Command Palette
Search for a command to run...
Rubrikbasierte On-Policy-Distillation
Rubrikbasierte On-Policy-Distillation
Junfeng Fang Zhepei Hong Mao Zheng Mingyang Song Gengsheng Li Houcheng Jiang Dan Zhang Haiyun Guo Xiang Wang Tat-Seng Chua
Zusammenfassung
On-Policy Distillation (OPD) stellt ein leistungsfähiges Paradigma für die Modellanpassung dar, doch seine Abhängigkeit von den Logits des Lehrmodells beschränkt seinen Einsatz auf White-Box-Szenarien. Wir vertreten die Auffassung, dass strukturierte semantische Bewertungskriterien als skalierbare Alternative zu den Logits des Lehrmodells dienen können und somit die Durchführung von OPD ausschließlich auf Basis der vom Lehrmodell generierten Antworten ermöglichen. Um dies zu belegen, stellen wir ROPD vor, ein einfaches, jedoch grundlegendes Framework für die rubrikenbasierte OPD. Konkret erzeugt ROPD prompt-spezifische Bewertungskriterien aus dem Kontrast zwischen Lehr- und Schülermodell und nutzt diese Kriterien anschließend, um die Rollouts des Schülermodells für die On-Policy-Optimierung zu bewerten. Empirisch übertrifft ROPD fortschrittliche, logit-basierte OPD-Methoden in den meisten Szenarien und erzielt dabei eine bis zu zehnfache Steigerung der Stichprobeneffizienz. Diese Ergebnisse positionieren die rubrikenbasierte OPD als flexible, Black-Box-kompatible Alternative zu den derzeit vorherrschenden logit-basierten OPD-Ansätzen und bieten eine einfache, aber leistungsfähige Basislinie für skalierbare Distillation bei proprietären und Open-Source-LLMs. Der Code steht unter https://github.com/Peregrine123/ROPD_official zur Verfügung.
One-sentence Summary
ROPD is a rubric-based on-policy distillation framework that replaces teacher logits with structured semantic rubrics derived from teacher-student contrasts to score student rollouts, enabling black-box compatibility while delivering up to a tenfold improvement in sample efficiency and establishing a scalable baseline for aligning proprietary and open-source large language models.
Key Contributions
{ "schema_version": "black_opd.rubric.v1", "contributions": [ "- The paper introduces ROPD, a framework for rubric-based on-policy distillation that replaces restrictive teacher logits with structured semantic rubrics to enable black-box model alignment.", "- The method derives prompt-specific evaluation criteria from teacher-student response contrasts and converts weighted pass rates against these rubrics into on-policy rewards for direct optimization.", "- Empirical evaluations demonstrate that this approach outperforms advanced logit-based distillation methods across most scenarios, delivering up to a 10x improvement in sample efficiency and robust performance across diverse model architectures." ] }
Introduction
On-policy distillation has become a foundational post-training paradigm for aligning large language models by replacing sparse rewards with dense feedback on student-generated trajectories. While this approach significantly improves sample efficiency and mitigates exposure bias, it traditionally depends on teacher logits or aligned token spaces, restricting its use to white-box environments and blocking distillation from proprietary or architecturally distinct models. Existing black-box alternatives attempt to overcome this limitation but rely on implicit signals like preference pairs or scalar evaluator scores that obscure the actual quality criteria. The authors introduce ROPD, a rubric-based on-policy distillation framework that replaces logit supervision with explicit, structured semantic rubrics derived from teacher-student contrasts. By scoring student rollouts against these dynamic criteria, the framework enables scalable black-box distillation, delivers up to a tenfold improvement in sample efficiency, and establishes a robust baseline for aligning both open and proprietary language models.
Dataset
- Dataset composition and sources: The authors assemble a structured question-answering collection where each entry pairs a central prompt with two distinct response groups: reference answers and exploratory rollouts.
- Subset details: The reference group contains high-quality teacher responses that serve as ground truth, while the rollout group captures multiple student-generated attempts. The exact count of teacher answers and student rollouts varies per sample to reflect diverse reasoning paths and answer distributions.
- Training usage and mixture: The authors feed these paired sequences directly into the model for supervised fine-tuning and alignment. Teacher responses guide the primary learning objective, while student rollouts are mixed in to teach comparative reasoning and self-correction capabilities.
