Command Palette
Search for a command to run...
Fish-Speech: Nutzung von Large Language Models für fortschrittliche multilinguale Text-to-Speech-Synthese
Fish-Speech: Nutzung von Large Language Models für fortschrittliche multilinguale Text-to-Speech-Synthese
Shijia Liao Yuxuan Wang Tianyu Li Yifan Cheng Ruoyi Zhang Rongzhi Zhou Yijin Xing
Zusammenfassung
Hier ist die professionelle Übersetzung des Textes ins Deutsche, unter Berücksichtigung der fachspezifischen Terminologie und des akademischen Stils:Text-to-Speech (TTS)-Systeme stehen weiterhin vor der Herausforderung, komplexe linguistische Merkmale zu verarbeiten, polyphone Ausdrücke zu handhaben und natürlich klingende, mehrsprachige Sprache zu erzeugen – Fähigkeiten, die für zukünftige KI-Anwendungen entscheidend sind. In diesem Paper präsentieren wir Fish-Speech, ein neuartiges Framework, das eine serielle Fast-Slow Dual Autoregressive (Dual-AR) Architektur implementiert, um die Stabilität der Grouped Finite Scalar Vector Quantization (GFSQ) bei Sequenzgenerierungsaufgaben zu verbessern. Diese Architektur steigert die Effizienz der Codebook-Verarbeitung bei gleichzeitiger Aufrechterhaltung einer High-Fidelity-Ausgabe, wodurch sie besonders effektiv für KI-Interaktionen und Voice Cloning ist. Fish-Speech nutzt Large Language Models (LLMs) zur Extraktion linguistischer Merkmale, wodurch die herkömmliche Graphem-zu-Phonem (G2P)-Konvertierung entfällt. Dies optimiert die Synthesis-Pipeline und verbessert die mehrsprachige Unterstützung. Zusätzlich haben wir FF-GAN mittels GFSQ entwickelt, um überlegene Kompressionsraten und eine Codebook-Ausnutzung von nahezu 100 % zu erreichen. Unser Ansatz adressiert zentrale Limitationen aktueller TTS-Systeme und schafft gleichzeitig die Grundlage für eine anspruchsvollere, kontextsensitive Sprachsynthese. Experimentelle Ergebnisse zeigen, dass Fish-Speech Baseline-Modelle bei der Handhabung komplexer linguistischer Szenarien sowie bei Voice-Cloning-Aufgaben signifikant übertrifft, was das Potenzial von Fish-Speech unterstreicht, die TTS-Technologie in KI-Anwendungen maßgeblich voranzutreiben.
One-sentence Summary
The authors propose Fish-Speech, a novel multilingual text-to-speech framework that utilizes a serial fast-slow Dual-AR architecture to enhance Grouped Finite Scalar Vector Quantization stability and leverages Large Language Models for linguistic feature extraction to eliminate traditional G2P conversion, achieving high-fidelity voice cloning and superior compression through FF-GAN.
Key Contributions
- The paper introduces Fish-Speech, a framework featuring a serial fast-slow Dual Autoregressive (Dual-AR) architecture designed to improve the stability of Grouped Finite Scalar Vector Quantization (GFSQ) during sequence generation.
- This work implements a non-grapheme-to-phoneme (non-G2P) structure that utilizes Large Language Models (LLMs) for linguistic feature extraction, which streamlines the synthesis pipeline and enhances multilingual support.
- The researchers developed FF-GAN through GFSQ to achieve superior compression ratios and near 100% codebook utilization, resulting in a system that outperforms baseline models in complex linguistic scenarios and voice cloning tasks.
Introduction
High-quality Text-to-Speech (TTS) systems are essential for advancing AI interactions, voice cloning, and multilingual virtual assistants. Traditional architectures often rely on grapheme-to-phoneme (G2P) conversion, which struggles with context-dependent polyphonic words and requires complex, language-specific phonetic rules that hinder scalability. Furthermore, many existing solutions must trade off semantic understanding for acoustic stability, which can limit their effectiveness in voice cloning. The authors leverage a novel Fish-Speech framework that utilizes Large Language Models (LLMs) for direct linguistic feature extraction, effectively eliminating the need for G2P conversion. Their main contribution is a serial fast-slow Dual Autoregressive (Dual-AR) architecture paired with a new Firefly-GAN (FFGAN) vocoder, which achieves high-fidelity synthesis, near 100% codebook utilization, and significantly lower latency than traditional DiT or Flow-based structures.
