Command Palette
Search for a command to run...
Schnelle NF4-Dequantization-Kernels für die Large Language Model Inferenz
Schnelle NF4-Dequantization-Kernels für die Large Language Model Inferenz
Xiangbo Qi Chaoyi Jiang Murali Annavaram
Zusammenfassung
Hier ist die professionelle Übersetzung des Textes ins Deutsche, unter Berücksichtigung der wissenschaftlichen Standards und Ihrer Vorgaben:Large Language Models (LLMs) haben die Speicherkapazität einzelner GPU-Geräte überschritten, was den Einsatz von Quantisierungstechniken für eine praktische Implementierung erforderlich macht. Während die NF4 (4-bit NormalFloat)-Quantisierung eine vierfache Reduzierung des Speicherbedarfs ermöglicht, erfordert die Inferenz auf aktuellen NVIDIA-GPUs (z. B. Ampere A100) eine kostspielige Dequantisierung zurück in das FP16-Format, was einen kritischen Leistungsengpass darstellt. In dieser Arbeit präsentieren wir eine leichtgewichtige Shared-Memory-Optimierung, die diese Lücke durch die gezielte Ausnutzung der Speicherhierarchie schließt und gleichzeitig die vollständige Kompatibilität mit dem bestehenden Ökosystem wahrt. Wir vergleichen unsere Technik mit der Open-Source-Implementierung von BitsAndBytes und erzielen bei drei Modellen (Gemma 27B, Qwen3 32B und Llama3.3 70B) eine Beschleunigung der Kernel um das 2,0- bis 2,2-fache sowie eine Verbesserung des End-to-End-Durchsatzes um bis zu das 1,54-fache. Dies wird durch die Nutzung des Latenzvorteils von Shared Memory gegenüber dem Global-Memory-Zugriff erzielt, der etwa das 12- bis 15-fache beträgt. Unsere Optimierung reduziert die Anzahl der Instruktionen durch eine vereinfachte Indexierungslogik, während pro Thread-Block lediglich 64 Bytes an Shared Memory verwendet werden. Dies demonstriert, dass leichtgewichtige Optimierungen mit minimalem Engineering-Aufwand erhebliche Leistungssteigerungen bewirken können. Diese Arbeit bietet eine Plug-and-Play-Lösung für das HuggingFace-Ökosystem, welche den Zugang zu fortgeschrittenen Modellen auf bestehender GPU-Infrastruktur demokratisiert.
One-sentence Summary
By utilizing a lightweight shared memory optimization to replace expensive global memory access, this method achieves up to 2.2x kernel speedup and 1.54x end-to-end improvement across the Gemma 27B, Qwen3 32B, and Llama3.3 70B models while maintaining full compatibility with the HuggingFace ecosystem.
Key Contributions
- The paper introduces a lightweight shared memory optimization that exploits the memory hierarchy of the Ampere architecture to address dequantization bottlenecks in NF4 quantized models.
- This method transforms redundant per-thread global memory accesses into efficient per-block loading, reducing lookup table traffic by 64x per thread block and simplifying indexing logic to reduce instruction counts by 71%.
- Experimental evaluations on Gemma 27B, Qwen3 32B, and Llama3.3 70B demonstrate 2.0 to 2.2x kernel speedups and up to 1.54x end-to-end performance improvements while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Introduction
As large language models grow beyond the memory capacity of single GPUs, NF4 quantization has become essential for reducing memory footprints by 4x. However, because current NVIDIA Ampere architectures lack native 4-bit compute support, weights must be dequantized to FP16 during every matrix multiplication. This process creates a major performance bottleneck, with dequantization accounting for up to 40% of end-to-end latency due to redundant and expensive global memory accesses. The authors leverage a lightweight shared memory optimization to address this inefficiency by transforming per-thread global memory loads into efficient per-block loads. This approach exploits the significant latency advantage of on-chip memory to achieve a 2.0 to 2.2x kernel speedup while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Experiment
The evaluation uses a single NVIDIA A100 GPU to test optimized NF4 dequantization kernels against baseline implementations across three models: Gemma 27B, Qwen3 32B, and Llama3.3 70B. The experiments validate that the original dequantization process creates a significant bottleneck due to high memory overhead and warp divergence caused by complex tree-based decoding. Results demonstrate that the shared memory optimization consistently accelerates kernel execution, leading to substantial end-to-end latency and throughput improvements that are particularly pronounced in larger models.
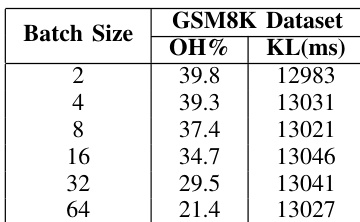
The authors analyze the dequantization overhead and kernel latency for the Qwen3-32B model using the GSM8K dataset. The results show that dequantization remains a significant portion of total inference time across various batch sizes. Dequantization overhead percentage decreases as the batch size increases Kernel latency remains relatively consistent regardless of the batch size The dequantization process represents a substantial bottleneck in end-to-end inference
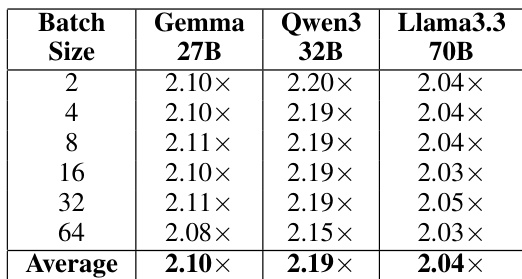
The authors evaluate the kernel-level speedup of their optimized NF4 dequantization implementation across different model architectures and batch sizes. Results show that the optimization provides consistent performance gains regardless of the specific model or workload scale. The optimization achieves a consistent speedup across all tested models and batch sizes. Larger models and different batch configurations all experience similar levels of kernel-level improvement. The performance gains remain stable across varying batch sizes from small to large workloads.
The authors evaluate dequantization overhead and the effectiveness of an optimized NF4 implementation using the Qwen3-32B model and various architectures. While dequantization is identified as a significant bottleneck in end-to-end inference, the optimized kernel provides consistent performance gains across different models and batch sizes. These results demonstrate that the optimization maintains stable speedups regardless of the specific workload scale or model architecture.