- Processing and metadata construction: Each sample follows a fixed template that explicitly labels the question, teacher outputs, and student rollouts. This formatting acts as built-in metadata, enabling the model to distinguish between authoritative and generated text. The full sequence is preserved without cropping to maintain complete context and reasoning chains.
Method
The authors leverage a two-stage framework for rubric-based on-policy distillation, designed to enable knowledge transfer from a teacher model to a student without requiring access to the teacher's internal token-level outputs. The overall architecture operates in a fully black-box regime, where the teacher model, Rubricator, and Verifier are accessed solely through text prompts and structured JSON outputs, without any access to internal logits or hidden states. As shown in the figure below, the process begins with an input question x, which is processed independently by both the teacher and student models to generate a set of rollouts. The teacher model produces m responses YxT={yjT}j=1m, while the student generates n rollouts YxS={yiS}i=1n from its current policy πθ. These rollouts are then fed into the Rubricator module, which synthesizes a shared, question-specific rubric set Cx={ck}k=1K. Each rubric item ck consists of a textual criterion ρk and an associated importance weight wk>0, derived from a contrastive analysis of the teacher and student responses. The rubric is designed to capture consistent quality dimensions in the teacher's behavior while identifying systematic weaknesses in the student's outputs, ensuring the criteria are specific, measurable, and evaluable on a single response without referencing other responses.
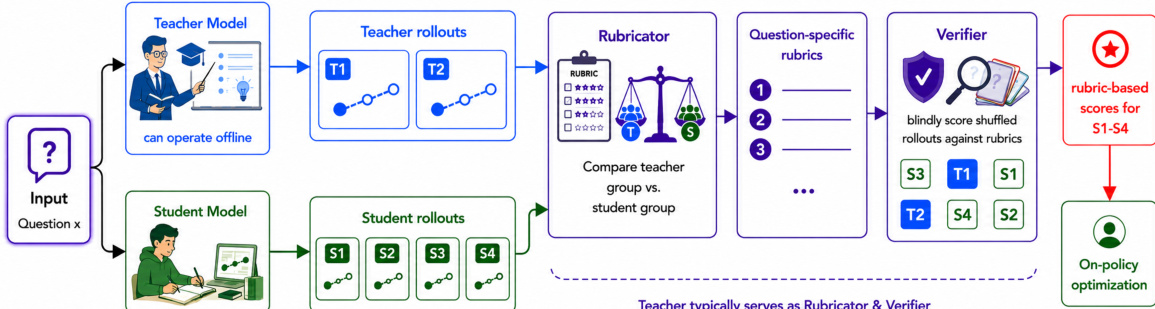
The induced rubric set is then used by the Verifier to evaluate each student rollout against the criteria. For each student response yiS and rubric item ck, the Verifier produces a binary judgment vi,k∈{0,1}, indicating whether the response satisfies the criterion. The response-level score si is computed as the weighted pass rate, ∑k=1Kwkvi,k/∑k=1Kwk, which serves as the reward signal for on-policy optimization. This reward computation is designed to be robust to varying question difficulties by having the Verifier score both teacher and student rollouts together in a blind manner, thereby calibrating any bias arising from differences in task complexity. The framework employs Group Relative Policy Optimization (GRPO) to update the student policy, which normalizes the advantage of each rollout within its group based on the mean and standard deviation of the rewards, avoiding the need for a separate value function. The final training procedure, as detailed in Algorithm 1, iteratively collects rollouts, induces rubrics, computes rewards, and updates the student policy parameters, enabling effective and efficient distillation even in black-box settings.
Experiment
The evaluation setup employs math and science benchmarks across both black-box and white-box distillation settings to validate the method's capacity for transferring complex reasoning capabilities from teacher to student models. Experimental results demonstrate that rubric-augmented supervision consistently outperforms static and logit-based baselines by decomposing response quality into verifiable criteria that align directly with logical correctness rather than superficial stylistic mimicry. Furthermore, the approach exhibits superior data efficiency, stable convergence, and robust cross-architecture generalization, confirming that structured criterion-based guidance effectively circumvents traditional distillation bottlenecks while preserving broad instruction-following alignment.