Dataset
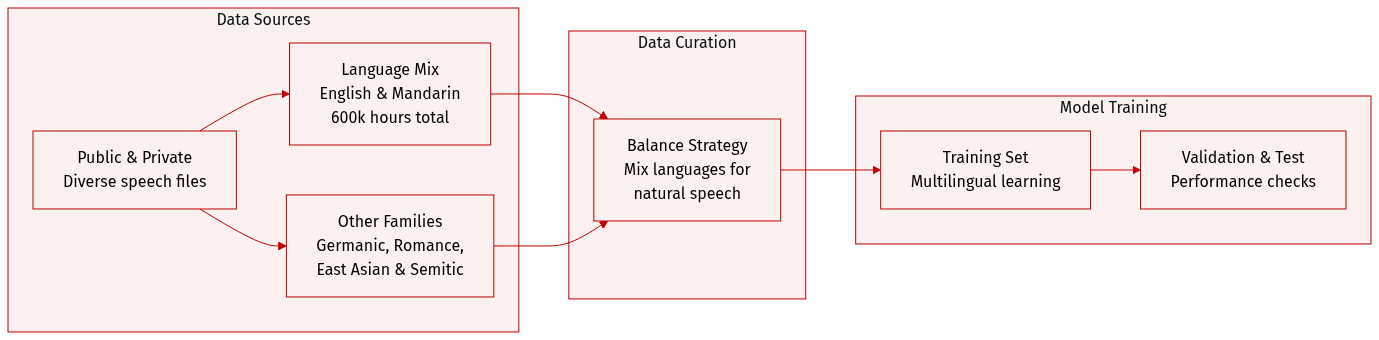
The authors constructed a massive multilingual speech dataset totaling approximately 720,000 hours, sourced from a combination of public repositories and proprietary data collection.
- Dataset Composition and Sources: The collection is built from diverse public sources and internal data collection processes to ensure high variety.
- Subset Details:
- English and Mandarin Chinese: These serve as the primary components, with 300,000 hours allocated to each language.
- Other Language Families: The authors included 20,000 hours each for Germanic (German), Romance (French, Italian), East Asian (Japanese, Korean), and Semitic (Arabic) language families.
- Data Processing and Strategy: The authors implemented a careful balancing strategy across different languages. This specific distribution is designed to facilitate simultaneous multilingual learning and improve the model's ability to generate natural mixed-language content.
Method
The Fish-Speech framework is designed as a high-performance Text-to-Speech (TTS) system capable of handling multi-emotional and multilingual speech synthesis. The authors leverage a hierarchical approach that combines a dual autoregressive architecture with an advanced vector quantization technique to ensure both stability and efficiency.
