Command Palette
Search for a command to run...
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Chulun Zhou Chunkang Zhang Guoxin Yu Fandong Meng Jie Zhou Wai Lam Mo Yu
Abstract
Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
One-sentence Summary
Researchers from The Chinese University of Hong Kong and WeChat AI introduce HGMEM, a hypergraph-based memory mechanism that enhances multi-step retrieval-augmented generation by dynamically modeling high-order correlations among facts. This approach evolves memory into an integrated knowledge structure, outperforming baselines in global sense-making tasks.
Key Contributions
- Multi-step RAG systems often rely on static working memory that passively stores isolated facts, failing to capture high-order correlations among information and leading to fragmented reasoning in long-context tasks.
- The authors introduce HGMEM, a hypergraph-based memory mechanism where hyperedges form dynamic, higher-order interactions, allowing memory to evolve into an integrated knowledge structure that guides subsequent reasoning steps.
- Experiments on challenging global sense-making datasets show HGMEM consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
Introduction
Multi-step RAG systems have evolved to use working memory for tracking reasoning, with some adopting graph structures to represent knowledge. However, these graph-based approaches are limited to modeling binary relationships between entities, which restricts their ability to capture complex, multi-way connections essential for deep, global reasoning. To address this, the authors introduce HGMEM, a novel hypergraph-based working memory mechanism. Their main contribution is a system that dynamically evolves its memory during query execution, enabling the flexible modeling of high-order, n-ary relationships to significantly enhance an LLM's reasoning capabilities.
Dataset
-
Dataset Composition and Sources: The authors evaluate their model on two task categories that require global comprehension over long contexts: generative sense-making question answering and long narrative understanding. For generative sense-making QA, they use a filtered subset of Longbench V2, retaining documents with over 100k tokens from Financial, Governmental, and Legal domains. For long narrative understanding, they leverage three public benchmarks: NarrativeQA, NoCha, and Prelude.
-
Key Details for Each Subset:
- Generative Sense-making QA: This subset is sourced from Longbench V2. The authors filter for single-document QA documents exceeding 100k tokens. They use GPT-4o to generate global sense-making queries for these documents, ensuring the queries require high-level understanding and reasoning across the entire context rather than focusing on specific phrases.
- Long Narrative Understanding: This data is drawn from three established benchmarks.
- NarrativeQA: The authors randomly sample 10 long books (over 100k tokens) and their associated queries from the benchmark.
- NoCha: They use the publicly released subset of this benchmark, which contains pairs of true and false claims about fictional books.
- Prelude: They use all English books included in this benchmark, which tests for consistency between a character's prequel and original story.
-
How the Paper Uses the Data: The paper uses this data for evaluation, not for training. The authors assess their model's performance on these tasks to demonstrate its ability to handle complex, multi-step retrieval and reasoning over long documents. The datasets are chosen specifically because they require models to synthesize information from disparate parts of a long context, which aligns with the paper's focus on complex relational modeling.
-
Processing and Other Details: The paper's core methodology assumes that documents are preprocessed into a graph structure before use. The document
Dis segmented into text chunks, and a graphGis constructed with nodes representing entities and edges representing relationships. Each node and edge is linked to its source text chunks, and all components (nodes, edges, and chunks) are embedded for vector-based retrieval. This allows the model to access both the raw text and a structured graph during its retrieval-augmented generation process.
Method
The authors leverage a multi-step retrieval-augmented generation (RAG) framework enhanced by a hypergraph-based memory mechanism, termed HGMEM, to support complex reasoning over long contexts. The overall system operates in iterative steps, where a large language model (LLM) interacts with external knowledge sources—comprising a document corpus D and a knowledge graph G—while maintaining and evolving a working memory M. At each step t, the LLM evaluates whether the current memory M(t) is sufficient to answer the target query q^. If not, it generates a set of subqueries Q(t) to guide further retrieval. These subqueries are used to fetch relevant entities from VG via vector-based similarity matching, as defined in Equation 1, and their associated relationships and text chunks are retrieved through graph-based indexing. The retrieved information is then consolidated into the memory, evolving it to M(t+1) via an LLM-driven process, as formalized in Equation 2.
Refer to the framework diagram, which illustrates the complete interaction loop at the t-th step. The LLM decides between local investigation and global exploration based on the current memory state. In local investigation, subqueries target specific memory points, and retrieval is confined to the neighborhood of the anchor vertices associated with those points. In global exploration, subqueries aim to discover new information outside the current memory scope, retrieving entities from the complement of VM(t) in VG. The retrieved entities, relationships, and text chunks are then fed back to the LLM for memory consolidation.