The experiment setup uses a consistent configuration across math, science, and medical tracks, with the student model being Qwen3-4B and the teacher model GPT-5.2-chat-latest in a black-box setting. The training leverages GRPO with shared hyperparameters, and ROPD-specific settings such as multiple teacher answers and rubric items are applied uniformly across domains. The hardware setup consists of 8 A100-80GB GPUs, and decoding parameters are kept identical for no-think and think modes. The experiment uses a consistent setup across math, science, and medical tracks with Qwen3-4B as the student model and GPT-5.2-chat-latest as the teacher. ROPD-specific parameters like multiple teacher answers and rubric items are applied uniformly across all domains. Training and decoding hyperparameters are shared across tracks, with identical hardware configuration of 8 A100-80GB GPUs.
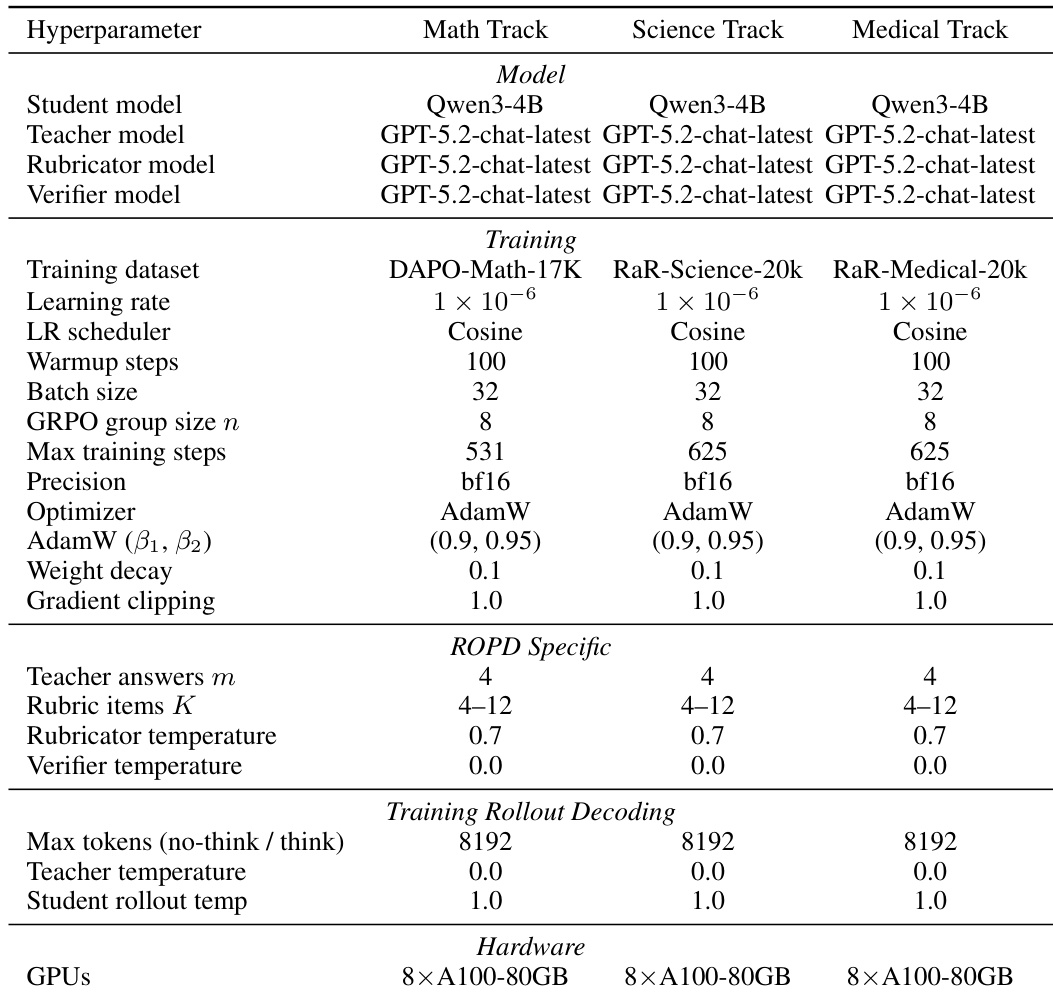
The authors evaluate ROPD's cross-architecture generalization by testing it with a less capable student model, Gemma3-4B, under identical conditions as the primary experiments. Results show that ROPD consistently improves the base model's performance across all benchmarks, demonstrating its ability to provide effective supervision even when the student is significantly weaker. The approach achieves substantial gains on the most challenging benchmark, HMMT (Nov.), and maintains improvements across all domains, indicating robust transferability. ROPD achieves significant performance gains over the base model on all benchmarks, including the most challenging one. The method demonstrates strong cross-architecture generalization, maintaining effectiveness even with a significantly weaker student model. ROPD consistently outperforms baseline methods across all evaluated configurations.
