Command Palette
Search for a command to run...
MACE-Dance: Bewegungs- und Erscheinungs-Kaskadierende Experten für musikgetriebene Tanzvideogenerierung
MACE-Dance: Bewegungs- und Erscheinungs-Kaskadierende Experten für musikgetriebene Tanzvideogenerierung
Kaixing Yang Jiashu Zhu Xulong Tang Ziqiao Peng Xiangyue Zhang Puwei Wang Jiahong Wu Xiangxiang Chu Hongyan Liu Jun He
Zusammenfassung
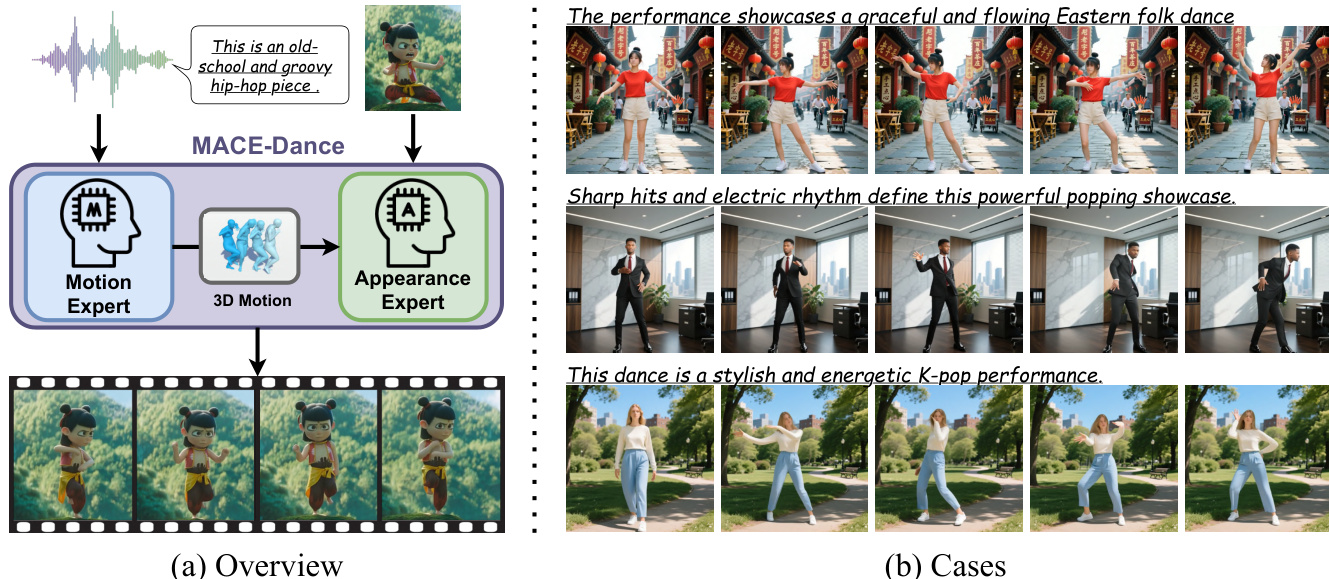
Mit dem Aufkommen von Online-Plattformen für Tanzvideos und den raschen Fortschritten im Bereich KI-generierter Inhalte (AIGC) hat sich die musikgetriebene Generierung von Tanzvideos als vielversprechende Forschungsrichtung entwickelt. Trotz erheblicher Fortschritte in verwandten Bereichen wie der musikgetriebenen 3D-Tanzgenerierung, der Pose-gesteuerten Bildanimation und der audiogetriebenen Synthese von sprechenden Köpfen (Talking-Head-Synthese) können bestehende Methoden nicht direkt für diese Aufgabe übernommen werden. Darüber hinaus kämpfen die wenigen bisherigen Studien in diesem Bereich weiterhin mit der gleichzeitigen Erzeugung hochqualitativer visueller Erscheinungsbilder und realistischer menschlicher Bewegungen. In diesem Kontext präsentieren wir MACE-Dance, ein Framework zur musikgetriebenen Generierung von Tanzvideos, das auf einer kaskadierten Mischung von Experten (Mixture-of-Experts, MoE) basiert. Der Motion Expert (Bewegungsexperte) führt die Generierung von 3D-Bewegungen aus der Musik durch und stellt dabei kinematische Plausibilität sowie künstlerische Ausdrucksfähigkeit sicher. Der Appearance Expert (Darstellungsexperte) übernimmt die videosynthese unter Konditionierung durch Bewegung und Referenzbilder und bewahrt dabei die visuelle Identität mit räumlich-zeitlicher Kohärenz. Spezifisch nutzt der Motion Expert ein Diffusionsmodell mit einer hybriden BiMamba-Transformer-Architektur und einer Guidance-Free Training (GFT)-Strategie (Leitfadensfreie Trainingsstrategie), wodurch State-of-the-Art (SOTA)-Leistung in der 3D-Tanzgenerierung erreicht wird. Der Appearance Expert employs eine entkoppelte Strategie zur feinen Anpassung von Kinematik und Ästhetik und erzielt ebenfalls State-of-the-Art (SOTA)-Leistung in der Pose-gesteuerten Bildanimation. Um die Bewertung dieser Aufgabe zu standardisieren, haben wir einen großformatigen und vielfältigen Datensatz zusammengestellt und ein Evaluierungsprotokoll für Bewegung und Erscheinungsbild entwickelt. Basierend auf diesem Protokoll erreicht MACE-Dance ebenfalls State-of-the-Art-Leistung. Projektseite: https://macedance.github.io/
One-sentence Summary
MACE-Dance is a cascaded Mixture-of-Experts framework for music-driven dance video generation that employs a BiMamba-Transformer hybrid diffusion model with guidance-free training to enforce kinematic plausibility and a decoupled kinematic-aesthetic fine-tuning strategy to preserve visual identity, achieving state-of-the-art performance across 3D dance generation, pose-driven image animation, and a newly curated motion-appearance evaluation protocol.