The memory M is structured as a hypergraph (VM,E~M), where vertices VM correspond to entities from VG, and hyperedges E~M represent memory points. Each vertex vi is represented as (Ωvient,Dvi), containing entity information and associated text chunks. Each hyperedge e~j is represented as (Ωe~jrel,Ve~j), where Ωe~jrel is a description of the relationship and Ve~j is the set of subordinate vertices. This structure enables the modeling of high-order correlations among multiple entities, surpassing the limitations of binary graph edges.
The dynamic evolution of memory involves three operations: update, insertion, and merging. The update operation revises the description of an existing hyperedge without altering its subordinate entities. The insertion operation adds new hyperedges to the memory when new, relevant information is retrieved. The merging operation combines two or more hyperedges into a single, more cohesive memory point, with the new description generated by the LLM based on the descriptions of the merged points and the target query, as shown in Equation 3. This process allows the memory to progressively form higher-order, semantically integrated knowledge structures.
As shown in the figure below, the memory evolves through these operations, transitioning from M(t) to M(t+1). The example illustrates an update to an existing memory point, the insertion of a new point, and the subsequent merging of two points into a unified, more comprehensive memory point. This evolution enables the system to capture complex relational patterns that are essential for global sense-making.

When the memory is deemed sufficient or the maximum interaction steps are reached, the LLM generates a final response. The response is produced using the descriptions of all memory points and the text chunks associated with all entities in the current memory. The prompts for memory evolving operations, including update, insertion, and merging, are designed to guide the LLM in extracting and organizing useful information, as shown in the provided prompt template. A toy example from the NarrativeQA dataset demonstrates the full workflow, where the memory evolves iteratively to refine understanding and support complex reasoning, ultimately leading to a coherent and contextually grounded response.

Experiment
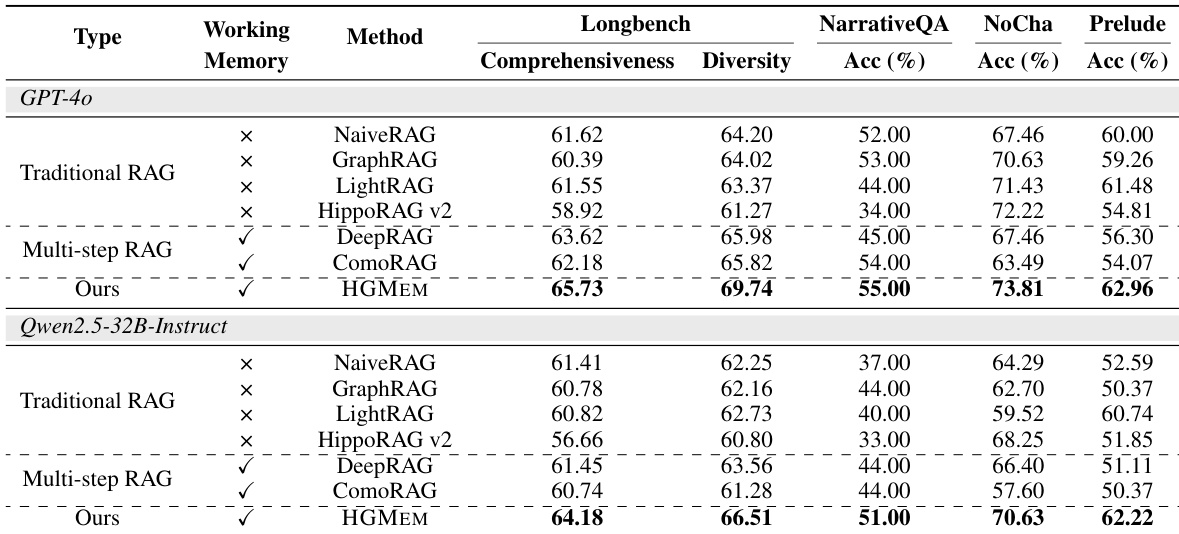
- The main experiments compare HGMEM to traditional and multi-step RAG baselines, including NaiveRAG, GraphRAG, LightRAG, HippoRAG v2, DeepRAG, and ComoRAG, validating its effectiveness across four benchmarks.
- On generative sense-making QA, HGMEM is evaluated using GPT-4o for Comprehensiveness and Diversity, while long narrative understanding tasks use prediction accuracy judged by GPT-4o.
- HGMEM consistently outperforms all comparison methods across all datasets.