The core of the system is the Dual Autoregressive (Dual-AR) architecture, which processes speech information through two sequential transformer modules: the Slow Transformer and the Fast Transformer. As shown in the architectural overview of the Dual-AR framework:
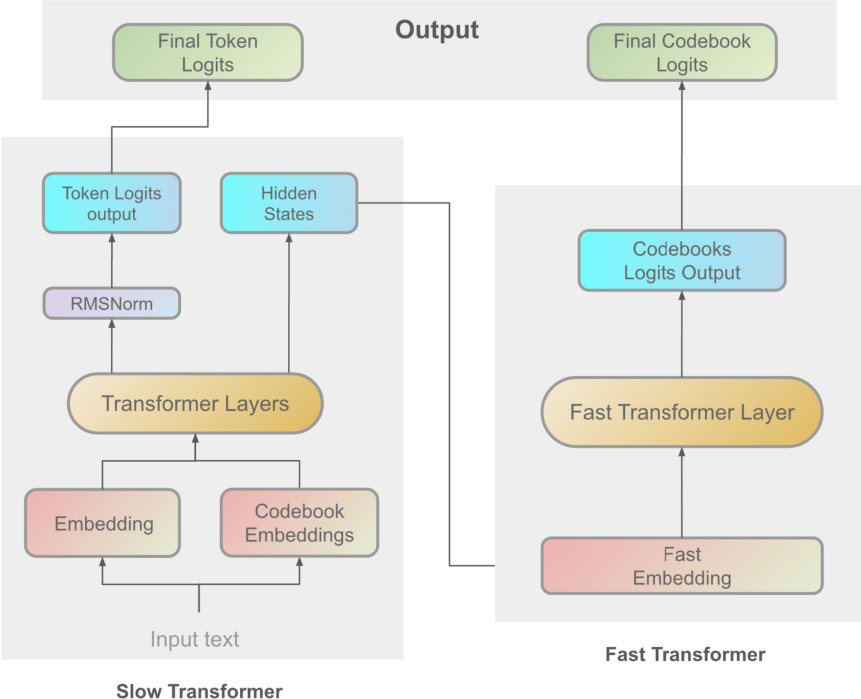
The Slow Transformer operates at a high level of abstraction, taking input text embeddings to capture global linguistic structures and semantic content. It generates intermediate hidden states h and predicts semantic token logits z via the following transformations:
h=SlowTransformer(x)z=Wtok⋅Norm(h)where Norm(⋅) represents layer normalization and Wtok denotes the learnable parameters of the token prediction layer. Following this, the Fast Transformer refines the output by processing detailed acoustic features. It takes a concatenated sequence of the hidden states h and codebook embeddings c as input:
h~=[h;c],(hfast)
hfast=FastTransformer(h~,(hfast))
y=Wcbk⋅Norm(hfast)
where Wcbk contains the learnable parameters for codebook prediction, and y represents the resulting codebook logits. This hierarchical design enhances sequence generation stability and optimizes codebook processing.
To facilitate efficient quantization, the authors introduce Grouped Finite Scalar Vector Quantization (GFSQ). This method divides the input feature matrix Z into G groups:
Z=[Z(1),Z(2),…,Z(G)]
Each scalar within a group undergoes quantization, and the resulting indices are used to decode the quantized vectors. The quantized vectors from all groups are then concatenated along the channel dimension to reconstruct the quantized downsampled tensor zqd:
zqd(b,:,l)=[zqd(1)(b,:,l);zqd(2)(b,:,l);…;zqd(G)(b,:,l)]
Finally, an upsampling function fup restores the tensor to its original size.
The speech synthesis is completed by the Firefly-GAN (FF-GAN) vocoder. This component improves upon traditional architectures by replacing the Multi-Receptive Field (MRF) module with a ParallelBlock, which utilizes a stack-and-average mechanism and configurable convolution kernel sizes. The internal structure of the FireFly Generator is illustrated below:
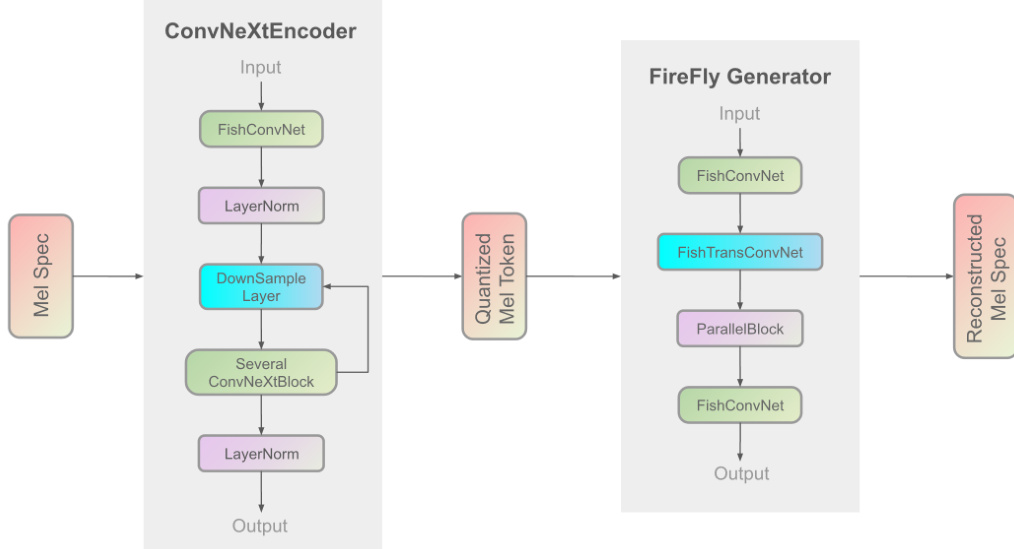
The overall training process follows a three-stage pipeline: initial pre-training on large-scale standard data, Supervised Fine-Tuning (SFT) on high-quality datasets, and Direct Preference Optimization (DPO) using manually labeled positive and negative sample pairs. The training infrastructure is divided into separate components for the AR model and the vocoder to optimize resource utilization.