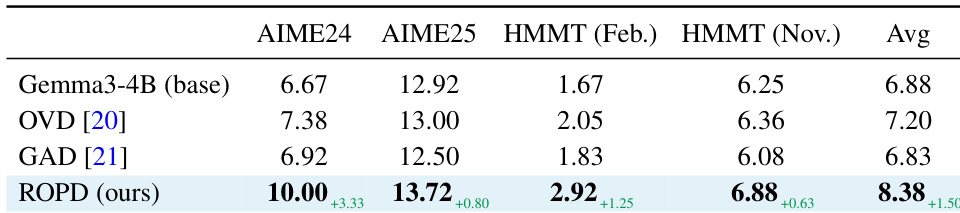
The experiment evaluates the impact of different reward design components in ROPD on model performance, using AIME24 as the evaluation metric. Results show that the full ROPD setup, which includes multi-teacher seeding, cross-rollout rubric sharing, and blind scoring, achieves the highest performance, significantly surpassing the base model and ablated versions that omit one or more of these components. The full ROPD setup achieves the highest performance on AIME24, outperforming all ablated variants. Removing multi-teacher seeding leads to a substantial drop in performance, indicating its importance for robust criterion generation. Omitting blind scoring also reduces performance, suggesting that identity-aware evaluation negatively impacts reward quality.
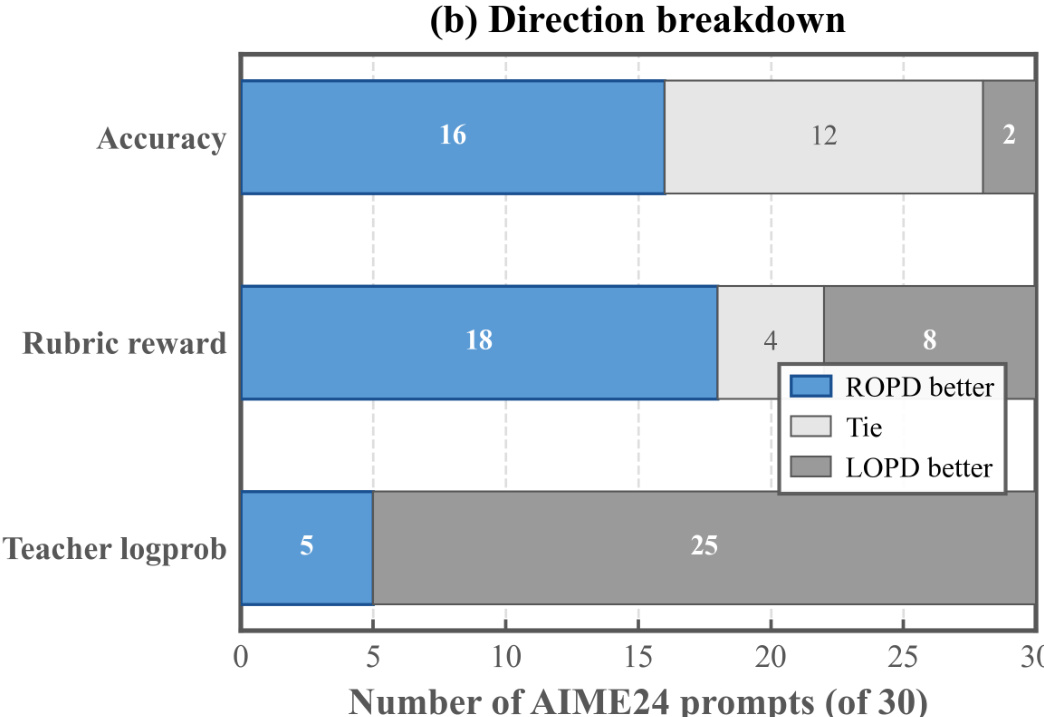
The figure presents a prompt-level breakdown of performance comparisons between ROPD and LOPD across three metrics: accuracy, rubric reward, and teacher logprob. ROPD outperforms LOPD on the majority of prompts in both accuracy and rubric reward, while LOPD dominates in teacher logprob. The results highlight ROPD's superior performance in reasoning accuracy and reward satisfaction, with LOPD achieving higher scores in teacher logprob, indicating a focus on mimicking the teacher's output distribution. ROPD outperforms LOPD on the majority of prompts in accuracy and rubric reward. LOPD achieves higher scores than ROPD in teacher logprob, indicating a focus on mimicking the teacher's output distribution. ROPD demonstrates superior reasoning accuracy and reward satisfaction compared to LOPD.