- On long narrative understanding tasks, HGMEM achieves its best performance at step t=3, surpassing NaiveRAG and LightRAG across steps.
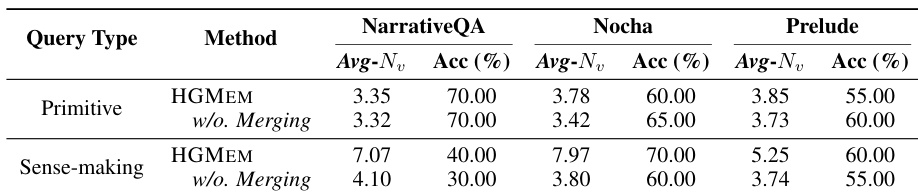
- A targeted analysis on primitive and sense-making queries shows that HGMEM achieves higher accuracy on sense-making queries by forming higher-order correlations, while maintaining comparable performance on primitive queries.
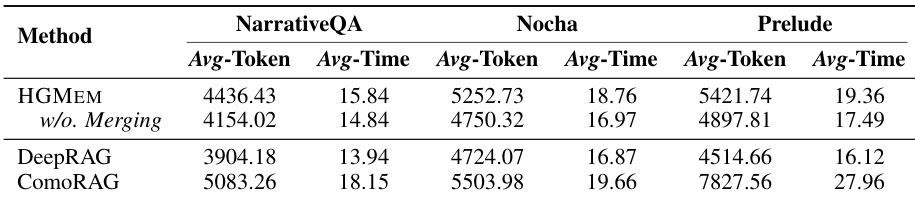
- The cost of HGMEM's online multi-step RAG execution is comparable to DeepRAG and ComoRAG, with the merging operation introducing only minor computational overhead.
- A case study demonstrates that HGMEM enables deeper and more accurate contextual understanding by forming high-order correlations and using adaptive memory-based evidence retrieval.
The authors compare their proposed HGMEM method against traditional and multi-step RAG baselines across four benchmarks using two LLMs: GPT-4o and Qwen2.5-32B-Instruct. Results show that HGMEM consistently achieves the highest scores in all metrics, including comprehensiveness, diversity, and accuracy, outperforming all baselines with and without working memory. The performance gains are particularly evident in complex tasks requiring deep reasoning, where HGMEM’s ability to form high-order correlations in memory leads to more accurate and comprehensive responses.
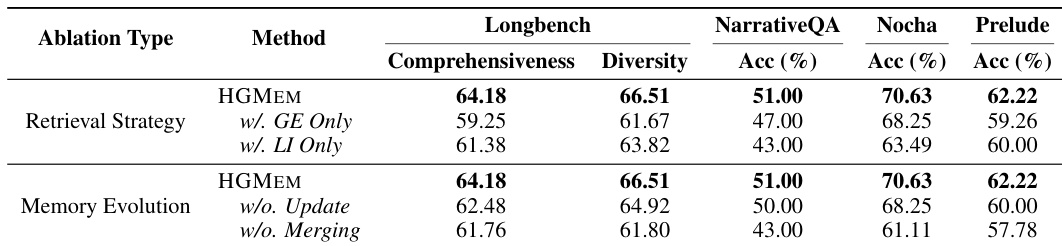
The authors use an ablation study to evaluate the impact of different components in their HGMEM framework, focusing on retrieval strategy and memory evolution. Results show that removing either the global evidence (GE) or local investigation (LI) retrieval strategies leads to significant performance drops across all benchmarks, while disabling memory update or merging operations also degrades performance, particularly on NarrativeQA and Prelude, indicating that both retrieval mechanisms and memory evolution are critical for HGMEM’s effectiveness.
The authors compare the computational cost of HGMEM with DeepRAG and ComoRAG, focusing on average token consumption and inference latency during online multi-step RAG execution. Results show that HGMEM’s cost is comparable to DeepRAG and ComoRAG across all three benchmarks, with only minor overhead from its merging operation, while consistently achieving superior performance.
The authors analyze the performance of HGMEM on primitive and sense-making queries across three datasets, measuring prediction accuracy and the average number of entities per hyperedge (Avg-Nv) as an indicator of relationship complexity. Results show that on sense-making queries, HGMEM achieves higher accuracy and significantly larger Avg-Nv compared to HGMEM without merging, indicating that forming high-order correlations improves comprehension for complex reasoning tasks. In contrast, for primitive queries, HGMEM yields comparable or slightly lower accuracy than the version without merging, likely due to redundant evidence association, while Avg-Nv remains slightly higher.