Experiment
The evaluation framework utilizes objective metrics, subjective listening tests, and inference speed benchmarks to validate the model's performance in voice cloning and real-time processing. Results demonstrate that the GFSQ and typo-codebook strategies significantly enhance codebook utilization, speaker similarity, and content fidelity compared to baseline models. Ultimately, the system achieves high speech naturalness and efficient real-time inference, making it a robust architecture for high-quality speech synthesis and AI agent applications.
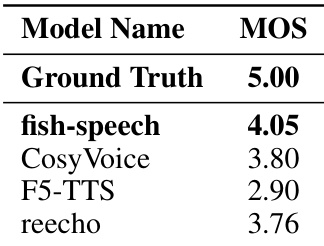
The authors conduct a subjective evaluation of synthesized audio quality using Mean Opinion Score (MOS) ratings. The results demonstrate that the proposed fish-speech model achieves higher perceptual quality scores compared to the tested baseline models. Fish-speech outperforms baseline models like CosyVoice, F5-TTS, and reecho in subjective quality ratings The proposed method shows superior performance in terms of speech naturalness and speaker similarity The results indicate that the model better captures and reproduces natural human speech characteristics
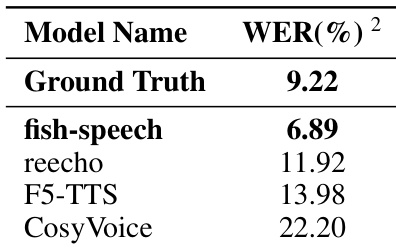
The authors evaluate the performance of the fish-speech model in voice cloning tasks by measuring the Word Error Rate. The results demonstrate that the proposed model achieves higher intelligibility compared to several baseline models. The fish-speech model achieves a lower word error rate than all listed baseline models The model's performance in terms of content fidelity even surpasses the ground truth recordings The proposed methodology shows a significant improvement in synthetic stability over competing models
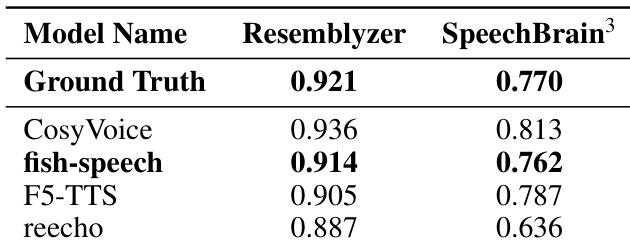
The authors evaluate speaker similarity across different models using Resemblyzer and SpeechBrain metrics. The results demonstrate that the proposed fish-speech model closely approximates the ground truth performance in both evaluation frameworks. The fish-speech model achieves speaker similarity scores that are remarkably close to the ground truth. The proposed method outperforms baseline models such as F5-TTS and reecho in capturing speaker characteristics. Consistent performance across both evaluation metrics validates the model's ability to preserve speaker identity.
The authors evaluate the Fish-Speech model through subjective quality assessments, voice cloning intelligibility tests, and speaker similarity measurements. The results demonstrate that the proposed model superiorly captures natural human speech characteristics and maintains high content fidelity compared to several baseline models. Furthermore, the model shows a remarkable ability to preserve speaker identity and provides enhanced synthetic stability across different evaluation frameworks.