Command Palette
Search for a command to run...
GPT-5 Ist in Allen Bereichen Führend; OpenAI Veröffentlicht FrontierScience Und Nutzt Dabei Einen Dualen Ansatz Aus „Inferenz + Forschung“, Um Die Leistungsfähigkeit Von Groß Angelegten Modellen Zu testen.
Da sich die Modelllogik und die Wissensfähigkeiten ständig verbessern, sind anspruchsvollere Benchmark-Tests entscheidend, um die Fähigkeit eines Modells zur Beschleunigung der wissenschaftlichen Forschung zu messen und vorherzusagen. Am 16. Dezember 2025 startete OpenAI FrontierScience, einen Benchmark zur Messung wissenschaftlicher Fähigkeiten auf Expertenniveau.Nach ersten Auswertungen erzielte GPT-5.2 bei den FrontierScience-Olympiad- und Forschungsaufgaben 251 TP3T bzw. 771 TP3T Punkte und übertraf damit andere hochmoderne Modelle.
OpenAI erklärte in einer offiziellen Stellungnahme: „Die Beschleunigung des wissenschaftlichen Fortschritts ist eine der vielversprechendsten Möglichkeiten für künstliche Intelligenz, der Menschheit zu nutzen. Daher verbessern wir unsere Modelle für komplexe mathematische und wissenschaftliche Aufgaben und arbeiten an der Entwicklung von Werkzeugen, die Wissenschaftlern helfen können, diese Modelle optimal zu nutzen.“
Bisherige naturwissenschaftliche Benchmarks konzentrierten sich hauptsächlich auf Multiple-Choice-Fragen, die entweder zu komplex waren oder einen zu geringen naturwissenschaftlichen Fokus hatten. Im Gegensatz dazu wird FrontierScience – anders als frühere Benchmarks – von Experten aus Physik, Chemie und Biologie entwickelt und validiert.Es umfasst sowohl olympische Fragetypen als auch forschungsbasierte Fragetypen und ermöglicht so die Messung sowohl wissenschaftlicher Denkfähigkeiten als auch wissenschaftlicher Forschungskompetenzen.Darüber hinaus umfasst FrontierScience-Research 60 originelle Forschungs-Teilaufgaben, die von promovierten Wissenschaftlern entwickelt wurden und einen Schwierigkeitsgrad aufweisen, der mit dem vergleichbar ist, dem promovierte Wissenschaftler während ihrer Forschung begegnen könnten.
Bezüglich der Zukunft und der Grenzen von Benchmarking erklärte OpenAI in seinem offiziellen Bericht: „FrontierScience hat die Einschränkung eines engen Anwendungsbereichs und kann nicht alle Aspekte der täglichen Arbeit von Wissenschaftlern abdecken. Das Fachgebiet benötigt jedoch anspruchsvollere, originellere und aussagekräftigere wissenschaftliche Benchmarks, und FrontierScience ist ein Schritt in diese Richtung.“
Die Forschungsergebnisse des Projekts wurden unter dem Titel „FrontierScience: evaluating AI's ability to perform expert-level scientific tasks“ veröffentlicht.
Papieradresse:
https://hyper.ai/papers/7a783933efcc
Weitere Artikel:
Weitere Benchmarks anzeigen:

Der FrontierScience-Datensatz ermöglicht einen zweigleisigen Ansatz aus „Argumentieren und Forschen“.
In diesem Projekt erstellte das Forschungsteam den FrontierScience-Evaluierungsdatensatz, um die Leistungsfähigkeit großer Modelle bei wissenschaftlichen Argumentations- und Forschungsaufgaben auf Expertenniveau systematisch zu bewerten.Der Datensatz verwendet einen Designmechanismus aus „Expertenerstellung + zweistufiger Aufgabenstruktur + automatischem Bewertungsmechanismus“, um einen anspruchsvollen, skalierbaren und reproduzierbaren Benchmark für die Bewertung wissenschaftlicher Argumentation zu schaffen.
Datensatzadresse:
https://hyper.ai/datasets/47732
Basierend auf den unterschiedlichen Aufgabenformaten und Bewertungszielen wird der FrontierScience-Datensatz in zwei Teilmengen unterteilt, die zwei Arten von Fähigkeiten entsprechen: geschlossenes exaktes Denken und offenes wissenschaftliches Denken.
* Olympiade-Datensatz: Ursprünglich von Medaillengewinnern und Trainern der Nationalmannschaften der Internationalen Physik-, Chemie- und Biologie-Olympiade entwickelt, mit einem Schwierigkeitsgrad, der mit internationalen Spitzenwettbewerben wie IPhO, IChO und IBO vergleichbar ist; Der Schwerpunkt liegt auf Aufgaben mit kurzen Antworten, die logisches Denken erfordern und von den Modellen die Ausgabe eines einzelnen numerischen Wertes, eines algebraischen Ausdrucks oder einer biologischen Terminologie verlangen, die unscharf zugeordnet werden kann, um die Überprüfbarkeit der Ergebnisse und die Stabilität der automatischen Auswertung zu gewährleisten.
* Forschungsdatensatz: Die von Doktoranden, Postdoktoranden, Professoren und anderen aktiven Forschern erstellten Fragen simulieren Teilprobleme, die in der realen wissenschaftlichen Forschung auftreten können, und decken die drei Hauptbereiche Physik, Chemie und Biologie ab. Jede Frage wird mit einer detaillierten Bewertung von 10 Punkten versehen, um die Leistungsfähigkeit des Modells in mehreren Schlüsselaspekten zu beurteilen, die über die reine Richtigkeit der Antwort hinausgehen. Dazu gehören die Vollständigkeit der Modellannahmen, die nachvollziehbaren Argumentationswege und die Zwischenergebnisse.
Um die Originalität und Aussagekraft der Fragestellungen zu gewährleisten, prüfte das Forschungsteam diese während der internen Modelltestphase und entfernte diejenigen, die sich leicht mit bestehenden Modellen lösen ließen, um eine Sättigung der Auswertung zu vermeiden. Die Trainingsaufgaben durchlaufen insgesamt vier Phasen: Erstellung, Überprüfung, Lösung und Überarbeitung. Unabhängige Experten begutachten gegenseitig ihre Aufgaben, um sicherzustellen, dass diese den Standards entsprechen.Letztendlich wählte das Team 160 Open-Source-Fragen aus Hunderten von Kandidatenfragen aus, während die übrigen Fragen als Reserve für die spätere Erkennung von Umweltverschmutzungen und für eine langfristige Evaluierung aufbewahrt wurden.
Unabhängige Teilmengenstichproben und andere Modelle wie GPT-5.2 erzielten beeindruckende Ergebnisse.
Um die wissenschaftliche Argumentationsfähigkeit großer Modelle stabil und reproduzierbar zu bewerten, ohne auf externe Datenabfrage angewiesen zu sein, entwickelte das Forschungsteam einen strengen Bewertungsprozess und einen Bewertungsmechanismus.
In dieser Studie wurden mehrere gängige, hochmoderne Großmodelle als Bewertungsobjekte ausgewählt, die verschiedene Institutionen und technische Ansätze abdecken, um das Gesamtleistungsniveau aktueller universeller Großmodelle im Bereich des wissenschaftlichen Denkens möglichst umfassend abzubilden.Während des Evaluierungsprozesses wurden alle Modelle vom Internet getrennt, um sicherzustellen, dass ihre Ergebnisse ausschließlich auf ihrem internen Wissen und ihren Denkfähigkeiten beruhten und nicht durch Echtzeit-Informationsabfragen oder externe Tools beeinflusst wurden.Dadurch wird der Einfluss von Unterschieden in der Informationserfassungsfähigkeit verschiedener Modelle auf die Ergebnisse verringert.
Angesichts der inhärenten Zufälligkeit großer Modelle in generativen Reaktionen führte das Forschungsteam eine statistische Analyse durch, indem es mehrere unabhängige Stichproben nahm und die Ergebnisse aus den beiden Teilmengen, Olympiade und Forschung, mittelte, um zufällige Schwankungen zu vermeiden.Hinsichtlich der Bewertungsmethode entwirft die Arbeit automatisierte Bewertungsstrategien für die beiden Aufgabentypen unter Berücksichtigung ihrer unterschiedlichen Merkmale:
* Unterkategorie FrontierScience-Olympiad: Schwerpunkt ist das Denken in geschlossenen Fragen, wobei die Bewertung primär auf der Bestimmung der Äquivalenz der Antworten basiert. Numerische Näherungen sind innerhalb eines angemessenen Fehlerbereichs zulässig, ebenso wie äquivalente Transformationen algebraischer Ausdrücke und die unscharfe Zuordnung von Begriffen oder Namen in biologischen Fragen. Eine übermäßige Empfindlichkeit gegenüber der Ausdrucksform wird vermieden.
* Teilmenge FrontierScience-Research: Diese Teilmenge bildet reale Forschungsaufgaben präzise nach, indem sie den Forschungsprozess in mehrere unabhängige, überprüfbare Schlüsselschritte unterteilt. Die Antworten des Modells werden anhand von Bewertungskriterien Punkt für Punkt bewertet, nicht allein anhand der Korrektheit des Endergebnisses.
Insgesamt zeigt der FrontierScience-Benchmark einen klaren Trend der Leistungsdifferenzierung bei den beiden Aufgabentypen.
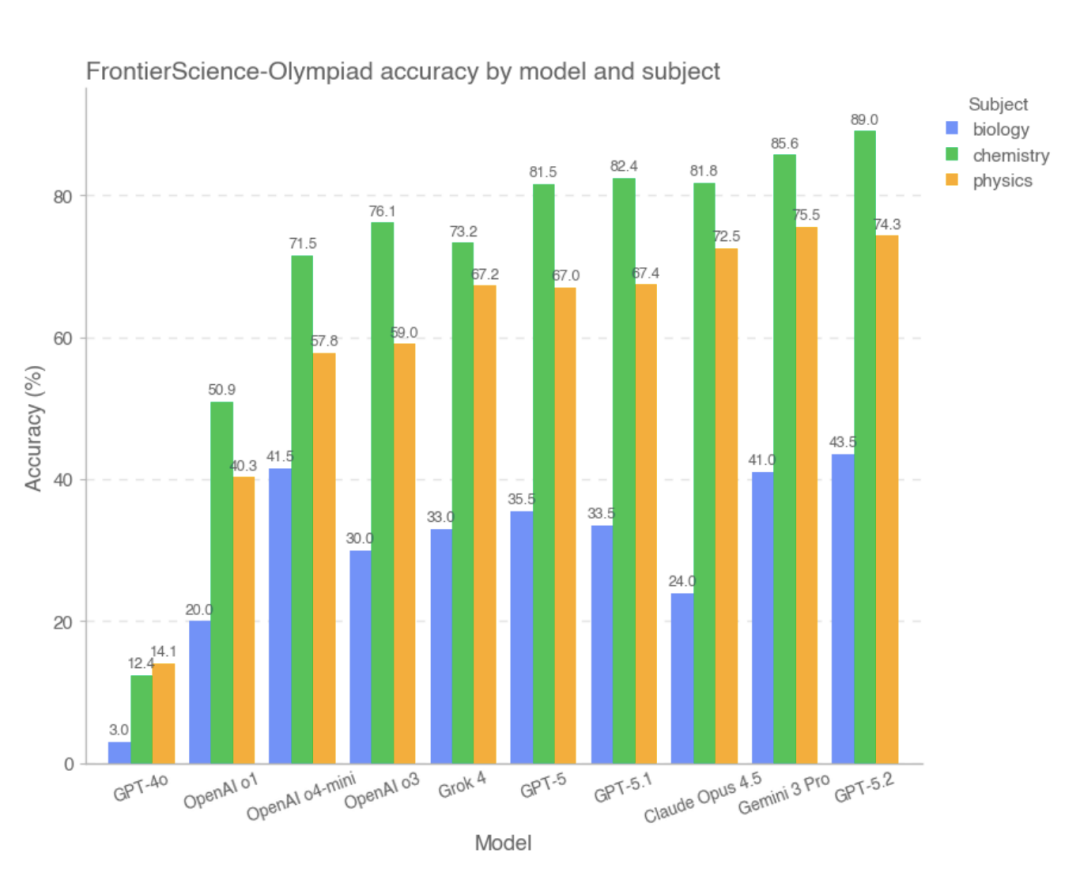
Im Olympiade-Teildatensatz erzielten die meisten hochmodernen Modelle hohe Punktzahlen. Darunter:Die drei besten Modelle mit den besten Gesamtergebnissen sind GPT-5.2, Gemini 3 Pro und Claude Opus 4.5, während GPT-4o und OpenAI-o1 vergleichsweise schlecht abschnitten.Die Studie zeigt, dass bei dieser Art von Problem mit klaren Bedingungen, relativ geschlossenen Denkpfaden und überprüfbaren Antworten die meisten Modelle in der Lage waren, komplexe Berechnungen und logische Schlussfolgerungen stabil durchzuführen, und ihre Gesamtleistung nahe an der von hochqualifizierten menschlichen Problemlösern liegt.
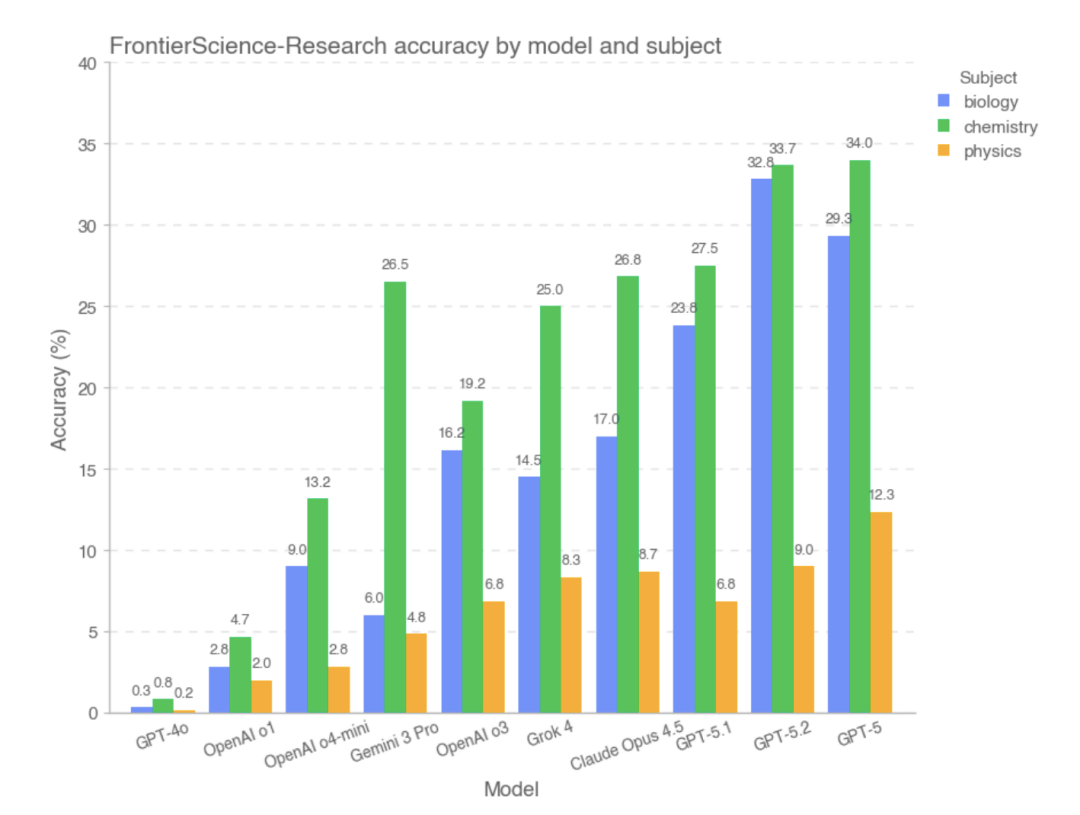
Im FrontierScience-Research-Teildatensatz war die Gesamtpunktzahl des Modells jedoch deutlich niedriger..Im Forschungsteilbereich ist das Modell bei der Zerlegung komplexer Forschungsprobleme anfälliger für Verzerrungen.Beispielsweise kann ein unvollständiges Verständnis der Problemstellung, ein unsachgemäßer Umgang mit Schlüsselvariablen oder Annahmen oder eine schleichende Anhäufung logischer Fehler in einer langen Argumentationskette vorliegen. Im Vergleich zu Aufgaben im Olympiade-Stil weisen groß angelegte Modelle weiterhin eine deutliche Leistungslücke auf, wenn sie mit offeneren Aufgaben konfrontiert werden, die realen Forschungsprozessen näherkommen. Basierend auf experimentellen Daten,Die Modelle, die im Forschungsteil gut abschnitten, waren GPT-5, GPT-5.2 und GPT-5.1.
Diese Studie verglich außerdem die Genauigkeit von GPT-5.2 und OpenAI-o3 auf den Testdatensätzen der FrontierScience-Olympiad und FrontierScience-Research unter verschiedenen Inferenzintensitäten. Die Ergebnisse zeigen, dass…Mit zunehmender Anzahl der im Test verwendeten Token verbesserte sich die Genauigkeit von GPT-5.2 von 67,51 TP3T auf 77,11 TP3T im Olympiad-Datensatz und von 181 TP3T auf 251 TP3T im Forschungsdatensatz.Es ist erwähnenswert, dass das o3-Modell auf dem Forschungsdatensatz bei hoher Inferenzintensität tatsächlich etwas schlechter abschneidet als bei mittlerer Inferenzintensität.
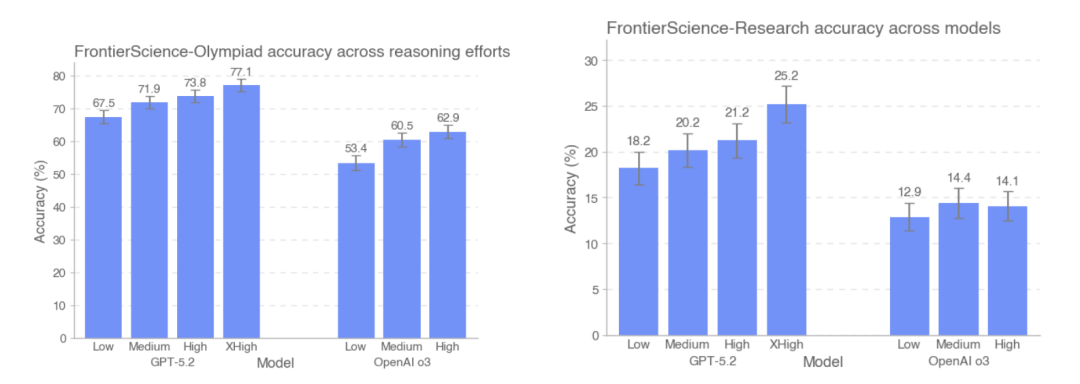
Basierend auf dem Gesamtdesign und den experimentellen Ergebnissen von FrontierScience,Das große Modell hat sich bei wissenschaftlichen Problemen mit klaren Strukturen und geschlossenen Bedingungen als stabil erwiesen, und seine Leistung bei einigen Aufgaben hat sich dem Niveau menschlicher Experten angenähert.Allerdings bleiben seine Fähigkeiten deutlich eingeschränkt, sobald es in Forschungsteilaufgaben eintritt, die kontinuierliche Modellierung, Problemzerlegung und die Aufrechterhaltung der Konsistenz beim Denken über lange Ketten erfordern.
Über die Richtigkeit der Antworten hinaus läuten groß angelegte Modelle einen neuen Standard der Leistungsfähigkeit ein.
In seiner offiziellen Erklärung weist OpenAI ausdrücklich darauf hin, dass FrontierScience nicht alle Dimensionen der wissenschaftlichen Alltagsarbeit abdeckt. Die Aufgaben basieren weiterhin primär auf textbasiertem Denken und beinhalten noch keine experimentellen Operationen, multimodale Informationen oder reale Forschungskooperationsprozesse. Angesichts der allgemeinen Sättigung bestehender wissenschaftlicher Evaluierungsmethoden bietet FrontierScience jedoch einen anspruchsvolleren und diagnostisch wertvollen Bewertungsansatz: Es konzentriert sich nicht nur auf die Korrektheit der Modellantworten, sondern misst systematisch auch, ob das Modell in der Lage ist, Teilaufgaben der Forschung zu lösen. Aus dieser Perspektive liegt der Wert von FrontierScience nicht nur in der Rangliste selbst, sondern auch darin, einen neuen Maßstab für die nachfolgende Modellverbesserung und die Forschung im Bereich der wissenschaftlichen Intelligenz zu schaffen. Da sich die Fähigkeiten von Modellen zum logischen Denken stetig weiterentwickeln, könnte diese Art von Benchmark, die Originalität, Expertenbeteiligung und Prozessevaluation betont, ein wichtiger Indikator dafür werden, ob künstliche Intelligenz tatsächlich den Weg zur Forschungskooperation beschreitet.
Referenzlinks:
1.https://cdn.openai.com/pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/frontierscience-paper.pdf
2.https://openai.com/index/frontierscience/
3.https://huggingface.co/datasets/openai/frontierscience