Key Contributions
- MACE-Dance is presented as a cascaded Mixture-of-Experts framework that decouples music-driven 3D choreography synthesis from visual rendering to resolve fundamental mismatches in prior generation pipelines.
- The Motion Expert leverages a BiMamba-Transformer hybrid diffusion model with a Guidance-Free Training strategy to enforce kinematic plausibility, while the Appearance Expert employs decoupled Kinematic-Aesthetic fine-tuning to maintain visual identity and spatiotemporal coherence.
- A large-scale dataset is curated alongside a dedicated motion-appearance evaluation protocol, enabling benchmarked state-of-the-art performance across both 3D dance generation and pose-driven image animation tasks.
Introduction
The surge of AI-generated content on dance-centric platforms has elevated music-driven dance video generation as a critical research direction, yet current methods struggle to simultaneously ensure kinematic plausibility and high-fidelity visual appearance. Existing approaches often rely on isolated 3D motion synthesis or pose-driven animation pipelines that fail to capture the full-body complexity of dance, suffer from information loss due to 2D projections, or demand manual choreography, leading to compromised motion quality and unrealistic visuals. To overcome these limitations, the authors introduce MACE-Dance, a cascaded Mixture-of-Experts framework that separates motion generation from video synthesis. The Motion Expert leverages a BiMamba-Transformer hybrid diffusion model with guidance-free training to produce efficient, physically consistent 3D dance sequences, while the Appearance Expert applies a decoupled kinematic-aesthetic fine-tuning strategy to render videos that preserve visual identity and spatiotemporal coherence. Complementing the model, the authors curate the MA-Data dataset and design a dedicated motion-appearance evaluation protocol to establish robust benchmarks for this emerging task.
Dataset
-
Dataset Composition and Sources: The authors introduce MA-Data, a large-scale collection designed for music-driven dance video generation. The dataset contains 70,000 clips lasting 5 to 10 seconds each, totaling approximately 116 hours and spanning over 20 dance genres including Jazz, Latin, and Eastern Folk. It combines two complementary sources: professional 3D motion data and real-world social media footage.
-
3D-Rendered Subset (Motion-Centric): Sourced from the FineDance dataset, this portion comprises 20,000 clips (roughly 28 hours). The authors retarget the original motion sequences to a standard character model and render front-view videos. To maximize data diversity, they extract random 5 to 10 second segments using a sliding-window strategy.
