools: Test-Time Tool Evolution for Scientific Reasoning
VIBE: Visual Instruction Based Editor
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs
Urban Socio-Semantic Segmentation with Vision-Language Reasoning
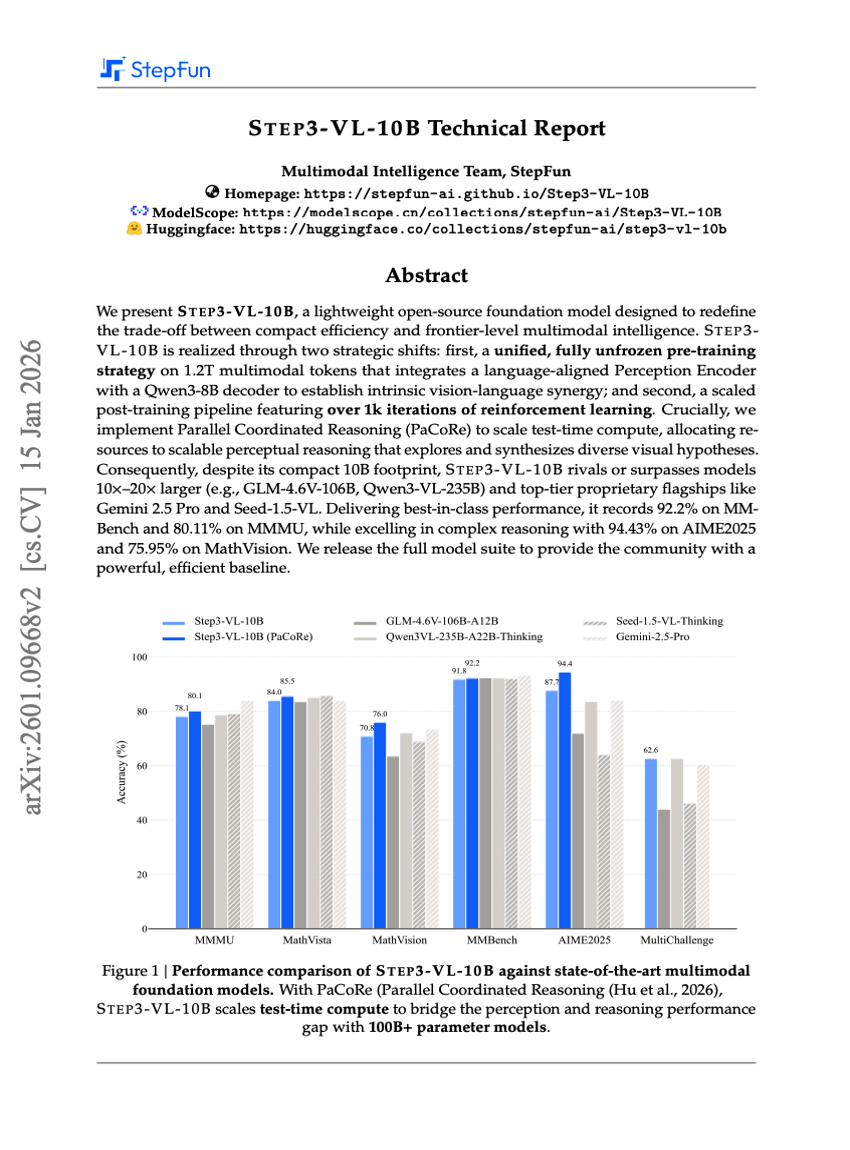
STEP3-VL-10B Technical Report
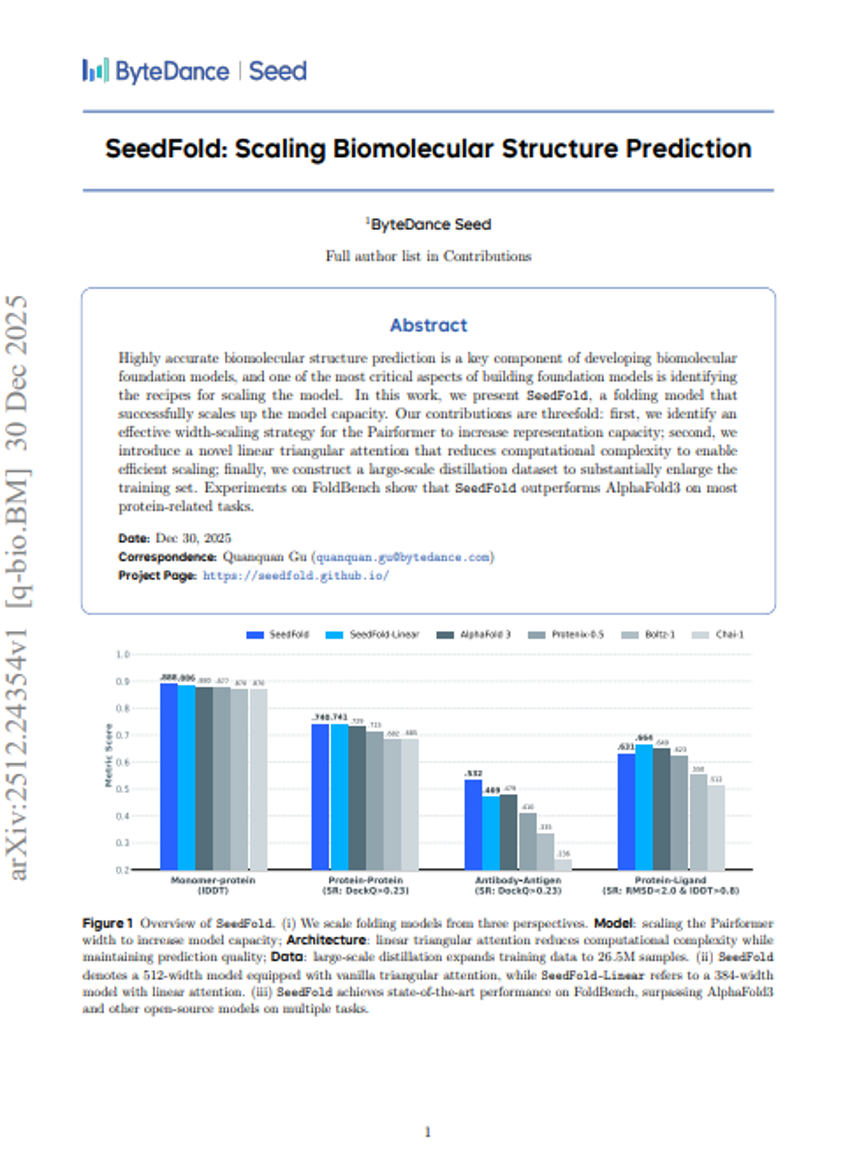
SeedFold: Scaling Biomolecular Structure Prediction
TranslateGemma Technical Report
Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
SkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
A^3-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation
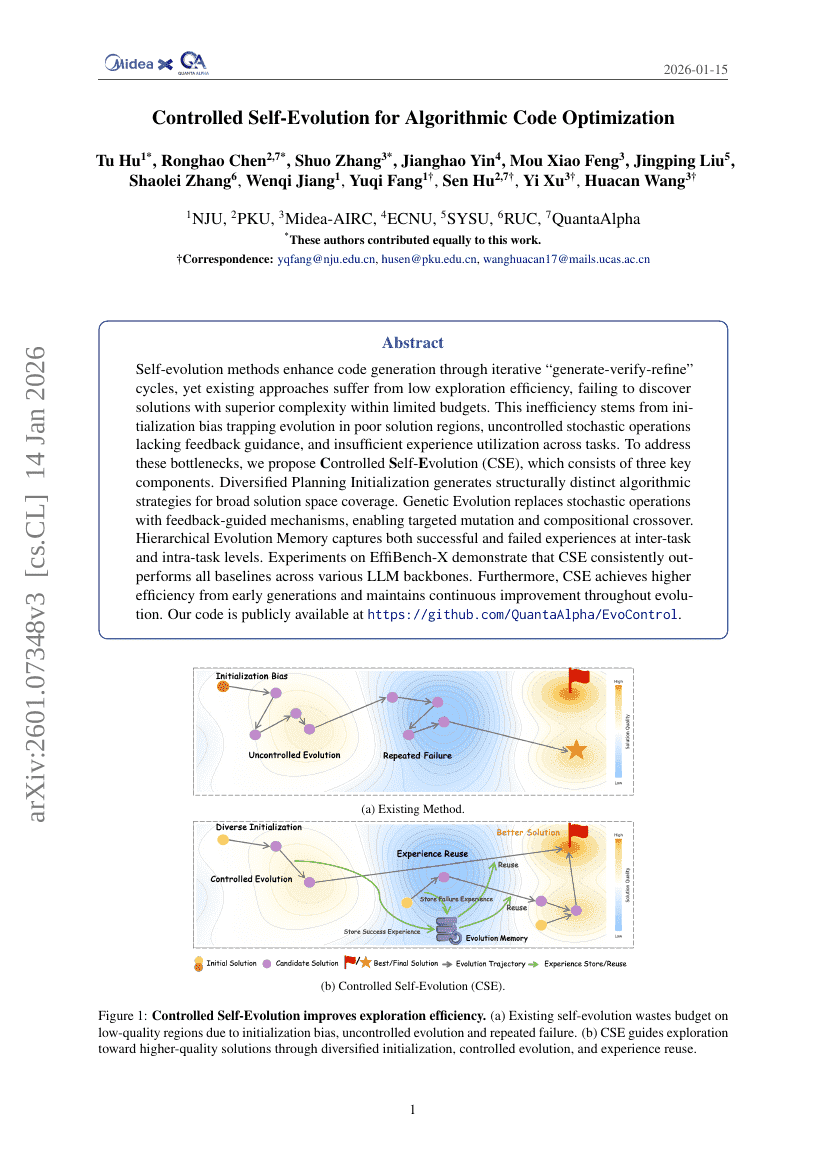
Controlled Self-Evolution for Algorithmic Code Optimization