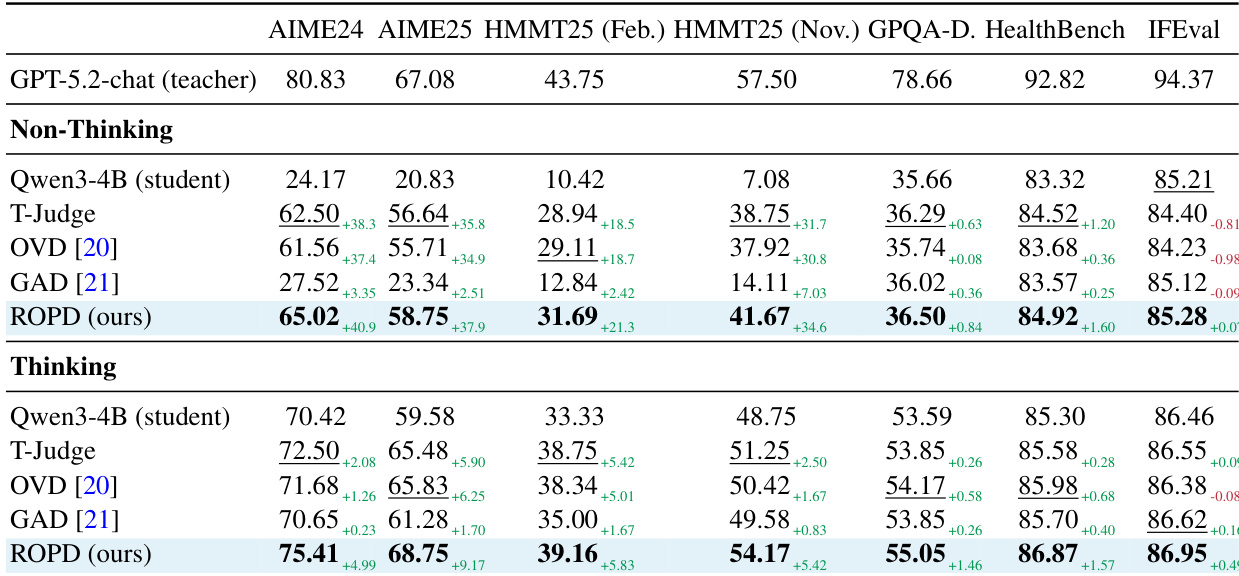
The authors evaluate their ROPD method in both black-box and white-box settings, demonstrating consistent performance improvements over baseline approaches across multiple benchmarks. In black-box scenarios, ROPD achieves the highest scores on all benchmarks, significantly outperforming the student model and other distillation methods, with notable gains on challenging tasks. In white-box settings, ROPD surpasses advanced logit-based methods despite using only text-based teacher information, showing superior data efficiency and convergence stability. The results indicate that rubric-based supervision provides more effective and discriminative feedback than dense logit signals, enabling the student to transcend teacher imitation and achieve higher reasoning accuracy. ROPD achieves the highest performance across all benchmarks in both non-thinking and thinking modes, consistently outperforming other distillation methods. ROPD demonstrates superior data efficiency and convergence stability compared to logit-based methods, achieving better results with significantly fewer training samples. Rubric-based supervision enables the student to transcend teacher imitation, achieving higher reasoning accuracy by focusing on correctness rather than surface-level mimicry.
The evaluation employs a consistent black-box teacher-student framework across multiple STEM domains, utilizing shared training hyperparameters and hardware to assess ROPD's effectiveness. Experimental results validate the method's strong cross-architecture generalization, demonstrating consistent performance gains even when applied to less capable student models. Ablation studies confirm that specific reward design components, particularly multi-teacher seeding and blind scoring, are essential for generating robust evaluation criteria. Furthermore, comparisons against distribution-matching baselines and tests across both black-box and white-box settings reveal that rubric-based supervision provides more discriminative feedback, enabling the student to prioritize reasoning accuracy over superficial imitation while maintaining superior data efficiency and convergence stability.