-
In-the-Wild Subset (Appearance-Centric): Curated from high-engagement TikTok and YouTube creators, this portion includes 50,000 clips (roughly 88 hours). The authors apply a rigorous multi-stage cleaning pipeline to filter out low-quality or misaligned content. They first use TransNet V2 for shot boundary detection and discard segments shorter than 5 seconds. Next, they remove near-static footage using an optical flow magnitude threshold. They then enforce a single performer constraint with ViTPose, filtering out clips with multiple people or minimal motion. Finally, they split longer videos into 5 to 10 second clips using a sliding window with random offsets.
-
Training Usage and Mixture Ratios: The authors utilize the full 70,000 clip collection as the primary training set, maintaining a 2 to 5 ratio between the 3D-rendered and in-the-wild subsets. This mixture balances technical motion accuracy with visual entertainment value. They reserve an additional 200 high-engagement 5-second clips across multiple genres to serve as the test set.
-
Processing and Cropping Strategy: The dataset relies heavily on temporal cropping and alignment techniques. Both subsets use sliding-window extraction with random offsets to generate consistent clip lengths. The 3D source requires front-view rendering and motion retargeting, while the in-the-wild source undergoes automated quality control via TransNet V2, optical flow analysis, and pose estimation. No explicit metadata schema is detailed beyond genre categorization and platform engagement metrics used during curation.
Method
The MACE-Dance framework employs a cascaded mixture-of-experts (MoE) architecture to address music-driven dance video generation, decoupling the task into two distinct stages: motion generation and appearance synthesis. This design enables the model to focus on specialized subproblems, reducing overall complexity and improving data efficiency. The framework takes as input a music sequence M and a reference image I, and produces a corresponding dance video D. The process begins with the Motion Expert, which transforms the music into a kinematically plausible and artistically expressive 3D motion sequence X. This intermediate representation serves as the foundation for the Appearance Expert, which uses X and I to generate a video with spatiotemporally coherent visual appearance. By explicitly using 3D motion as the bridge between the two experts, the framework avoids the pitfalls of end-to-end models, such as spurious cross-modal correlations, and provides an interpretable and controllable interface for video synthesis. The use of SMPL as the 3D motion representation further enhances the model's ability to capture full-body geometric structure and handle complex locomotion, offering richer spatial fidelity, cleaner supervision, and better robustness compared to 2D keypoint-based approaches.
The Motion Expert is designed to generate temporally coherent and musically aligned 3D dance motions. It adopts a BiMamba-Transformer hybrid backbone, leveraging the strengths of both architectures to model local and global dependencies. The input music features, extracted using Librosa, are processed by an Lm-layer BiMamba to capture intra-modal temporal dynamics. The diffusion time step t and the temperature parameter β are encoded as sinusoidal embeddings and fused via element-wise addition to form a t-β embedding, which is used throughout the generator. The core of the generator consists of Ld stacked blocks. Each block processes the current state zt through a BiMamba to model intra-modal local dependencies, followed by a FiLM modulation using the t-β embedding. A Transformer then performs cross-modal attention over the music encoding to integrate global musical context, which is further processed by a feed-forward network. A second FiLM modulation reinforces the t-β conditioning. This architecture enables non-autoregressive generation of the entire sequence, improving efficiency and avoiding exposure bias. The model is trained using a diffusion-based approach, specifically a denoising diffusion probabilistic model (DDPM). The forward noising process adds Gaussian noise to the 3D motion sequence, while the model learns to reverse this process by estimating the original motion from the noisy latent at each timestep. To enhance physical plausibility and aesthetic expressiveness, the training objective includes not only a reconstruction loss but also 3D joint, velocity, and foot contact losses. The model utilizes Guidance-Free Training (GFT), which parameterizes the model to implicitly represent temperature-controlled sampling behavior during training, mitigating distribution mismatch and enabling more stable generation. During inference, the model uses Denoising Diffusion Implicit Models (DDIM) for accelerated sampling, where the β parameter controls the trade-off between motion diversity and fidelity.
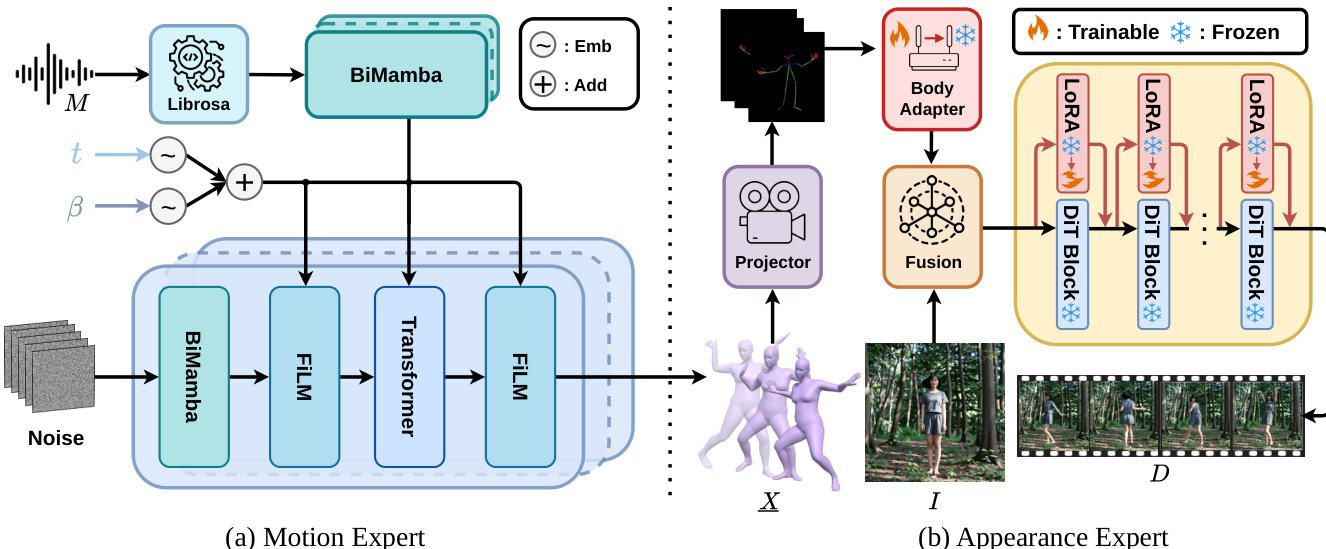
The Appearance Expert is built upon the Wan-Animate framework, which is adapted for dance video generation through a decoupled Kinematic-Aesthetic fine-tuning strategy. This strategy ensures high-fidelity appearance synthesis while maintaining strict motion adherence. The architecture takes a reference image I and a 3D motion sequence X as inputs. The motion sequence is first projected to 2D keypoints using a 3D-to-2D Motion Projector, which renders the SMPL mesh under a fixed camera and extracts 2D keypoints with ViTPose. These 2D keypoints are encoded by a Body Adapter to yield motion features, which are then fused with the latent extracted from the reference image. The resulting latent is processed by a backbone of stacked DiT blocks, where lightweight LoRA adapters are integrated into each block. The Kinematic Stage fine-tunes only the Body Adapter, strengthening kinematic conditioning by reweighting body features across scales to enforce motion adherence without altering the backbone. The Aesthetic Stage fine-tunes only the LoRA parameters, which are attached to the attention and feed-forward projections in each DiT block. This allows the model to specialize in dance-specific aesthetics—such as sharpening textures and stabilizing clothing—without disturbing the motion control pathways. The use of LoRA enables efficient adaptation with a small number of trainable parameters. The training process involves two stages: first, the Kinematic Stage is trained to ensure motion adherence, and second, the Aesthetic Stage is trained to refine visual quality. This decoupled approach allows the model to achieve high-fidelity results while maintaining the robustness and efficiency of the underlying pre-trained architecture.
Experiment
The evaluation establishes a comprehensive motion-appearance protocol that benchmarks the proposed dual-expert architecture against state-of-the-art baselines and general video foundation models, supplemented by a human preference study conducted by dance experts. Quantitative and qualitative comparisons consistently demonstrate that explicitly separating motion synthesis from visual rendering significantly enhances kinematic plausibility, rhythmic synchronization, and artistic diversity while eliminating common artifacts like temporal flickering and physical impossibilities. Ablation studies and cross-validation further confirm that key architectural choices, including the hybrid diffusion architecture, guidance-free training strategy, and three-dimensional motion representation, are critical for maintaining long-sequence stability and high-fidelity subject consistency. Ultimately, the strong alignment between objective measurements and human judgments validates the framework as a robust and perceptually accurate standard for music-driven dance video generation.
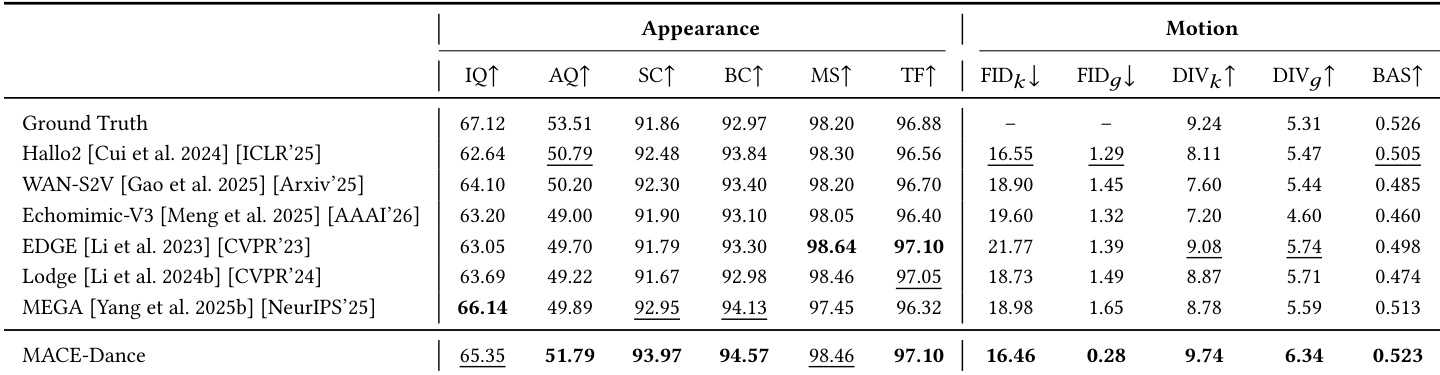
The authors compare their method against general-purpose video foundation models, evaluating both motion and appearance quality using a comprehensive protocol. Results show that their approach achieves superior performance across key metrics related to visual fidelity, identity consistency, and music-motion alignment, outperforming the baselines in most aspects. The user study further confirms that the proposed method is preferred by participants for both motion expressiveness and visual coherence. The proposed method achieves the best performance in identity consistency and beat alignment compared to general-purpose video models. The method outperforms baseline models in visual quality and motion synchronization, as validated by both quantitative metrics and user preference. User study results align with quantitative evaluations, showing strong preference for the proposed method in both motion and appearance aspects.
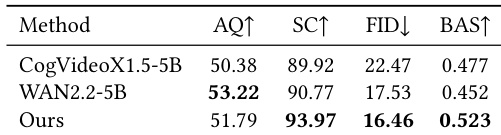
The authors present a comprehensive evaluation of their method, MACE-Dance, focusing on both motion and appearance quality. The results show that the proposed approach achieves state-of-the-art performance across multiple metrics, demonstrating superior kinematic plausibility and artistic expressiveness, as well as high-fidelity and temporally coherent visual appearance. The evaluation protocol effectively aligns with human perception, as confirmed by a user study where the method consistently outperforms baselines. MACE-Dance achieves the best performance in both motion and appearance quality, demonstrating superior kinematic plausibility and visual fidelity. The evaluation metrics strongly correlate with human preferences, validating the effectiveness of the proposed motion-appearance evaluation protocol. The method outperforms baselines in generating diverse and expressive dance motions while maintaining spatiotemporal consistency and identity preservation.
The authors evaluate their method, MACE-Dance, through a user study comparing it against several state-of-the-art baselines across multiple dimensions of dance video generation. The results show that MACE-Dance consistently outperforms all compared methods in user preference across all six evaluated metrics, indicating superior performance in both motion and appearance quality. The quantitative metrics from the user study align well with the authors' proposed motion-appearance evaluation protocol, confirming its effectiveness in capturing human perception. MACE-Dance achieves the highest user preference across all six evaluated dimensions, including dance creativity, quality, and synchronization, as well as perceptual and identity consistency. The user study results show that MACE-Dance significantly outperforms all baseline methods, with preference rates ranging from 50% to over 65% across all metrics. The quantitative evaluation metrics strongly correlate with human perception, validating the proposed motion-appearance evaluation protocol as a reliable framework for assessing music-driven dance video generation.
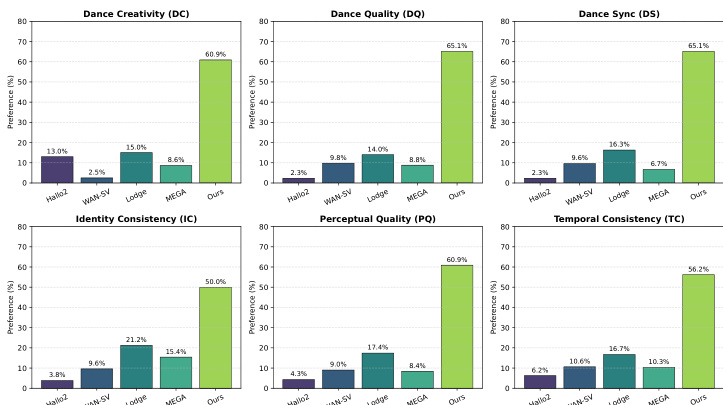
The authors present a comprehensive evaluation of their proposed method, MACE-Dance, comparing it against several state-of-the-art baselines across both appearance and motion dimensions. Results show that MACE-Dance achieves the best performance in most metrics, particularly in motion quality and appearance fidelity, outperforming other methods in terms of kinematic plausibility, synchronization with music, and visual coherence. The evaluation includes both quantitative metrics and user studies, which confirm that MACE-Dance produces high-quality, expressive, and consistent dance videos. MACE-Dance achieves the best performance in most metrics, particularly in motion quality and appearance fidelity. The method outperforms baselines in kinematic plausibility, music-motion synchronization, and visual consistency. User studies confirm that MACE-Dance is preferred across all evaluated dimensions, including motion expressiveness and visual quality.
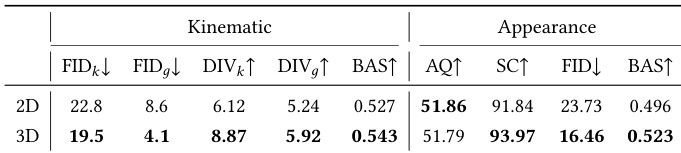
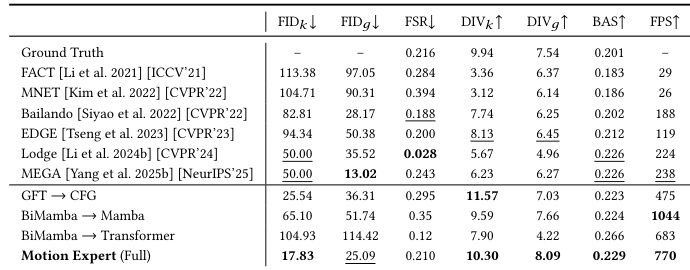
The authors evaluate their proposed Motion Expert model on a music-driven 3D dance generation task, comparing it against several state-of-the-art methods. The results show that the Motion Expert achieves the best performance across multiple metrics related to motion fidelity, diversity, and synchronization, indicating superior generation quality and efficiency. The evaluation includes both quantitative comparisons and qualitative analysis, highlighting the effectiveness of the model's architecture and training strategy. The Motion Expert achieves the best results across all motion-related metrics, including fidelity, diversity, and synchronization. The model demonstrates superior performance in both motion quality and generation efficiency compared to existing methods. The evaluation confirms the effectiveness of the proposed architecture and training strategy in producing high-quality 3D dance motions.
The authors conduct a comprehensive evaluation comparing their proposed method against general-purpose video foundation models and state-of-the-art baselines using both quantitative metrics and user studies. The experiments validate motion fidelity, visual appearance, and music synchronization, demonstrating that the approach consistently outperforms existing methods in kinematic plausibility, identity preservation, and temporal coherence. Qualitative assessments and user preferences strongly align with quantitative results, highlighting a clear consensus favoring the method for its superior motion expressiveness and visual quality. These findings confirm that the evaluation framework accurately captures human perception while establishing the method as a robust solution for high-quality, music-driven dance generation.