MAXS: Meta-Adaptive Exploration with LLM Agents
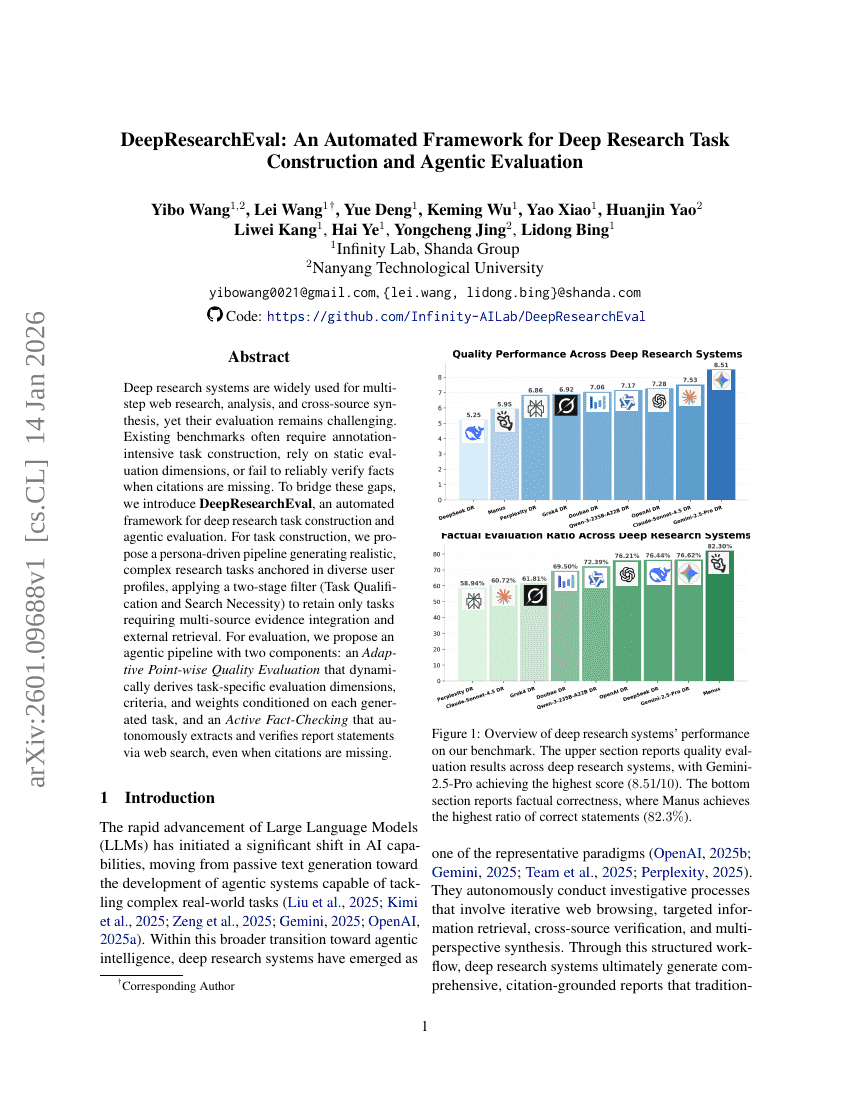
DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
The motivic class of the space of genus 0 maps to the flag variety
UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities
On the Non-decoupling of Supervised Fine-tuning and Reinforcement Learning in Post-training
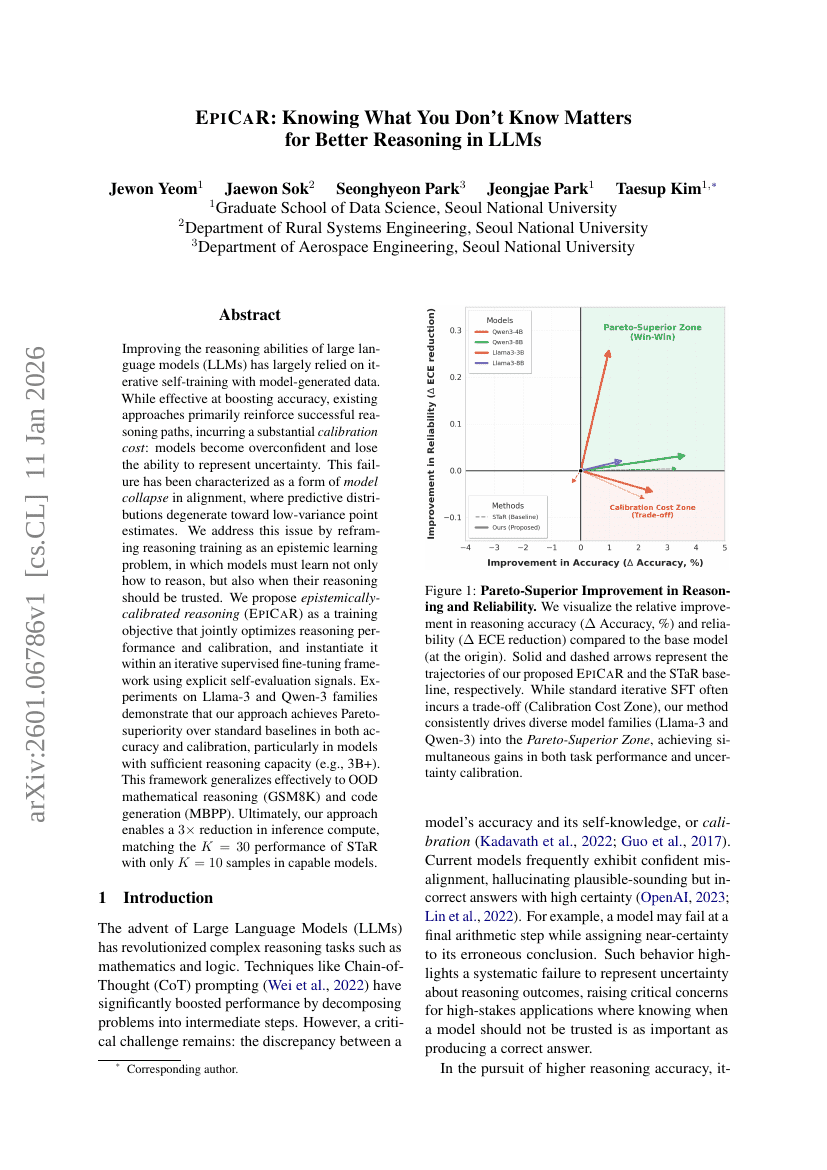
EpiCaR: Knowing What You Don't Know Matters for Better Reasoning in LLMs
Aligning Text, Code, and Vision: A Multi-Objective Reinforcement Learning Framework for Text-to-Visualization
How Do Large Language Models Learn Concepts During Continual Pre-Training?
JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents
Your Group-Relative Advantage Is Biased
STEM: Scaling Transformers with Embedding Modules
Lost in the Noise: How Reasoning Models Fail with Contextual Distractors
Beyond Static Tools: Test-Time Tool Evolution for Scientific Reasoning
VIBE: Visual Instruction Based Editor
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs
Urban Socio-Semantic Segmentation with Vision-Language Reasoning
STEP3-VL-10B Technical Report
SeedFold: Scaling Biomolecular Structure Prediction
TranslateGemma Technical Report
Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
SkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
A^3-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation
Controlled Self-Evolution for Algorithmic Code Optimization
MAXS: Meta-Adaptive Exploration with LLM Agents
DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
The motivic class of the space of genus 0 maps to the flag variety
UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities
On the Non-decoupling of Supervised Fine-tuning and Reinforcement Learning in Post-training
EpiCaR: Knowing What You Don't Know Matters for Better Reasoning in LLMs
Aligning Text, Code, and Vision: A Multi-Objective Reinforcement Learning Framework for Text-to-Visualization
How Do Large Language Models Learn Concepts During Continual Pre-Training?
JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices