Command Palette
Search for a command to run...
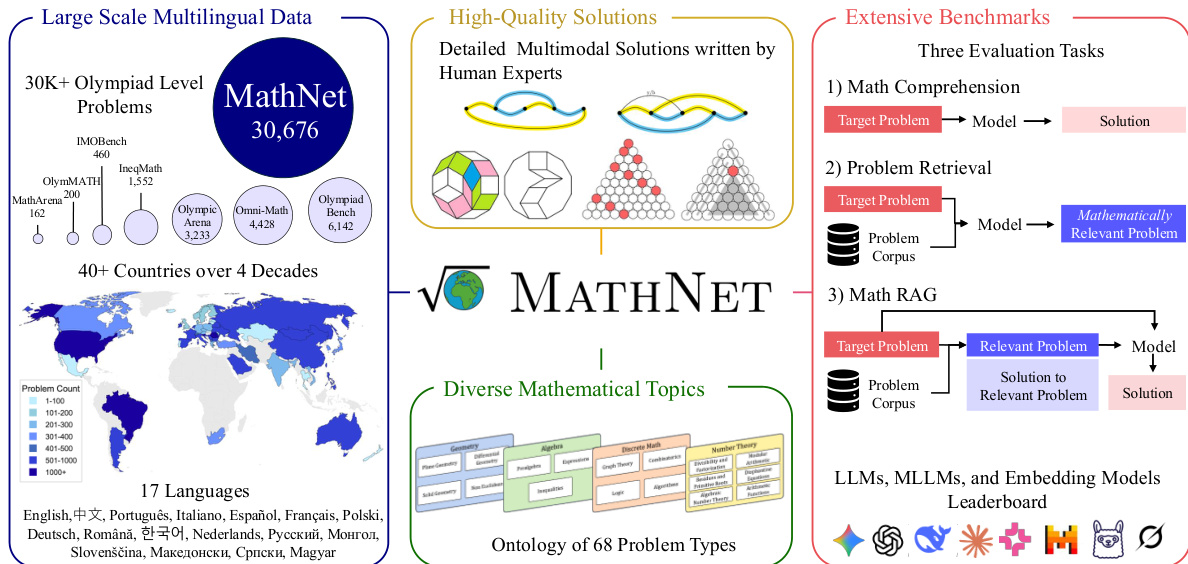
MathNet: Ein globaler Multimodal-Benchmark für mathematisches Reasoning und Retrieval
MathNet: Ein globaler Multimodal-Benchmark für mathematisches Reasoning und Retrieval
Shaden Alshammari Kevin Wen Abrar Zainal Mark Hamilton Navid Safaei Sultan Albarakati William T. Freeman Antonio Torralba
Zusammenfassung
Die Lösung mathematischer Probleme bleibt für Large Language Models (LLMs) und multimodale Modelle ein anspruchsvoller Prüfstein für deren Schlussfolgerungsvermögen. Bestehende Benchmarks sind jedoch in Bezug auf Umfang, Sprachabdeckung und Aufgabenvielfalt begrenzt. Wir stellen MATHNET vor, einen hochwertigen, umfangreichen, multimodalen und mehrsprachigen Datensatz mit Olympiade-Niveau-Mathematikaufgaben sowie einen Benchmark zur Bewertung der mathematischen Schlussfolgerungsfähigkeit generativer Modelle und der mathematischen Informationsretrieval-Leistung einbettungsbasierter Systeme. MATHNET deckt 47 Länder, 17 Sprachen und zwei Jahrzehnte von Wettbewerben ab und umfasst 30.676 von Experten erstellte Aufgaben mit Lösungen aus diversen Fachgebieten. Neben dem Kerndatensatz konstituieren wir einen Retrieval-Benchmark, der aus mathematisch äquivalenten und strukturell ähnlichen Aufgabenpaaren besteht, die von menschlichen Experten kuratiert wurden. MATHNET unterstützt drei Aufgabenstellungen: (i) Problemlösung, (ii) Mathematikbewusstes Retrieval und (iii) retrievalvergrößerte Problemlösung (Retrieval-Augmented Problem Solving). Experimentelle Ergebnisse zeigen, dass selbst modernste Reasoning-Modelle (78,4 % für Gemini-3.1-Pro und 69,3 % für GPT-5) weiterhin vor Herausforderungen stehen, während Embedding-Modelle Schwierigkeiten haben, äquivalente Aufgaben zu finden. Wir zeigen weiterhin, dass die RAG-Leistung (Retrieval-Augmented Generation) stark von der Retrieval-Qualität abhängt; so erzielt DeepSeek-V3.2-Speciale Verbesserungen von bis zu 12 % und erreicht auf dem Benchmark die höchsten Scores.
One-sentence Summary
The authors introduce MATHNET, a global multimodal benchmark comprising 30,676 expert-authored Olympiad-level problems across 17 languages, 47 countries, and two decades of competitions to evaluate mathematical reasoning and retrieval via human-curated mathematically equivalent and structurally similar problem pairs, revealing that state-of-the-art models like Gemini-3.1-Pro and GPT-5 achieve 78.4% and 69.3% respectively while RAG performance is highly sensitive to retrieval quality as demonstrated by DeepSeek-V3.2-Speciale achieving gains of up to 12%.
Key Contributions
- The paper introduces MATHNET, a large-scale multimodal and multilingual dataset containing 30,676 expert-authored Olympiad-level math problems across 47 countries and 17 languages. This resource addresses limitations in existing benchmarks by covering two decades of competitions and diverse mathematical domains.
- A retrieval benchmark is constructed alongside the core dataset using human-curated pairs of mathematically equivalent and structurally similar problems. This framework supports three evaluation tasks including problem solving, math-aware retrieval, and retrieval-augmented problem solving.
- Experimental results show that state-of-the-art reasoning models remain challenged by the benchmark, with top performers achieving scores around 78.4 percent. The study further demonstrates that retrieval-augmented generation performance is highly sensitive to retrieval quality, yielding gains of up to 12 percent for specific models.
Introduction
Robust mathematical reasoning is essential for advancing artificial intelligence, yet current evaluation standards often lack global diversity and multimodal depth. Existing benchmarks frequently rely on limited language sets or competition types, which hinders the assessment of model performance across varied educational contexts. To address this gap, the authors present MathNet, a comprehensive global multimodal benchmark featuring over 30,000 problems from Olympiad competitions. This dataset spans 143 competitions from 47 countries and 17 languages over 40 years with expert solutions to facilitate rigorous testing of problem solving and math retrieval capabilities.
Dataset
The authors introduce MATHNET, a high-quality multimodal and multilingual dataset designed to evaluate mathematical reasoning and retrieval in generative models.
Dataset Composition and Sources
- The core corpus, MathNet-Solve, contains 30,676 expert-authored Olympiad-level problems with solutions.
- Data originates from 1,595 official PDF volumes spanning 47 countries from 1985 to 2025, covering 17 languages and 143 competitions.
- Unlike prior benchmarks, the authors exclude community-sourced platforms to ensure expert-level quality and consistency.
Subset Details
- MathNet-Solve: Divided into a training split of 23,776 samples, a test split of 6,400 samples, and a hard test split of 500 samples.
- MathNet-Retrieve: Built from 10,000 anchor problems from the core set. Each anchor pairs with 1 mathematically equivalent positive and 3 hard negatives generated by GPT-5, totaling 40,000 synthetic problems.
- MathNet-RAG: Consists of 70 real problems organized into 35 expert-curated pairs exhibiting structural resonance, used for retrieval-augmented problem solving.
Processing and Annotation
- The authors convert source booklets to Markdown using the dots-ocr framework to handle diverse formats including scanned documents.
- A novel LLM-based pipeline segments documents and aligns problem-solution pairs using Gemini-2.5-Flash and GPT-4.1.
- Metadata construction includes recording problem authors, hints, remarks, and provenance information such as source file and page numbers.
- Verification involves a three-stage process combining rule-based analytical checks, GPT-4.1 screenshot comparison, and manual human review for low-confidence cases.
Model Usage
- Generative models are trained on the MathNet-Solve training split and evaluated on the test splits for problem solving accuracy.
- Embedding models are evaluated on MathNet-Retrieve using Recall@k to assess math-aware retrieval capabilities.
- Retrieval-augmented generation systems are tested on MathNet-RAG to measure performance gains from retrieving structurally similar problems.
Method
The authors introduce MathNet, a framework designed to support large-scale multilingual mathematical reasoning through a structured ecosystem of data, solutions, and benchmarks. As shown in the overview diagram, the system integrates over 30,000 Olympiad-level problems sourced from more than 40 countries across four decades.
To ensure the integrity of this large-scale dataset, the authors employ a multi-stage processing pipeline. Refer to the framework diagram below for the specific workflow.
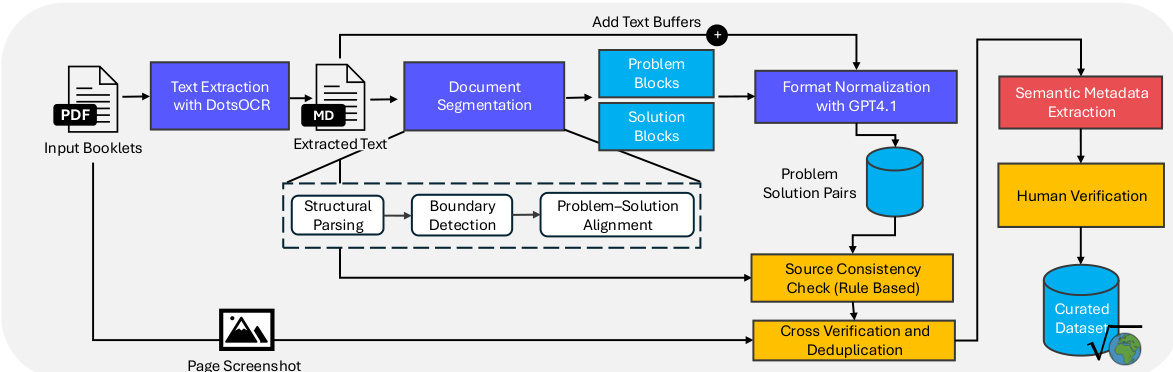
Input booklets in PDF format are first processed via text extraction using DotsOCR. The extracted text undergoes document segmentation to separate problem and solution blocks. A structural parsing module performs boundary detection and aligns problems with their corresponding solutions. Subsequent format normalization is handled by GPT-4.1. The pipeline includes robust quality control measures such as source consistency checks, cross-verification, deduplication, and semantic metadata extraction, culminating in human verification to produce the final curated dataset. The semantic metadata extraction module categorizes problem relationships using a taxonomy that distinguishes three modes of similarity: Invariance, which refers to strict equivalence under transformation; Resonance, indicating partial similarity in proof strategy; and Affinity, denoting broad thematic relatedness.
The dataset encompasses diverse mathematical topics organized into an ontology of 68 problem types, including geometry, algebra, discrete math, and number theory. It features detailed multimodal solutions written by human experts. The following figures provide examples of the geometric problems contained within the dataset.
The framework supports extensive benchmarks that evaluate three specific tasks: math comprehension, problem retrieval, and math RAG. These evaluations utilize LLMs, MLLMs, and embedding models to assess performance across the collected data.
Experiment
The evaluation assesses 27 models across three benchmarks covering problem solving, math-aware retrieval, and retrieval-augmented problem solving. Frontier reasoning models achieve high accuracy in algebra but struggle with geometry and discrete mathematics, indicating that Olympiad-level reasoning remains challenging even for state-of-the-art systems. Furthermore, retrieval performance is limited by the inability of embedding models to capture deep structural relationships, which causes inconsistent gains in retrieval-augmented settings unless expert-paired context is utilized.
The experiment evaluates problem-solving accuracy across four mathematical domains using various large language and multimodal models. Results demonstrate that models with explicit reasoning capabilities consistently outperform those without, particularly in the LMM with reasoning category. Performance trends indicate that Algebra is the most accessible domain, whereas Geometry and Discrete Mathematics remain significantly more difficult for all systems. LMMs with reasoning achieve the highest overall accuracy, led by the gemini-3.1-pro-preview model. Algebra consistently yields higher success rates compared to Geometry and Discrete Mathematics across all model groups. A substantial performance gap exists between frontier reasoning models and smaller or non-reasoning baselines.
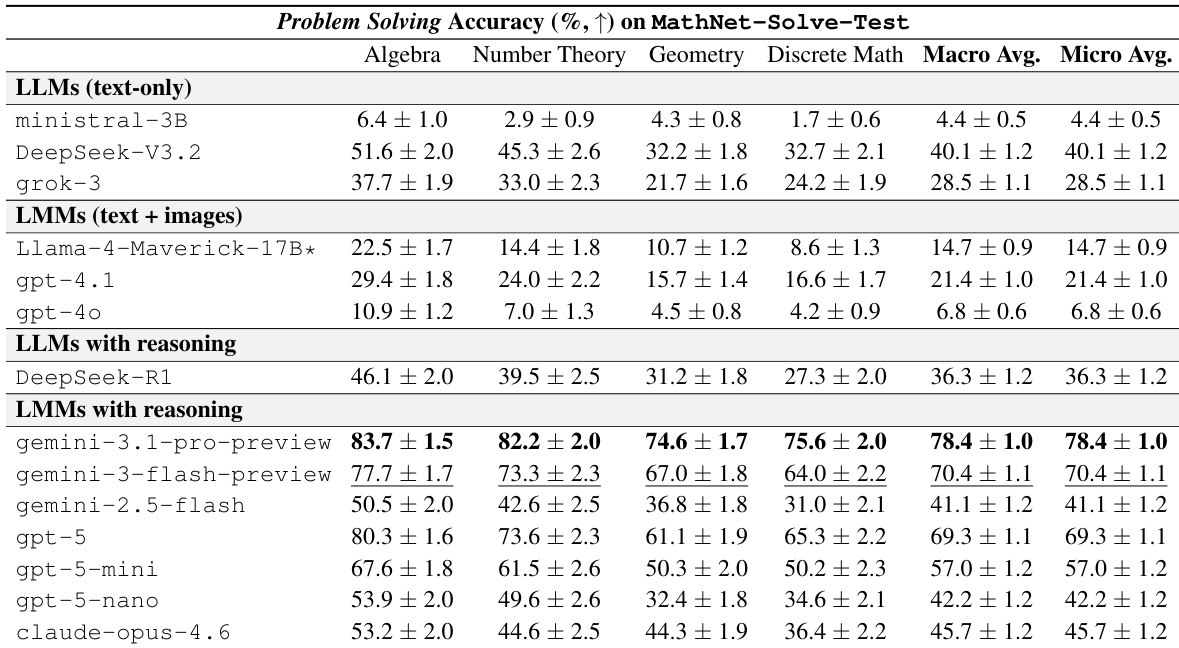
The the the table compares model accuracy on MathNet-RAG across Zero-shot, Embed-RAG, and Expert-RAG settings using both LLM and human grading. Expert-RAG generally provides the strongest performance, particularly for top-tier models, while Embed-RAG yields inconsistent gains compared to the Zero-shot baseline. Expert-RAG generally yields the best performance for top-tier models like DeepSeek-V3.2-Speciale and GPT-5, surpassing both Zero-shot and Embed-RAG settings. Embed-RAG shows inconsistent benefits and can result in lower accuracy than Zero-shot for certain models like Grok-4.1-fast and olmo-3-32b-think. Human Expert and LLM Grading results align in identifying Expert-RAG as the superior setting for most models, despite some variations in absolute scores.
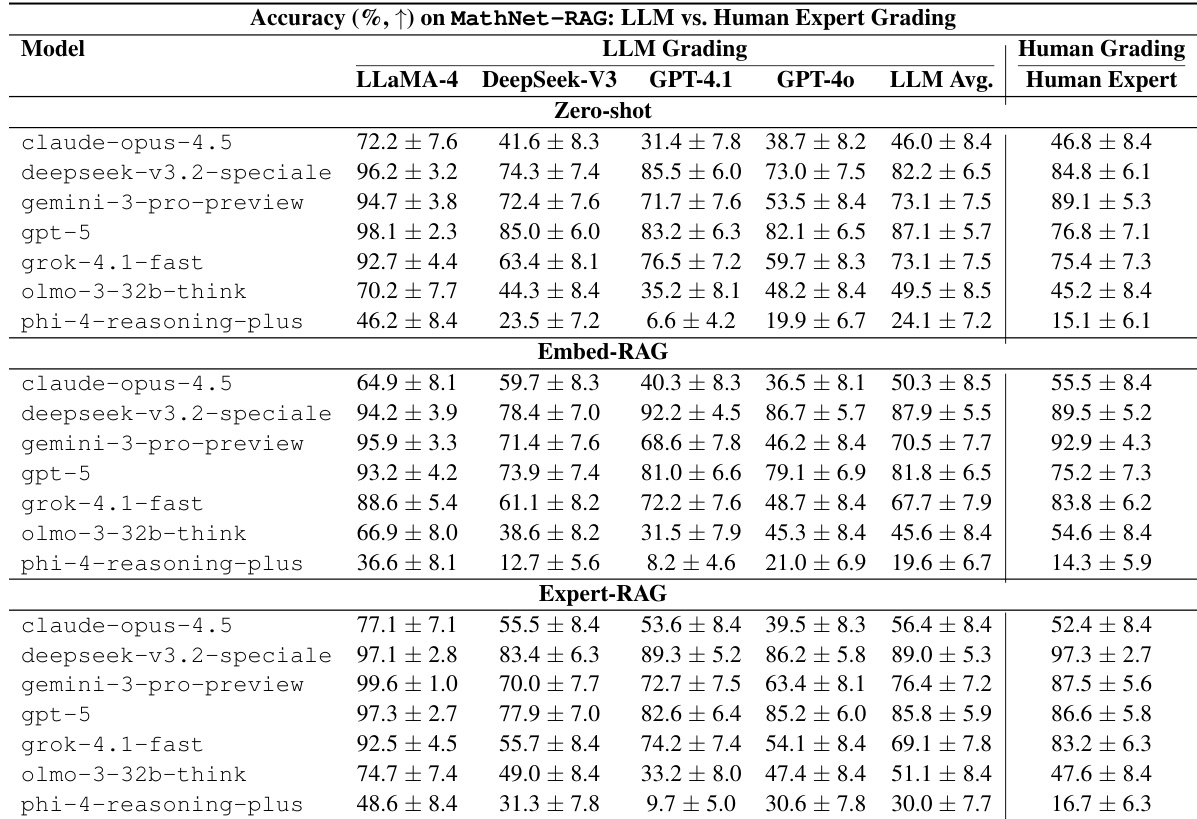
The authors evaluate a diverse set of large language and multimodal models on the MathNet-Solve-Test benchmark to assess problem-solving accuracy. Results demonstrate a clear performance stratification where frontier reasoning models substantially outperform mid-tier and weaker baselines. Additionally, the data indicates that providing multimodal inputs generally enhances accuracy for the top-performing systems compared to text-only inputs. Frontier reasoning models achieve significantly higher accuracy than smaller or earlier model families. Multimodal inputs consistently yield better results than text-only inputs for the top-ranked models. A substantial performance gap exists between the highest and lowest scoring models in the evaluation.
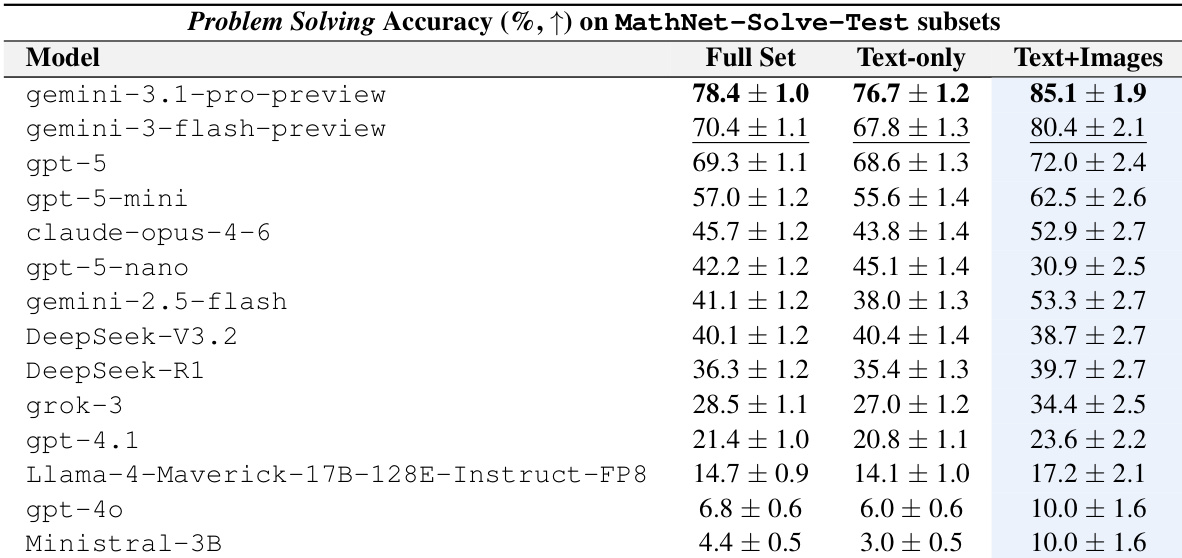
The authors evaluate retrieval-augmented problem solving on the MathNet-RAG benchmark using three inference settings: Zero Shot, Embed-RAG, and Expert-RAG. Results indicate that Expert-RAG generally provides the strongest performance, particularly under human grading, though improvements are not uniform across all models. While some models benefit significantly from expert-retrieved context, others show mixed results or perform better with standard zero-shot prompting. Expert-RAG generally achieves the best performance, with DeepSeek-V3.2-Speciale reaching the top result under human grading. GPT-5 demonstrates substantial performance gains when switching from Zero Shot to Expert-RAG. Embed-RAG is less reliable than Expert-RAG and can sometimes result in lower accuracy than Zero Shot under LLM grading.
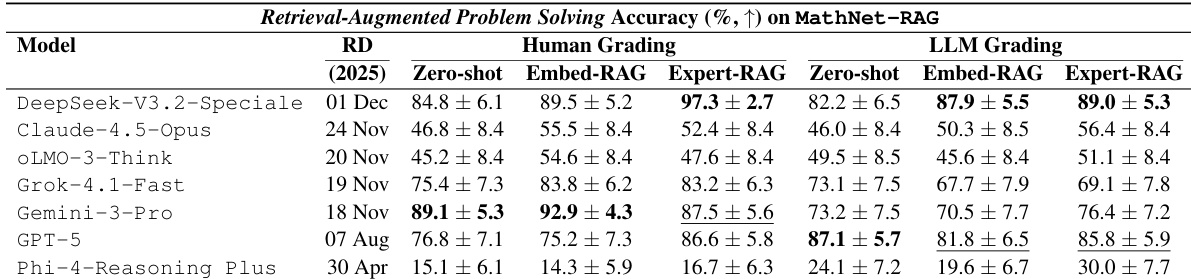
The authors evaluate multiple large language models on the MathNet-Solve-Test benchmark, measuring problem-solving accuracy across a range of languages. Results show a distinct hierarchy where frontier reasoning models substantially outperform smaller or older baselines, with the top model leading significantly. Performance varies notably by language, with top systems achieving higher accuracy in languages like French and Italian compared to Chinese or Spanish. Frontier models such as gemini-3.1-pro and gpt-5 achieve the highest overall accuracy. There is a significant performance gap between top-tier models and weaker baselines like Ministral-3B. Accuracy fluctuates across languages, with top models performing particularly well in French and Italian.
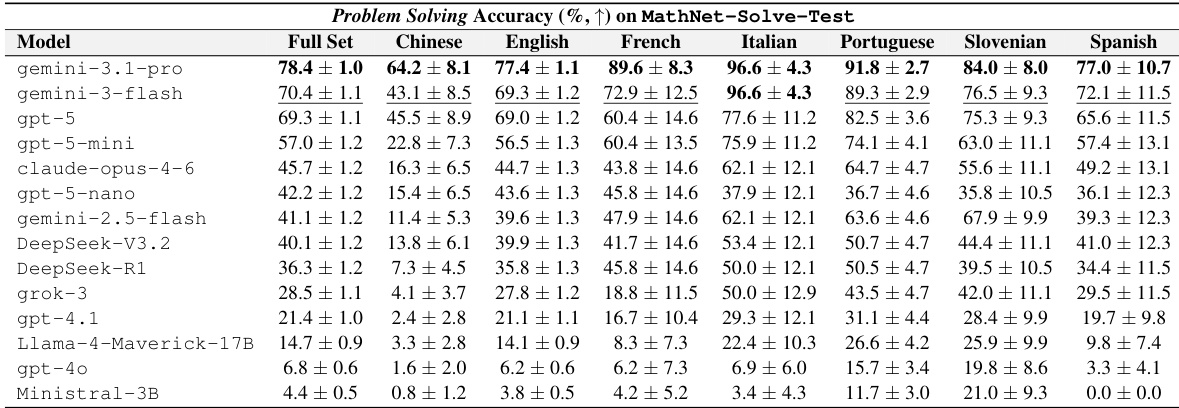
These experiments evaluate problem-solving accuracy and retrieval-augmented generation across mathematical domains using various large language and multimodal models on the MathNet benchmarks. Results indicate that explicit reasoning capabilities and multimodal inputs consistently enhance performance, with frontier models substantially outperforming weaker baselines. Additionally, the Expert-RAG setting generally yields superior performance for top-tier systems compared to Zero-shot or Embed-RAG configurations, though outcomes vary by specific mathematical domain and language.